前言¶
相信各位做算法的同学都很熟悉框架的使用,但未必很清楚了解我们跑模型的时候,框架内部在做什么,比如怎么自动求导,反向传播。这一系列细节虽然用户不需要关注,但如果能深入理解,那会对整个框架底层更加熟悉
从一道算法题开始¶
有算法基础的同学,应该都知道迪杰斯特拉的双栈算术表达式求和这个经典算法。他的原理是利用两个栈分别存放运算数,操作。根据不同的情况弹出栈里的元素,并进行运算,我们可以具体看下图
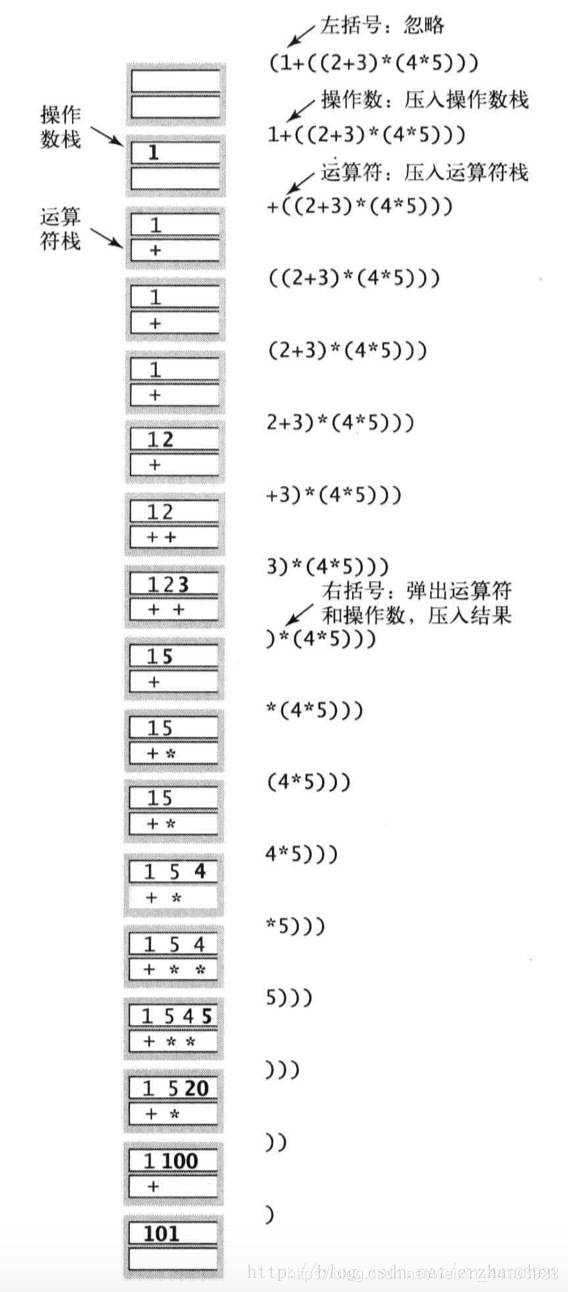
这里讨论的是最简单的情况,我们根据操作符的优先级,以及括号的种类(左括号和右括号),分别进行运算,然后得到最终结果。
神经网络里怎么做?¶
在神经网络里,我们把数据和权重都以矩阵运算的形式来计算得到最终的结果。举个常见的例子,在全连接层中,我们都是使用矩阵乘法matmul来进行运算,形式如下
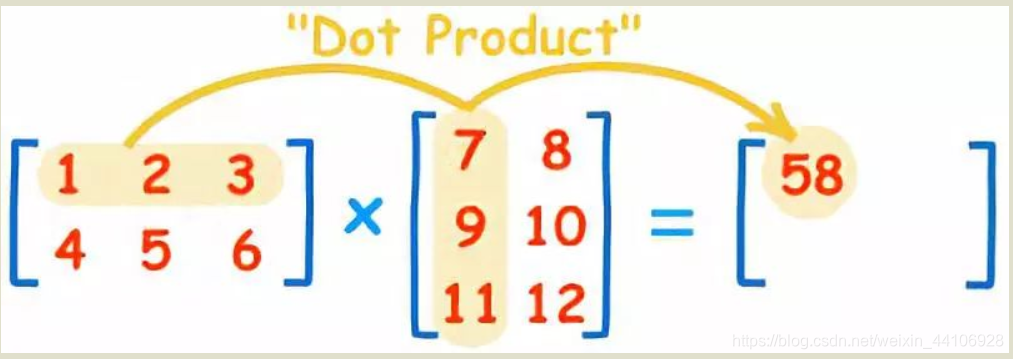
如图,一个(2x3)的矩阵W和一个(3x2)的矩阵X运算出来的结果Y1是(2x2) 那么Y可以被表示为
那后续还有一系列相关操作,比如我们可以假设
这一系列运算,都是我们拿输入X一层,一层的前向计算,因此这一个过程被称为前向传播
神经网络为了学习调节参数,那就需要优化,我们通过一个损失函数来衡量模型性能,然后使用梯度下降法对模型进行优化
原理如下(完整的可以参考我写的一篇深度学习里的优化)
 可以看到最后我们能让loss值变小,这也能代表模型性能得到了优化。
那既然涉及到了梯度,就需要对里面的元素进行求导了。那么应该对谁求呢, 也就是神经网络里的权重W1, W2, W3
可以看到最后我们能让loss值变小,这也能代表模型性能得到了优化。
那既然涉及到了梯度,就需要对里面的元素进行求导了。那么应该对谁求呢, 也就是神经网络里的权重W1, W2, W3
可以观察到,要想求各个权重,就需要从最后一层往前逐层推进。求导得到各个权重对应的梯度,这叫后向传播。 那既然算术表达式可以用双栈来轻松的表达
对于神经网络里的运算,需要前向传播和后向传播,有没有什么好的数据结构对其进行抽象呢?有的,那就是我们需要说的计算图
