CVPR2022:计算机视觉中长尾数据平衡对比学习
【前言】¶
现实中的数据通常存在长尾分布,其中一些类别占据数据集的大部分,而大多数稀有样本包含的数量有限,使用交叉熵的分类模型难以很好的分类尾部数据。在这篇论文中,作者专注不平衡数据的表示学习。通过作者的理论分析,发现对于长尾数据,它无法形成理想的几何结构(在下文中解释该结构)。为了纠正 SCL(Supervised Contrastive Learning,有监督对比学习) 的优化行为并进一步提高长尾视觉识别的性能,作者提出了一种新的BCL(Balanced Contrastive Learning,平衡对比学习)损失。
与 SCL 相比,作者在 BCL 上有两个改进:
- 一个是平衡负样本的梯度贡献,称为类平均;
- 一个是使所有类都出现在每个mini-batch中,称为类补充。
Code:https://github.com/FlamieZhu/BCL
一、过去的方式¶
为了解决数据不均衡的问题,早期的方法有:
- 对训练数据进行重新采样,低采样高频类或过采样低频类;
- 采用加权计算损失函数的方式来关注稀缺类别,为每个类或每个例子的不同的训练样本分配不同的损失;
最近也有一些新研究,如logits补偿方式来校准分布的数据。解耦则是采取一种二阶的训练方案,其中分类器在第二阶段被重新加强训练。然而,对比学习的方法却很少被探索。
二、长尾识别对比学习¶
2.1 监督对比损失¶
在图像分类任务中,通常目标是学习一个复杂函数φ,该函数的映射从一个输入空间X到目标空间 Y=[K]={1,2,...,K}. 其中,函数φ通常实现为两部分,一个是编码器f:X→Z∈R^h,一个是线性分类器W:Z→Y。 最终分类精度在很大程度上取决于Z。因此,作者的目标是学习一个好的编码器f来改进长尾学习。此外,通过引入监督对比损失的定义,以便于以后的分析:对于批次B中表示的z_i,它的每个实例是x_i,监督对比损失函数可以表示为:
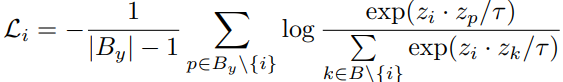
其中By是包含y类的所有样本B的子集(指的是一个批次内的所有样本),进一步定义了B^C_y作为B的补集,T>0是一个温度超参数,控制着相似样品的关联度,而小温度对相似样的关联性性较差。与上式类似,作者还引入了对特定类的批处理损失,如下:
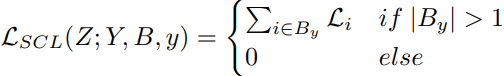
2.2 简单正则构体:¶
当且仅当以下条件成立时:
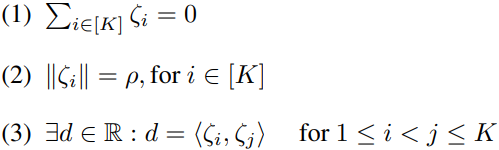
点的组合 s ζ1, . . . , ζK ∈ R^h 在半径ρ > 0的超球面中形成内接的简单正则构体:

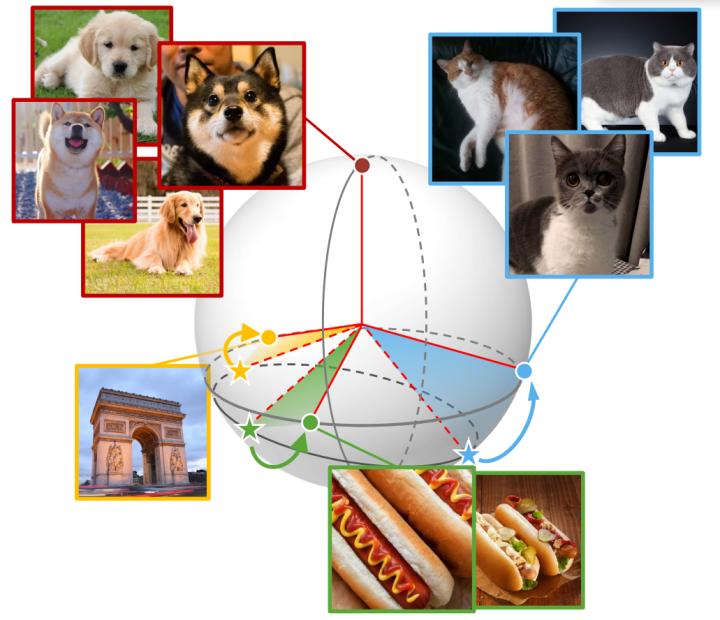
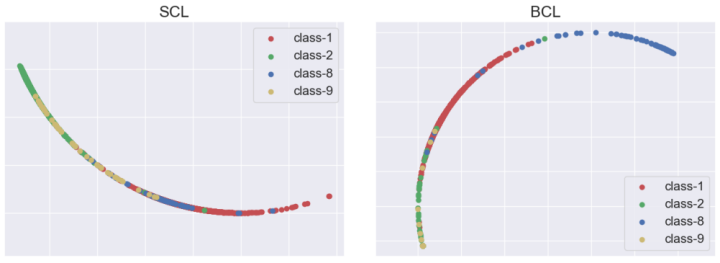
上图为数据点几何分布示意图 ,(a) 表示平衡数据上的 SCL、(b) 长尾数据上的 SCL 和 © 长尾数据上的 BCL 。 ⋆ 代表每个类的均值。 不同的颜色代表不同的类别。 如(b)所示,SCL 扩大了高频类之间的距离同时减少了低频类之间的距离,这会导致长尾数据的不对称几何分布。
2.3 分析¶
为了分析SCL在长尾数据上的问题,作者主要关注由每个类形成的几何构体产生的变化。当监督对比损失在平衡数据集上达到最小值时,每个类的表示会内接到简单正则构体的顶点,但SCL在长尾数据上会形成不对称分布。
2.4 进一步探究¶
作者分析了损失的极小值,由于直接计算整个长尾数据集的下界是比较困难的,所以只关注某个特定小批处理的损失,更加合理的损失函数应该需要被表示成:
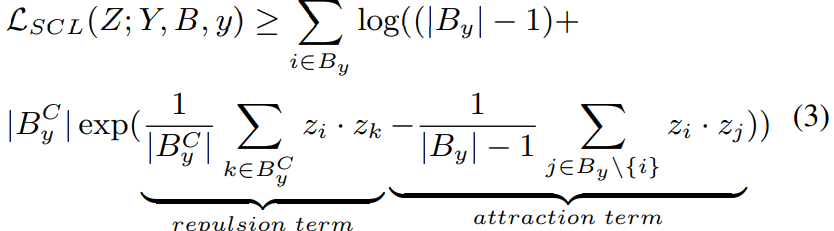
上述 SCL 损失由排斥项和吸引项组成。随着训练不断进行,吸引项会导致所有类内表示最终都会趋向于到它们的类均值。这意味着无论数据集是否平衡,同一类内的样本最终都会尽可能接近。排斥项影响类间均匀性并由高频类主导,但 SCL得到的特征难以分离,说明数据不平衡主要影响排斥项。并显然,排斥项与小批量中出现的类数据分布密切相关。当数据集长尾分布时,作者对每个 mini-batch 采样都是不均衡的,这导致了头类在排斥项中占主导地位,并使每个样本离头部更远。此外,对于每个样本,来自头类的梯度将远大于尾类。这不可避免地导致损失函数的优化更加集中在头类上,并导致不对称的几何构体。
2.5 解决方案¶
作者使用类平均和类补冲的思想来修正监督对比损失。为了避免优化过度集中在头类,一个最直接的方法是平衡梯度,作者将此操作称为类平均,以减少头类样本的梯度,定义如下:
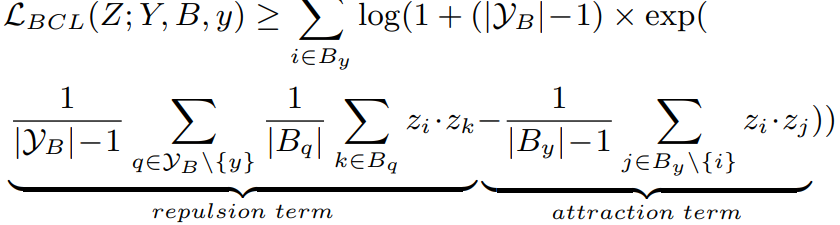
其中,Y_B ⊆ [K] 表示批次中出现的类集,此时的头类不再支配排斥项。由于每个类不是以相等的概率进行采样,这仍然可能导致优化不稳定并且无法形成正则构体。 为了解决这个问题,作者让所有类都出现在每个小批量中,并将这个操作命名为类补充,定义如下:
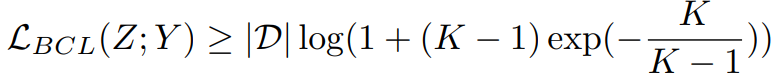
其中,D 表示数据集。 原先公式中的归一化项被剔除。此时每个类对梯度的贡献都是相等的。此外,BCL确保了每个样本的损失高度一致且类间独立,这也意味着优化将更少地偏向于头类(图2©).
