【综述】神经网络中不同类型的卷积层¶
在计算机视觉中,卷积是最重要的概念之一。同时研究人员也提出了各种新的卷积或者卷积组合来进行改进,其中有的改进是针对速度、有的是为了加深模型、有的是为了对速度和准确率的trade-off。本文将简单梳理一下卷积神经网络中用到的各种卷积核以及改进版本。文章主要是进行一个梳理,着重讲其思路以及作用。
- 【综述】神经网络中不同类型的卷积层
- 1. Convolution
- 2. 1x1/Pointwise Convolutions
- 3. Spatial and Cross-Channel Convolutions
- 4. Grouped Convolutions
- 5. Separable Convolutions
- 6. Flattened Convolutions
- 7. Shuffled Grouped Convolutions
- 8. Dilated Convolution(Atrous Convolution)
- 9. Deformable Convolution
- 10. Attention
- 11. Summary
- Reference
1. Convolution¶
下图是一个单通道卷积操作的示意图:
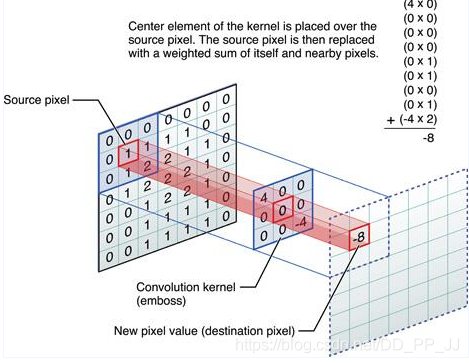
在深度学习中,卷积的目的是从输入中提取有用的特征。在图像处理中,卷积滤波器的选择范围非常广,每种类型的滤波器(比如Sobel算子、Canny算子等)都有助于从输入图像中提取不同的方面或者特征,比如水平、垂直、边缘或对角线等特征。
而在CNN中,不同的特征是通过卷积在训练过程中自动学习得到的filter的权重得到的。卷积具有权重共享和平移不变性的优点。
下图是一个单filter的卷积的示意图:
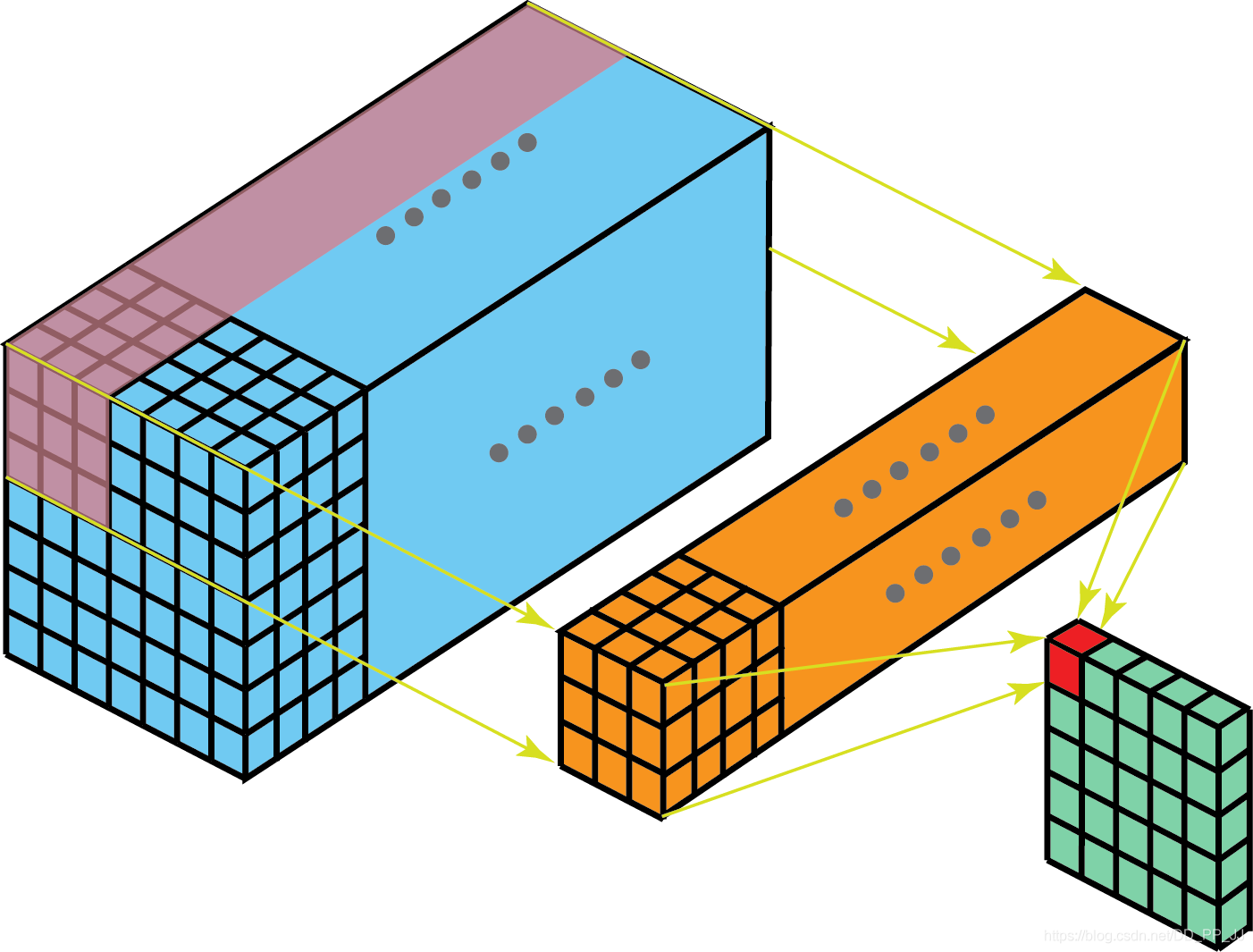
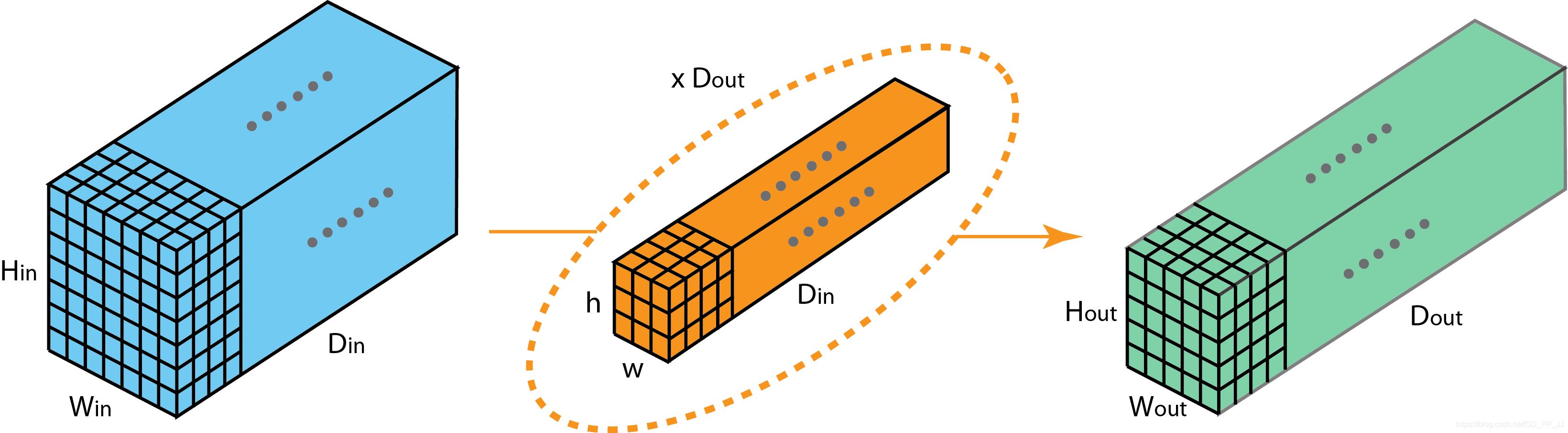
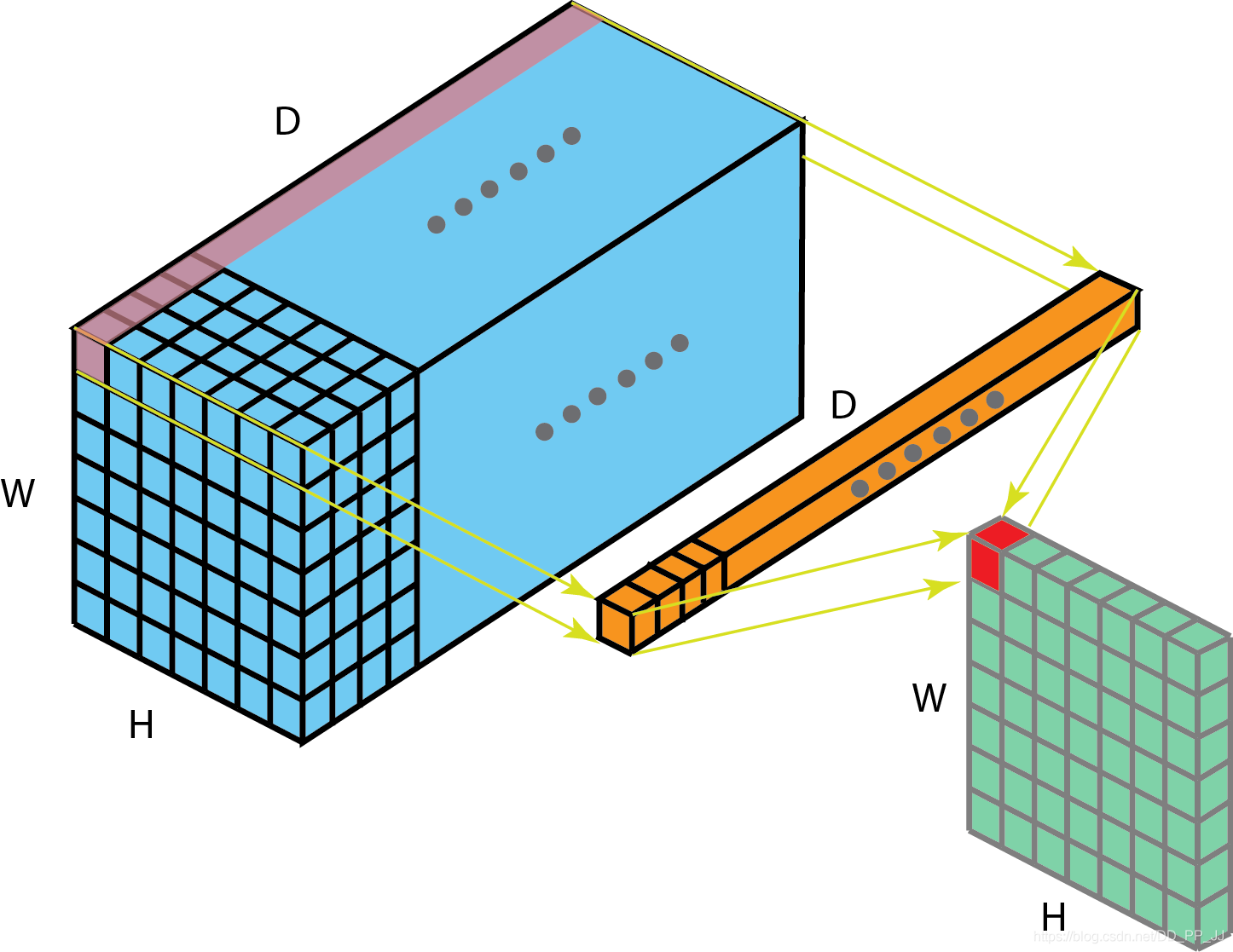
多个filter效果就如下图所示:
2. 1x1/Pointwise Convolutions¶
最初1x1卷积是在Network in Network中提出的,之后1x1convolution最初在GoogLeNet中大量使用,1x1卷积有以下几个特点:
- 用于降维或者升维,可以灵活控制特征图filter个数
- 减少参数量,特征图filter少了,参数量也会减少。
- 实现跨通道的交互和信息整合。
- 在卷积之后增加了非线性特征(添加激活函数)。
3. Spatial and Cross-Channel Convolutions¶
最初被使用在Inception模块中,主要是将跨通道相关性和空间相关性的操作拆分为一系列独立的操作。
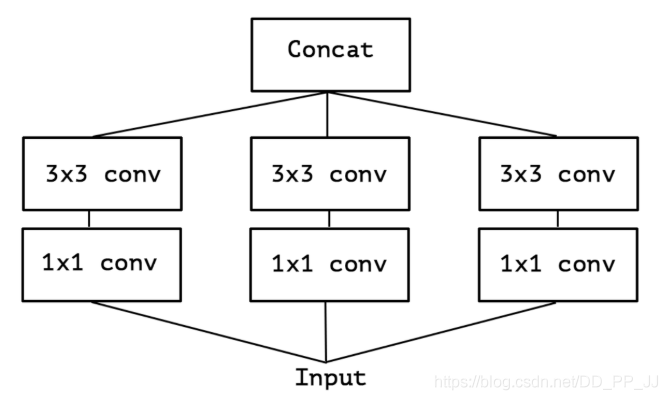
先使用1x1 Convolution来约束通道个数,降低计算量,然后每个分支都是用3x3卷积,最终使用concat的方式融合特征。
