CVPR 2022:利用CLIP高效处理三维点云_Garfield
CVPR 2022: PointCLIP: Point Cloud Understanding by CLIP
1. 论文信息¶
标题:PointCLIP: Point Cloud Understanding by CLIP
作者:Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, Hongsheng Li
原文链接:https://arxiv.org/abs/2112.02413
代码链接:https://github.com/ZrrSkywalker/PointCLIP
2. 介绍¶
众所周知,通过在视觉领域引入自然语言的监督这种概念,CLIP取得了非常让人震撼的成果,在经典的二维image classification领域,它解决目前主流的深度网络存在的几个问题:
-
需要收集和创建大量的训练数据集,带来较高的成本。
-
由于在单一任务上对训练集过拟合,很难在不同任务设定下都发挥作用。
-
在baseline上表现良好的模型,部署到真实场景中,可能遇到泛化能力不足的问题。
CLIP利用从互联网周收集的4亿(image、text)对的数据集,在预训练之后,用自然语言描述所学的视觉概念,从而使模型能够在zero-shot状态下转移到下游任务。而通过对比视觉语言预训练的大模型CLIP在2D视觉识别方面展现的潜力,尤其是其具有非常强的zero-shot和few-shot学习,让我们很自然地思考,它是不是能迁移到其它模态的信息中使用。
而随着3D传感技术的快速发展,对处理3D点云数据的需求不断增长,催生了许多具有更好的深度模型。但与基于网格的二维图像数据不同,三维点云具有空间稀疏性和不规则分布的特点,阻碍了二维深度模型的直接转移。
此外,新捕获的大规模点云数据中包含大量对训练过的分类器来说“unseen”类别的对象。由于前面提到的传统的二维深度模型的缺点在三维模型中依然存在,所以当每次出现“unseen”的对象可能又要进行重新训练,那么这种负担是难以接受的。
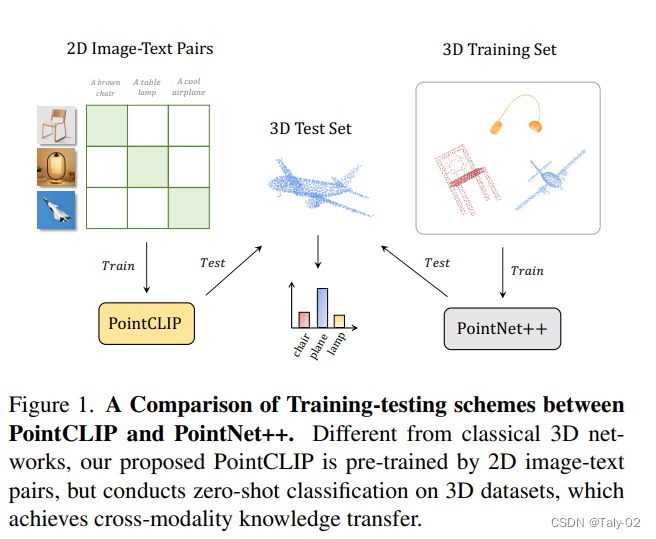