2.6 平衡对比学习¶
一种包含两部分,一个是类平均,一个是类补充。
1. 类平均: 关键思想是在一个小批量中平均每个类的实例,以便每个类对优化有一个近似相近的贡献(就是减少分母中头类的比例),作者给出L1,L2,L3三种损失形式如下:
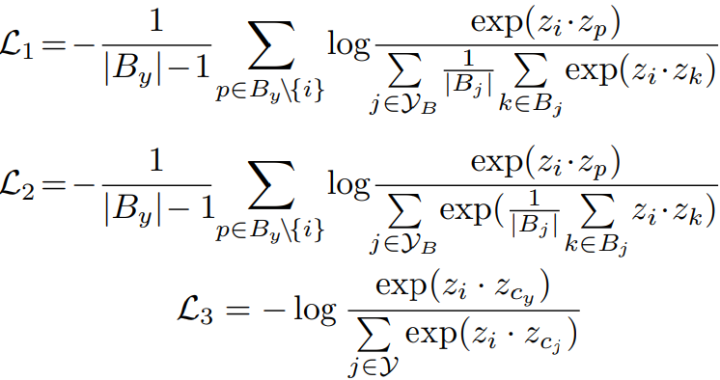
当|B_j |表示的正类被平均时,左部权重分母将减一。 L1 和 L2 之间的唯一区别是平均操作发生在不同的位置。 L1 是在指数函数外进行平均,而 L2 在指数函数内进行平均。 L3 中每个样本被拉向其原类并远离其他类,以下为类平均的代码实现。
2. 类补充: 为了让所有类都出现在每个 mini-batch 中,作者引入了类中心表示,即平衡对比学习的原型,公式如下:
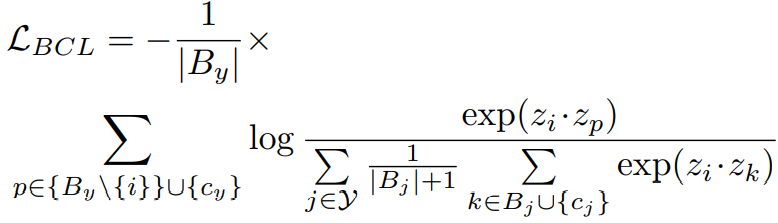
其中, c_j 是类别的prototype。 在实验中,作者对分类器权重进行非线性映射,并将输出视为每个类的prototype。 通过类平均和类补充,下界是一个与类无关的常量,避免了模型对头类的偏好。
在官方的实现中,引入了温度系数T,因此需要使用 exp(z_i.z_p/T) 和 exp(z_i.z_k/T) 替换上述公式的 exp(z_i.z_p) 和 exp(z_i.z_k) .
