本文转载于我的知乎:https://zhuanlan.zhihu.com/p/100609339
目录¶
- 总纲
- 多尺度处理方法
- 分割篇
- low-level篇
- 检测篇
- metric learning篇
- 分类篇
- landmark篇
- 视频理解篇
- 双目篇
- 3D篇
- 数据增强篇
总纲¶
cnn中各个参数的辩证矛盾。
深度决定了网络的表达能力,网络越深学习能力越强。
宽度(通道数)决定了网络在某一层学到的信息量,另外因为卷积层能重组通道间的信息,这一操作能让有效信息量增大(这也是1x1卷积的作用,它能学习出重组信息,使得对于任务更友好,所以这里不能和分离卷积一起比较,传统卷积的有效卷积数更多,正比于输入通道乘以输出通道,分离卷积的有效卷积正比于输入通道数,传统卷积相当于分离卷积前升维再做分离卷积)。
感受野决定了网络在某一层看到多大范围,一般说来最后一层一定至少要能看到最大的有意义的物体,更大的感受野通常是无害的。感受野必须缓慢增大,这样才能建模不同距离下的空间相关性。
在达到相同感受野的情况下,多层小卷积核的性能一定比大卷积核更好,因为多层小卷积核的非线性更强,而且更有利于特征共享。
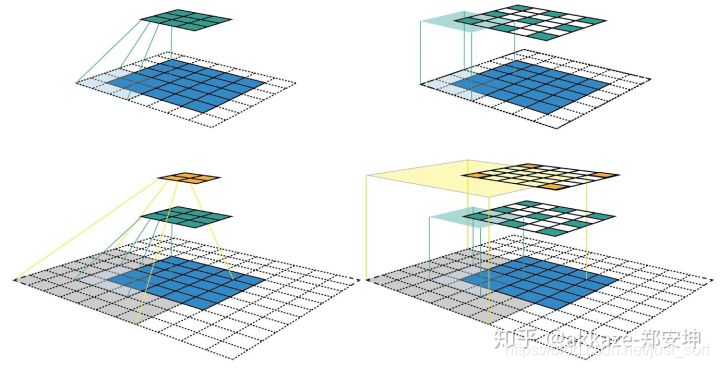
分辨率很重要,尽量不要损失分辨率,为了保住分辨率,在使用下采样之前要保证在这一层上有足够的感受野,这个感受野是相对感受野,是指这一个下采样层相对于上一个下采样层的感受野,把两个下采样之间看成一个子网络的话,这个子网络必须得有一定的感受野才能将空间信息编码到下面的网络去,而具体需要多大的相对感受野,只能实验,一般说来,靠近输入层的层空间信息冗余度最高,所以越靠近输入层相对感受野应该越小。同时在靠近输入层的层,这里可以合成一个大卷积核来降低计算量,因为在输入端,每一层卷积的计算量都非常大。另外相对感受野也必须缓慢变换。
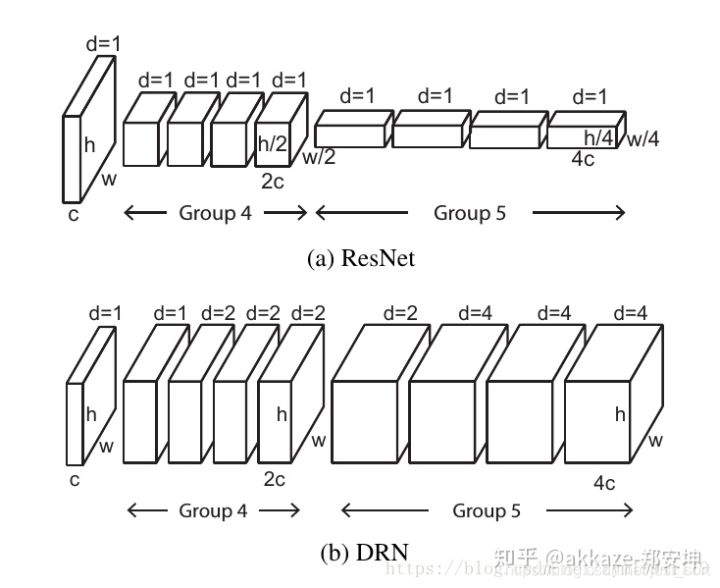
这种矛盾决定了下面的做法:
