ICCV2023 基准测试:MS-COCO数据集的可靠吗?¶
论文标题:Benchmarking a Benchmark: How Reliable is MS-COCO?
论文链接:https://arxiv.org/abs/2311.02709
摘要¶
数据集是用于分析和比较各种任务的算法的基础,从图像分类到分割,它们也在图像预训练算法中起着重要作用。然而,人们往往只关注结果,而忽略了数据集中实际的内容。因此,质疑数据集中所包含的信息类型以及其中的微妙差异和偏见是非常必要的。在本文中,我们利用形状分析流程来发现Sama-COCO(MS-COCO的重新标注版本)的潜在问题。我们在两个数据集上训练和评估了模型,以检查不同标注条件对结果的影响。我们的实验表明,标注方式对性能有显著影响,因此标注过程应该根据目标任务进行设计。
公开数据集链接:https://www.sama.com/sama-coco-dataset/。

图1 当注释不绕遮挡物(蓝色)和绕遮挡物(黄色)时的模型预测
引言¶
数据集基准和评估标准对于塑造计算机视觉研究的方向和动力具有关键作用。它们是衡量社区进步和算法创新的标尺。这些组件通常被认为是单一的工作,它们被收集和分析以确保所有算法的可靠性和质量。然而,当基准本身存在缺陷时,研究人员和从业者花费大量时间调整他们的实验以在基准上取得最佳性能,会产生什么后果呢?
视觉数据集通常用于分类、检测和分割等任务的算法基准测试或大型神经网络的预训练。然而,这存在一个问题,那就是实际的目标并不总是与数据集中提供的数据相一致。这种不一致可能源于自动标注协议的缺陷或众包努力的不协调。因此,有必要建立一个严格的端到端流程,其中注释过程由实际任务的明确定义所指导。
目标检测数据集(MS-COCO)是一个用于评估和比较检测和实例分割算法的标准数据集,包括YOLO,R-CNN和DETR等方法。它由自然图像组成,具有自动驾驶行业的应用价值,因此为在其上开发的神经网络提供了质量标准。由于MS-COCO在计算机视觉中作为基准的重要性,理解其数据集中的边界框和分割掩模的可靠性和质量是非常必要的,因为它们反映了数据的趋势和特征。为了评估数据集的质量,可以创建数据集的重新标注版本,以便与原始版本进行比较和发现潜在的差异,这些差异可能会影响算法的性能和泛化能力。

图2 除了聚集的实例外,其他对象的大小分布
数据集¶
Sama-COCO数据集是对现有MS-COCO数据集的重新标注工作,由一组专业的标注员完成。该项目最初是作为一个内部工作,旨在生成高质量的地面真实数据,后来发展成为一种提供了解机器学习数据集质量复杂因素的新方法。
该数据集是在数月内生成的,使用了不固定的人力资源:有时有多达500名标注员同时工作。关键点是有对标注员的进行详细指导。与MS-COCO数据集一样,标注以矢量多边形的形式提供。
我们指导标注员在绘制COCO对象轮廓的多边形时要尽可能精确,尽量避免包含背景。我们还指导标注员优先标注对象的单个实例,而不是聚集在一起的对象。如果图像中某个对象类别的实例数量超过了给定的阈值,我们就指示标注员只标注前几个实例,然后将剩余的实例标记为聚集。整个项目中的阈值根据不同的情况进行调整,以平衡预算、时间和数据质量之间的关系。此外,我们还指示标注员忽略尺寸小于10×10像素的对象。
重新标注过程涵盖了MS-COCO数据集中的所有123,287张训练和验证图像。这些图像预先加载了MS-COCO的原始标注,这使得标注员可以根据需要修改、保留或删除这些标注。在标注阶段之后,还有一个质量保证(QA)阶段,QA专家会检查每个提交的标注。不符合质量要求的标注会被退回,要求标注员进行修正,直到达到满意的水平。需要注意的是,一些标注员误解了忽略小对象的要求,认为是要删除MS-COCO的预标注,而另一些标注员则没有改变它们。
