Attention SLAM:一种从人类注意中学习的视觉单目SLAM¶
0. 引言¶
当人们在一个环境中四处走动时,他们通常会移动眼睛来聚焦并记住显而易见的地标,这些地标通常包含最有价值的语义信息。基于这种人类本能,"Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze"的作者提出了一种新的方法来帮助SLAM系统模拟人类导航时的行为模式。该论文为语义SLAM和计算机视觉任务提出了一种全新的模式。此外,作者公开了他们标注了显著性EuRoc数据集。
1. 论文信息¶
标题:Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze
作者:Jinquan Li, Ling Pei, Danping Zou, Songpengcheng Xia, Qi Wu, Tao Li, Zhen Sun, Wenxian Yu
来源:2020 Computer Vision and Pattern Recognition (CVPR)
原文链接:https://arxiv.org/abs/2009.06886v1
代码链接:https://github.com/Li-Jinquan/Salient-Euroc
2. 摘要¶
本文提出了一种新颖的同步定位与建图(SLAM)方法,即Attention-SLAM,它通过结合视觉显著性模型(SalNavNet)和传统的单目视觉SLAM来模拟人类的导航模式。大多数SLAM方法在优化过程中将从图像中提取的所有特征视为同等重要。然而,场景中的显著特征点在人类导航过程中具有更显著的影响。因此,我们首先提出了一个称为SalVavNet的视觉显著性模型,其中我们引入了一个相关性模块,并提出了一个自适应指数移动平均(EMA)模块。这些模块减轻了中心偏差,以使SalNavNet生成的显著图能够更多地关注同一显著对象。此外,显著图模拟了人的行为,用于改进SLAM结果。从显著区域提取的特征点在优化过程中具有更大的权重。我们将语义显著性信息添加到Euroc数据集,以生成开源显著性SLAM数据集。综合测试结果证明,在大多数测试案例中,Attention-SLAM在效率、准确性和鲁棒性方面优于Direct Sparse Odometry (DSO)、ORB-SLAM和Salient DSO等基准。
