多项SOTA!SVDFormer-自增强自结构双生点云补全算法-ICCV2023论文详解¶
1. 方法前瞻¶
目前,点云补全任务只要存在以下两个挑战:利用不完整的点云中生成真实的全局形状,并生成高精度的局部结构。当前的方法要么仅使用3D坐标系,要么导入额外的标注好相机内部参数的图像,来指导模型补全缺失部分的几何。然而,这些方法并不总是完全利用可用于准确高质量点云补全的跨模态自结构信息。
针对上面的分析,本方案设计了一个自视图融合网络(Self-view Fusion Network),它利用从多个视角投影得到的深度图像来观察不完整的自形状,并生成一个紧凑的全局形状表示。
为了揭示的结构的细节,本文引入了一个称为自结构双生成器(Self-structure Dual-generator)的细化模块,该模块结合学习到的形状先验知识和几何自相似性来生成新点。通过感知每个点的不完整性,该双路径设计根据每个点的结构类型,采取细化的策略。
大量实验表明,我们的模型在多项测试中都取得了最先进的性能。
文章链接:https://arxiv.org/abs/2307.08492
代码链接:https://github.com/czvvd/SVDFormer
2. 背景补充¶
近年来,已经提出了几种方法来直接处理点,通过端到端的网络。一个开创性的基于点的工作是PCN,它使用共享的多层感知器(MLP)来提取特征,并使用从粗到细的折叠操作生成额外的点。
由于点数据中可用的信息有限,辅助输入被用来提高性能,基于跨模态的方法横空出世。这种方法将渲染的彩色图像以及对应的相机参数和局部点云组合起来。虽然这些方法显示了不错的结果,这种对应的额外输入难以获得。
考虑到上述缺陷,本设计提出让模型从多个角度观察输入点云结构的2D图像,并将其作为额外输入来辅助模型理解整体形状。我们的实现了模型对整体形状更全面的感知,而且无需额外的信息或训练期间的可微渲染。我们的的特点是将形状细化任务分解为两个子目标,并针对不同的局部区域自适应地提取可靠的特征。
3. 方法详解¶
SVDFormer的输入包含三个部分:(1)不完整和低分辨率点云P_{in} \subseteq \mathbb{R}^{N \times 3},(2)N_V个相机位置V_P \subseteq \mathbb{R}^{N_V \times 3},(3)N_V个深度图D \subseteq \mathbb{R}^{N_V \times 1 \times H \times W}。之后,以从粗到细的方式估计一个完整的点云P_2 \subseteq \mathbb{R}^{N_2 \times 3}。
模型的整体架构包含两个部分,如图1所示:一个SVFNet和一个配备两个SDG模块的精细化模块。首先SVFNet利用点云从多个视角自投影的产生的深度图生成一个全局补全形状P_0 \subseteq \mathbb{R}^{N_0 \times 3}。随后,两个SDG逐渐细化点云和上采样P_0以产生具有高度结构细节的最终点云P_2。
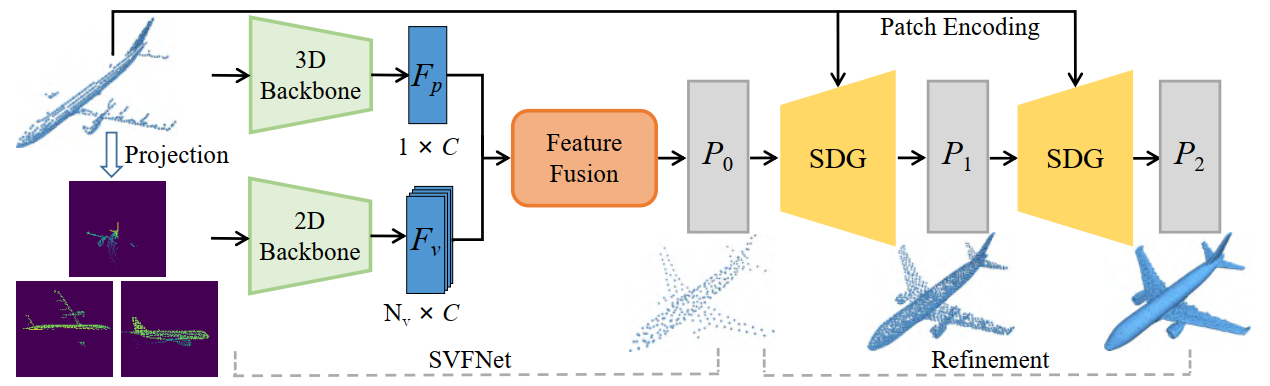
3.1 SVFNet¶