前面几层下采样频率高一点,中间层下采样频率降低,并使用不下采样的方法提高深度。
网络能深则深,在保持比较小宽度的时候,要想办法加深网络,变深的过程中网络慢慢变胖。
使用小卷积核(不包括1x1,因为它对于增加感受野无意义),小卷积核有利于网络走向更深,并且有更好的识别鲁棒性,尤其是在分辨率更小的特征图上,因为卷积核的尺寸是相当于特征图的分辨率来说的,大特征图上偏大的卷积核其实也并不大。
下采样在网络前几层的密度大一些,(这样能尽可能用微弱精度损失换取速度提升) 越往后下采样的密度应该更小,最终能够下采样的最大深度,以该层的感受野以及数据集中最大的有意义物体尺寸决定(自然不可能让最大有意义的物体在某一层被下采样到分辨率小于1,但是网络依然可以work,只不过最后几层可能废弃了(要相信cnn的学习能力,因为最大不了它也能学出单位卷积,也就是只有中心元素不为0的卷积核),更准确的说这是最大感受野的极限,最大感受野应该覆盖数据集中最大有意义的物体)。
第一层下采样的时候大卷积核能尽可能保住分辨率(其实相当于合成了两三层小卷积核,另外,这和插值是类似的,类比于最近邻插值,双线性插值,双三次插值,这其实和感受野理论一致,更远的插值意味着更大的感受野)。
shortcut connection里,找不到concat,用add凑合吧,在需要量化的场合,add会更好,反之亦然。
先训一个大模型然后裁剪,也许比直接训一个小模型性能好。
能用可分离卷积替代的卷积一定要替代,一般除了第一个卷积,都能替代,替代完后考虑给替代可分离的通道数乘以2,因为可分离卷积的参数和计算量都是线性增长的,这样做依然有速度增益。同样的道理适用于2+1分离卷积。
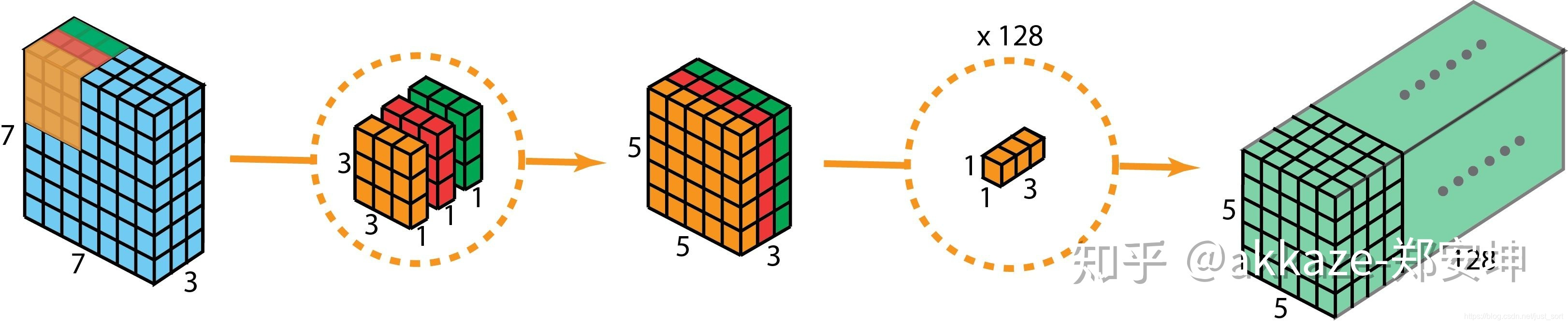
这里稍微提醒一下分离卷积在大型gpu上性能不好原因是gpu利用率,因为大型gpu核心数太多,如果计算量不够大核心没有用完,那么不同卷积层比较不出差异,反而层数带来的延迟会更严重,但是我个人表示相信分离卷积在未来一定会被合成一个层,这只是工程问题。
