通过整合IMU运动动力学实现尺度感知、鲁棒和可推广的无监督单目深度估计¶
0. 引言¶
虽然近年来无监督单目深度学习取得了很大的进展,但仍然存在一些基本问题。首先,目前的方法存在尺度模糊性问题,因为反推过程对于深度和平移来说相当于任意尺度因子。其次,光度误差对照明变化和移动物体敏感。此外,尽管在无监督学习框架下已经为光度误差图引入了不确定性,但自我运动的不确定性度量仍然是重要的。在2022 ECCV论文"Towards Scale-Aware, Robust, and Generalizable Unsupervised Monocular Depth Estimation by Integrating IMU Motion Dynamics",作者提出了一种感知框架,通过集成视觉和IMU来进行真实尺度估计,算法已经开源。
1. 论文信息¶
标题:Towards Scale-Aware, Robust, and Generalizable Unsupervised Monocular Depth Estimation by Integrating IMU Motion Dynamics
作者:Sen Zhang, Jing Zhang, Dacheng Tao
来源:2022 European Conference on Computer Vision (ECCV)
原文链接:https://arxiv.org/abs/2207.04680
代码链接:https://github.com/SenZHANG-GitHub/ekf-imu-depth
2. 摘要¶
近年来,无监督单目深度和自我运动估计引起了广泛的研究关注。尽管当前的方法已经达到了很高的尺度精度,但是由于利用单目序列进行训练所固有的尺度模糊性,它们通常不能学习真实的尺度度量。在这项工作中,我们解决了这个问题,并提出了DynaDepth,一种新的尺度感知框架,集成了视觉和IMU运动动力学的信息。具体来说,我们首先提出了IMU光度损失和跨传感器光度一致性损失,以提供稠密的监督和绝对尺度。