计算图¶
我们借用图的结构就能很好的表示整个前向和后向的过程。形式如下

我们再来看一个更具体的例子
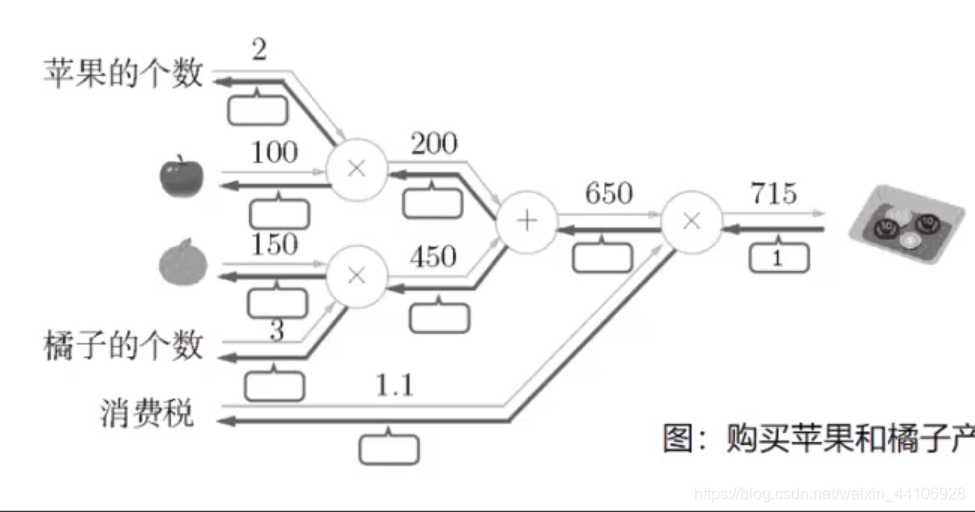
(这幅图摘自Paddle教程。
比如最后一项计算是
则在反向传播中 650这一项对应的梯度为1.1 1.1这一项对应的梯度为650 以此类推。
常见的反向传播¶
卷积层的反向传播¶
这里参考的是知乎一篇 Conv卷积层反向求导 我们写一个简单的1通道,3x3大小的卷积
import torch
import torch.nn as nn
conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=0, bias=False, stride=1)
inputv = torch.range(1, 16).view(1, 1, 4, 4)
print(inputv)
out = conv(inputv)
print(out)
out = out.mean()
out.backward()
print(conv.weight.grad)
最后得到conv的梯度为
tensor([[[[ 3.5000, 4.5000, 5.5000],
[ 7.5000, 8.5000, 9.5000],
[11.5000, 12.5000, 13.5000]]]])
我们3x3 的卷积核形式如下
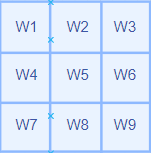
我们的数据为4x4矩阵
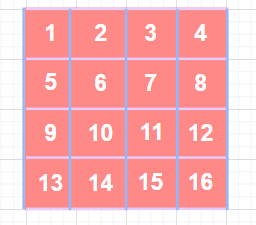
这里我们只关注卷积核左上角元素W1的求导过程 在stride=1,pad=0情况下,他的移动过程是这样的
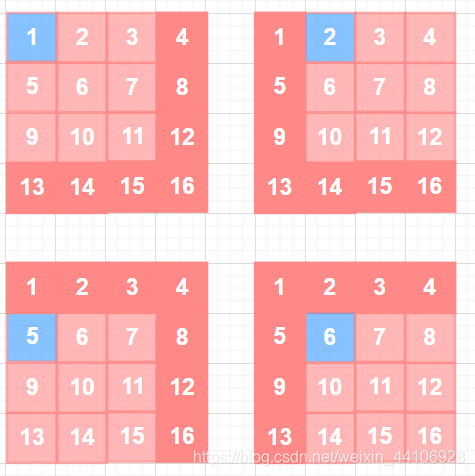
白色是卷积核每次移动覆盖的区域,而蓝色区块,则是与权重W1经过计算的位置
可以看到W1分别和1, 2, 5, 6这四个数字进行计算 我们最后标准化一下