inception或者shortcut connection或者dense connection其实都相当于ensemble模型,考虑结合使用,shortcut connection的使用几乎是无痛的。
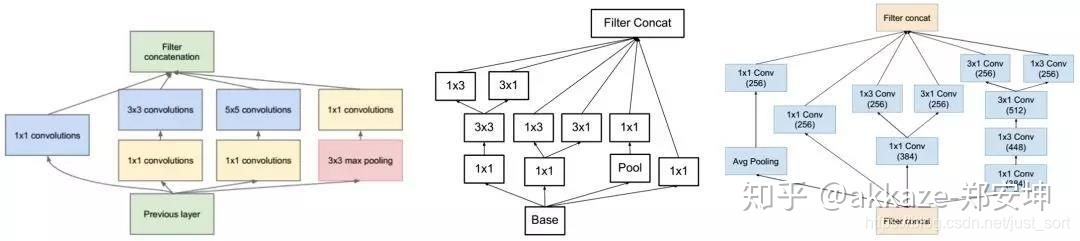
使用通道注意力,比如squeeze and excitation attention
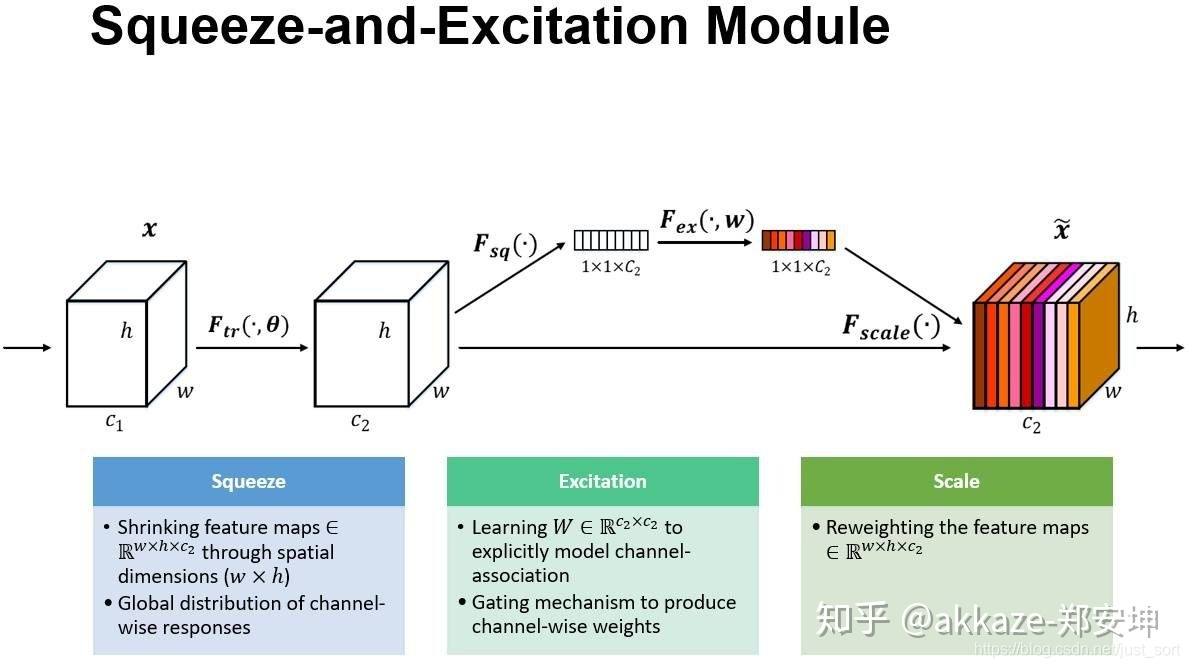
事实上,senet是hrnet的一个特例,hrnet不仅有通道注意力,同时也有空间注意力
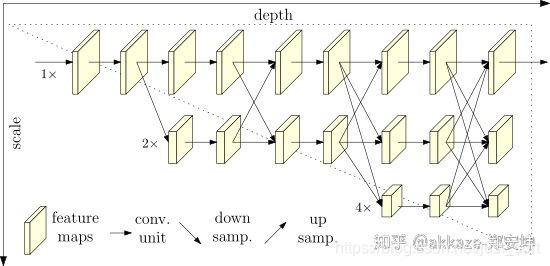

多尺度处理方法¶
图像金字塔,这种属于在输入侧处理,使用的越来越少了。
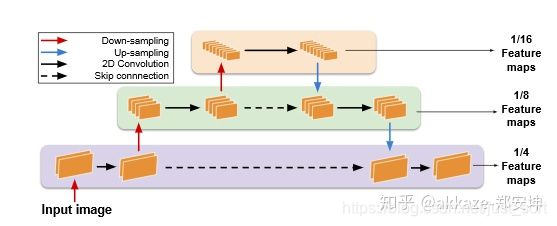
所有的跨层连接本质上都是在做多尺度处理,这里面有resnet的shortcut,fpn,和unet的encoderdecoder,这些跨层连接都能融合尺度信息,也包括densenet的dense connect。
分割篇¶
分割同时需要大感受野和高分辨率,分割的感受野要和物体大小相当,当然稍微小一些影响不大,另外注意分割一定需要background,这对于全卷积landmark模型也是一样,需要backgroud,这两个任务比较相似,都是需要大感受野和高分辨率。
分割网络最后面完全可以使用不采样的空洞卷积来做,这样可以同时保证感受野和分辨率,但是空洞卷积尽可能用在后面,因为前面使用下采样能够减少很多计算量,到了最后面使用空洞卷积计算量不会增大很多,但是后面的分辨率更重要,如果使用下一次,分辨率会下降的非常厉害,比如图像下采样到一定地步基本就丧失分辨能力了。

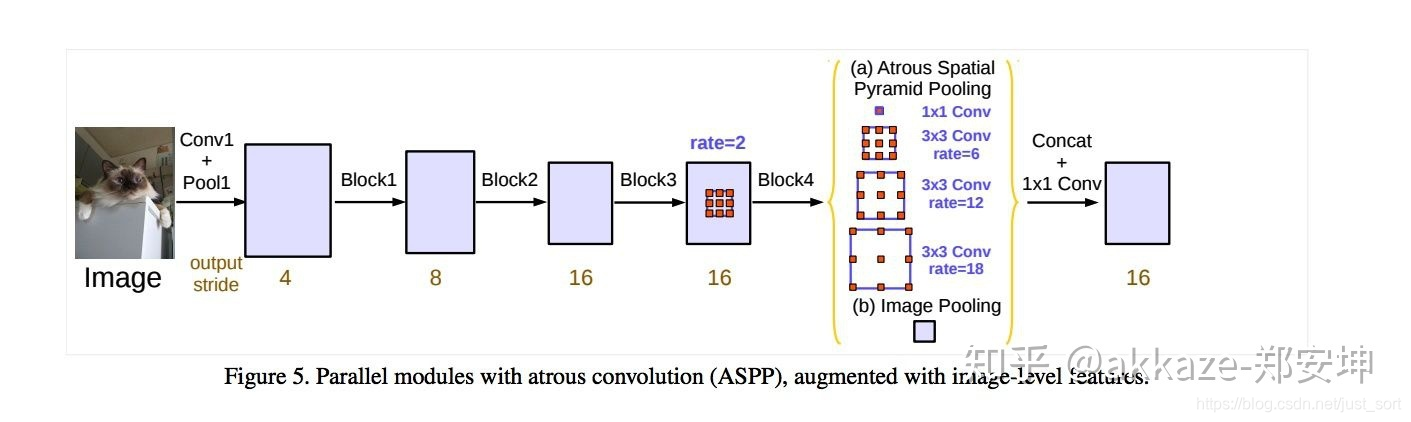