SVFNet的目的是从不同的视角观察部分输入,并学习一个有效的描述,来产生一个全局合理的完整形状。首先从P_{in}中使用基于点的3D骨干网络提取一个全局特征F_p,并从N_V个深度图中使用基于CNN的2D骨干网络提取一组视图特征F_V。这里直接采用了早期成熟的骨干网络。具体来说,采用了三个集合抽象层的PointNet++对P_{in}进行分层编码,采用ResNet-18模型作为2D骨干网络。
但是,如何有效融合上述跨模态特征是一个挑战。为了解决这个问题,作者提出了一个新的特征融合模块,将F_p和F_V融合产生全局形状描述符F_g,然后是一个解码器生成全局形状P_c。解码器使用1D卷积转置层将F_g变换为一组逐点特征,并用一个自注意力层回归3D坐标。最后,合并P_c和P_{in}并对合并的结果进行重采样以生成粗略结果P_0。
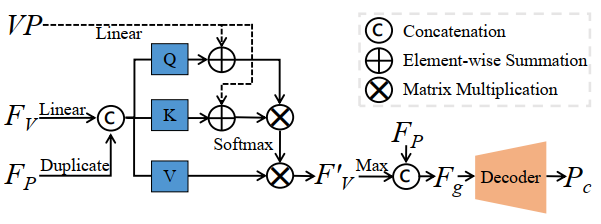
特征融合。如图2所示,F_V首先通过线性映射变换为查询、键和值标记,并在F_P的指导下计算注意力权重。然后,为了增强视图特征的可辨别性,在投影视点VP的条件下,根据查询和键标记计算注意力权重。详细地讲,通过线性变换将VP映射到潜在空间,然后将它们用作特征融合的位置信号。在元素乘积之后,F_V'中的每个特征集成了来自其他视图在F_P指导下的关系信息。最后,通过最大池化获得全局形状描述符F_g。
3.2 SDG¶
SDG的目的是根据缺失表面区域的结构类型,生成一组坐标偏移来微调和上采样粗糙形状。为实现这个目的,SDG被设计为双通道结构,如图3所示,它包含两个并行单元,分别称为结构分析单元和相似度校准单元。总体而言,输入P_{in}和上一步输出的粗略点云P_{l-1},我们获得组合的逐点特征F_l \subseteq \mathbb{R}^{N \times 2C}。F_l包含两种来源的形状信息:一个来自学习到的形状先验,而另一个来自于在P_{in}中发现的相似几何图案。然后,将F_l投影到更高维空间并重塑来产生一组上采样偏移O_l \subseteq \mathbb{R}^{rN \times 3},其中r代表上采样率。预测的偏移量之后被添加回P_{l-1}得到一个新完成结果。注意,SDG迭代两次,如图1所示。

3.2.1 结构分析单元¶
由于来自缺失区域的几何细节很难恢复,本方案嵌入了一个不完整性感知自注意力层,来明确鼓励网络关注更多在缺失的区域。具体来说,P_{l-1}首先与形状描述符F_g拼接,然后通过线性层嵌入为一组逐点特征F_{l-1} = \{f_i\}_{i=1}^{N_{l-1}}。接下来,F_{l-1}被馈送到不完整性感知自注意力层以获得一组特征F_Q = \{q_i\}_{i=1}^{N_{l-1}},其中编码了逐点不完整性信息。q_i计算如下:
\begin{equation} q_i = \sum_{j=1}^{N_{l-1}} a_{i,j} (f_j W_V) \end{equation}
\begin{equation} a_{i,j} = \mathrm{Softmax}((f_i W_Q + h_i) (f_j W_K + h_j)^T) \end{equation}
