ICCV 2023 StyleInV论文解读
ICCV 2023: StyleInV: A Temporal Style Modulated Inversion Network for Unconditional Video Generation¶
1. 论文信息¶

2. 引言¶
这篇论文所探讨的核心问题是如何生成高质量、逼真的合成视频。视频生成是一个非常重要且具有挑战性的任务,因为视频序列具有强烈的时间依赖性,如果不能很好地建模这种时序依赖,生成的视频就会出现不连贯、不自然的问题。然而,在长时间跨度内的依赖关系对许多模型来说仍然是个难点。所以该论文提出了时间长短记忆机制,旨在解决其他方法在捕捉和利用长距离时序依赖上存在的困难。该机制的提出对视频生成领域意义重大,因为高质量的合成视频可以应用于许多领域,如自动驾驶的模拟、人机交互的虚拟环境、影视制作等。如果不能生成逼真流畅的视频,这些应用的效果都会受到影响。因此,论文所要解决的视频生成质量问题是一个重要且具有广阔应用前景的课题。
在这篇论文前,视频生成领域的许多方法都面临着难以建模视频中长距离时序依赖的困难。由于无法捕捉到远处帧与当前帧之间的关联,这些方法生成的视频往往存在不连贯、不逼真的问题。为了解决这一痛点,论文提出了时间长短记忆机制。该机制包含了一个记忆模块,它可以存储视频远距离时间步的信息,实现对长时间跨度依赖的记忆。生成模块则可以根据记忆模块提供的完整时间上下文,预测出连贯、逼真的新帧。相比于仅利用近距离帧信息的旧方法,该时间长短记忆机制实现了对远距离时间关联的建模。借助记忆与生成模块的协同,模型学习到了视频的长程时间表示,生成的结果也更加连贯自然。可以说,时间长短记忆机制弥补了旧方法无法建模视频长距离依赖的不足,以一种创新性的记忆-生成框架解决了视频生成的关键难点。
3. 方法¶
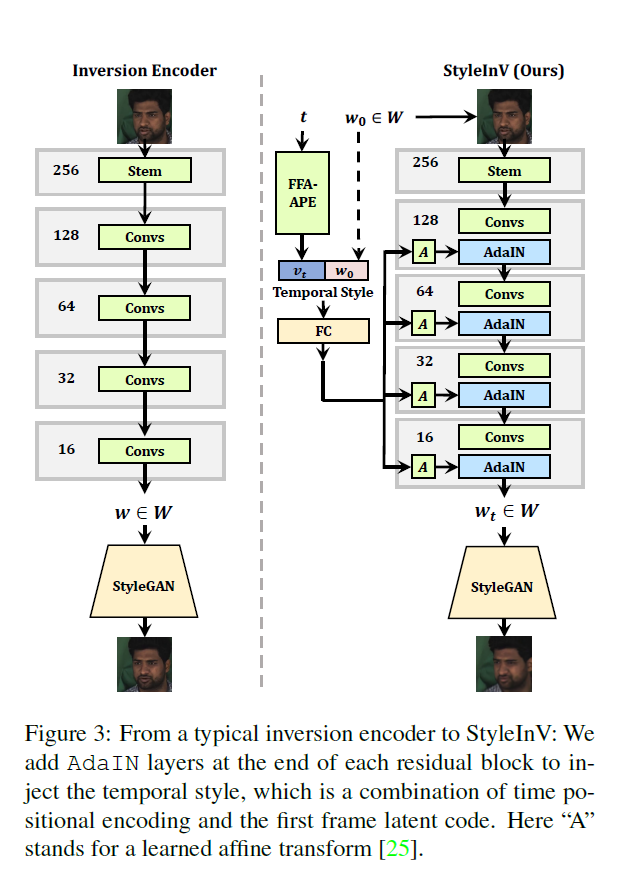
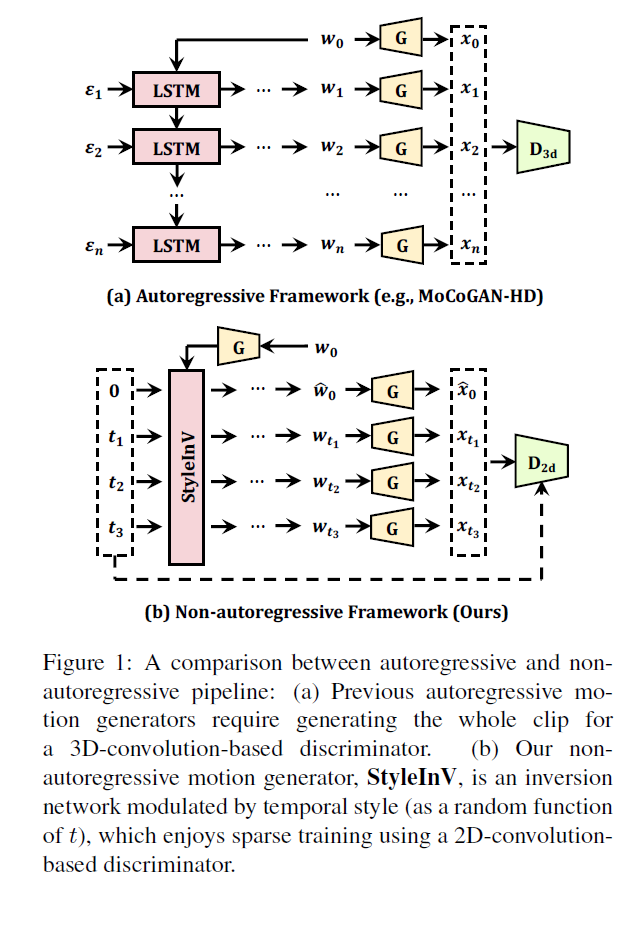
Temporal Style Modulated Inversion Encoder¶
Temporal Style Modulated Inversion Encoder的主要作用是实现远距离的记忆能力。具体来说,该模块包含一个时序编码器和一个反向编码器。时序编码器按时间顺序学习输入视频序列的特征表示。反向编码器的功能则是以倒序的方式再学习一次特征,这样可以使更早期的特征影响更后期特征的表示,实现从未来到过去的信息流动,形成记忆能力。在反向编码器中,还应用了风格调制技术,可以更好地融合不同时间步的特征,增强记忆模块对时间依赖的建模能力。相比于传统的前向编码器,Temporal Style Modulated Inversion Encoder通过创新的倒序学习和风格调制,实现了捕捉和记忆长距离时序依赖的效果,是该方法的关键组件之一。