与原始MS-COCO数据集相比,Sama-COCO数据集有几个显著的差异。首先,Sama-COCO数据集中标记为聚集的实例明显更多。这部分是因为标注员被指示将大型的单一聚集分解为较小的部分和单个实体。尽管两个数据集有相同的基础,但Sama-COCO在80个类别中的47个类别中拥有更多的实例。其中一些类别,如person,增加的数量非常显著。其次,Sama-COCO的顶点数几乎是MS-COCO的两倍,这是因为标注员被指示在绘制多边形时要尽可能精确,尽量不包含背景。此外,如图2所示,大型对象的数量显著减少,因为大型的聚集或对象群中的单个元素被重新标注为不同的实体。在Sama-COCO数据集中还可以观察到一个关键的变化是非常小的对象(尺寸小于或等于10×10像素)的数量明显减少。最后,Sama-COCO数据集中还有更多的小型(从10×10到32×32像素)和中等大小(从32×32到96×96像素)的对象。
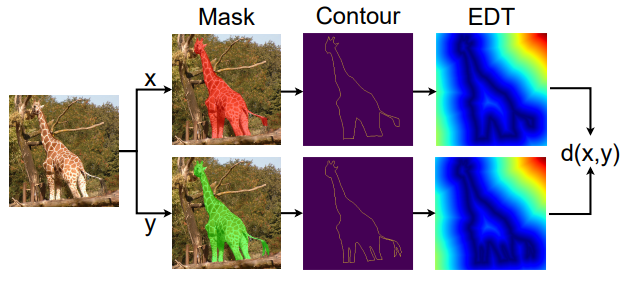
图3 表面距离对匹配流程
形状分析¶
由于Sama-COCO是重新注释而非最初数据集的更正,所以样本之间没有对应关系。为了确定地分析注释形状的差异,必须首先匹配多边形。放宽分析要求为单个多边形形状,并利用边界框形状一致性的概念。形状一致性假设轮廓错误不意味着盒子错误。使用基于交集与并集(IoU)度量的重叠标准确定匹配。对于任何一对封闭形状x,y,IoU定义为:
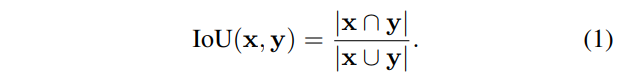
数据集之间注释实例的匹配由所有形状中IoU大于置信度阈值T的形状对定义。每个注释最多只有一个匹配,且不能保证一定找到匹配。经验选择匹配阈值为0.90。这种策略可找到受轮廓噪声影响的匹配,而不是与全局框错误相关的匹配。对形状x和形状集Y,匹配定义为:
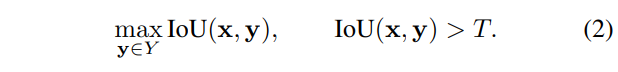
一旦找到匹配,则使用轮廓分析量化成对形状之间的差异。设(\partial x,\partial y)表示成对形状(x,y)的轮廓,长度为(\|\partial x\|,\|\partial y\|)。设D为空间域\Omega \subset \mathbb{R}^2上轮廓的精确距离变换(EDT),其中p定义了\Omega中的空间位置。用于量化形状之间平均差异的平均表面距离d_\mu(x,y)定义为:
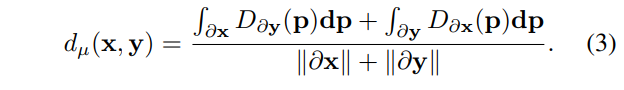
某些成对形状可能存在大型区域分歧。在这种情况下,平均表面距离无法捕获这种现象。为了缓解这个问题,引入最大距离d_{max}(x,y),定义为:
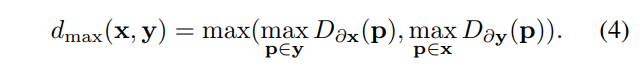
匹配流程应用于训练分割,找到310504个确定匹配。每个形状使用pycoco标准栅格化为掩模,并通过将掩模与自身的二值腐蚀相减生成轮廓。生成EDT,并通过用成对形状的轮廓索引距离图来计算路径积分。该流程对两个形状双向完成,如图3所示。平均和最大表面距离的分布如图4所示。
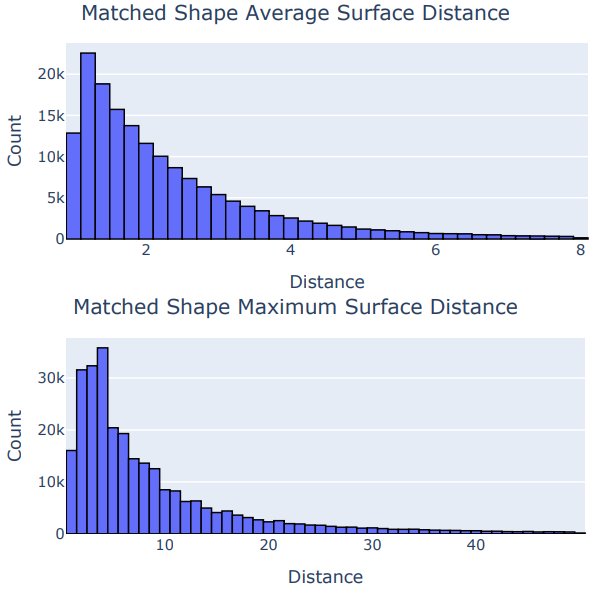
图4:平均和最大表面距离的长尾分布
实验¶