3. 算法分析¶
如图1所示是作者提出的Attention-SLAM架构,在架构主要是在基于特征点的视觉单目SLAM中加入显著性语义信息。首先,作者利用显著性模型来生成Euroc数据集的相应显著性图。这些图显示了图像序列中每一帧的重要区域。其次,作者采用它们作为权值,使特征点在BA过程中具有不同的权重。它帮助系统保持语义的一致性。当图像序列中存在相似纹理时,传统的基于特征点的SLAM方法可能会出现误匹配。这些失配点可能会降低SLAM系统的精度。因此,这种方法确保系统聚焦在最重要区域的特征点上,提高了准确性和效率。此外,作者还利用信息论来选择关键帧和估计姿态估计的不确定性。

图1 Attention-SLAM架构总览
作者的主要贡献如下:
1 作者提出了一种新颖的SLAM架构,即Attention-SLAM。该架构使用一种加权BA方法来代替SLAM中的传统BA。它能更有效地减小轨迹误差。通过在导航期间学习人类的注意,显著特征被用于具有高权重的SLAM后端。与基准相比,Attention-SLAM可以用更少的关键帧减少姿态估计的不确定性,并获得更高的精度。
2 作者提出了一个名为SalNavNet的视觉显著性模型来预测帧中的显著区域。主要在SalNavNet中引入了一个关联模块,并提出了一个自适应EMA模块。这些模块可以减轻显著性模型的中心偏差,并学习帧之间的相关性信息。通过减轻大多数视觉显著性模型所具有的中心偏差,SalNavNet提取的视觉显著性语义信息可以帮助Attention-SLAM一致地聚焦于相同显著对象的特征点。
3 通过应用SalNavNet,作者生成了一个基于EuRoc的开源显著数据集。使用显著性Euroc数据集的评估证明,Attention-SLAM在效率、准确性和鲁棒性方面优于各项基准。
3.1 SalNavNet网络架构¶
Attention-SLAM由两部分组成,第一部分是输入数据的预处理,第二部分是视觉SLAM系统。在第一部分,作者使用提出的SalNavNet生成对应于SLAM数据集的显著图。这些显著图被用作输入来帮助SLAM系统找到显著的关键点。