空洞卷积不能乱用,感受野缓慢增大是必须的,这样才能建模各种距离的空间相关性。aspp模块一般都用在网络很后面,用来建模不同的scale。空洞卷积和下采样都会损失图像细节,都能增大感受野,这两点是相同的,但是空洞卷积能保证分辨率,所以对于landmark可以更多的使用空洞卷积,语义分割相应地要少一些,因为分割很重视细节。另外在两个下采样之间的子网络里也可以使用空洞卷积,这样可以减少层数,尤其在子网络越靠近后面的时候,另外landmark使用空洞卷积的频率应该高一些。
fastfcn提出了模块jpu,它可以试作分割里的fpn,它的能大幅减少分割的计算量
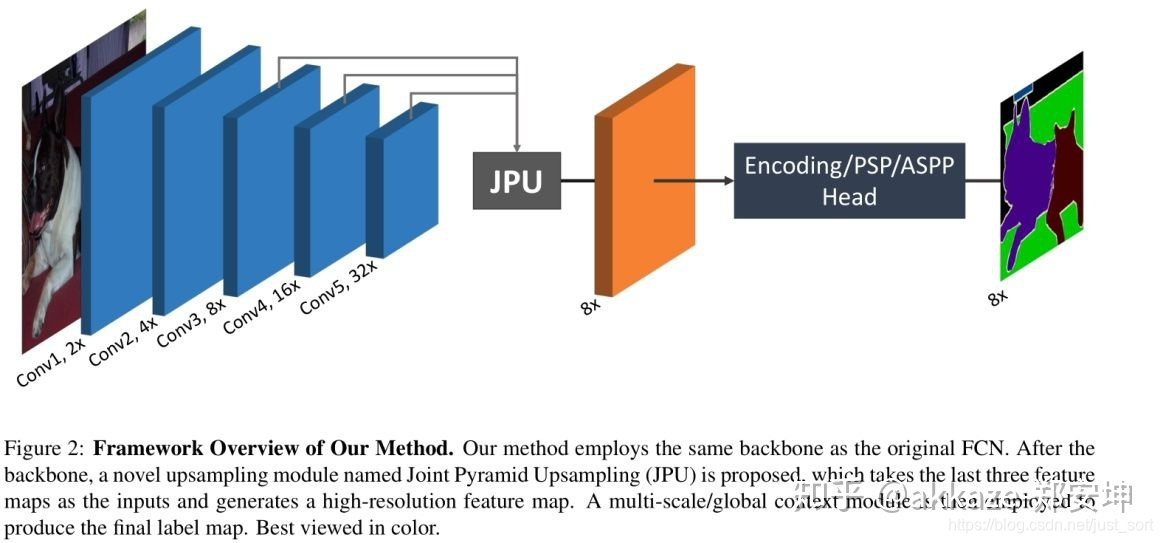
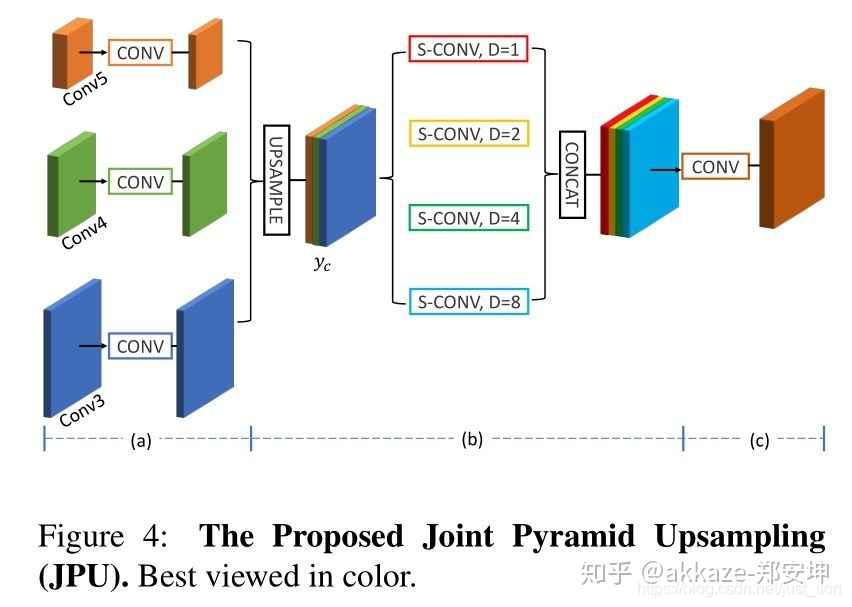
转置卷积完全可以使用上采样+卷积来替代。
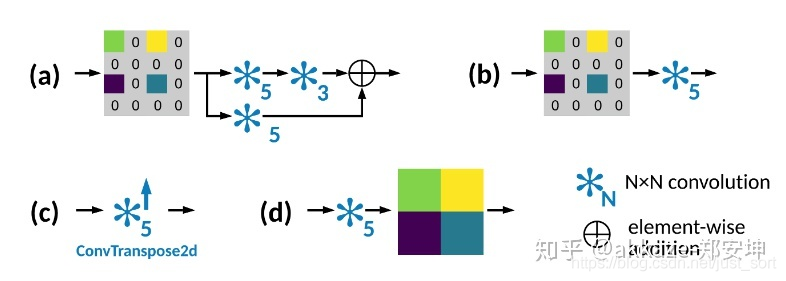
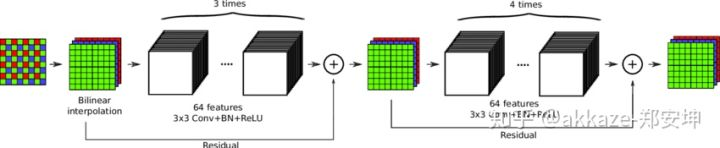
这四种上采样方法里面,a的性能最好,但是计算量最大,b的计算量也很大,b和c本质上是等价的,但是b的计算量更大,这工程实现的原因,c和d的计算量相当,但是c很容易产生棋盘格现象,d如果使用小卷积核计算量会更小。
a和b还有更加快速的版本,可见
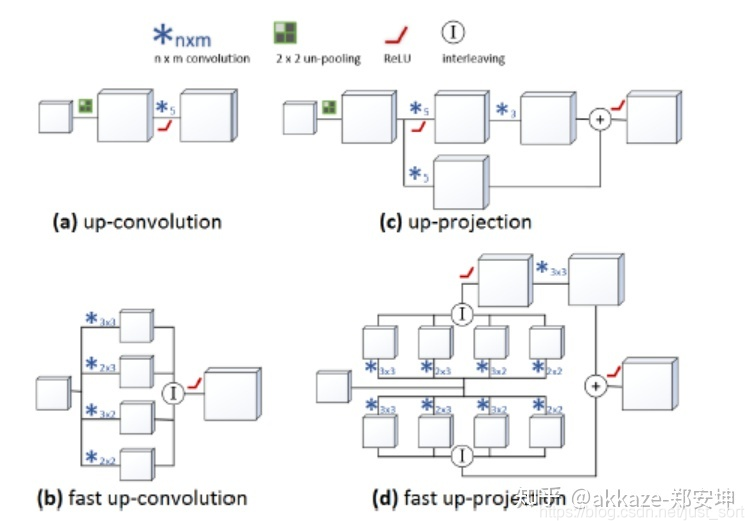
interleaving的实现如下,可以参见tensorflow的depth_tospace或者pytorch的pixel_shuffle,这就是子像素卷积
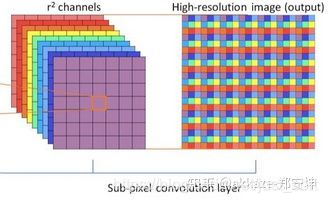
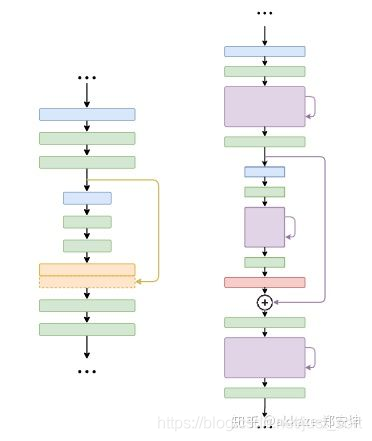
对于分割模型而言,在encoder和decoder之间使用长跳转连接,在encoder和decoder内部使用短跳转连接,尤其是encoder比较深的情况下,通常说来,长跳转连接的作用更多的是为了恢复分辨率,短跳转连接的作用更多是为了防止梯度消失。
low-level篇¶