其中W_Q、W_K和W_V是可学习矩阵,大小为C \times C。h_i是一个向量,表示P_{l-1}中每个点x的不完整程度。直观来看,缺失区域中的点倾向于与部分输入有更大的距离值。因此我们通过下式计算不完整性:
\begin{equation} h_i = \mathrm{Sinusoidal}(\frac{1}{\gamma} \min_{y \in P_{in}} \|x - y\|) \end{equation}
其中\gamma是一个缩放系数。我们在实验中将其设置为0.2。使用正弦函数确保h_i与查询、键和值的嵌入具有相同的维度。最后将F_Q解码为F'_Q进行进一步分析粗糙形状。
3.2.2 相似度对齐¶
相似度校准单元为P_{l-1}中的每个点利用P_{in}中的潜在相似局部模式,解决由点云无序性导致的特征不匹配问题。之后,使用三个EdgeConv层提取一组下采样的逐点特征F_{in}。F_{in}中的每个向量捕获了局部上下文信息。由于可能存在长程相似结构,作者通过交叉注意力执行特征交换。计算过程与vanilla自注意力类似,唯一的不同在于查询矩阵是由F_Q产生的,而F_{in}充当键和值向量。交叉注意力层输出逐点特征F_H \subseteq \mathbb{R}^{N_{l-1} \times C},将P_{in}中的相似局部结构集成到粗糙形状P_{l-1}中的每个点。通过这种方式,这个单元可以建模两个点云之间的几何相似性,并促进带有相似结构的点在输入中的细化点云。与结构分析单元类似,F_H也被解码为一个新的特征F'_H。这两个解码器具有相同的架构,都是由两个自注意力层实现。
3.3 损失函数¶
为了测量生成的点云和真值点云P_{gt}之间的差异,我们使用Chamfer距离(CD)作为我们的损失函数,这是最近工作中的常见选择。为实现从粗糙到精细的生成过程,我们通过以下方式正则化训练:
\begin{equation} L = L_{CD}(P_c, P_{gt}) + \sum_{i=1,2} L_{CD}(P_i, P_{gt}) \end{equation}
值得注意的是,我们对P_{gt}下采样到与P_c、P_1、P_2相同的密度,以便计算损失。
4. 实验结果¶
综合实验表明,我们的方法在广泛使用的基准测试上实现了最先进的性能。
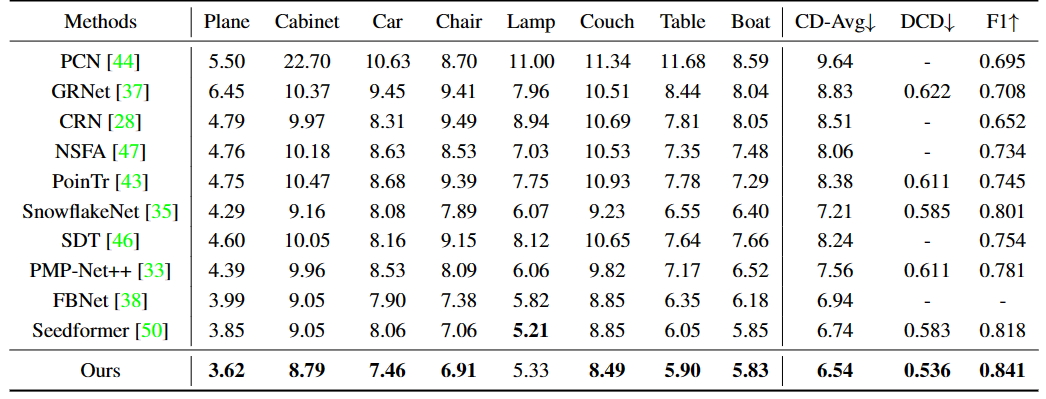
PCN数据集的定量结果
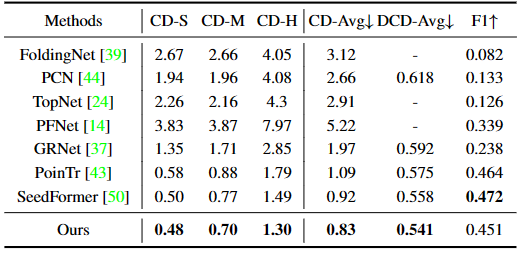
ShapeNet-55上的定量结果。CD-S、CD-M和CD-H分别代表易难度、中等难度和难难度级别下的CD值
ShapeNet-34上的定量结果

真实世界扫描的定量结果

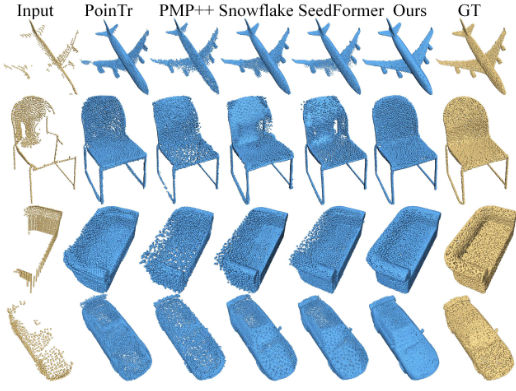
实验结果可视化

5. 总结分析¶
本研究提出了一种新的神经网络架构SVDFormer用于点云补全。SVDFormer利用自我投影的多视图分析来理解整体形状,并有效地感知缺失区域。此外,本方案引入了一个称为自监督双生成器的解码器,它将形状细化点云过程分解为两个子目标。最后,实验表明,SVDFormer在各种类型的点云上实现了最先进的点云补全性能。
本文总阅读量次