为了充分利用来自两个传感器的互补信息,我们进一步驱动一个可微分的以相机为中心的扩展卡尔曼滤波器(EKF),以在观察视觉测量时更新IMU预积分。此外,EKF公式使得能够学习自我运动不确定性测量,这对于无监督的方法来说不是微不足道的。通过在训练过程中利用IMU,DynaDepth不仅学习了绝对尺度,还提供了更好的泛化能力和对光照变化和移动物体等视觉退化的鲁棒性。我们通过在KITTI和Make3D数据集上进行大量实验和仿真,验证了DynaDepth的有效性。
3. 算法分析¶
如图1所示是作者提出的单目尺度感知深度估计和自我运动预测方法DynaDepth的概述,该系统在以相机为中心的扩展卡尔曼滤波器(EKF)框架下,将IMU运动动力学显式集成到基于视觉的系统中。DynaDepth旨在联合训练尺度感知深度网络Md,以及融合IMU和相机信息的自我运动网络Mp。
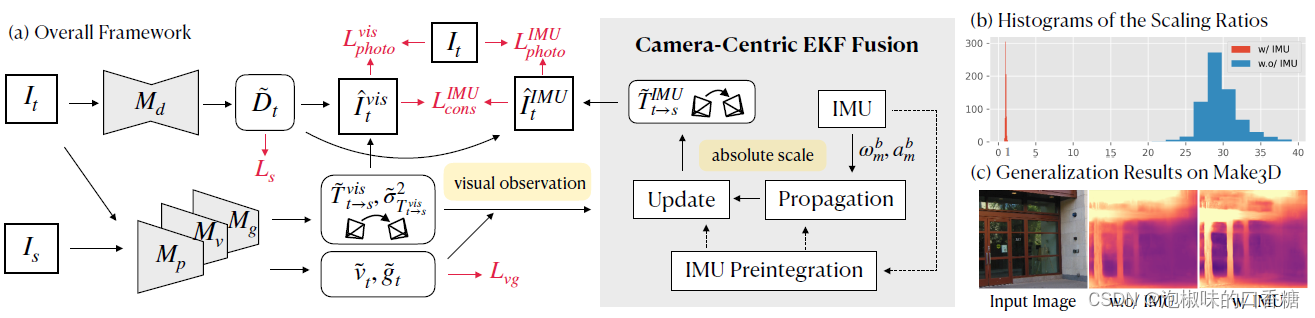
图1 DynaDepth概述
DynaDepth通过使用IMU的估计运动执行反向操作,来构建尺度感知的IMU光度损失,并使用基于外观的光度损失。为了校正由光照变化和运动物体引起的误差,作者进一步提出了跨传感器光度一致性损失,分别使用网络预测和IMU集成自我运动的合成目标视图。
与积累来自初始帧的重力和速度估计的经典VIO-SLAM系统不同,对于无监督深度估计方法,这两个度量是未知的。为了解决这个问题,DynaDepth训练两个超轻型网络,这两个网络将两个连续帧作为输入,并在训练期间预测以相机为中心的重力和速度。
考虑到IMU和相机提供两种互补的独立传感模式,作者进一步为DynaDepth导出了一个可区分的以相机为中心的EKF框架,以充分利用这两种传感器。当从相机观察新的自我运动预测时,DynaDepth根据IMU误差状态和视觉预测的协方差更新IMU预积分。这样一方面可以通过视觉来纠正IMU噪声偏差,另一方面还提供了一种学习预测自我运动的不确定性测量的方式,这对于最近出现的将深度学习纳入经典SLAM系统以实现学习、几何和优化的协同作用的研究方法是有益的。