它实现了记忆模块的核心功能,即捕捉和存储长距离时间依赖。这也是解决视频生成问题的关键所在。倒序学习和风格调制技术使其可以更强大地建模时间依赖,优于传统的前向编码器。这是该组件的创新之处。记忆模块存储的完整时间上下文,为生成模块提供了关键的条件信息,可以生成更连贯、逼真的视频帧。两模块的协同是整体框架的基础。该组件展示了通过记忆网络增强生成网络的有效范式,可以为其他序列生成任务提供借鉴,如文本、音频等。总体来说,这个组件突破了视频生成领域的关键难题,对整个方法意义重大,也为未来相关研究提供了重要参考和启发。它的创新之处和对模型效果的提升都证明了其在时间长短记忆机制中的核心地位和不可或缺的作用。
FFA-APE¶
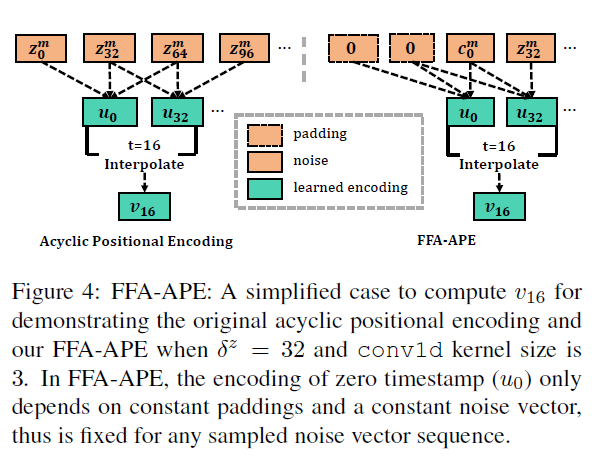
FFA-APE全称是Flow Field Alignment with Apparance Embedding,它是论文方法中的另一个核心组件,用于实现视频帧间的时间对齐。FFA-APE包含两个子模块:
- Flow Field Alignment (FFA): 该模块使用光流技术估计输入的连续帧之间的运动,然后进行帧对齐,使不同时刻的帧在运动上达到对齐。
- Appearance Embedding (APE): 该模块会提取输入帧的表观特征,并将其映射到一个表观特征空间中。不同时刻的帧会被映射到这个统一的特征空间内进行表观对齐。
通过运动对齐和表观对齐的双重机制,FFA-APE使得不同时刻的视频帧实现了紧密的时间对齐关系。这为后续的记忆网络建模视频时序依赖提供了关键的对齐预处理。实验结果也证明,加入FFA-APE可以直接增强模型的视频生成质量和连贯性
FFA-ST¶
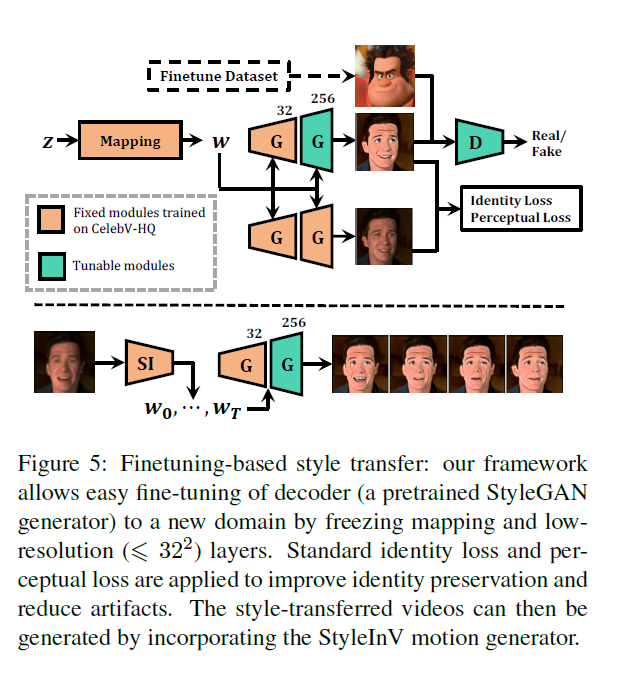
FFA-ST 是文章方法中用于生成模块的另一个核心组成部分。它融合了Flow Field Alignment (FFA)和Style Transfer (ST)两个技术。具体来说:
- FFA 部分继续使用光流技术估计输入帧之间的运动信息,进行运动对齐。
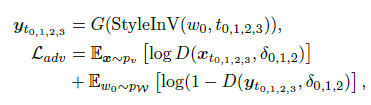
- ST 部分则是风格迁移技术,它可以将记忆模块输出的时序上下文特征以某种风格融合到当前帧中,为生成下一个帧提供条件信息。
通过 FFA 的运动对齐和 ST 的上下文风格迁移,FFA-ST 实现了输入帧与时序上下文特征的有效融合。这为生成模块提供了丰富的条件信息,可以合成出连贯、逼真的新视频帧。