感受野也不是越大越好(大感受野意味着更多的语义信息),对于某些low-level的任务而言,比如图像降噪,感受野可能也就局部patch大小,对于low-level而言,下采样的意义更小,尽可能少使用下采样。
检测篇¶
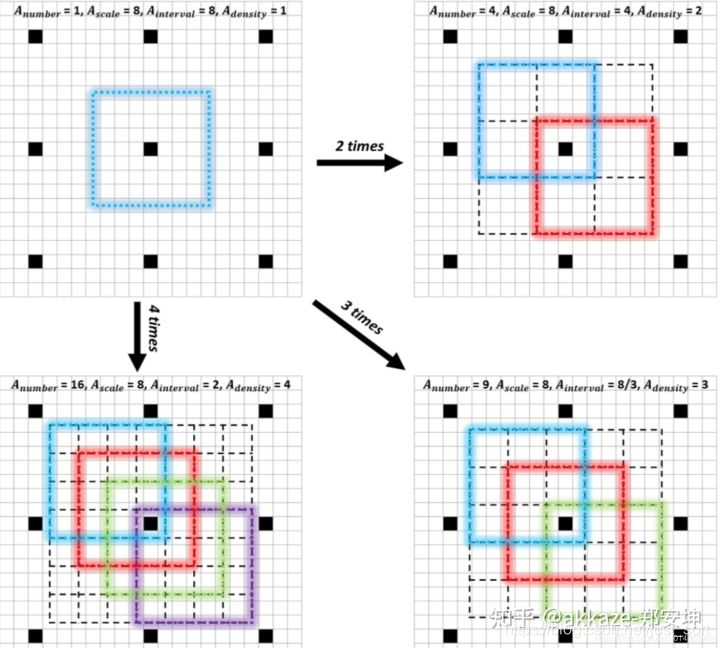
对于检测,anchor层不一定要有三层,同一层按照需求可以设定的aspect ratio和size都是可选的,比如blazeface使用两层anchor,这个要按照需求设计,事实上不同的层其实代表着不用的scale,三层就是三个scale,两层就是两个scale,一般说来scale分为大中小三种,但是依具体情况而变,主要取决于数据集中的scale分布(这点可能需要修改了,因为根据最新的论文,可能不需要铺更密的anchor,但是需要新的采样算法)。
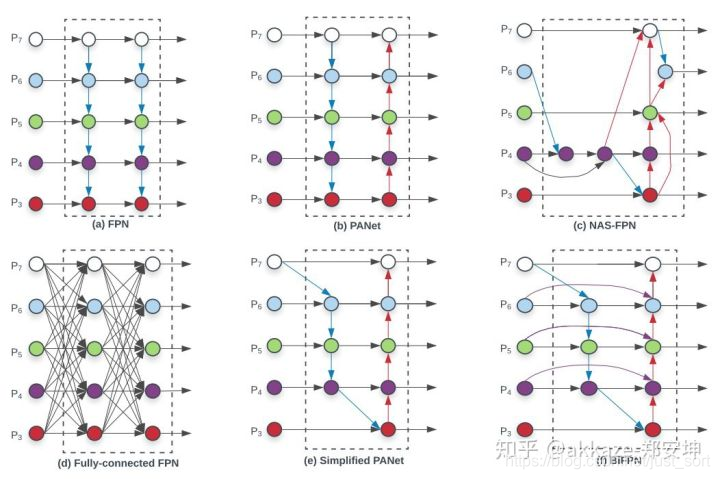
bifpn真的有用,性能有提升且计算量小。
batchnorm一定要用,如果你是多机多卡,也可以考虑同步的batchnorm。
如果你的一阶段检测模型得不到好的分类结果,考虑两阶段,先检测再分类。
检测模型里的预训练模型是有用的,至少能提升前景背景的检测区分度。
anchor free暂不讨论,以后再添加,因为anchor based方法效果已经不错了,并且工程上非常成熟。另外请记住,密集检测没法完全做到anchor free,因为事实上检测目标的可能的位置和宽度高度的分布范围太广 ,所以必须要加上限制,而这个限制本质上就是anchor,另外anchor很容易推广到3d检测。

metric learning篇¶
metric learning(图像比对)一般说来是batchsize更大会性能更好,因为这样能采样到的正负样本对的范围更大。

分类篇¶
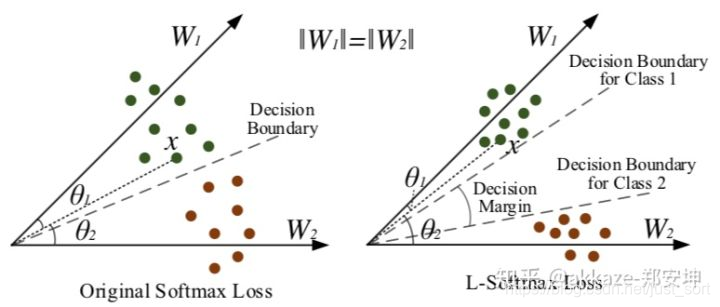
如果你的分类精度不够是因为有两类或者多类太相近造成的,考虑使用其他softmax,比如amsoftmax。