在帧序列中,显著物体的位置会随着镜头移动。由于现有显著性模型的中心偏差,只有当这些显著对象到达图像的中心时,显著性模型才将其标记为显著区域。当这些对象移动到图像的边缘时,显著性模型会忽略这些对象。注意力的转移使得视觉SLAM系统不能一致地聚焦于相同的显著特征。在Attention-SLAM中,作者希望显著性模型能够连续聚焦于相同的特征点,而不管它们是否在图像的中心。因此,作者应用的SalNavNet的网络结构如图2所示,它采用与SalEMA和SalGAN相同的编码器和解码器结构,其中编码器部分是VGG-16,解码器使用与编码器相反顺序的网络结构。SalNavNet可以在专注于上下文信息的同时,避免注意力的快速变化。
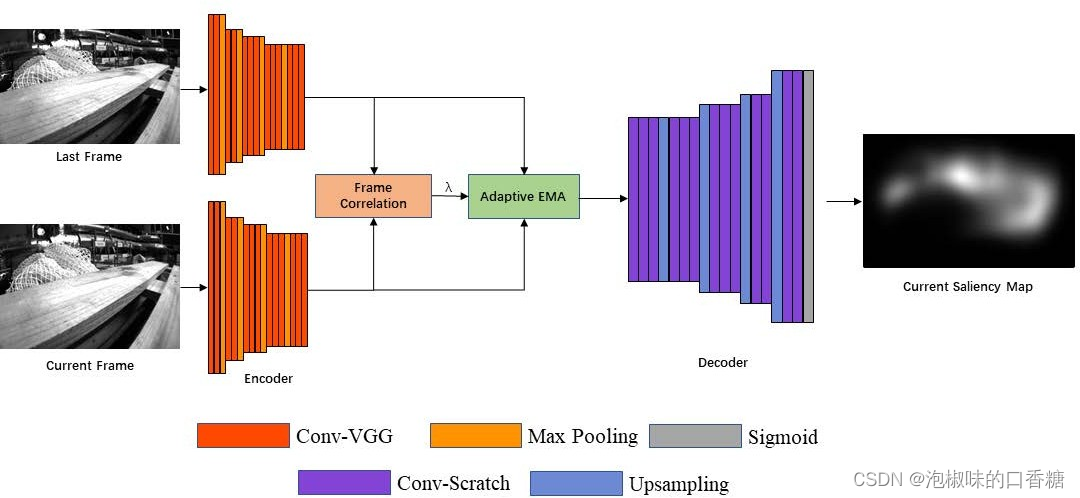
图2 SalNavNet架构
为了学习帧间的连续信息,作者首先利用图3所示的帧相关模块,通过编码器输出比较当前帧的特征图和通过编码器输出的前一帧的特征图。最后,得到两帧的相关系数λ,并将相关系数引入自适应EMA模块。当λ接近1时,表示两个特征图没有变化。当相邻特征图的差异较大时,会使λ的值变小。因此,当两个相邻特征图之间存在巨大变化时,显著性模型生成的显著性图具有快速的注意力变化。
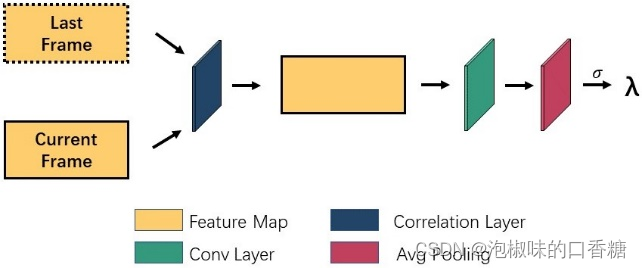
图3 帧相关模块架构
此外,作者设计了一个自适应EMA模块,如图4所示。一方面,自适应EMA模块允许模型学习帧之间的连续信息。另一方面,相似系数λ的引入减轻了显著模型的中心偏差和注意力的快速变化。在视觉显著性领域,注意力的快速变化可以更好地模仿数据集的真实数据。

图4 EMA模块架构
3.2 权重BA优化及关键帧选择¶
Attention-SLAM系统的第二部分使用显著图来提高优化精度和效率。作者使用视觉显著性模型生成的模型作为权值。显著性地图是灰度地图,其中白色部分的值为255,黑色部分的值为0。为了使用显著性映射作为权重,作者将这些映射归一化:
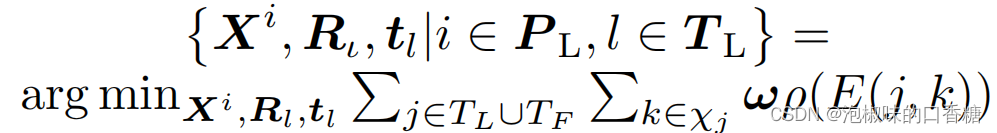
其中,重投影误差计算公式为:
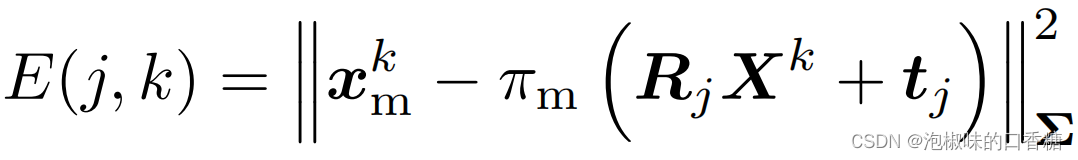
作者使用熵减少的概念作为选择关键帧的标准,以进一步提高Attention-SLAM系统的性能。具体来说有如下几个步骤:
1 利用熵比选择关键帧:在Attention-SLAM的运动估计过程中,使用如下表达式进行熵比计算:
在原文中,作者设置α的阈值为0.9。当一帧的熵比超过0.9时,它将不会被选为关键帧。因为这意味着当前帧不能有效地降低运动估计的不确定性。
2 熵缩减评估:显著性模型从环境中提取语义显著性信息,这可能会使Attention-SLAM估计的轨迹更接近轨迹真值。因此,作者从信息论的角度分析了Attention-SLAM对姿态估计的不确定性的影响。计算公式如下:
其中,n为关键帧数。作者主要计算ORB-SLAM和Attention-SLAM之间的熵缩减γ。如果Attention-SLAM在姿态估计过程中的不确定性小于ORB-SLAM,则γ将大于零。
4.实验¶
作者首先分析了不同显著性模型生成的显著性图对Attention-SLAM的影响,并使用显著性模型生成了一个新的显著性数据集,称为显著EuRoc。然后,作者在显著的Euroc数据集上将Attention-SLAM与其他SOTA的视觉SLAM方法进行比较。作者使用的计算设备为i5-9300H CPU (2.4 GHz)和16G RAM。
4.1 基于Attention-SLAM的图像显著性模型¶
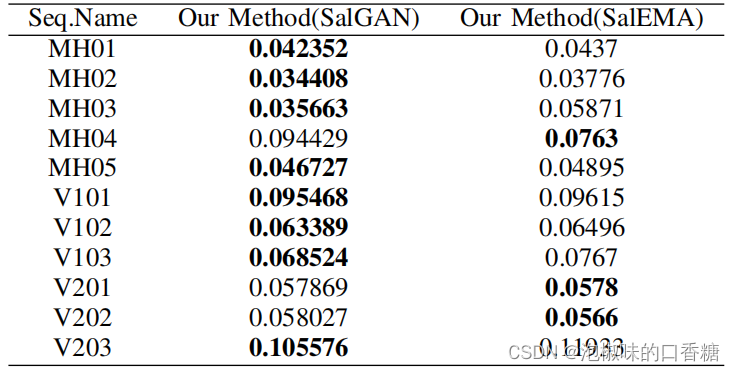
如图5所示是分别使用显著性模型SalGAN和显著性模型SalEMA生成对应于Euroc数据集的显著图结果,SalEMA生成的显著图中的显著区域很小,SalGAN生成的显著图的中心偏差较弱。表1所示是计算的绝对轨迹误差(ate)的均方根(RMSE)。结果显示,SalGAN生成的显著图有助于Attention-SLAM在大多数数据序列中表现更好,即弱中心偏置的显著图使得Attention-SLAM达到更高的精度。

图5 显著图比较:(a)原始图像序列 (b)SalEMA生成的显著图 ©SalGAN生成的显著图
表1 使用不同显著性模型生成的权重,计算ORB-SLAM和Attention-SLAM之间的绝对轨迹误差的RMSE
4.2 视频显著性模型与SalNavNet的比较¶
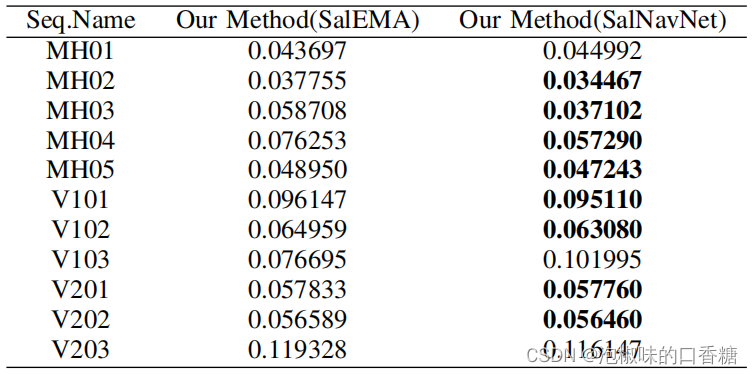