综上所述,作者所做工作的主要贡献如下:
1 提出了IMU光度损失和交叉传感器光度一致性损失,以提供稠密的监督和绝对尺度;
2 为传感器融合推导了一个可微分的以相机为中心的EKF框架;
3 通过在KITTI和Make3D数据集上的大量实验和仿真证明了DynaDepth有利于:\<1>绝对尺度的学习;\<2>泛化能力;\<3>对诸如照明变化和移动物体的视觉退化的鲁棒性;\<4>自我运动不确定性度量的学习。
3.1 IMU光度损失¶
如果直接将训练损失写为IMU预积分项上的残差,那么就只能为自我运动网络提供稀疏的监督,作者提出了一种IMU光度损失:
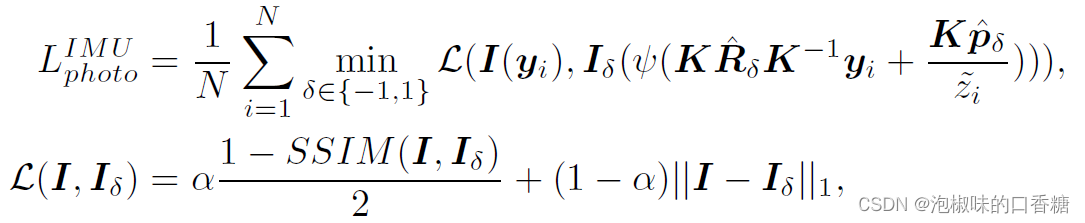
其中K和N是相机的固有特性,yi和zi是图像中的像素坐标系以及由Md预测的深度,I(yi)是yi处的像素强度,ψ()表示深度归一化函数,SSIM()表示结构相似性索引。
3.2 交叉传感器光度一致性损失¶
作者进一步提出跨传感器光度一致性损失来对齐IMU预积分和Mp的自我运动,而不是直接比较。对于自我运动,作者使用反向图像之间的光度误差,这为Md和Mp提供了更密集的监督信号:
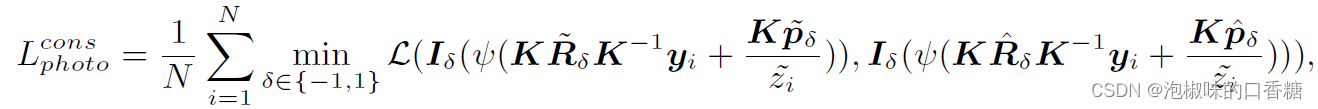
此外,DynaDepth中的总训练损失Ltotal还包括基于视觉的光度损失Lvis、平滑度损失Ls以及弱L2范数损失Lvg:
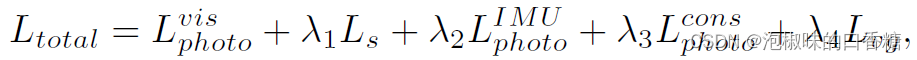
3.3 以相机为中心的EKF融合框架¶
为了充分利用互补的IMU和相机,作者提出了一个以相机为中心的EKF框架。与之前将EKF集成到基于深度学习的框架中以处理IMU数据的方法不同,DynaDepth不需要真实的自我运动和速度来获得每个IMU帧的对齐速度和重力,而是提出{Mv,Mg}来预测。在论文中,作者推导了该EKF的传播和更新过程。
EKF传播:设ck表示时刻tk的相机帧,bt表示tk到tk+1之间的IMU帧,误差状态为:
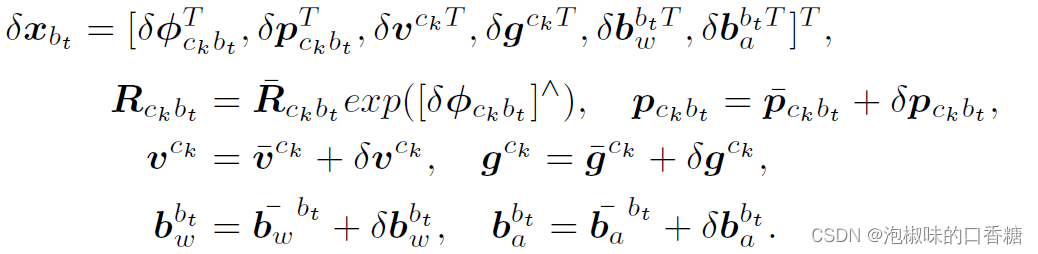
EKF利用一阶泰勒近似将状态转移模型在每个时间步线性化进行传播,误差状态的连续时间传播模型为:δx*bt = Fδxbt + Gn,其中F和G为:
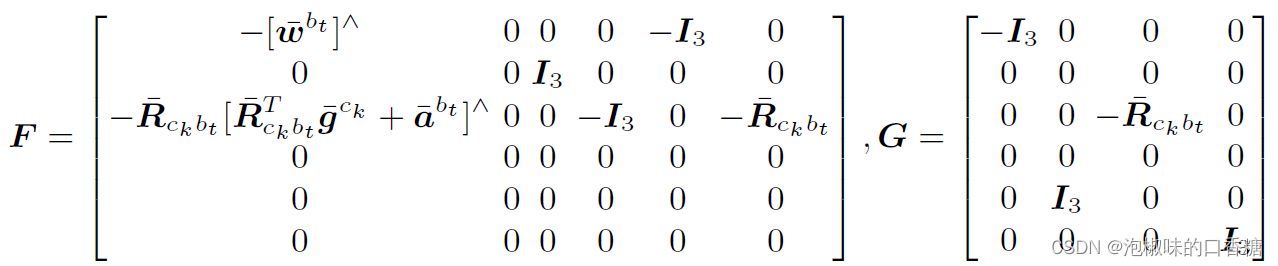
EKF更新公式为:
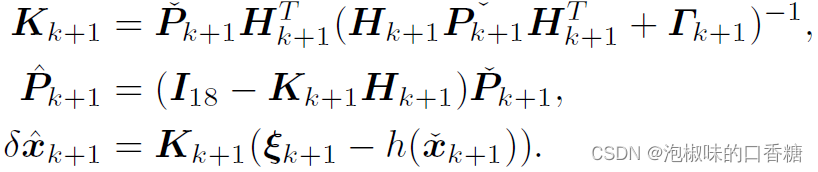
DynaDepth将观测量定义为Mp预测的自我运动,为了完成以相机为中心的EKF更新步骤,可推导h和H为:
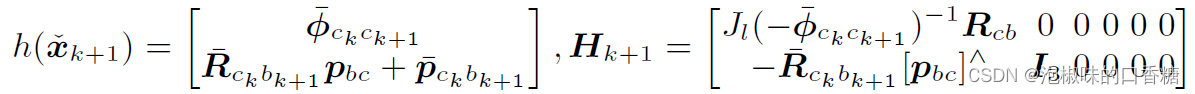
4. 实验¶
作者评估了DynaDepth在KITTI上的有效性,以及在Make3D上的泛化能力。此外,作者对IMU损耗、EKF框架、学习到的自我运动不确定性以及对光照变化和移动物体的鲁棒性进行了消融实验。在具体试验阶段,损失函数的四个权重依次为0.001,0.5,0.01,0.001,初始学习率为1e-4,在一个NVIDIA V100 GPU上训练了30轮。
4.1 KITTI上的尺度感知深度估计¶
如表1所示是将DynaDepth与最新的单目深度估计方法进行比较的结果,作者为了公平比较只给出了图像分辨率为640x192和尺寸适中的编码器所取得的结果,即ResNet18(R18)和ResNet50(R50)。
表1 对KITTI进行的每张图像的重定标深度评估
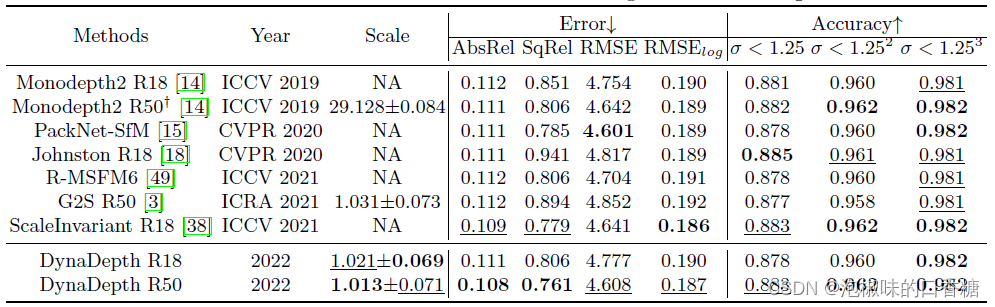
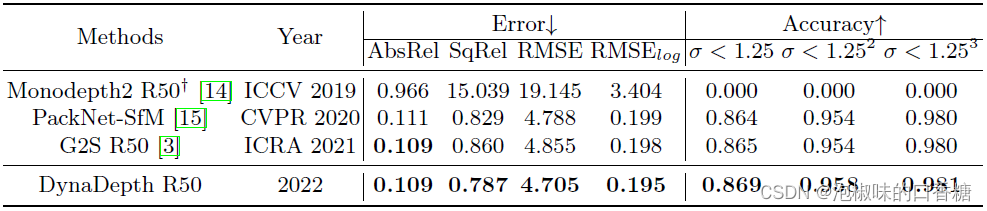
除了标准的深度评价指标之外,作者还报告了重尺度因子的均值和标准误差来证明尺度感知能力。值得注意的是DynaDepth达到了一个近乎完美的绝对尺度,在尺度感知方面甚至R18版本也优于G2S R50 ,而后者使用了更重的编码器。如表2所示是对比结果,并与利用GPS信息构造速度约束的PackNet-SfM和G2S进行了比较。在这种情况下,DynaDepth实现了所有度量指标的最佳性能,为单目方法的非尺度深度评估设定了一个新的基准。为了更好的说明,图1(b)给出了包含IMU和不包含IMU的比例直方图。
