目标检测和感受野的总结和想法¶
1. 概念¶
经典的目标检测如Faster R-CNN, YOLOv3等都用到了Anchor, 怎么设计Anchor每个目标检测方法各不相同。Faster R-CNN中的Anchor有三种形状,三种长宽比,比如形状有[128, 256, 512]三个,长宽比有[1:1, 1:2, 2:1]三种,这样组合就是9个anchor。YOLOv3中的Anchor是通过K-Means聚类得到的。这些基于anchor的方法的目的是学习一个从Anchor到GT Box的转换函数,下边我们了解一下理论感受野、Anchor、实际感受野三者之间的关系。
先看一张图:

图源Medium
一个kernel size=3的卷积核,通过在原feature map上划窗,然后计算得到的是一个值,这个值是通过计算原来feature map上3×3面积上的值得到的结果,那就说经过这个3×3卷积以后,这一层feature map的感受野就是3×3。如果是两个kernel size=3的卷积核堆叠起来,那么上图黄色的feature map每个值对应最下面的5×5的感受野。
理论感受野:某一层feature map中的某一个位置,是由前面某一层固定区域输入计算出来的,那这个固定区域就是这个位置的感受野。
实际感受野: 实际感受野要小于理论感受野,是在NIPS2016中的Understanding the Effective Receptive Field in Deep Convolutional Neural Networks提出的。
文章主要贡献有以下几点:
1. 并不是感受野内所有像素对输出向量的贡献相同,实际感受野是一个高斯分布,有效感受野仅占理论感受野的一部分

以上就是不同层下的不同的感受野。


使用不同的激活函数与不同的卷积采样方法,产生的实际感受野也不尽相同。其中ReLU的高斯分布没有另外两个平滑,创建了一个较少的高斯分布,ReLU导致很大一部分梯度归零。
2. 另外就是非常关心的问题,实际感受野是如何变化的?实际感受野和理论感受野的关系是什么样的?

文章中也给出了答案,见上图,随着网络层数的加深,实际有效的感受野是程\sqrt{n}级别增长。而右图展示了随着网络层数的加深,有效感受野占理论感受野的比例是按照1/\sqrt{n}级别进行缩减的。其中需要注意的是实际感受野的计算方式:若像素值大于(1-96.45%)的中心像素值,就认为该像素处于实际感受野中。
3. 训练的过程中,感受野也会发生变化。

可以看出分类和分割任务经过训练后的感受野都有提升,不过提升幅度不太一样。这也说明了神经网络通过学习,扩大了感受也,能够自适应把越来越大的权重放在感受野之外的像素上。也在一定程度上说明更大感受野的必要性。
2. 计算¶
2.1 一种简单的感受野计算方法¶
以下内容整理自:zhihu@YaqiLYUhttps://zhuanlan.zhihu.com/p/44106492
规定一下:k代表kernel size, s代表stride, r代表感受野
-
第一个feature map(也就是原始图片)的感受野默认为1
-
经过kernelSize=k, s=1 的卷积层, 感受野计算方法如下:
- 经过kernelSize=k, s=2 的卷积层, 感受野计算方法如下:
- 经过s=2的maxpool或avgpool层,感受野计算方法如下:
- 经过kernelSize=1的卷积层不改变感受野
- 经过全连接层和Global Average Pooling层的感受野就是整个输入图像
- 经过多路分支的网络,按照感受野最大支路计算
- shortcut层不改变感受野
- ReLU、BN、Dropout不改变感受野
- 全局Stride等于所有层Stride的累乘
- 全局Padding需要通过以下公式计算(通过feature map反推即可):
出个计算题,计算VGG16最后一层感受野, 代入公式:

VGG16对应D系列,来计算这一列的感受野(从上往下):
R=(((((1+2+2)x2+2+2)x2+2+2+2)x2+2+2+2)x2+2+2+2)x2=308
S=2x2x2x2x2=32
P=138
实际上tensorflow和pytorch已经有人开发出了计算CNN感受野的模型,实际上VGG16感受野没有那么大,下图是可视化一个416x416大小输入图片的感受野,RF实际上只有212x212,也就是下边黄色和蓝色的正方形。
PS:提供一下pytorch和tensorflow计算感受野的库:
Tensorflow:https://github.com/google-research/receptive_field/
Pytorch:https://github.com/Fangyh09/pytorch-receptive-field