然而,大规模二维图像文本对预先训练的CLIP能否推广到三维识别中,还有待进一步探讨。在本文中,作者通过提出PointCLIP来确定这种设置是可行的,它在clip encoding的点云和3D类别文本之间进行对齐。
具体来说,论文通过将点云投影到多视点深度图而无需渲染来编码点云,并聚合视图上的zero-shot预测,以实现从2D到3D的知识转移。在此基础上,我们设计了一个视图间adapter,以更好地提取global feature,并自适应地将从3D学习到的少量镜头知识融合到预先训练的2D CLIP中。通过在少量镜头设置中微调轻量级适配器,PointCLIP的性能可以得到很大的提高。
此外,论文还观察到PointCLIP与经典3D监督网络之间的互补性。通过简单的集成,PointCLIP提高了baseline的性能,也和最先进的模型。因此,PointCLIP是一种在low-resolution下通过CLIP进行有效三维point clouds understanding的有前景的选择。
概括来讲,本文从方面层面的创新点有:
- 提出了PointCLIP来扩展CLIP来处理3D点云数据,通过将2D预训练的知识转换到3D来实现跨模态零镜头识别。
- 通过多视图之间的特征交互,在PointCLIP上引入了视图间适配器,提高了Few-shot微调的性能。
- PointCLIP可以作为一个多知识集成模块,用于提高现有的经过充分训练的3D网络的性能,从而超越现有的很多方法。
3. 方法¶
3.1 点云特征抽取¶
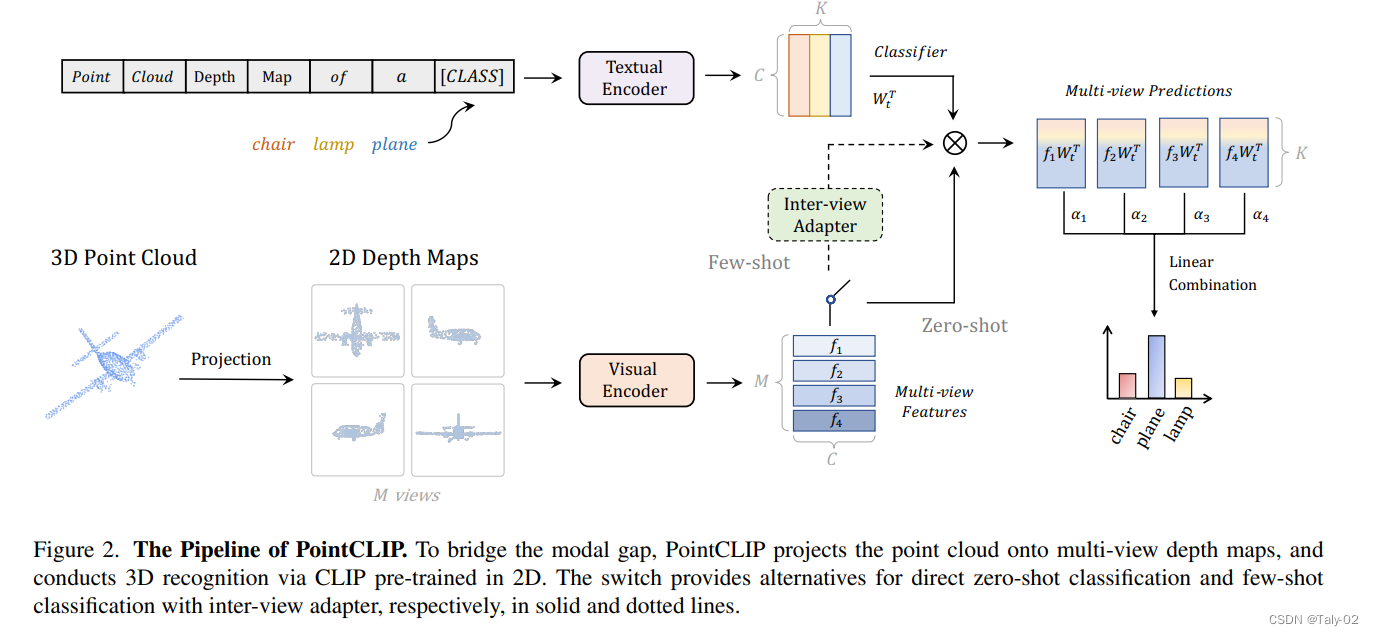
其实完成三维到二维信息的采用了投影的方式,把三维的点,朝各个视图的平面进行投影,变成二维的图像。举个例子,点云的坐标可以表 示为 (x, y, z) ,对 z 方向做perceptive project可以把这个点变换为 \left(\left\lceil\frac{x}{z}\right\rceil,\left\lceil\frac{y}{z}\right\rceil\right), 这种投影的好处 是可以让图片比较接近于自然图像。然后再把投影得到的图像,复制两次,变成三通道图像。这样一来,利用pre-trained的CLIP得到的特征就可以在点云上进行使用了。其实方法相对来说还是比较直接的。
3.2 Zero-shot Classification¶