如果你的分类精度不够是样本不均衡造成的,考虑使用focal loss。
不要只看精度,考虑其他metrics,并始终以上线后的可视化效果为最终评判标准。
landmark篇¶
尽可能使用全卷积网络来做landmark,不要直接用fc回归,回归真的不太稳定。另外,数学意义上的cnn是平移不变的,位置信息是通过padding泄露出来,所以fc直接回归landmark相当于用padding去拟合位置信息,另外回归模型都有着全局感受野,这样相当于没有空间注意力(很难定位到关键信息,除了分类模型,不应该让其它任务拥有全局感受野)。
全卷积回归landmark如有必要一定要考虑part affinity fields的做法。
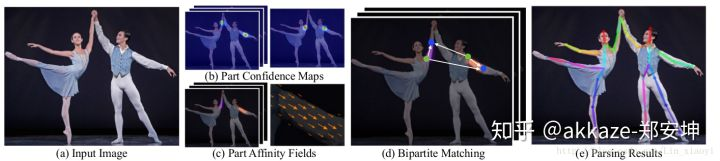
part affinity fields是替代picturiol structure model最好的选择,并且它也是全卷积的,它能极大的提高关节点检测的鲁棒性,它和热度图有类似支持,它也是一个map,但是一般是二维向量(我也在思考一维的可能性),所以一个连接(比如胳膊)相当于一个两通道的featuremap,在连接处有值,这个值就是从一个landmark指向另一个landmark的单位向量。paf对于解决多物体landmark问题非常有用,对于遮挡非常鲁棒。
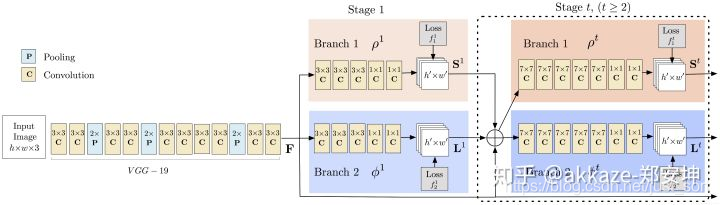
另外,landmark和midlevel中的关键点角点有类似支持,不需要特别大的感受野,只需要在感受野范围中能明显区别出该点,当然更稳健的做法是让感受野和物体大小相当,类似于分割。
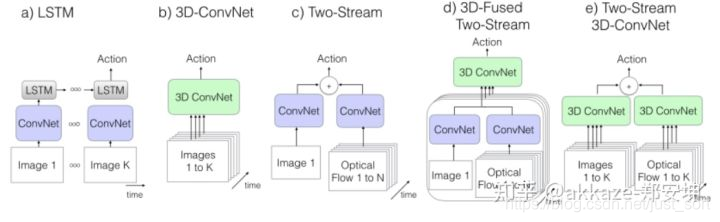
视频理解篇¶
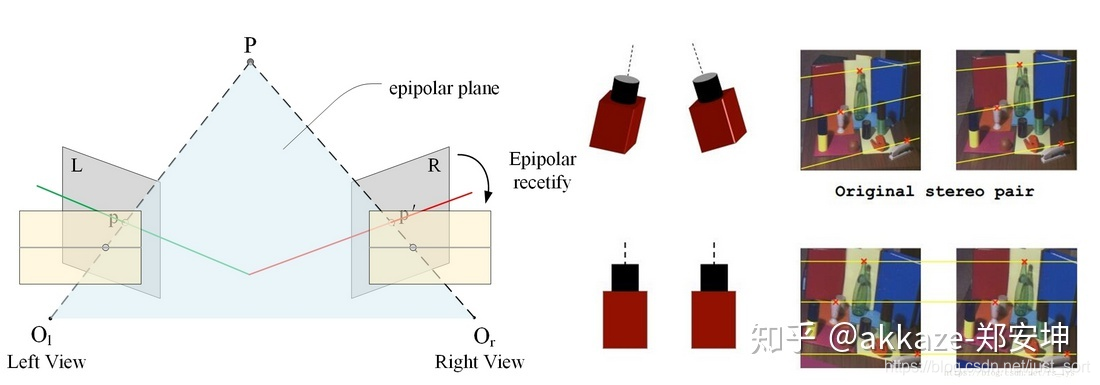
双目篇(立体匹配)¶
这里提醒作立体匹配前必须做畸变校正和极线校正