以上的计算方式是国内认可度比较高的一种计算方式,在知乎上获得了400+的高赞,但是与谷歌计算出来的结果不一样,所以我就去读了一下谷歌发在Distill上的一篇论文:Computing Receptive Fields of Convolutional Neural Networks,里边非常丰富的讲解了如何计算感受野,包含的情况非常广。先说结论,实际上以上计算方法应该是从下往上进行的,而不是从上往下,另外以上规则只能适合比较有限范围的卷积,而没有一个详细的公式。在讲解下一节以后,我们尝试重新计算VGG的感受野
2.2 自下而上的计算方法¶
首先也来规定一下默认的符号意义,规定L代表网络的层数l=1,2,...,L, 定义feature map: f_l\in R^{h_l\times w_l\times d_l}, 代表第l层的输出,高宽深度分别为h_l,w_l,d_l。规定输入的图片为f_0,最后一层feature map输出为f_l

l代表第几层;f代表feature map;p代表left padding;
q代表right padding;s代表stride,k代表kernel size。
在这里,定义元素级操作的kernel size=1,比如加法,filter concatenation、relu等操作。
下图是一个四层的网络的感受野示意图:

经过了两个3x3卷积和一个stride=2的maxpooling层,如果按照原来的方法从上往下进行计算,那最后一层每个点的感受野应该是:(1+2+2)x2=10, 要比上图的6要大很多,所以就知道为啥计算的感受野偏大了(没有处理重叠部分),而且也可以发现感受野中间集中更多信息,两边信息处理较少。
单路网络中的计算方法
单路网络就是没有分支的网络,比如VGG。
规定r_l是第l层feature map相对于 r_L 的感受野。说人话,就是最后一层f_L的一个像素值是由第l层feature map的r_l个值计算出来的,注意r_L=1。所以整个计算过程是从后往前进行的。
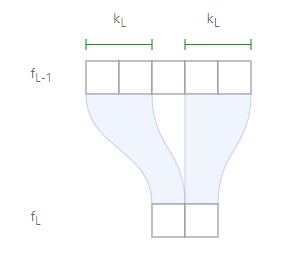
上图是一个简单例子,kernel size=2, padding=0, stride=3的情况下,下边这层每个值只受上一层2个值的影响,所以第l-1层的感受野就是2。
然后我们要考虑更加一般的情况,也就是通过r_l能计算出r_{l-1},这样就能通过类推,得到最终结果。具体推导过程推荐去原文看一下,非常详细,在这里不多赘述,否则篇幅会太大。直接给出结论:
递推公式:
通项公式:
建议自己推导的时候使用递推公式,非常方便,代码实现的时候考虑使用通项公式。
观察一下通项公式,可以发现,如果每一层kernel size都是1,那么最终的感受野就是1。如果所有的stride=1,那么最终感受野之和就是\sum(k_l-1)+1。并且可以发现,影响感受野最大的参数应该是stride,如果stride>1,那将成倍的影响之后的层。
补充一下知道感受野以后的,如何计算有效stride和有效padding。
Effective Stride:
递推公式:
通项公式:
Effective Padding:
递推公式:
通项公式:
下面我们来重新计算VGG16整个模型的感受野:

多路网络
以上讲解了单路情况下的感受野计算方法,但是现在STOA的卷积网络通常都是拥有多分支的,比如说ResNet、Inception、DenseNet等网络。
多路网络不得不提到对齐问题,感受野是不具有平移不变性,下图就是一个例子:

可以看到,最后一层通过两条不同路径后对应到第一层feature map的感受野的中心是不重合的。这是感受野的一个性质,不过好在大多数现代的网络设计是对齐的,对很多计算机视觉任务来说,都需要对其输出特征,包括目标检测、语义分割、边缘检测、着色等。
在网络对齐时候,所有不同路径都会导致感受野的中心是重合的,所以不同路径必须保持相同的stride。这一点可以观察Inception系列的网络,两条路的Stride是不可能不同的。
在网络对齐的情况下,多路网络的感受野应该是所有分支中最大感受野,比如下边是一个对齐的网络,中心是重合的,感受野的大小就是3。

有了以上的计算方法,我们可以很方便计算所有卷积网络的感受野:

上图是常用分类模型对应的感受野的结果,我们可以发现,随着模型的不断进化,感受野在不增大,在比较新提出的网络中,感受野已经能够覆盖整个输入图像了,这就意味着最终特征图中每个点都会使用到整个图像所有得上下文信息。


上图是感受野大小和在ImageNet上top-1准确率的关系,其中圆圈的大小代表每个网络的浮点运算数量。分类的准确率和感受野大小大体程对数关系,也就是说虽然感受野可以无限增长,越往后,带来的准确率上的提升也就越小,而需要的计算代价会变得更大。
上图MobileNet和VGG16准确率相当,但是MobileNet所需计算量却非常小(约为VGG16的27分之1),这是由于MobileNet使用了大量depth-wise Convolution,这样可以以较小的计算代价来增加模型感受野。这个对比可以表明生成更大感受野的网络可以有更好的识别准确率。
注意: 感受野并不是唯一影响准确率的因素,其他因素,比如网络的深度,宽度,残差连接,BatchNorm等也起着非常重要的作用。也就是说,感受野是我们在设计网络的时候需要考虑的一个因素,但还是要综合其他方法。
补充:
除了最普通的卷积,还有空洞卷积、上采样、BatchNorm、Separable Conv的感受野计算需要补充。
- 空洞卷积:引入空洞率\alpha, 经过空洞卷积,kernel size有原来的k变为\alpha \times (k-1)+1,所以只要替换原来的公式中的k即可。
- 上采样:一般通过插值来实现,假如\alpha通过2倍上采样得到\beta,那么认为这个层感受野计算等价于与\alpha的kernel size相等的卷积。(这个地方不是特别理解,按照自己想的,一般upsample不会改变感受野,下边是谷歌论文中关于这部分的讲解,希望能读懂的大佬能联系一下我,我的联系方式在文末)
Upsampling. Upsampling is frequently done using interpolation (e.g., bilinear, bicubic or nearest-neighbor methods), resulting in an equal or larger receptive field — since it relies on one or multiple features from the input. Upsampling layers generally produce output features which depend locally on input features, and for receptive field computation purposes can be considered to have a kernel size equal to the number of input features involved in the computation of an output feature.
- 可分离卷积: 等价于普通卷积,并没有变化。
- BatchNorm:推理过程中BN不改变感受野,而训练过程中,BN的感受野是整个输入图像。
- 转置卷积: 会增加感受野,和普通计算方法类似
3. 作用¶
1.目标检测:像SSD、RPN、YOLOv3等都使用了anchor,而anchor的设计正是依据感受野,如果感受野太小,只能观察到局部的特征,不足以得到整个目标的信息。如果感受野过大,则会引入过多噪声和无效信息。Anchor太大或太小均会影响性能。
2.语义分割:最终预测的像素的感受野越大越好,涉及网络一般也是越深越好,这样才能捕获更多的上下文信息,预测才会更准。
3.分类任务:图像分类中最后卷积层的感受野要大于输入图像,网络深度越深,感受野越大,性能越好。
为了更合适的感受野,各种多尺度的模型架构被提出,可以分为图像金字塔和特征金字塔,具体实现方面可以是:1. 采用多尺度输入,如yolov3的multi scale机制。2. 多尺度特征融合,最经典的是FPN。3. 多尺度特征预测融合,如SSD。4. 以上方法的多种组合。
4. 关系¶
在论文 Single Shot Scale-invariant Face Detector 中,说明了目标检测中Anchor, 理论感受野,实际感受野三者的关系。这篇论文主要针对的是中小目标,密集人脸情况下的anchor设置。
Anchor一般是通过先验进行指定的,Anchor与目标的大小和位置越匹配(IOU>0.5or0.7),回归效果就会越好。如果小人脸和anchor的IOU过小,就会造成anchor很难回归到GT上,从而导致Recall过低。