总的代码实现如下:
class BalSCL(nn.Module):
def __init__(self, cls_num_list=None, temperature=0.1):
super(BalSCL, self).__init__()
self.temperature = temperature
self.cls_num_list = cls_num_list
def forward(self, centers1, features, targets, ):
device = (torch.device('cuda')
if features.is_cuda
else torch.device('cpu'))
batch_size = features.shape[0]
targets = targets.contiguous().view(-1, 1)
targets_centers = torch.arange(len(self.cls_num_list), device=device).view(-1, 1)
targets = torch.cat([targets.repeat(2, 1), targets_centers], dim=0)
batch_cls_count = torch.eye(len(self.cls_num_list))[targets].sum(dim=0).squeeze()
mask = torch.eq(targets[:2 * batch_size], targets.T).float().to(device)
logits_mask = torch.scatter(
torch.ones_like(mask),
1,
torch.arange(batch_size * 2).view(-1, 1).to(device),
0
)
mask = mask * logits_mask
# class-complement
features = torch.cat(torch.unbind(features, dim=1), dim=0)
features = torch.cat([features, centers1], dim=0)
logits = features[:2 * batch_size].mm(features.T)
logits = torch.div(logits, self.temperature)
# For numerical stability
logits_max, _ = torch.max(logits, dim=1, keepdim=True)
logits = logits - logits_max.detach()
# class-averaging
exp_logits = torch.exp(logits) * logits_mask
per_ins_weight = torch.tensor([batch_cls_count[i] for i in targets], device=device).view(1, -1).expand(
2 * batch_size, 2 * batch_size + len(self.cls_num_list)) - mask
# 计算每个mini batch的均值作为右部分前系数权重
exp_logits_sum = exp_logits.div(per_ins_weight).sum(dim=1, keepdim=True)
# 上位除以下位
log_prob = logits - torch.log(exp_logits_sum)
mean_log_prob_pos = (mask * log_prob).sum(1) / mask.sum(1)