视差估计一般分为两个阶段,代价初始值计算构建cost volume(cost-volume也是3d的)和代价聚合,在最简单的架构里面,直接在feature-map使用L1或者L2构建cost volume(也叫做distance-based cost volume)
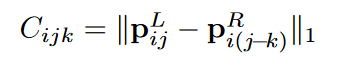
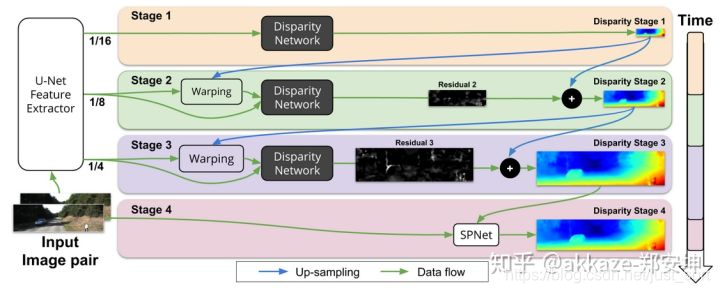

3d卷积负责代价匹配的代价其实很大,因为3d卷积的计算量其实比较大。
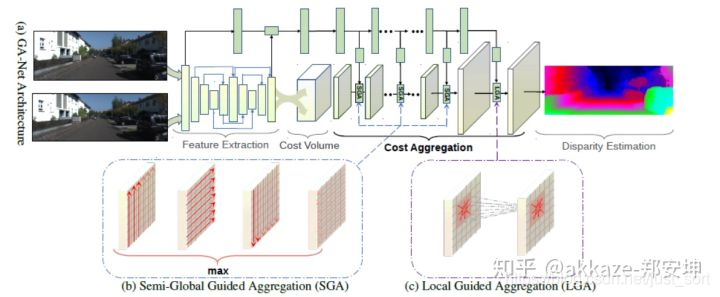
GANet借鉴sgm(semi-global matching)算法的思想,使用如下公式来进行代价聚合,
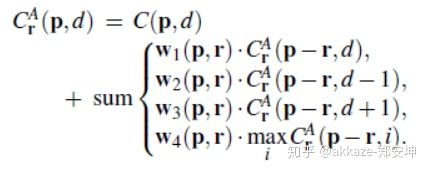
3D篇¶
lidar篇
lidar最为特殊,因为它的输入是分布不均匀的空间点集,也就是点云,不像2d图像或者3d视频那样,均匀分布。
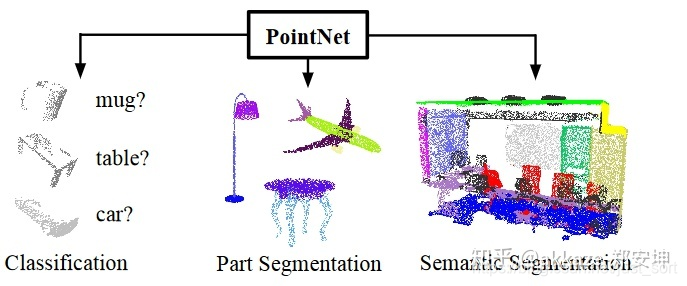
点云存在的问题:
- 无序性:点云本质上是一长串点(nx3矩阵,其中n是点数)。在几何上,点的顺序不影响它在空间中对整体形状的表示,例如,相同的点云可以由两个完全不同的矩阵表示。
- 相同的点云在空间中经过一定的刚性变化(旋转或平移),坐标发生变化,我们希望不论点云在怎样的坐标系下呈现,网络都能得到相同的结果。
也就是说我们希望点云上的神经网络同时具有点集置换不变性和刚性不变性
pointnet的做法,保证置换不变性,去拟合一个对称函数,对称函数有置换不变性,比如x1+x2,同理x1-x2没有置换不变性

为了保证刚性不变性,类似于spatial transformer network的做法,用一个旁支去拟合一个刚性变换,
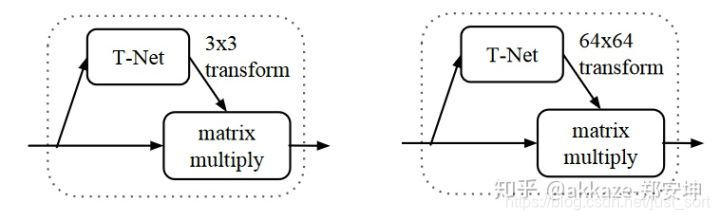
所有的拟合都是通过mlp进行的,
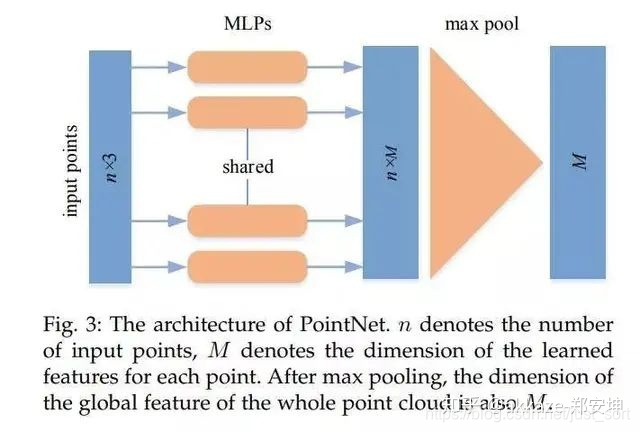