表2 在KITTI进行深度评估结果
4.2 Make3D上的泛化¶
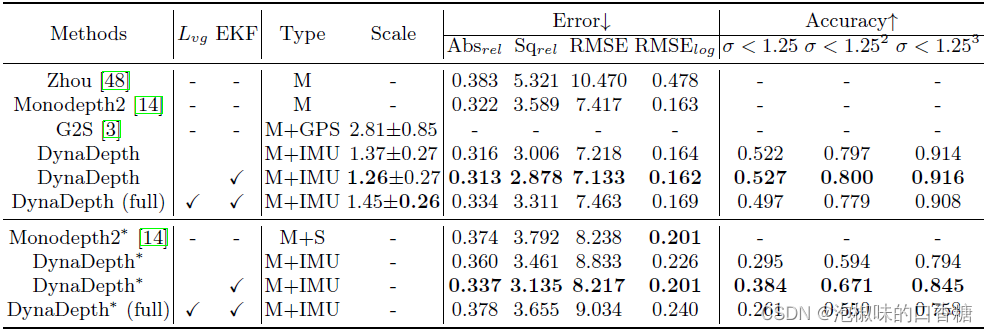
作者利用KITTI上训练的模型进一步检验DynaDepth在Make3D上的泛化能力,图1©给出了一个定性示例,其中没有IMU的模型在玻璃和阴影区域失效,而DynaDepth实现了可区分的预测。定量结果如表3所示,DynaDepth取得了相当好的尺度比例,表明DynaDepth学习的尺度能力可以很好地推广到不可观测的数据集。
此外,仅利用陀螺仪和加速度计IMU信息的DynaDepth取得了最好的泛化效果。作者解释了可能的原因:首先,由于建模能力的提高,完整模型可能会过拟合KITTI数据集。第二,因为Mv和Mg都以图像作为输入,性能退化可能是由于视觉数据的域间隙造成的,这也解释了这种情况下G2S的尺度损失。此外,实验也表明EKF有明显的提高泛化能力,可能是因为EKF融合框架考虑了不确定性,以更合理的方式融合了可泛化IMU动力学和特定视觉信息。
表3 Make 3d上的泛化结果
4.3 消融研究¶
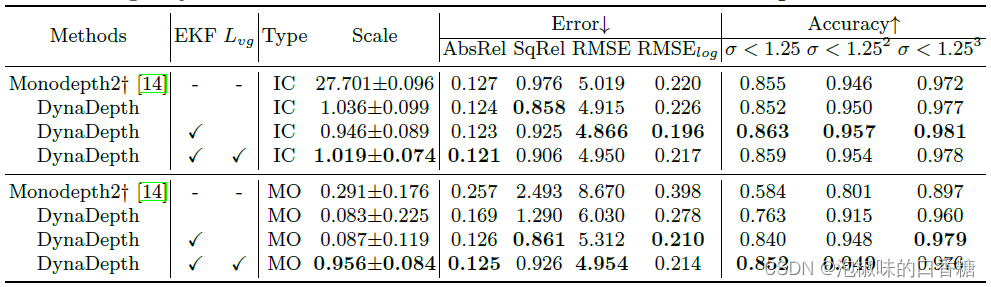
作者对KITTI进行了消融研究,并关注IMU相关损失、EKF融合框架和学习自我运动不确定性对KITTI的影响,结果如表4所示。此外,还设计了模拟实验来验证DynaDepth对光照变化和运动物体等视觉退化的鲁棒性。
表4 KITTI上IMU相关损失和EKF融合框架的消融结果
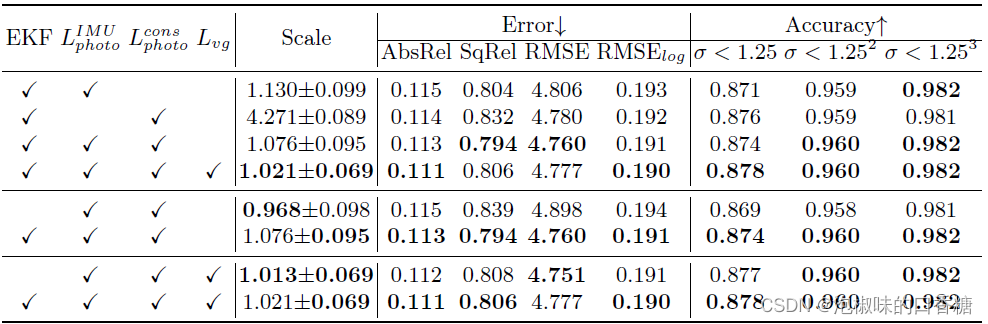
结果显示,IMU光度损失具有重要作用。但仅用IMU光度损失学习的只是一个粗略的尺度。将IMU光度损失和交叉传感器光度损失结合在一起,可以提高准确性,Lvg的使用进一步增强了评价结果。