如图6所示是SalEMA与SalNavNet生成的显著图对比。结果显示,SalEMA生成的显著图具有很强的中心偏差。虽然相邻的三幅原始图像变化不大,但是SalEMA生成的显著图发生了显著变化。而SalNavNet生成的显著图减轻了中心偏差。如表2所示,SalNavNet在大多数数据序列中的表现优于SalEMA。这意味着SalNavNet生成的显著图可以帮助Attention-SLAM比SalEMA获得更好的性能。

图6 显著图对比:(a)原始图像序列 (b)SalEMA生成的显著图 ©SalNavNet生成的显著图
表2 使用最先进的显著性模型SalEMA与使用SalNavNet的Attention-slam之间的绝对轨迹误差的RMSE
4.3 显著性Euroc数据集¶
为了验证Attention-SLAM的有效性,作者在EuRoc数据集的基础上建立了一个新的语义SLAM数据集。显著性EuRoc数据集包括原始数据集中cam0的数据、真实值和相应的显著性图。图7展示了显著性Euroc数据集中三个连续的相框及其对应的视觉显著性掩码。可以发现,注意力随着相机运动的变化而变化,但对显著物体的注意是连续的。

图7 显著性EuRoc数据集:(a)原始图像 (b)相应的显著性表示,其中白色部分表示更高的关注度 ©热力图表示
4.4 与其他SLAM方法的比较¶
图8所示是Attention-SLAM在V101数据集上的二维轨迹。结果表明,使用Attention-SLAM估计的轨迹更接近真值。Attention-SLAM更加关注显著的特征点,从而使姿态估计更接近真实值。为了更好地分析姿态估计的准确性,作者分别在图9中绘制了三维姿态的估计值和真实值。并使用一个红色的框架来扩大轨迹的重要部分。两种方法在前40秒内都很好地跟踪了轨迹,但之后基线方法在X轴和Z轴上的大偏移量。在50-60秒时,Attention-SLAM可以更好地跟踪Z轴。
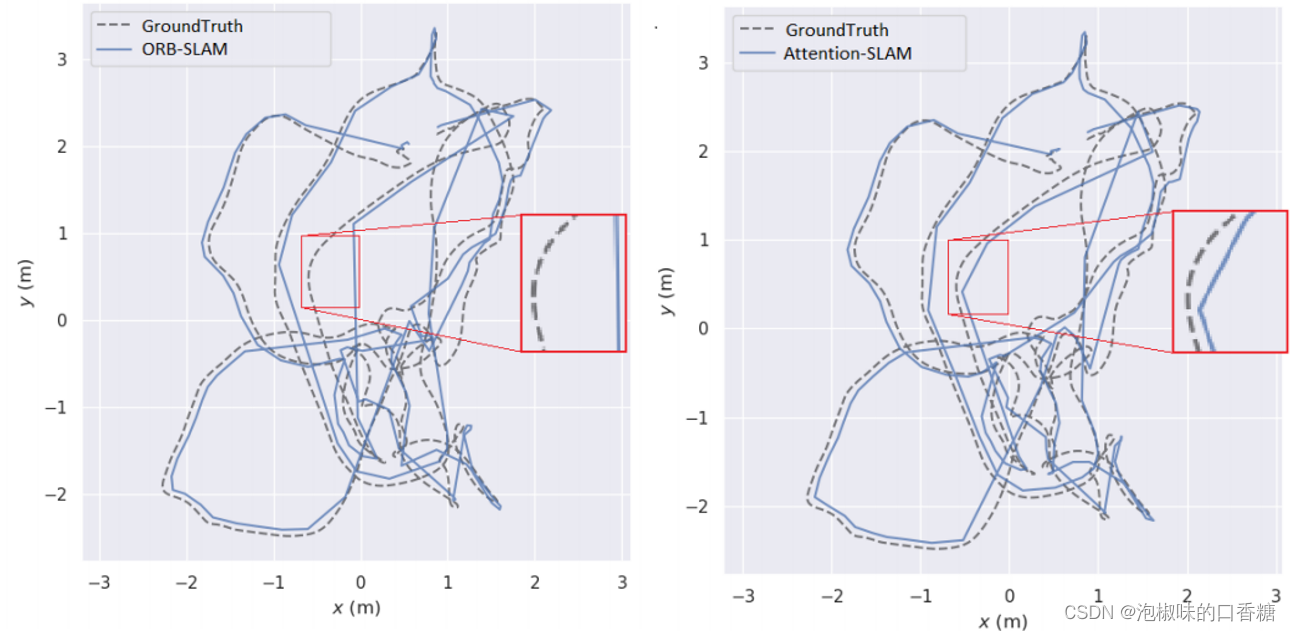
图8 在v101数据集上ORB-SLAM和Attention-SLAM的2D轨迹比较
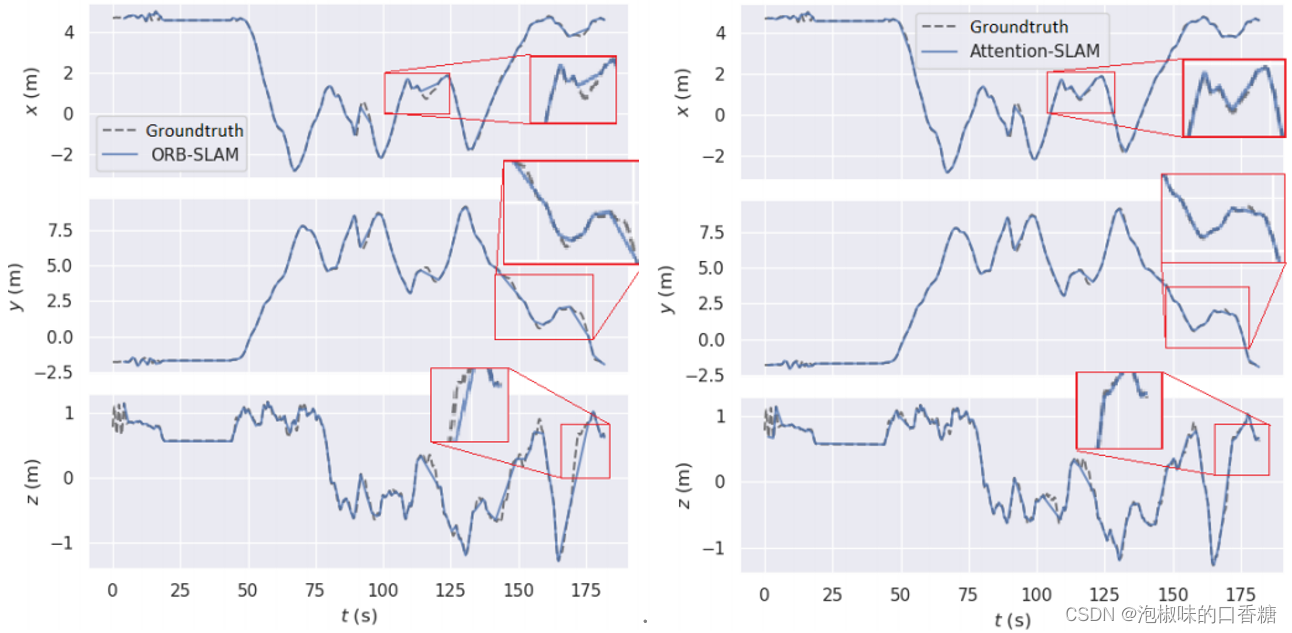
图9 ORB-SLAM和Attention-SLAM的3D轨迹对比