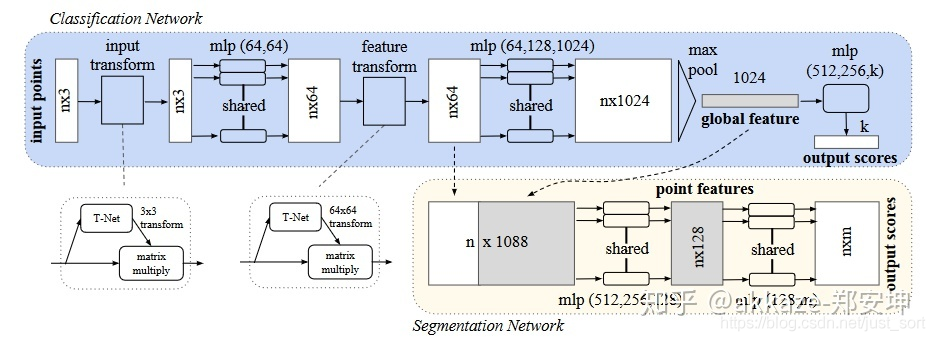
pointnet不是卷积神经网络,在19年的cvpr上,有这样一篇论文,叫pointconv,它实现了点集上的卷积
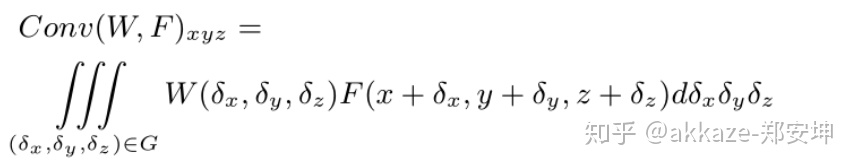
其中,W 和 F 均为连续函数,(x,y,z)(x,y,z) 是 3D 参考点的坐标,(δx,δy,δz)(δx,δy,δz) 表示邻域 G 中的 3D 点的相对坐标。上式可以离散化到一个离散的 3D 点云上。同时,考虑到 3D 点云可能来自于一个不均匀采样函数,为了补偿不均匀采样,使用逆密度对学到的权重进行加权。PointConv 可以由下式表示,
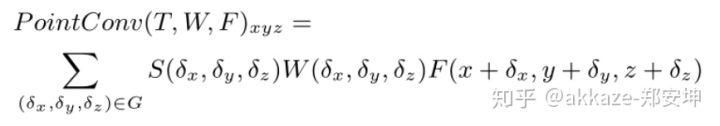
离散化后如下所示
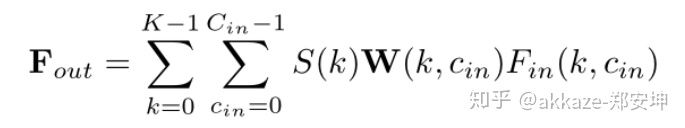
其中,S 表示逆密度系数函数。连续函数 W 可以用多层感知器(MLP)近似。函数 W 的输入是以 (x, y, z) 为中心的 3D 邻域内的 3D 点的相对坐标,输出是每个点对应的特征 F 的权重。S 是一个关于密度的函数,输入是每个点的密度,输出是每个点对应的逆密度系数。这个非线性的函数同样可以用一个多层感知机近似。
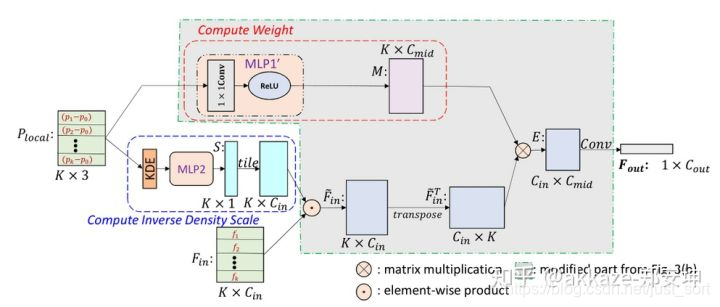
pointconv是真正的卷积操作,可以期待以后在其上可以做3d分类,分割,检测,和2d卷积网络使用方法几乎一致。
多任务篇¶
很多任务本来就是多任务的,比如检测相当于同时做bbox回归和分类,实例分割相当于同时做语义分割和目标检测
数据增强篇¶
一定要做图像亮度变换增强,亮度鲁棒性会更好,但是要结合你的数据的亮度分布自适应的调整。
最后,在不改动网络backbone的基础上,多尝试一些新的loss,工程上的代价并不大。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次