pytorch实现(上图只是简化图,和代码并不一一对应)
class InceptionA(nn.Module):
def __init__(self, in_channels, pool_features, conv_block=None):
super(InceptionA, self).__init__()
if conv_block is None:
conv_block = BasicConv2d
self.branch1x1 = conv_block(in_channels, 64, kernel_size=1)
self.branch5x5_1 = conv_block(in_channels, 48, kernel_size=1)
self.branch5x5_2 = conv_block(48, 64, kernel_size=5, padding=2)
self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)
self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)
self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, padding=1)
self.branch_pool = conv_block(in_channels, pool_features, kernel_size=1)
def _forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return outputs
def forward(self, x):
outputs = self._forward(x)
return torch.cat(outputs, 1)
4. Grouped Convolutions¶
组卷积最初是在AlexNet中提出的,之后被大量应用在ResNeXt网络结构中,提出的动机就是通过将feature 划分为不同的组来降低模型计算复杂度。
下图详解了组卷积计算过程。
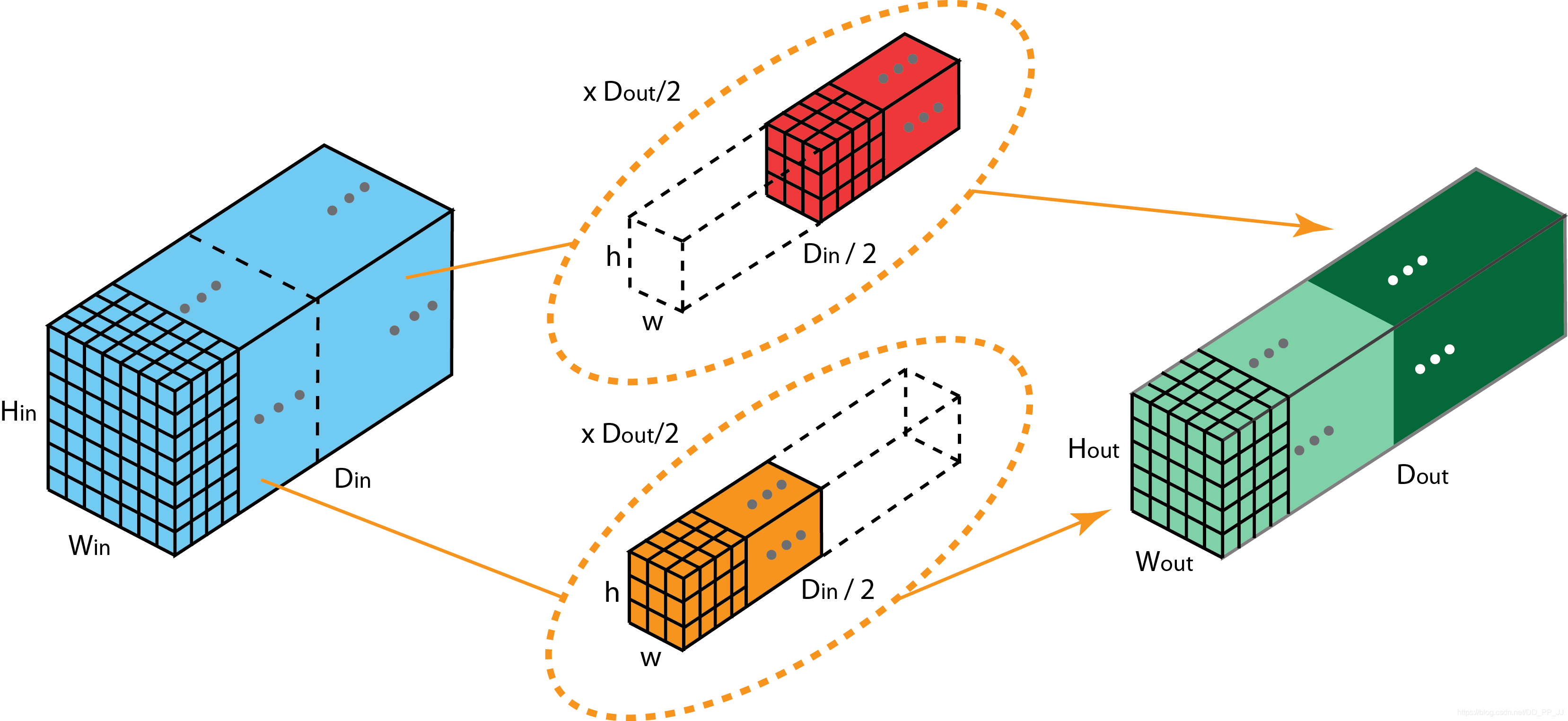
所谓分组就是将输入feature map的通道进行分组,然后每个组内部进行卷积操作,最终将得到的组卷积的结果Concate到一起,得到输出的feature map。
ResNeXt是ResNet和Inception的结合,其每个分支都采用的相同的拓扑结构。ResNeXt本质是使用组卷积(Grouped Convolutions),通过基数( cardinality )来控制组的数量。
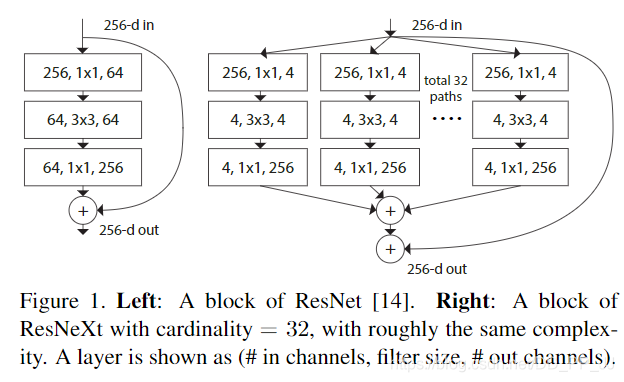
使用组卷积的优点:
-
训练效率高。由于卷积被分为几个不同的组,每个组的计算就可以分配给不同的GPU核心来进行计算。这种结构的设计更符合GPU并行计算的要求,这也能解释为何ResNeXt在GPU上效率要高于Inception模块。