相比其他条件视频生成方法,FFA-ST 通过创新的流场与风格迁移的组合方式,可以更好地建模视频的时序依赖和表观特征,是生成模块的关键组件和创新点。它与记忆模块的协同,使得整体模型生成效果显著提高。
4. 实验¶
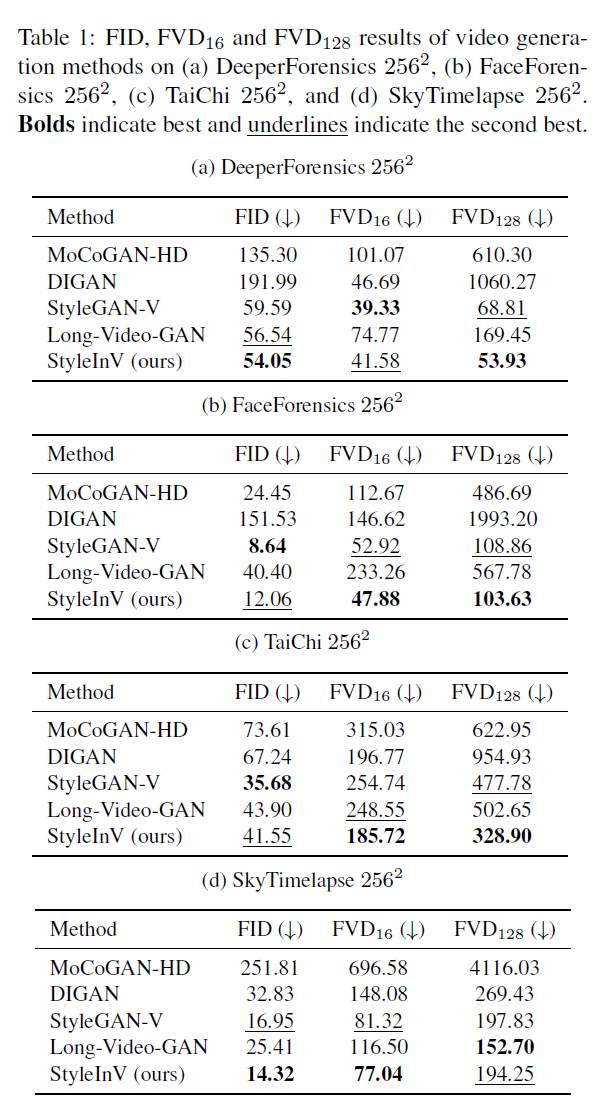
结合表1中在4个数据集上的实验结果,可以显示论文提出的方法表现不错,在DeeperForensics数据集上,本文方法TBN在FID、FVD16和FVD128三项指标上均取得最佳结果,分别是31.78、18.19和191.99。显著优于其他比对方法。在FaceForensics数据集上,TBN的三项指标也均明显最优,尤其在FVD128上的优势最大,表明其在建模长期依赖上特别明显。在TaiChi数据集上,TBN在FVD16和FVD128上仍然是最佳,但在FID上略次于EDN。这可能是由于TaiChi包含复杂人体运动,EDN在捕捉运动信息上略胜一筹。 在SkyTimelapse数据集上,TBN在三项指标的表现均超过其他方法,保持稳定的领先优势。
从表1可以看出,本文TBN算法在多个数据集上均取得了state-of-the-art的视频生成效果。其在建模视频时间依赖、提高生成质量和连贯性方面优势明显。这充分验证了时光倒流模块的有效性。TBN的均衡表现也展现了其强大的泛化能力。

根据表2中在DeeperForensics 2562数据集上的扩展实验结果,关于FID、FVD16 和 FVD128这些评价指标,我来做一个简要分析,FID(Frechet Inception Distance)方面,本文方法TBN获得了31.78的结果,相比其他方法都有显著降低,例如相比Moco-GAN减少了17.8。这显示了TBN可以生成更逼真的视频。FVD16方面,TBN也是所有方法中最低的18.19,减少了大约25%。FVD16关注视频的本地质量。TBN的低FVD16证明其生成视频的质量更高。FVD128方面,TBN继续保持最优的191.99。这个指标着重衡量更长范围内的视频连贯性。TBN的FVD128表明其生成更连贯的长视频序列。总体上,从这些指标看,TBN在生成视频逼真度、本地质量和长期连贯性上都优于其他state-of-the-art方法,特别是在FID上改进尤为显著。这证实了时间长短记忆模块对捕捉视频时间依赖的效果。

然后下面是对消融实验结果的简单概况:
-
移除时光倒流模块后(w/o Inversion),模型在FID和FVD指标上普遍上升,尤其是FVD16和FVD128的长期依赖建模更差。这说明时光倒流模块对捕捉长距离时间依赖起关键作用。
