不需要训练来纠正文本生成图像模型的错误匹配
推荐阅读: - 一文弄懂 Diffusion Model - 35张图,直观理解Stable Diffusion - 如何简单高效地定制自己的文本作画模型? - Diffusion Model的演进 NeurIPS 2022最佳论文:Imagen
1. 论文信息¶
标题:Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis
作者:Weixi Feng, Xuehai He, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, William Yang Wang
原文链接:https://arxiv.org/abs/2212.05032
代码链接:https://github.com/weixi-feng/Structured-Diffusion-Guidance
2. 引言¶
Stable Diffusion这一text-to-image的强大开源模型,为从文本生成高分辨率图像提供了新的机会。而除了直接从文本中生成生成高分辨率的图像之外,将多个对象组合成连贯场景的能力也必不可少。 实现这种能力需要模型从提示中理解完整的提示和个别语言概念。 因此,该模型应该能够结合多个概念并生成从未包含在训练数据中的新对象。 在这项工作中,我们主要关注提高生成过程的组合性,因为在复杂场景中实现具有多个对象的可控和通用的文本到图像合成至关重要。
尽管在同一场景中生成多个对象方面有所改进,但现有模型在给出诸如“白色建筑物前的棕色长凳”之类的提示时仍然会失败,如下图, 输出图像包含“白色的长凳”和“棕色的建筑物”,这可能是由于训练集中存在一定的bias,或者甚至训练集中的语言理解模式就是不准确的。 解释和解决这样的对象绑定是非常有挑战的,同时也是一个机遇,能帮助我们理解具有多个对象的的复杂prompt。 因此,完成把属性绑定到正确的对象上,是我们实现更复杂和更可靠的高质量图像生成的关键步骤。

尽管最先进的text-to-image模型是在大规模文本图像对这种模式的数据集上训练,但它们仍然会因类似于上例的简单提示而出现不准确的结果。所以设计一种替代的、数据高效的方法来提高组合性。 我们观察到attribute-object的relation对可以作为文本中,从句子的树中免费获得。 因此,我们建议将提示的structural representation(例如region tree或scene graph这种结构化的场景描述)与diffusion这一过程相结合。 文本的编辑仅仅是对整个图像的某一特定区域进行描述。 其实在DALL-E和stable diffusion这种超强的预训练模型流行之前,通常,我们需要坐标 (bounding boxes) 等空间信息作为输入,将它们的semantic映射到相应的图像区域中。 但是,现有的基于大模型的T2I 方法无法解释坐标输入。 因此,论文提出利用attention map在训练好的 T2I 模型 citep中提token-region associations的观察结果。 通过修改交叉注意力层中的key pair,可以完成每个文本的编码,然后把其映射到二维图像空间中的,从而完成编辑。
在这项工作中,作者在 Stable Diffusion中发现了类似的观察结果,并利用该属性构建结构化的cross-attention guidance。 具体来说,我们使用语言解析器从提示中获取层次结构。 我们提取跨所有级别的文本,包括视觉 concepts和entities,并对它们进行单独编码,以将属性-对象对彼此分开。与使用单个文本嵌入序列进行指导相比,我们通过多个序列提高了组合性,其中每个序列都强调结构化语言表示中来自多个层次结构的实体或实体的并集。 我们将我们的方法称为结构化扩散指导 (StructureDiffusion)。 我们的贡献可以概括为三方面:
- 提出了一种直观有效的方法,通过利用语言输入的结构化表示来改进组合文本到图像的合成。 我们的方法高效且无需训练,不需要额外的训练样本。
- 实验结果表明,我们的方法在生成的图像中实现了更准确的属性绑定。 我们还提出了一新基准来衡量 T2I 模型的组合性能。
- 通过大量的实验和分析,确定了不正确的属性绑定的原因,这指出了提高文本到图像合成的可靠性和组合性的未来方向。
3. 方法¶
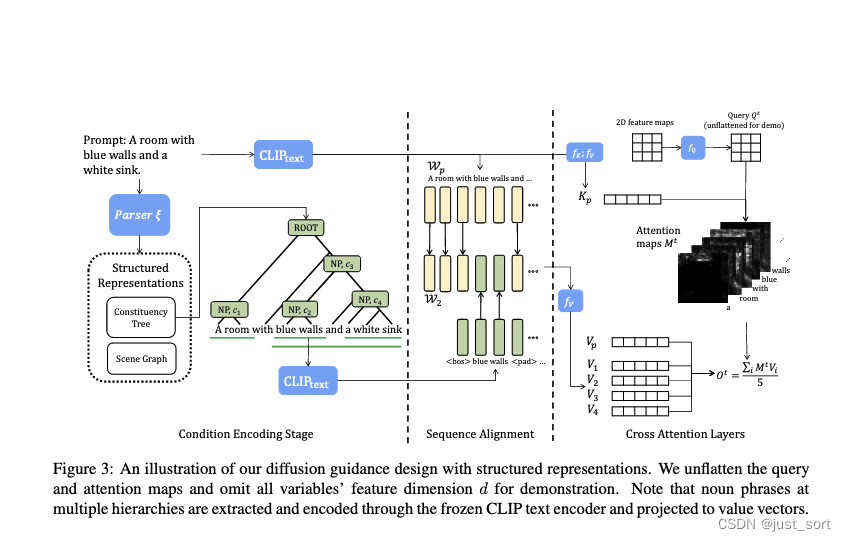
Stable Diffusion和CLIP大家应该都比较熟悉,直接介绍本文主要研究的cross-attention的这一操作。
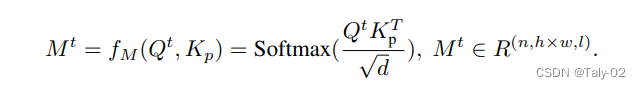
就是对不同的K和Q进行match面积算他们的attention值,这样就可以做到非一一对应,而可以完成不同的文本到属性之间的匹配。而怎么完成编辑呢?在Google的Imagen中,有观察是空间布局取决于交叉注意力图。 这些映射控制生成图像的布局和结构,而key包含映射到相应的描述区域的丰富语义。 因此,可以假设图像布局和内容可以通过分别控制attention map和key来分离。
本文的做法就是先把描述文本内容的prompts进行分解,然后对每一个层级进行相应的编辑和生成。
首先第一步是把prompts中的若干名词给提取出来,它们分别代表某个区域中的内容,然后用CLIP进行文本信息的编码:

然后就是在每一个cross-attention layer中完成映射,来对相应的属性进行绑定:

之后对这种结构进行重复和feedward:
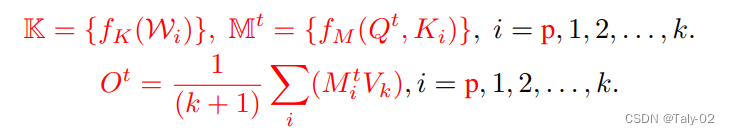
算法的步骤描述如下,整体比较清晰简单:

4. 实验¶

Stable Diffusion这种T2I的模型一直缺少指标来进行比较,本文提出了Alignment和Fidelity来描述相应的Diffusion model的性能。实际上就是看生成的图像和文本描述match与否然后看能不能从海量图像中给检索出来。

在ABC-6K中表现可以发现很好地解耦了匹配了场景和对象。

整体的风格把握也比较到位。
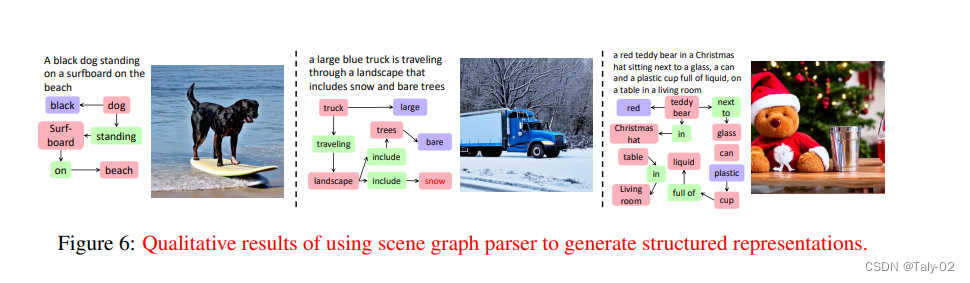
完成的场景图抽取也非常到位。
5. 结论¶
在这项工作中,论文提出了一种用于组合文本到图像生成的training-free方法。 首先,作者观察到现有的大规模 T2I 扩散模型在合成图像合成中仍然存在困难。 然后通过明确attention具有正确属性的对象,来完成他们之间的绑定来解决。 其次,我们提出将语言结构纳入交叉注意层的guidance中,可以更准确地绑定属性,同时保持整体图像质量和多样性。 通过对冻结text encoder和attention map进行深入分析来实现。 希望本文的方法能够加速开发基于扩散的文本到图像模型的可解释和有原则的方法。
本文总阅读量次