-
模型效率高。模型参数随着组数或者基数的增加而减少。
-
效果好。分组卷积可能能够比普通卷积组成的模型效果更优,这是因为滤波器之间的关系是稀疏的,而划分组以后对模型可以起到一定正则化的作用。从COCO数据集榜单就可以看出来,有很多是ResNeXt101作为backbone的模型在排行榜非常靠前的位置。
组卷积为何效果更好的详细解释可以看这篇博客:https://blog.yani.io/filter-group-tutorial/,其中有比较详细的解释。
5. Separable Convolutions¶
可分离卷积可以分为空间可分离卷积(Spatially Separable Convolutions)和深度可分离卷积(depthwise separable convolution)。
假设feature的size为[channel, height , width]
- 空间也就是指:[height, width]这两维度组成的。
- 深度也就是指:channel这一维度。
5.1 Spatially Separable Convolutions¶
简单来讲,空间可分离卷积就是将原nxn的卷积,分开计算变为1xn和nx1两步。
下边举一个例子:
普通的3x3卷积在一个5x5的feature map上是如下图这样进行计算:
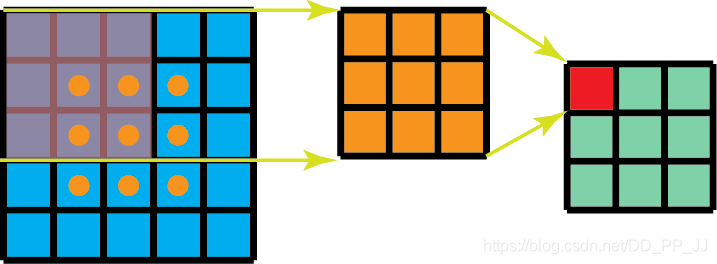
每个位置需要9次乘法,一共有9个位置,所以整个操作下来就是9x9=81次乘法操作。
如果用空间可分离卷积的话,如下图所示:
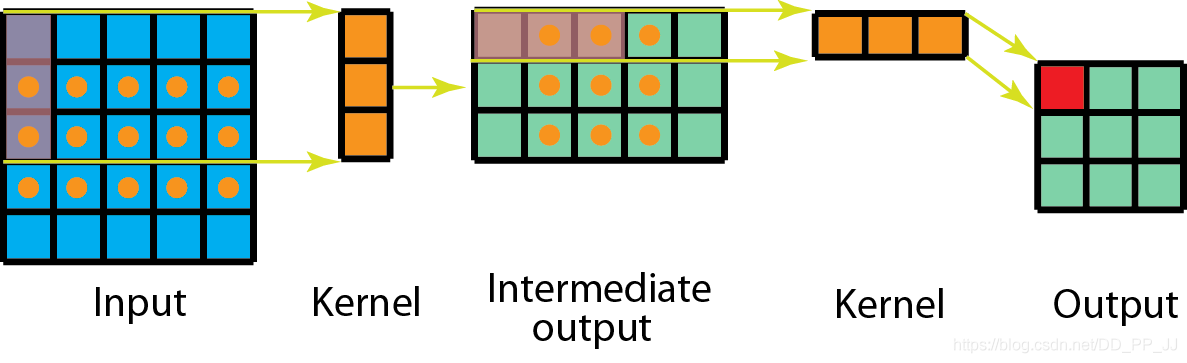
第一步先使用3x1的filter,所需计算量为:15x3=45
第二步使用1x3的filter,所需计算量为:9x3=27
总共需要72次乘法就可以得到最终结果,要小于普通卷积的81次乘法。
推广一下,假设对nxn的feature map使用kernel size为mxm的卷积,
普通卷积需要计算的乘法次数为:
空间可分离卷积需要计算的乘法次数为:
那么代价比为:
在n>>m的情况下,这个比值将变为2/m,所以可以极大降低计算量。
虽然空间可分离卷积节省了计算成本,但是一般情况很少用到。原因是并非所有的kernel 都可以分为两个较小的kernel;空间可分离卷积可能会带来一定的信息损失;如果将全部的传统卷积替换为空间可分离卷积,将影响模型的容量, 这样得到的训练结果可能是次优的。
5.2 Depthwise Separable Convolutions¶
深度可分离卷积在Xception或者MobileNet中大量使用,主要有两个部分组成:
- Depthwise Convolution: 独立地施加在每个通道的空间卷积
- Pointwise Convolution: 1x1 convolution,通过深度卷积将通道输出投影到一个新的通道空间。
下边是一个深度可分离卷积的pytorch实现:
class DWConv(nn.Module):