针对光照变化和运动物体,这两种情况违反了光度损失的底层假设。作者通过在0.5范围内随机交替的图像对比度来模拟光照变化,通过随机插入三个150x150的黑色方块来模拟运动物体,结果如表5所示。在光照变化下,Mono deep2的精度按预期下降,DynaDepth则在一定程度上挽救了精度,保持了正确的绝对尺度。在这种情况下,EKF几乎改进了所有的度量指标,使用EKF和Lvg在AbsRel上达到了最优。然而,没有Lvg的模型在大多数度量指标上都取得了最好的性能,其原因可能是Lvg对视觉数据的依赖性,对图像质量更加敏感。当存在移动对象时,Mono deep2完全失败,使用EKF显著地提高了性能,但考虑到任务的难度,仍然难以学习到尺度。在这种情况下,使用Lvg显著提供了强有力的规模监管,取得了良好的规模效果。
表5 对来自KITTI的模拟数据的鲁棒性消融结果
作者以平均协方差作为不确定性度量,图2说明了自我运动不确定性的训练过程。学习的不确定性表现出与深度误差(AbsRel)类似的模式,这意味着随着训练的继续,模型对其预测变得更加确定。此外,DynaDepth R50比R18具有更低的不确定性,表明更大的模型容量也有助于提高预测的可信度,但这种差异并不明显。
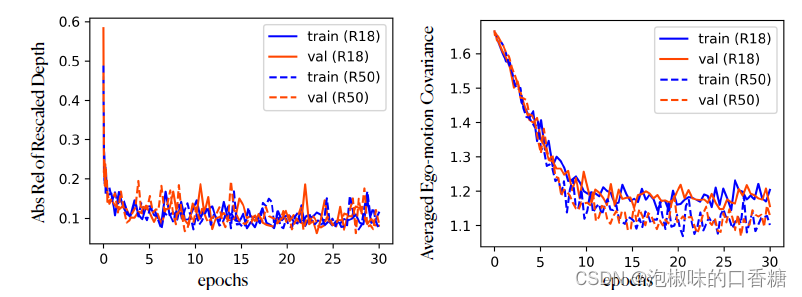
图2 训练过程
5. 结论¶
在2022 ECCV论文"Towards Scale-Aware, Robust, and Generalizable Unsupervised Monocular Depth Estimation by Integrating IMU Motion Dynamics"中,作者提出了DynaDepth,这是一个使用IMU运动动力学的尺度感知、鲁棒和可推广的单目深度估计框架。具体来说,作者提出了IMU光度损失和跨传感器光度一致性损失,以提供稠密的监督和绝对尺度。此外,作者为传感器融合推导了一个以摄像机为中心的EKF框架,它也提供了在无监督学习设置下的自我运动不确定性度量。最后作者通过实验证明了DynaDepth在学习绝对尺度、泛化能力和抵抗视觉退化的鲁棒性方面具有优势。
本文总阅读量次