为了研究重新标注过程对神经网络预测质量的影响,我们使用检测和实例分割任务来训练和评估神经网络。重新标注过程包括更精确的多边形、更细化的聚集和更多的标注实例。我们使用Detectron2框架在MS-COCO和Sama-COCO上训练了一个基于ResNet-50和FPN的Faster R-CNN模型,并使用MS-COCO的标准评估指标对其进行评估,将每个数据集的验证分割作为地面真实数据。我们使用8个Nvidia V100 GPU,在批量大小为16的情况下,总共进行了270k次迭代的训练。我们在所有的实验中保持了相同的超参数。我们使用平均精度均值(mAP)作为评估指标,结果如表1所示。
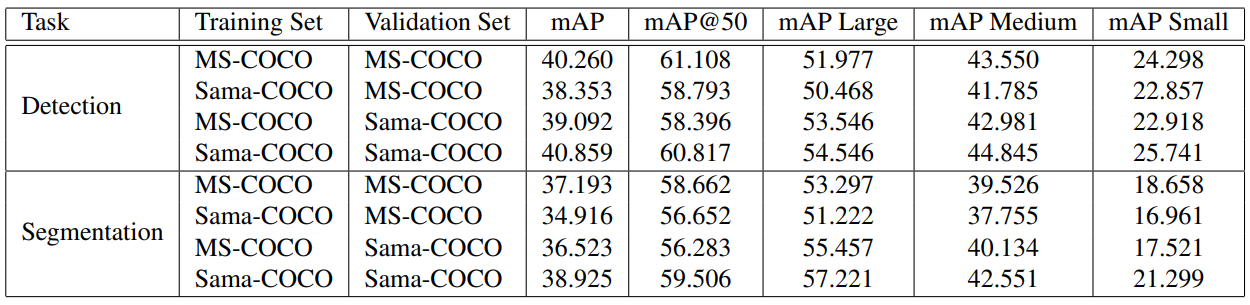
表1:检测和分割结果
我们还评估了学习与验证集完全匹配的理想表示的意义。在这种情况下,我们将源标注与目标标注进行比较,将源视为模型预测,目标视为地面真实数据。我们交替使用MS-COCO和Sama-COCO作为源和目标,以确保评估的公平性。结果如表2所示。

表2: 当将源数据集视为针对目标数据集的预测时,检测和分割结果

图5:具有遮挡的注释样式差异。MS-COCO(红色)和Sama-COCO(绿色)都将人手视为领带的遮挡。但是,MS-COCO没有将领带视为人的遮挡。
讨论¶
我们要先说明,没有任何数据集是完美的,Sama-COCO也不比MS-COCO更好或更差。每个数据集都会不可避免地存在一些偏差,但是不同形式的偏差会对神经网络的性能产生不同的影响。这可以通过比较不同数据集的基准测试结果来观察。
当我们比较两个数据集中的匹配实例时,可以发现MS-COCO数据集中存在一些系统性的偏差。这些偏差有两种不同的形式。第一种形式的偏差与多边形的紧密程度有关。我们发现,平均表面距离较低的成对多边形在轮廓上有轻微的差异。平均来说,Sama-COCO的多边形比原始标注更贴合对象,但是过分割和欠分割实例的组合可能对真实的预测质量没有影响,如果噪声的期望值为零。也有可能,随着网络规模的增大,它们会适应这些轮廓中的偏差,从而误导评估指标。在这种情况下,很难判断神经网络学习的表示的真实质量,因为评估它们的唯一方式也包含了偏差。
第二种形式的偏差与遮挡物和标注风格指南的处理和规定有关。Sama-COCO强调多边形贴近可观察到的像素,而原始数据集包含绕过遮挡物的多边形。考虑遮挡物更适合像素级的实例分割任务,而忽略遮挡物更类似于定位任务。在这种隐性的偏差上训练的神经网络会以不同的方式学习解决这些任务。因此,任何机器学习从业者都必须了解他们的数据集与他们想要解决的下游任务之间的关联性,并应该在数据收集阶段注意标注标准和指南,以尽量减少顶层问题。合并具有冲突标注风格的数据集可能是不明智的,因为神经网络的下游行为可能难以预测。
当我们查看检测和分割任务的评估指标差异时,可以明显看到网络从与训练数据集相同风格的评估中受益,如表1所示。这意味着性能与主观的质量定义密切相关。如果我们使用额外的样本来丰富数据集,但是样本的风格分布发生了变化,那么网络的性能可能会降低,这与我们的预期相反。这可以通过将一个数据集的验证标注作为源,另一个数据集的验证标注作为目标来理论上验证。即使我们在另一个数据集上是完美的预测者,我们也会受到错过的实例、边界变形和细微差异的影响。还值得注意的是,一些最先进的检测算法的性能优于我们的结果。这很有趣,因为框标注应该与多边形的变化相对一致。这意味着网络可能会过拟合训练数据集中可能无法在另一个数据集中复现的特定信息类型。
结论¶
从讨论中可以看出,数据集中的偏差可能导致一些不期望或意外的结果,这可能是有问题的。在实例分割中,标注方式的选择会影响模型对遮挡对象的输出。因此,在构建标注数据集时必须仔细考虑,以确保它们能够反映真实世界应用中的需求。虽然Sama-COCO并不完全避免所有的标注错误,但它确实提供了一组高质量的标注,可以用于更好地探索标签噪声领域和对精确多边形很重要的应用。
本文总阅读量次