def __init__(self, in_plane, out_plane):
super(DWConv, self).__init__()
self.depth_conv = nn.Conv2d(in_channels=in_plane,
out_channels=in_plane,
kernel_size=3,
stride=1,
padding=1,
groups=in_plane)
self.point_conv = nn.Conv2d(in_channels=in_plane,
out_channels=out_plane,
kernel_size=1,
stride=1,
padding=0,
groups=1)
def forward(self, x):
x = self.depth_conv(x)
x = self.point_conv(x)
return x
通过比对代码,很容易理解下图的操作过程:
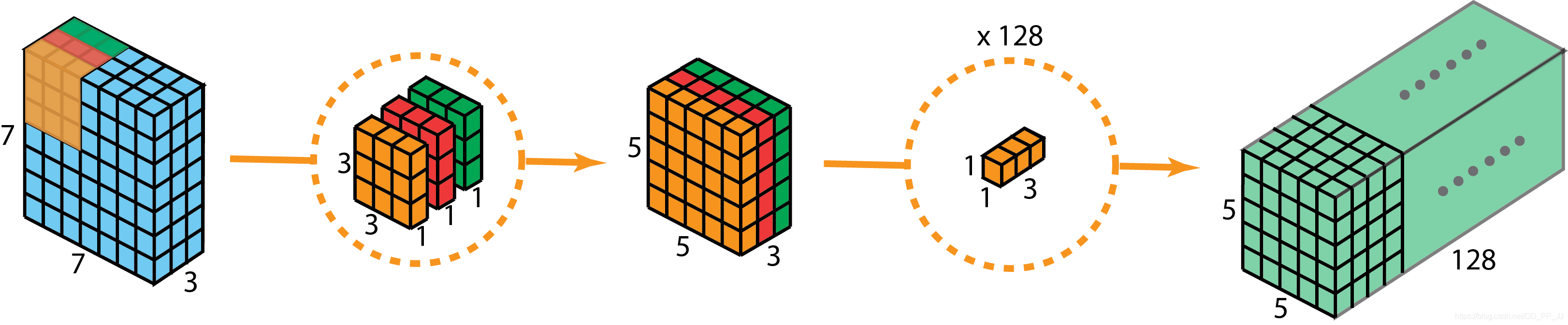
Inception模块和可分离卷积的区别:
- 可分离卷积是先用Depthwise Convolution, 然后再使用1x1卷积;Inception中是先使用1x1 Convolution,然后再使用Depthwise Convolution。
- 深度可分离卷积实现的时候没有增加非线性特征(也就是使用激活函数)。
下面再来比较一下所需计算量:
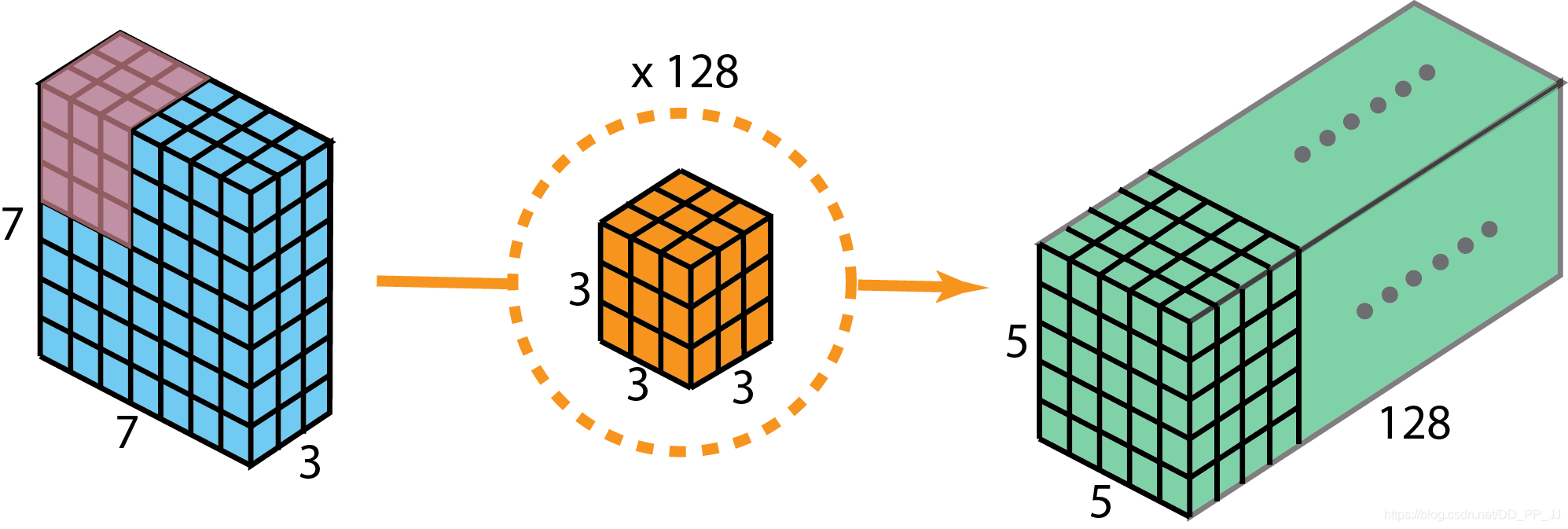
以上图为例,普通卷积需要的计算量为:
对应128个3x3x3的卷积核移动5x5次的结果。
深度可分离卷积计算量应该分为两个部分:
第一步:depthwise convolution 有3个3x3x1的kernel移动5x5次。
第二步:1x1 convolution 有128个1x1x3的kernel移动5x5次。
两步总计10275次乘法,只有普通卷积计算量的12%左右。
推广一下,对于一个输入尺寸为[C,H,W]的feature map, 如果用stride=1、padding=0、kernel size=h(h为奇数),那么输出的尺寸为[N_c, H-h+1, W-h+1]。
普通卷积需要的乘法次数为:
深度可分离卷积所需要乘法次数为:
代价比为:
在Nc>>h的情况下,代价比可约等于h的平方分之一。
同样,深度可分离卷积也有缺点,通过使用深度可分离卷积替代普通的卷积,可以显著降低模型的计算量,但是与此同时会导致模型的容量也显著降低。这将导致训练得到的结果可能也不是最优的。因此,在使用深度可分离卷积的时候要考虑模型容量和计算效率的平衡。
6. Flattened Convolutions¶
最初在Flattened Convolutional Neural Networks for Feedforward Acceleration中提出,是2015年ICLR的workshop。(链接:https://arxiv.org/abs/1412.5474)

