DID-M3D:用于单目3D物体检测的解耦实例深度¶
0. 引言¶
单目三维物体检测是自动驾驶和计算机视觉领域的重要课题,该任务中的一个重要挑战在于实例深度估计。因为深度信息在相机投影过程之后容易丢失,因此实例深度估计是提高性能的瓶颈。在2022 ECCV论文"DID-M3D: Decoupling Instance Depth for Monocular 3D Object Detection"中,作者提出了一种解耦实例深度网络DID-M3D,将实例深度重新表述为视觉深度和属性深度的组合,获得最终的实例深度,算法已经开源。
1. 论文信息¶
标题:DID-M3D: Decoupling Instance Depth for Monocular 3D Object Detection
作者:Liang Peng, Xiaopei Wu, Zheng Yang, Haifeng Liu, Deng Cai
来源:2022 European Conference on Computer Vision (ECCV)
原文链接:https://arxiv.org/abs/2207.08531
代码链接:https://github.com/SPengLiang/DID-M3D
2. 摘要¶
单目3D检测由于其低成本和设置简单而引起了社会的广泛关注。它采用RGB图像作为输入,并预测3D空间中的3D框。其中最具挑战性的子任务在于实例深度估计。以前的工作通常使用一种直接估算方法。然而,本文指出RGB图像上的实例深度是非直观的。它由视觉深度线索和实例属性线索耦合而成,难以在网络中直接学习。因此,我们建议将实例深度重新表述为实例视觉表面深度(视觉深度)和实例属性深度(属性深度)的组合。视觉深度与物体的外观和在图像上的位置有关。相比之下,属性深度依赖于对象的固有属性,这些属性对于图像上的对象仿射变换是不变的。相应地,我们将3D位置不确定性解耦为视觉深度不确定性和属性深度不确定性。通过组合不同类型的深度和相关的不确定性,我们可以获得最终的实例深度。此外,单目3D检测中的数据增强通常由于物理性质而受到限制,阻碍了性能的提升。基于实例深度分解策略的提出,可以缓解这一问题。在KITTI上进行评估后,我们的方法获得了最新的结果,并且广泛的消融研究验证了我们方法中每个组成部分的有效性。
3. 算法分析¶
如图1所示是作者提出的DID-M3D网络架构。网络以RGB图像作为输入,经过特征编码后获得深度特征。其次,网络将深度特征输入到三个2D检测头,即2D热图、2D偏移、2D尺寸。然后,利用2D估计,通过RoI对齐从深度特征中得到单个物体特征。最后,将这些目标特征输入三维检测头,生成三维参数。

图1 DID-M3D网络架构总览
在DID-M3D中,作者提出将实例深度解耦为实例视觉表面深度(视觉深度)和实例属性深度(属性深度)。如图2所示,对于物体上的每个点(或小块),视觉深度表示朝向代理(汽车/机器人)相机的绝对深度,属性深度表示从该点(或小块)到物体的3D中心的相对深度偏移。这种分离的方式鼓励网络学习实例深度的不同特征模式。单目图像的视觉深度取决于物体在图像上的外观和位置,这是仿射敏感的。相比之下,属性深度高度依赖于对象的对象固有属性(例如尺寸和方向),它聚焦于RoI内部的特征,这是仿射不变的。因此属性深度独立于视觉深度。