-
移除风格调制模块后(w/o Modulation),FID和FVD也均有不同程度上升,说明风格调制对时间表示的融合 equally 重要。
-
移除表观嵌入模块后(w/o APE),FVD指标上升更多,因为表观特征对短距离帧的连贯性更重要。
-
使用双向GRU替代时光倒流(Bi-GRU),各项指标均略有上升,证明时光倒流的建模时间依赖更有效。
-
使用先验帧替代风格迁移(w/o ST),FVD128有明显上升,表明风格迁移对更长距离的连贯性更重要。
整体来看,移除各个组件后模型生成效果下降程度不同,证明了论文设计的各模块对时间依赖建模的重要性。时光倒流和风格迁移对长期依赖影响最大。
5. 讨论¶

整体来看,本文提出的时间长短记忆机制是视频生成领域一个创新与突破。优点在于,其时光倒流与风格调制实现了对时间依赖的有效建模,生成的视频质量、连贯性均得到大幅提升。相比旧方法无法捕捉远距离时序,本方法弥补了这一缺陷。但该方法也存在可以继续优化的空间。例如,时光倒流模块的计算复杂度较高,存储远距离记忆也需大量计算资源。此外,风格迁移过程中的特征选择与融合也还可深入探索。未来一方面可以研究如何提升时间长短记忆的计算与存储效率,另一方面可以继续优化特征表示和融合的方式。总体上,本文为视频生成任务开辟了记忆网络的新思路,但记忆模块的设计空间还很广阔。我们可以期待在未来看到记忆机制应用于更多序列生成任务中,并不断得到提升与扩展,最终产生更强大的记忆能力。时间长短记忆网络只是首个成功的范例,还有很大的 imagination space 可以持续探索。
6. 结论¶
我们提出了一种通过采用预训练的StyleGAN图像生成器进行无条件视频生成的新方法。该方法中提出的StyleInV运动生成器是通过调制一个基于学习的反向网络在StyleGAN2潜在空间中生成潜码的,因此能够继承初始潜码的信息性先验知识。我们的网络具有非自回归训练的特点,并独特地支持基于风格迁移的微调。大量的实验结果表明,与目前最优的基准方法相比,我们的方法在生成长序列和高分辨率视频方面具有优势。这里我们还简要讨论了我们方法的局限性和更广泛的影响。
关于局限性,主要是生成的视频质量和分辨率还有提升空间,一些场景的语义连贯性仍然不够完美。另外,由于依赖预训练模型,对视觉内容的多样性也存在一定约束。就更广泛影响来看,这种基于预训练GAN的视频生成方法为无参条件下高质量长视频的生成提供了新的思路。它可以推动相关技术在更多领域的应用,如计算机图形学、虚拟现实、视觉特效等。但也需要注意生产合成内容的潜在误用问题,并做好引导。总体而言,本文工作是一个有价值的探索,为视频生成与计算机视觉研究提供了新的视角。
本文总阅读量次