# 左半系数权重
loss = - mean_log_prob_pos
loss = loss.view(2, batch_size).mean()
return loss
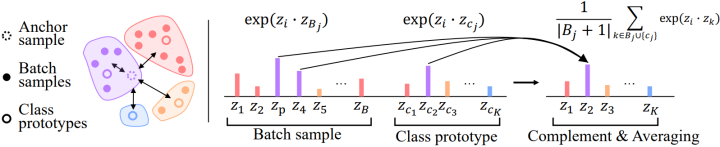
左:将Anchor Sample与其他样本进行对比。 右:对特定类同时应用类平均和类补充。 作者对 Anchor Sample 和 Batch sample 以及 Class prototype 之间的相似性进行平均。 请注意,蓝色的类不会出现在 mini-batch 中,因此可以直接将 anchor 与其prototype的相似度作为结果。
3. 架构: 所提出的架构如下图所示。由两个主要部分构成:分类分支和对比学习分支。 两个分支同时训练并共享相同的特征提取器。 BCL 是一个端到端模型,不同于传统两阶段训练策略的对比学习方法。 作者对这两个分支有不同的扩充方法。总共生成了三个不同的视图,其中 v1 是用于分类任务的视图,v2 和 v3 是对比学习的成对视图。
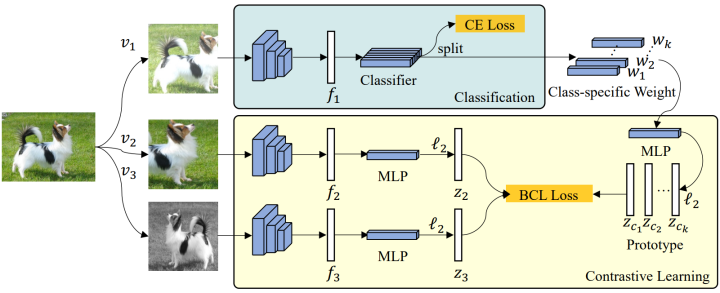
v2 和 v3 采用了与 v1 不同的相同增强方法,两个分支共享主干的特征。 分类器权重由 MLP 单独转换以用作 prototypes。 所有的表示都经过 ℓ2 归一化,以实现对比损失的平衡。
4. 使用 Logit补偿进行优化: 对于长尾学习任务,由于数据的不平衡性,最后一个分类层的输出 logit 通常存在偏差。 Logit 补偿旨在消除由数据不平衡引起的偏差。补偿可以应用在训练或测试期间,概括为以下形式:
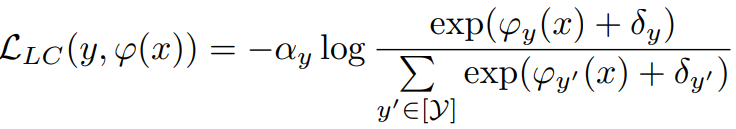
这里,α_y 是控制类 y 重要性的因素,δy 是类 y 的补偿,它的值与类频率有关。 作者定义 α_y = 1,δ_y = log P_y,并在训练的同时执行 logit 补偿,其中 Py 表示标签 y 的类先验。 总的训练损失可以表示为:
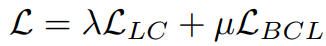
其中 λ 和 μ 是分别控制 L_{LC} 和 L_{BCL} 影响的超参数。
三、实验¶
3.1 实验细节¶
对于 CIFAR-10-LT 和 CIFAR-100-LT(LT指long tail),作者使用 ResNet-32 作为主干。使用 AutoAugment 和 Cutout 作为分类分支的数据增强策略,使用 SimAugment 作为对比学习分支的数据增强策略。 为了控制 L_{LC} 和 L_{BCL} 的影响,λ 设置为 2.0,μ 为 0.6,温度 T 设置为 0.1。 将批量大小设置为 256,权重衰减为 5e−4。 MLP 的隐藏层和输出层的维度分别设置为 512 和 128。 运行 BCL 200 个 epoch,学习率在前 5 个 epoch 将T设为 0.15,并在 epoch 160 和 180 处以 0.1 的步长衰减。 使用 Nvidia GeForce 1080Ti GPU 训练上述模型。
对于 ImageNet,使用 ResNet-50 和 ResNeXt50 作为主干。运行 BCL 90 个 epoch,初始学习率为 0.1,权重衰减为 5e-4。 对于 iNaturalist,使用 ResNet-50 作为主干,并使用 0.2 的初始学习率和 1e-4 的权重衰减运行 BCL 100 个 epoch。 两类数据集上的学习率使用余弦下降,λ 设置为 1.0,μ 设置为 0.35。 Batch设置为 256。对分类分支使用 RandAug 增强策略,对比学习分支使用 SimAug。 所有模型都使用 SGD 优化器进行训练,动量设置为 0.9。
3.2 实验过程¶