在了解了空间可分离卷积以后,再来看Flattened Convolutions就比较简单了,Flattened Convolution将标准的卷积核拆分成3个1D卷积核(空间可分离卷积只拆分HxW维度),可以极大地降低了计算成本。
论文在结论中提到,使用Flattened Convolutions能够将计算量减少为原来的10倍,并可以达到类似或更高的准确率在CIFAR-10、CIFAR-100和MNIST数据集中。
深度学习中的学习型滤波器具有分布特征值,直接将分离应用在滤波器中会导致严重的信息损失,过多使用的话会对模型准确率产生一定影响。
7. Shuffled Grouped Convolutions¶
最初是在ShuffleNet中提出的,使用了pointwise group convolution和channel shuffle两种操作,能够在保持精度的同时极大地降低计算量。之前解读的ThunderNet也是在ShuffleNetV2为基础进行改进的。
Channel Shuffle操作主要是为了消除原来Grouped Convolution中存在的副作用,也就是输出feature map的通道仅仅来自输入通道的一小部分,因此每个滤波器组仅限于学习一些特定的特性,如下图(a)所示。
Grouped Convolution的这个属性会阻碍信息在通道组之间的信息流动并削弱了模型的表达。通过使用Channel Shuffle可以促进通道间信息的融合从而解决以上问题。
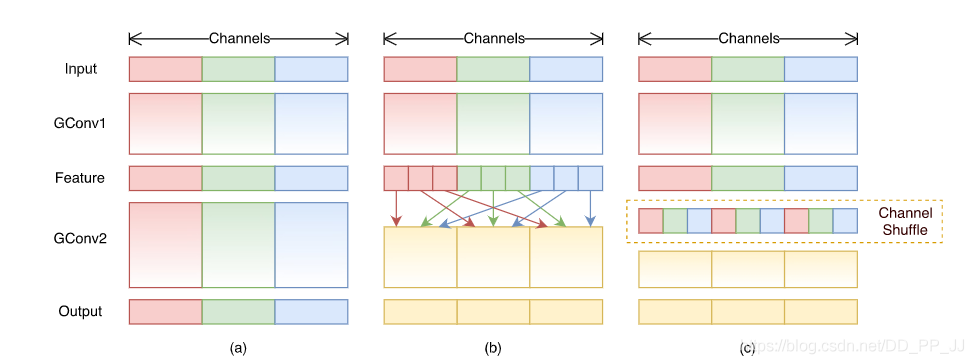
从上图中,(a)代表的是组卷积,所有输出只和一部分输入有关(b)代表的是Channel Shuffle组合的方式,不同的组内部进行了重排,都是用到了输入的一部分(c)代表的是一种与(b)等价的实现方式。
ShuffleNet还用到了pointwise grouped convolution, 作者认为1x1卷积成本也非常高,所以也对1x1卷积使用组卷积,具体模块化的设计如下图(b)和©所示。
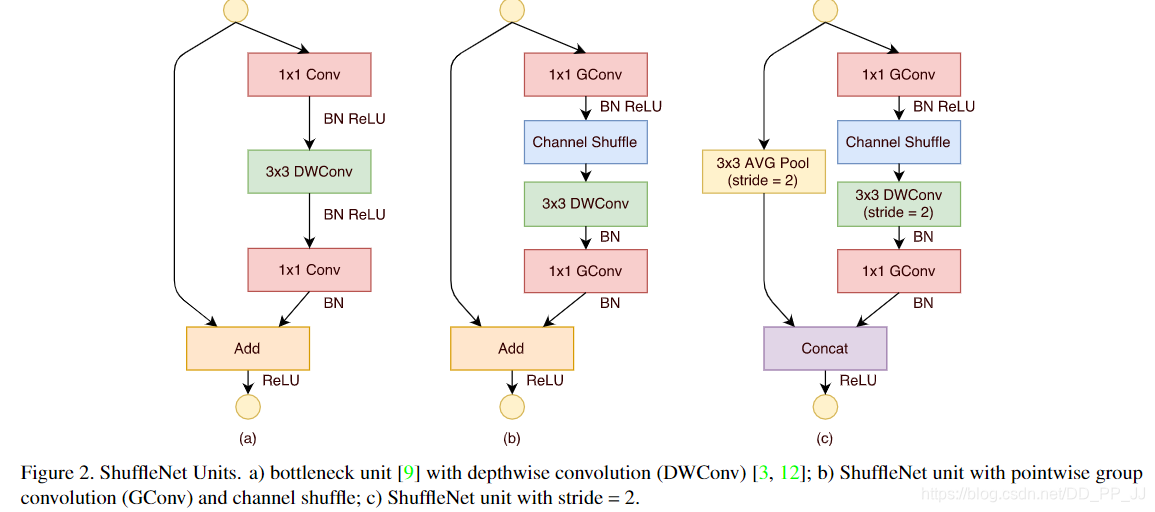
所以实际上用到了三种类型的卷积:
- shuffled grouped convolution = grouped convolution + Channel Shuffle
- pointwise grouped convolution = 1x1 convolution + grouped convolution
- depthwise separable convolution
8. Dilated Convolution(Atrous Convolution)¶
空洞卷积是在DeepLabv1和《Multi-scale context aggregation by dilated convolutions》中提出的。
空洞卷积是在kernel之间插入空洞,并引入了空洞率,普通卷积如下图(a)所示,其空洞率为1, (b)中所示的Dilated Convolution的空洞率为2,©中空洞率为4。