这就是权重W1对应的梯度,以此类推,我们可以得到9个梯度,分别对应着3x3卷积核每个权重的梯度
卷积层求导的延申¶
其实卷积操作是可以被优化成一个矩阵运算的形式,该方法名为img2col 这里简单介绍下
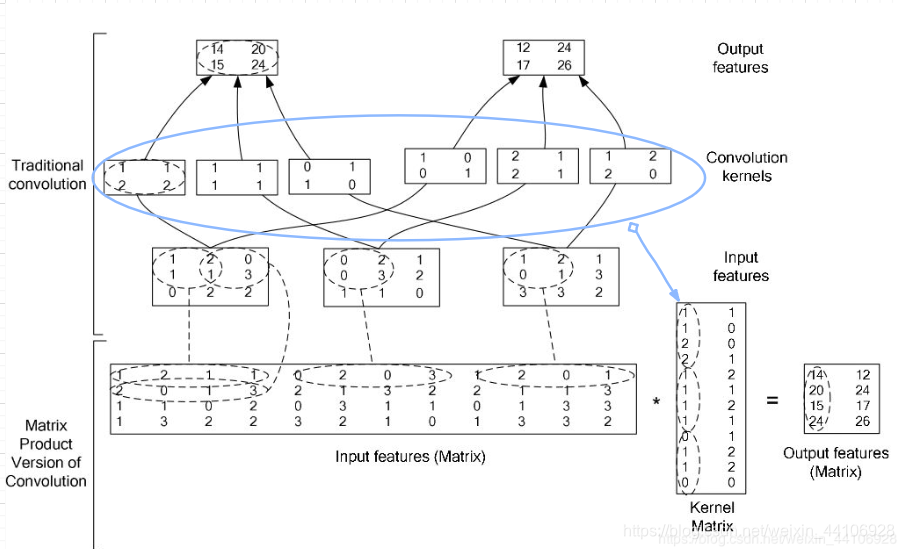
蓝色部分是我们的卷积核,我们可以摊平成1维向量,这里我们有两个卷积核,就将2个1维向量进行组合,得到一个核矩阵 同理,我们把输入特征也摊平,得到输入特征矩阵
这样我们就可以将卷积操作,转变成两个矩阵相乘,最终得到输出矩阵。 而不需要用for循环嵌套,极大提升了运算效率。
池化层的反向传播¶
池化层本身并不存在参数,但是不存在参数并不意味着不参加反向传播过程。如果池化层不参加反向传播过程,那么前面层的传播也就中断了。因此池化层需要将梯度传递到前面一层,而自身是不需要计算梯度优化参数。
import torch
import numpy as np
inputv = np.array(
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16],
]
)
inputv = inputv.astype(np.float)
inputv = torch.tensor(inputv,requires_grad=True).float()
inputv = inputv.unsqueeze(0)
inputv.retain_grad()
print(inputv)
pool = torch.nn.functional.max_pool2d(inputv, kernel_size=(3, 3), stride=1)
print(pool)
pool = torch.mean(pool)
print(pool)
pool.backward()
print(inputv.grad)
注意这里我们打印的是input的梯度,因为池化层自身不具备梯度
tensor([[[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.2500, 0.2500],