图2 实例深度的耦合性质,
综上所述,作者所做工作的主要贡献如下:
1 作者指出了实例深度的耦合性。由于纠缠的特征,先前直接预测实例深度的方法是次优的。因此,作者建议将实例深度解耦为属性深度和视觉深度,它们是独立预测的。
2 作者提出两种不确定性来表示深度估计的可信度,提出自适应地将不同类型的深度聚合到最终的实例深度中,并相应地获得3D定位置信度。
3 借助于所提出的属性深度和视觉深度,作者克服了在单目三维检测的数据扩充中使用仿射变换的局限性。
4 在KITTI数据集上评估实现了SOTA效果,并通过广泛的消融研究证明了方法中每种成分的有效性。
3.1 视觉深度¶
视觉深度表示小RoI图像网格上物体表面的物理深度。对于每个网格,作者将视觉深度定义为网格内的平均像素深度。如果网格是1×1像素,视觉深度等于逐像素深度。假设像素表示物体的量化表面,那么可以将视觉深度视为像素深度的一般扩展。
单目图像中的视觉深度具有一个重要的性质:对于基于单目的系统,视觉深度高度依赖于物体的2D盒大小(远处的物体在图像上看起来很小,反之亦然)和图像上的位置(图像坐标系下较低的坐标表示较大的深度)。因此,如果对图像执行仿射变换,视觉深度应该被相应地变换,其中深度值应该缩放。作者称这种性质为仿射敏感。
3.2 属性深度¶
属性深度是指从视觉表面到对象的3D中心的深度偏移。作者称之为属性深度,是因为它更可能与对象的固有属性有关。例如,当汽车方向平行于3D空间中的z轴(深度方向)时,汽车尾部的属性深度是汽车的半长。相反,如果方向平行于x轴,属性深度是汽车的半宽。属性深度取决于对象语义及其固有属性。与仿射敏感相反,属性深度对于任何仿射变换都是不变的,因为对象的固有特性不会改变。作者称这种性质为仿射不变量。
因此,作者使用两个独立的头部来分别估计视觉深度和属性深度。实例深度的解耦有几个优点:(1) 对象深度以一种合理而直观的方式被解耦,因此可以更全面和精确地表示对象;(2) 允许网络为不同类型的深度提取不同类型的特征,这有利于学习;(3) 利用解耦深度,DID-M3D可以有效地执行基于仿射变换的数据增强,这在以前的工作中通常是有限的。
3.3 数据扩充¶
在单目三维检测中,许多先前的工作受到数据扩充的限制。它们中的大多数仅使用光度失真和翻转变换。因为变换的实例深度是不可知的,因此直接使用仿射变换的数据扩充很难被采用。
如图3所示,作者在数据扩充中添加了随机裁剪和缩放策略,图像上的3D中心投影点遵循图像的相同仿射变换过程。视觉深度由图像上沿y轴的比例因子缩放,属性深度由于其关联不变的性质而保持不变。物体的其他固有属性如观察角度和尺寸,与原始值相同。消融实现证明数据增强的效果很好。

图3 基于仿射变换的数据扩充
3.4 深度不确定性和聚集¶
由于三维定位困难,二维分类评分不能完全表达单目三维检测的置信度。鉴于作者已经将实例深度解耦为视觉深度和属性深度,可以进一步解耦实例深度的不确定性。只有当一个对象同时具有低视觉不确定性和低属性深度不确定性时,实例深度才能具有较高的置信度。
如图4所示是深度流过程,作者假设每个深度预测都是一个拉普拉斯分布,并使用视觉深度、属性深度和相关的不确定性来获得最终的实例深度。

图4 物体的深度流
3.5 损失函数¶
二维检测部分:如图1所示,对于二维目标检测部分,二维热图H表示图像上粗糙的物体中心,2D偏移O2d表示向粗糙2D中心的残差,2D尺寸S2d表示2D盒的高度和宽度。因此,分别可以得到损失函数LH、LO2d和LS2d。
三维检测部分:首先利用典型的损失函数LS3d。对于方向,该网络预测观测角度,并使用多箱损失LΘ。对于三维中心投影,通过预测到二维中心的三维投影偏移来实现它,损失函数为LO3d。视觉深度损失为LDvis,其中uvis为不确定性。同样,也有属性深度损失LDatt和实例深度损失LDins。在这些损失项中,关于实例深度(LDvis、LDatt和LDins)的损失起着最重要的作用,所有损失项的权重设为1.0,总体损失函数为:
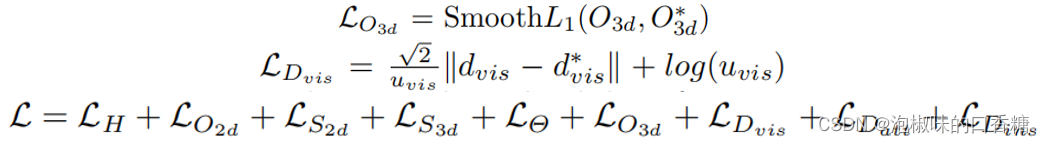
4. 实验¶
4.1 KITTI基准测试¶
作者在RTX 3080 TI GPU上进行实验,并训练200个epoch,数据集采用KITTI 3D。训练方式上采用层次任务学习(HTL)训练策略,Adam优化器的初始学习率为1e−5。采用线性热身策略,学习速率在前5轮增加到1e−3,在第90和120阶段为0.1衰减。此外,作者将激光雷达点云投射到图像帧上,创建稀疏的深度图,然后执行深度补全,在图像中的每个像素处生成深度值。
如表1所示是DID-M3D与KITTI测试集中的其他方法的对比。与GUPNet相比,DID-M3D在中等设置下将性能从21.19/15.02提高到22.26/16.29。对于PCT,DID-M3D在中等设置下超过了3.23/2.92AP。与MonoCon相比,DID-M3D在所有BEV指标和3D指标上表现出更好的性能。此外,DID-M3D的运行速率也可以与其他实时方法相媲美。这些结果验证了该方法的优越性
表1 KITTI测试集的比较