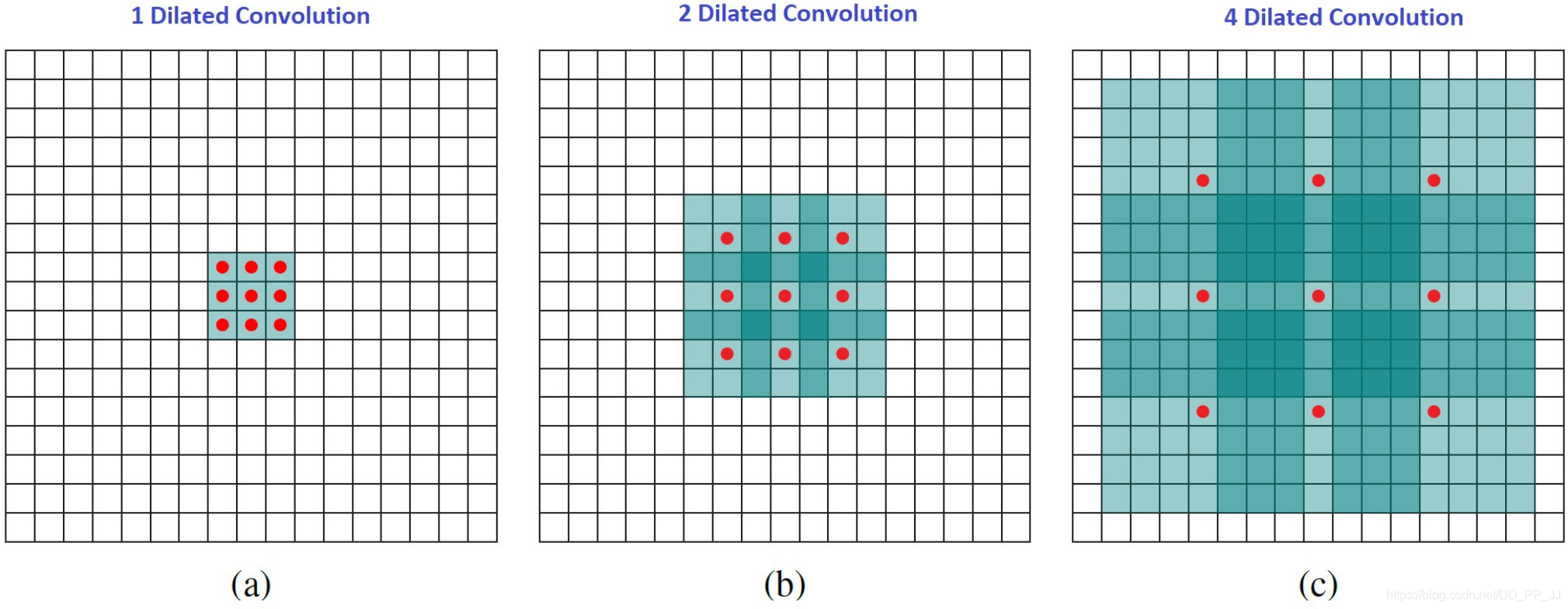
上图中浅绿色的正方形块代表Dilated Convolution对应的感受野, 颜色越深代表其被覆盖的次数越多。而以上三种方法所需要的计算量是相等的,也就是说,空洞卷积能够在不增加计算量的情况下,增加模型的感受野。并且如果使用多个空洞卷积组成多层结构来构建网络,有效感受野将呈指数级增长,而所需要的参数数量仅仅呈线性增长。
空洞卷积用于多尺度的上下文信息,并且不会丢失分辨率,在其应用到语义分割模型后,达到了当时的STOA。
不过也存在几个问题:
- Gridding Effect:
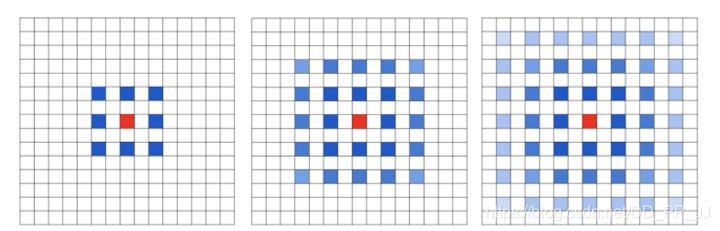
上图是具体使用到的结点,可以发现kernel并不连续,并不是所有的点都被计算了,这会导致损失信息的连续性,对细粒度信息处理(pixel-level dense prediction)来说并不友好。
- 上下文信息多少
dilated convolution可以获取长距离信息,使用dilated convolution对大物体的效果会有一定效果,但是对小物体来说并不友好,小物体所需要的感受野并不需要太大。所以如何同时处理好不同大小物体之间的关系是使用空洞卷积的关键。
9. Deformable Convolution¶
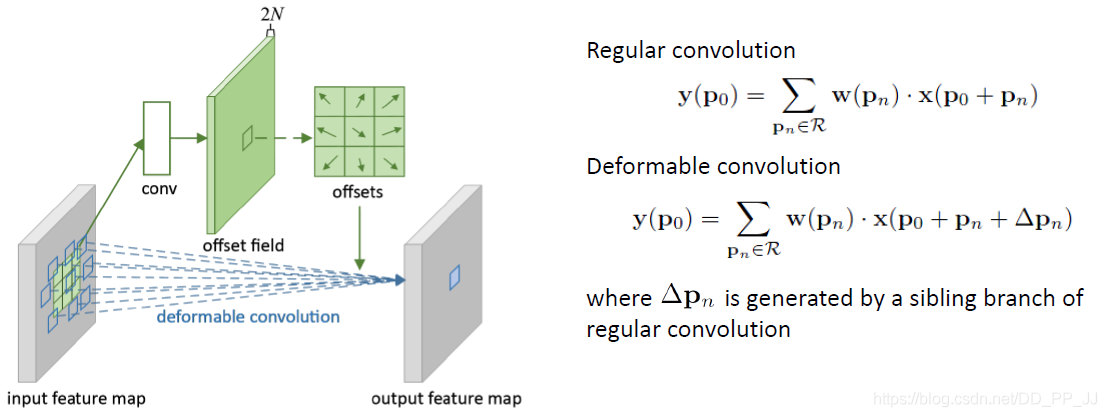
可变形卷积(DCN) 是一个特别新颖的想法,最初是为了提升目标检测模型,提出以后也成为刷榜利器。
DCN提出的动机是为何特征提取形状一定要是正方形或者矩形,为何不能更加自适应的分布到目标上(如下图右侧所示),进而提出了一种形状可学习的卷积。
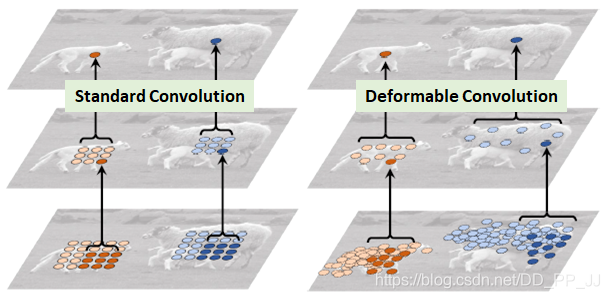
实现过程如下图所示,在普通卷积之外又添加了一个分支,专门用于学习每个点的偏移量,将原始的卷积和offset结合就形成了可变形卷积。
10. Attention¶
这里介绍两个最经典的注意力机制的模块,SE Module和CBAM Module。
10.1 Squeeze and Excitation¶
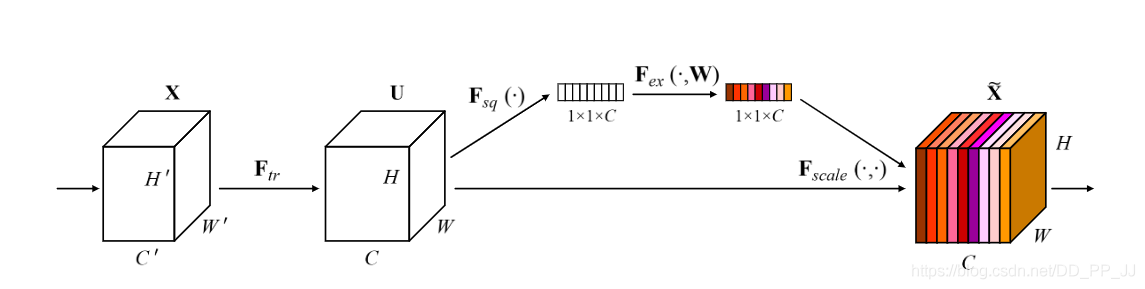
SENet的核心想法是,每个通道的重要性不是一样的。基于这个想法,SENet添加了一个模块,如上图靠上的分支,这个模块作用是给每个通道打分,最终将打分的结果与卷积得到的feature map相乘,完成特征通道的权重重分配。SENet是通道注意力机制的最经典的实现。
pytorch实现:
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
其具体实现也非常简单,值得一提的是,SENet成功拿到了ImageNet2017分类比赛的冠军。
缺点:不利于并行处理,添加SELayer以后导致在GPU上运行速度有一定的减慢。
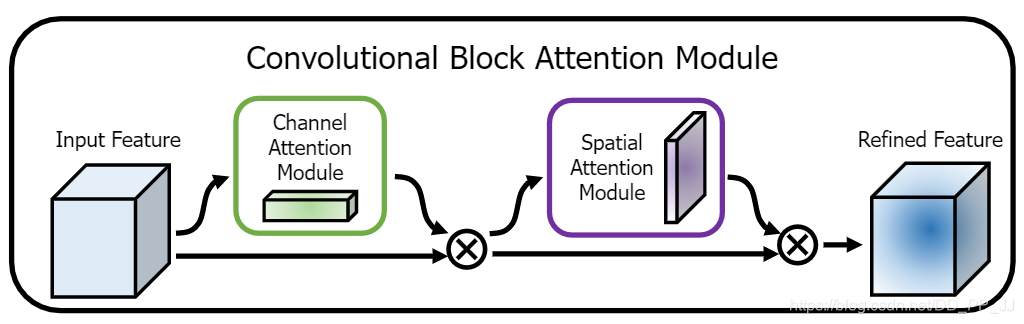