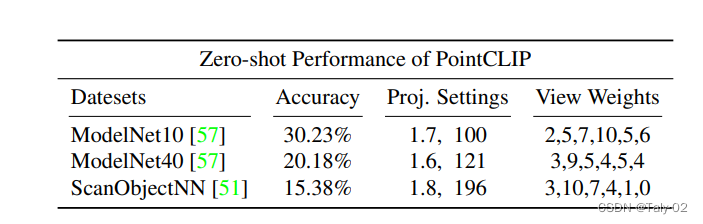
对于zero-shot的样本分类方法,首先对点云对象做 \mathrm{M} 个视角的投影,通过visual encoder抽取特征 f_i ,通过预设的类别和模板 "point cloud depth map of a [CLASS].",抽取文本特征 W_t \in \mathbb{R}^{K * C} 。这样通过对每个view的特征信息分别计算相应的分数,让后加权得到最终的分数。但是这种方式的结果和有监督相差甚远,毕竟点云投影和真实图像之间的domain gap非常大,CLIP是直接在二维的自然图像上训练的,要完成这样的跨模态信息检测显然是比较有挑战的,例如其在ModelNet40数据集上的准确率只有 20.18 \% ,和有监督学习方法之间的gap明显存在。
3.3 训练方法¶
用一个小网络作为Adapter,结构如上图所示,先把多视角的特征concat成一维,通过两个全连接得到全局特征,然后把每个全局特征乘一个矩阵,再和原始的特征用残差连接放到一起,在训练的时候把其余部分固定住,只训练这个adapter,用few shot 进行学习,就得到了最终的adapted feature,然后和textual embeddings比较相似度:
4. 实验¶
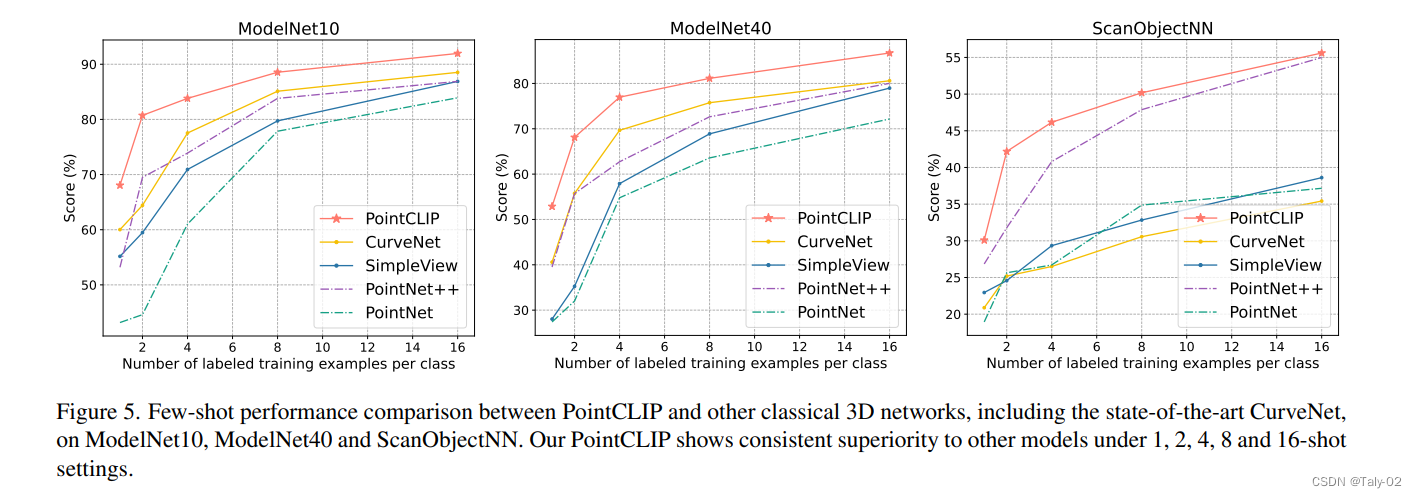
可以发现模型在增加训练样本的情景下,还是具有比较明显的提升的。
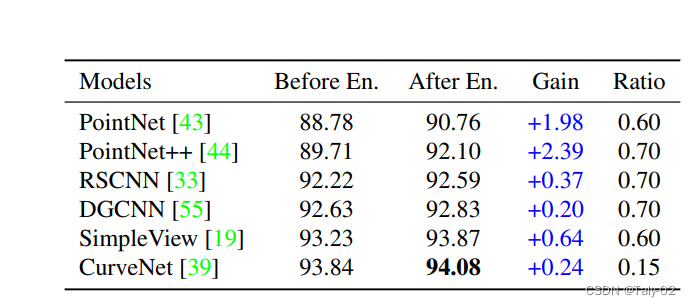
由于few shot的设定采用的训练样本较少,所以可以看到即使使用16个样本,最后的特征还是比pointnet差一点,所以本文还考虑是否可以用模型融合的方式,得到更好的模型。可以发现采用简单的方法也取得了非常不错的效果。
5. 结论¶
论文提出了PointCLIP,它在点云上进行跨模态的zero-shot识别,而不需要任何3D训练。通过多视图投影,PointCLIP有效地将CLIP预先训练的2D知识转移到3D领域。在few-shot的设定下,论文设计了一个轻量级的视图间适配器来聚合多视图表示并生成适应的特征。通过微调这样的适配器和冻结所有其他模块,PointCLIP的性能得到了很大的提高。
本文总阅读量次