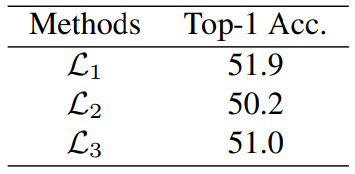
- 首先比较不同类平均实现(即 L1、L2 和 L3)的性能,所有实验均在 CIFAR-100 上进行。L1 和 L2 之间的主要区别在于执行平均操作的顺序。 对于 L3,使用prototype而不是同一类的平均值。 如下表 所示,L1 取得了最佳性能,这与作者在之前的分析一致。 令人惊讶的是,L3 实现了比 L2 更好的性能,这可能归因于prototype的良好表征特性。
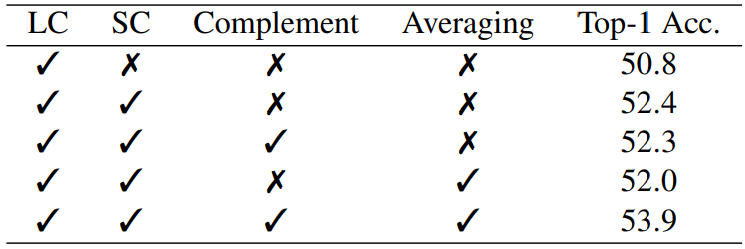
- 为了证明平衡对比损失函数的优越性,作者在下表中比较了不同损失的性能。使用带有 logit 补偿 (LC) 的交叉熵损失作为基线。 SC 表示添加对比学习分支和常规监督对比损失的基线。 类补充和类平均是所提出的平衡对比损失函数的主要思想。结果表明,单独使用类补充或类平均不能提高整体准确性。 相比之下,两者同时应用可以获得显着的性能提升,这表明这两个策略都是实现更强性能不可或缺的组件。
3.3 实验结果¶
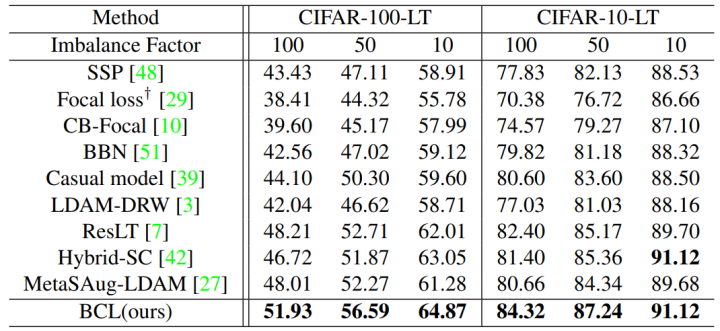
1. CIFAR-LT: BCL 与其他现有方法在 CIFAR 上的比较结果如下表所示。从表中可以看出,BCL 始终优于其他方法。 作者注意到 BCL 和 Hybrid-SC 之间的准确度差距随着数据不平衡程度的降低而减小。 这一结果主要是由于当不平衡问题更严重时,传统的监督对比损失会导致表示学习中的偏差更严重。
2. ImageNet-LT: 表 5 和表 6 列出了 ImageNet-LT 上的结果,与 Balanced Softmax 相比,通过根据类频率调整 prediction 来添加 logit 补偿,BCL 在所有分组上的效果都显着优于 Balanced Softmax 。 LWS 、T-norm 和 DisAlign 采用 two-stage 学习策略。这些方法侧重于在第二阶段对分类器进行微调,而忽略了表示学习阶段隐含的偏差。 PaCo 在监督对比学习中使用了一组参数中心,这些中心被分配了更大的权重,可以看作是分类器的权重。但是,BCL 中使用的 prototypes 补充了每个类的样本,以确保所有类都出现在每个 mini-batch 中。与 PaCo 相比,BCL 实现了 57.1% 的准确率,头类和低频类的准确率显着提高。
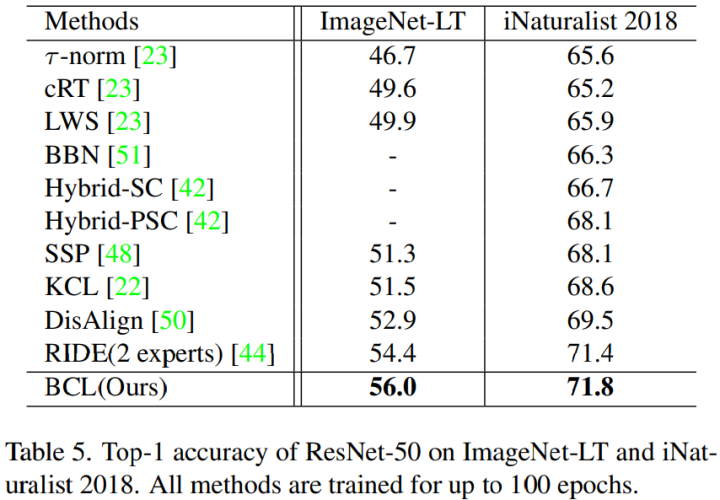
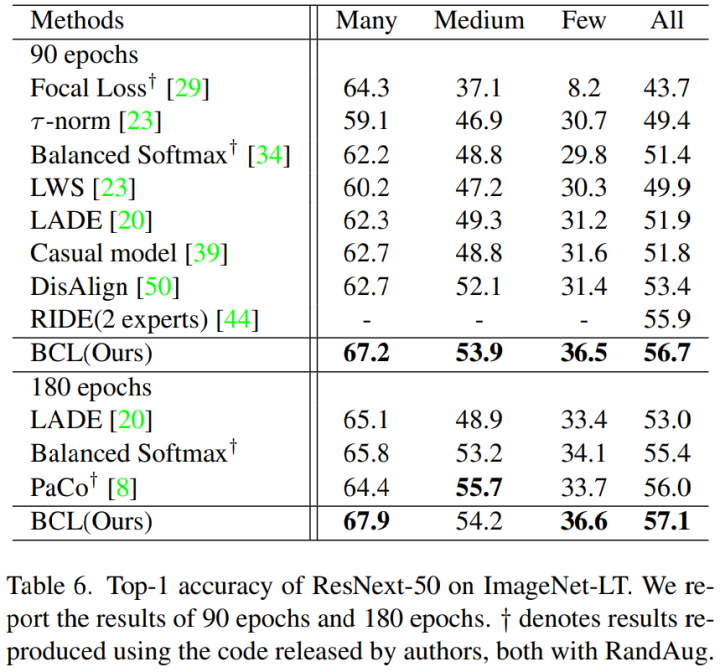
3. iNaturalist 2018: 表 5 显示了在 iNaturalist 2018 上的实验结果。由于 BCL 是一种对比学习方法,可以从更长的训练时间中获得更多的受益。 然而,为了公平比较,作者仅训练了各种模型 100 个 epoch 的结果。 Hybrid-SC 和 Hybrid-PSC 是对比学习方法,由于表示学习中产生的潜在偏差,它们的性能不如 BCL。与基于集成模型的 RIDE 策略相比,BCL 也始终表现出更好的性能,整体准确率达到 71.8%。
总结¶
在这项工作中,作者从表示学习的角度研究了长尾问题,提供了深入的分析来证明现有的监督对比学习对于长尾数据形成了一种分布不友好的不对称几何构体。 为了解决不平衡的数据表示学习问题,作者研究出一种平衡的对比损失 BCL 。 除了 BCL 之外,作者还采用了一个带有 logit 补偿的分类分支来解决分类器产生偏差的问题(个人感觉类似于 model ensemble)。 并在 CIFAR、ImageNet-LT 和 iNaturalist 2018 的长尾数据上进行了广泛的实验,结果充分证明了 BCL 与现有长尾学习方法相比具备更好的性能。
本文总阅读量次