10.2 Convolutional Block Attention Module¶
CBAM模块算是比较早的一批将通道注意力机制和空间注意力机制结合起来的模型,通过添加该模块,能在一定程度上优化feature。
CBAM分为Channel Attention Module 和 Spatial Attention Module:
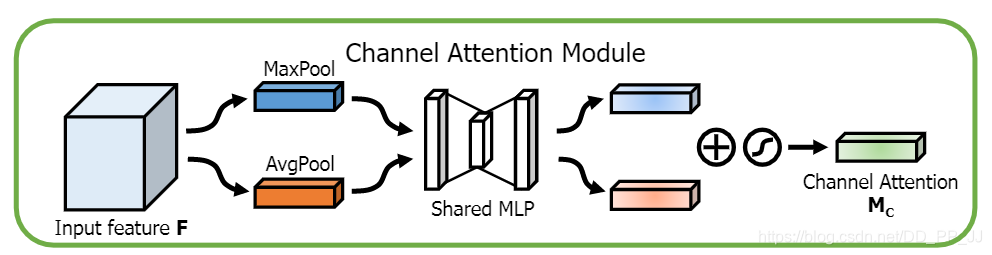
pytorch实现通道注意力机制:
class ChannelAttention(nn.Module):
def __init__(self, in_planes, rotio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.sharedMLP = nn.Sequential(
nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False), nn.ReLU(),
nn.Conv2d(in_planes // rotio, in_planes, 1, bias=False))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = self.sharedMLP(self.avg_pool(x))
maxout = self.sharedMLP(self.max_pool(x))
return self.sigmoid(avgout + maxout)
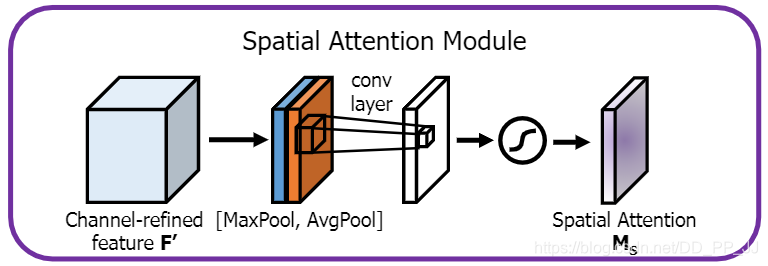
pytorch实现空间注意力机制:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3,7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avgout, maxout], dim=1)
x = self.conv(x)
return self.sigmoid(x)
最终CBAM模块选择将两个部分进行串联:
11. Summary¶
卷积核的设计非常多,以上仅仅是一部分常见的卷积核,以上卷积核可以这样分类:
-
通道和空间
- Convolution
- 1x1 Convolution
- Spatial and Cross-Channel Convolutions
-
通道相关性(channel)
- Depthwise Separable Convolutions
- Shuffled Grouped Convolutions
- Squeeze and Excitation Network
- Channel Attention Module in CBAM
- 空间相关性(HxW)
- Spatially Separable Convolutions
- Flattened Convolutions
- Dilated Convolutions