为了进一步评估Attention-SLAM,作者对比了Attention-SLAM和DSO的性能,结果如表3和表4所示。结果显示,Attention-SLAM在大多数场景中获得了较高精度。
表3 相关方法和Attention-SLAM的平均绝对轨迹误差
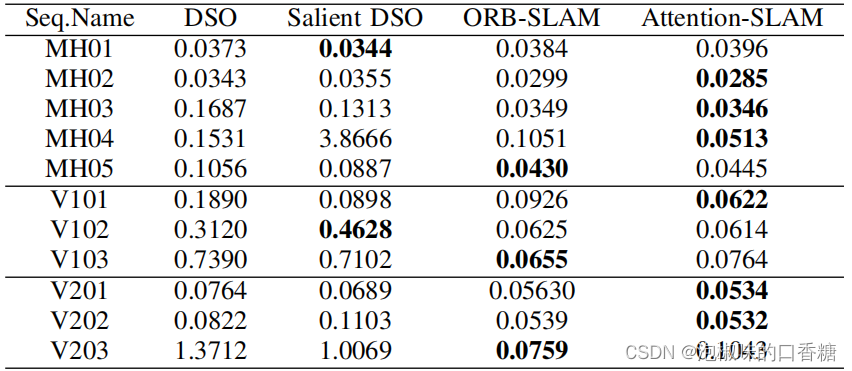
表4 相关方法和Attention-SLAM的RMSE绝对轨迹误差
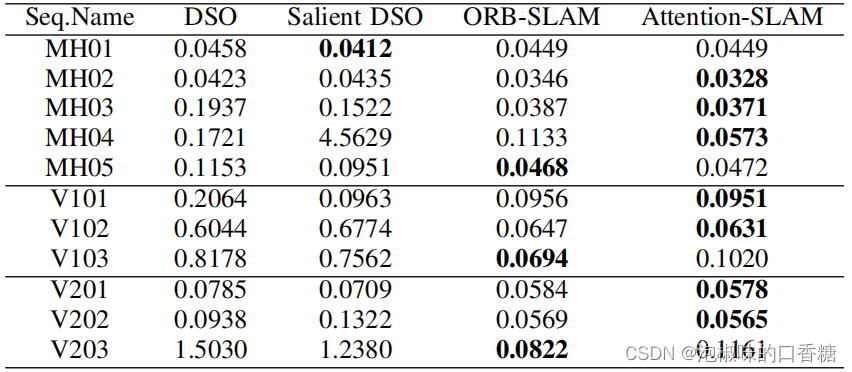
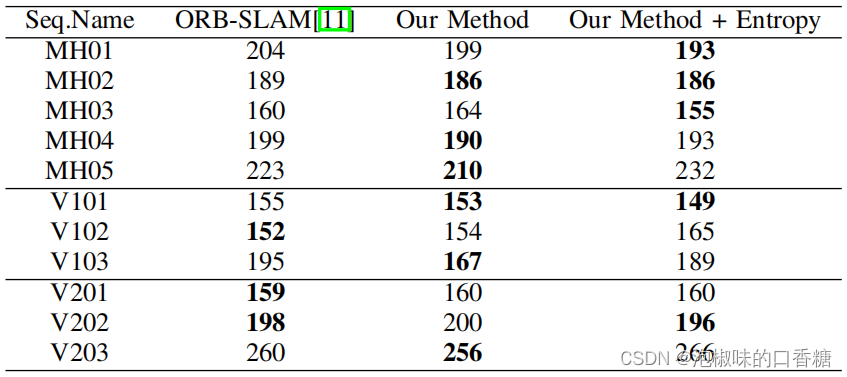
表5所示是ORB-SLAM和Attention-SLAM生成的关键帧对比。结果显示,Attention-slam在最简单和中等难度的数据序列中表现良好,但在困难的序列中表现不佳,例如MH04、MH05、V203、V103。
表5 关键帧数量
但在作者将熵关键帧选择策略添加到Attention-SLAM之后,这个标准使得Attention-SLAM在困难的数据序列中选择更多的关键帧。如表6所示,这一标准使Attention-SLAM在困难的数据序列中表现更好。因此,熵比度量是Attention-SLAM的一个重要策略。当显著性模型向系统添加足够的语义信息时,就会使系统选择更少的关键帧。当显著性模型不能降低运动估计的不确定性时,会使系统选择更多的关键帧以获得更好的性能。
表6 添加熵比选择前后Attention-SLAM的平均ATE性能比较

此外,如表7所示,Attention-SLAM降低了传统方法的不确定性,熵的减少与Attention-SLAM的精度呈正相关。
表7 熵缩减的对比

5. 结论¶
在2020 CVPR论文"Attention-SLAM: A Visual Monocular SLAM Learning from Human Gaze"中,作者提出了一种称为Attention-SLAM的语义SLAM方法。它结合了视觉显著性语义信息和视觉SLAM系统。作者基于EuRoc数据集建立了显著EuRoc,这是一个标注了显著语义信息的SLAM数据集。与目前主流的单目视觉SLAM方法相比,该方法具有更高的效率和准确性,同时可以降低姿态估计的不确定性。
本文总阅读量次