[0.0000, 0.0000, 0.2500, 0.2500]]])
其中最大池化层是这样做的
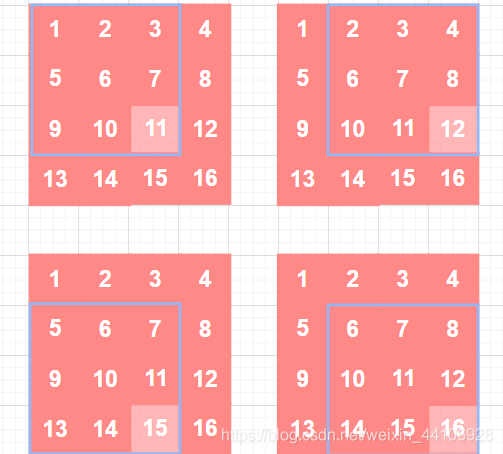
可以看到我们有4个元素进行了最大池化,但为了保证传播过程中,梯度总和不变,所以我们要归一化
也就是
因此最大元素那四个位置对应的梯度是0.25 在平均池化过程中,操作有些许不一样,具体可以参考 Pool反向传播求导细节
静态图与动态图的区别¶
静态图¶
在tf1时代,其运行机制是静态图,也就是符号式编程,tensorflow也是按照上面计算图的思想,把整个运算逻辑抽象成一张数据流图
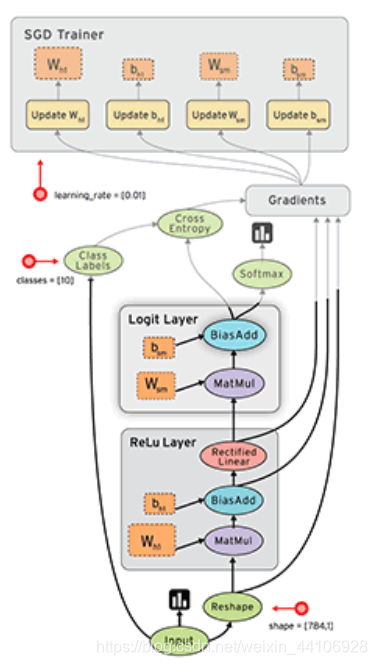
tensorflow提出了一个概念,叫PlaceHolder,即数据占位符。PlaceHolder只是有shape,dtype等基础信息,没有实际的数据。在网络定义好后,需要对其进行编译。于是网络就根据每一步骤的placeholder信息进行编译构图,构图过程中检查是否有维度不匹配等错误。待构图好后,再喂入数据给流图。 静态图只构图一次,运行效率也会相对较高点。当然现在的各大框架也在努力优化动态图,缩小两者之间效率差距。
动态图¶
动态图也称为命令式编程,就像我们写代码一样,写到哪儿就执行到哪儿。Pytorch便属于这种,它与用户更加友好,可以随时在中间打印张量信息,方便我们进行debug。
每一次读取数据进行计算,它都会重新进行一次构图,并按照流程执行下去。其特性更加适合研究者以及入门小白
两者区别¶
- 静态图只构图一次
- 动态图每次运行都重新构图
- 静态图能在编译中做更好的优化,但动态图的优化也在不断提升中
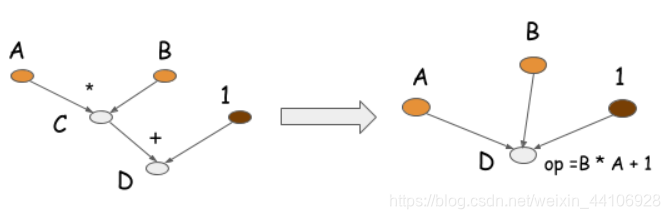
比如按动态图我们先乘后加,形式如左图。 在静态图里我们可以优化到同一层级,乘法和加法同时做到
总结¶
这篇文章讲解了计算图的提出,框架内部常见算子的反向传播方法,以及动静态图的主要区别。限于篇幅,没有讲的特别深入,但读完也基本可以对框架原理有了基本的了解~
本文总阅读量次