- Deformable Convolution
- Spatial Attention Module in CBAM
现在很多CNN模型准确率越来越高,很多研究人员的研究方向也转向如何在尽可能保证准确率的情况下,尽可能减少模型参数,做好准确率和速度的平衡。
其中ShuffleNet系列效果得到了认可(ShuffleNetV2是腾讯扫一扫项目和ThudnerNet的backbone)。
总结一下效果优异的人工设计的backbone可能会用到以下策略:
-
单一尺寸卷积核用多个尺寸卷积核代替(参考Inception系列)
-
使用可变形卷积替代固定尺寸卷积(参考DCN)
- 大量加入1x1卷积或者pointwise grouped convolution来降低计算量(参考NIN、ShuffleNet)
- 通道加权处理(参考SENet)
- 用深度可分离卷积替换普通卷积(参考MobileNet)
- 使用分组卷积(参考ResNeXt)
- 分组卷积+channel shuffle(参考shuffleNet)
- 使用Residual连接(参考ResNet)
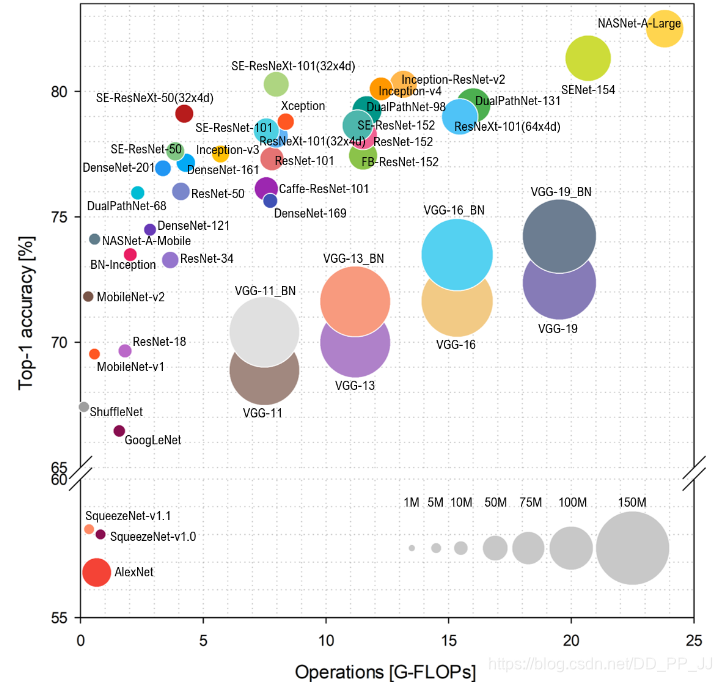
最后附上一个18年综述《Benchmark Analysis of RepresentativeDeep Neural Network Architectures》中的图,文章也提供了代码:https://github.com/CeLuigi/models-comparison.pytorch
致谢:感谢Kunlun Bai,本文中使用了不少便于理解的图都是出自这位作者。
Reference¶
https://ikhlestov.github.io/pages/machine-learning/convolutional-layers/
https://zhuanlan.zhihu.com/p/37910136
https://ikhlestov.github.io/pages/machine-learning/convolutions-types/
https://arxiv.org/abs/1610.02357
https://arxiv.org/abs/1704.04861
https://arxiv.org/pdf/1611.05431.pdf
https://arxiv.org/abs/1707.01083
http://fourier.eng.hmc.edu/e161/lectures/convolution/index.html
https://arxiv.org/pdf/1412.7062
https://arxiv.org/abs/1511.07122
https://arxiv.org/abs/1412.5474
https://www.zhihu.com/question/54149221
https://zhuanlan.zhihu.com/p/28749411
https://arxiv.org/pdf/1810.00736.pdf
本文总阅读量次