文章中指出了Anchor、理论感受野、实际感受野三者的关系。(a)图中,整个黑色的box是理论感受野,中间的白点是一个高斯分布的实际感受野。(b)图中举了一个例子,黑色点状的框代表是理论感受野的面积,蓝色的代表实际感受野位置,而最合适的anchor就是红色的框,所以关系为:
Anchor大小<实际感受野<理论感受野
SFD是基于SSD进行改进的,SSD中使用了6个层来进行检测,以下是文章中设置内容:

为了探究Anchor和RF的关系,这里使用MATLAB的工具箱来拟合两者关系:

设anchors=x, RFs=y则有如下关系:
所以y和\sqrt{x}大体上是正比例关系。其实这里只是探索一下他们之间的关系,实际感受野实际上依然是一个超参数,我们不可能明确计算出来,然后设置对应的anchor,不过我们了解了这个之后,最起码anchor的限制范围应该是小于理论感受野的。
作者在论文中说明了Anchor设置的理由,Anchor=stirde\times 4, 这样就跟上(c)图一样,这样设置可以保证不同尺度的anchor在图片上采样的密度是一样的。将铺设的anchor的scale值设为大致覆盖到有效感受野的size。这一点并不是特别理解
SFD效果可以说是非常好了,以下是mAP对比图:

5. 总结¶
-
首先,许多经典的网络结构中的这些卷积不是随便决定的,在修改网络的时候不能随便删除。比如在yolov3中,backbone后边的几个卷积再接yolo层这个当时就觉得很随意,但是他是有一定道理的。
-
假如出于对小目标的考虑,想要降低下采样率,那么直接删掉一个maxpool层,或者删掉stride=2的卷积层都是不可取的。通过公式我们知道,stride对一个网络的感受野影响非常大,而且会对后边的网络层的感受野都进行影响,所以要通过使用stride=1的maxpool或者空洞卷积来弥补对感受野带来的损失。
-
实际感受野依然是一个超参数,他是会随着训练的过程发生变化,我们无法准确计算出来实际感受野,但是通过分析anchor,实际感受野和理论感受野,我们知道了anchor<实际感受野<理论感受野,所以anchor还是会被理论感受野的大小所限制。
-
自己尝试过使用kmeans算法聚类自己数据集的Anchor,之前两个数据,两次聚类,都出现了自己聚类得到的Anchor不如默认的Anchor得到的结果。之前一直不知道原因在哪里。在总结了感受野以后,我觉得可以合理推测,Anchor应该和实际感受野尽量匹配,但是实际感受野实际上是一个超参数,通过聚类得到的anchor有一定代表性,但是效果反而不如默认的anchor,这是因为我们自己聚类得到的Anchor的范围实际上没有默认的广。
比如yolov3-tiny里边的anchor最小是【10,14】最大是【344,319】,经过计算理论感受野是382,按照SFD里边推导得到的公式计算,对应的anchor大小应该为159,如果按照理论感受野的三分之一来计算,大概是127.3。大概在这个范围,自己聚类得到的最大anchor也就是20左右,所以网络如果想要适应(回归)20左右的anchor需要网络更长时间的训练。
最后想推荐一下以上涉及到的三篇文章,都特别有价值,值得多看几遍:
(1)S3FD
(2)Computing Receptive Fields of Convolutional Neural Networks
(3)Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
另外,以上内容是基于论文以及自己的理解表述的,如果有问题,欢迎加我微信,互相交流。
6. 参考文献¶
SFD论文: https://arxiv.org/abs/1708.05237
YaqiLYU:https://zhuanlan.zhihu.com/p/44106492
感受野计算论文:https://distill.pub/2019/computing-receptive-fields/
感受野推导: "Computing Receptive Fields of Convolutional Neural Networks", Distill, 2019.
一个用来计算感受野的网站:https://fomoro.com/research/article/receptive-field-calculator
本文总阅读量次