为了证明在其他类别上的普遍性,作者还在自行车和行人类别上进行了实验,结果如表2所示。DID-M3D对基线带来了明显的改进,同时证明了DID-M3D也适用于其他类别。
表2 对KITTI上的行人和骑自行车者类别进行比较结果

此外,图5所示是RGB图像和3D空间的定性结果。可以观察到,对于大多数简单的情况,模型预测相当精确。然而,对于严重遮挡、截断或远处的对象,方向或实例深度不太准确。由于单目图像中的信息有限,这是大多数单目算法的常见困境。
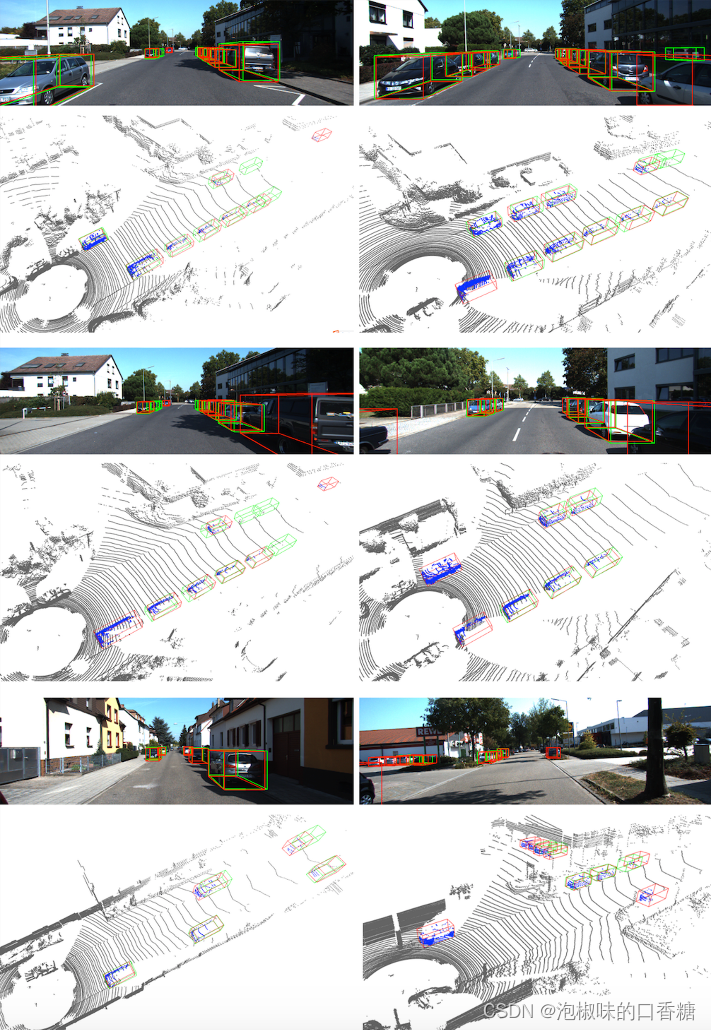
图5 KITTI数据集的定性结果
4.2 消融实验¶
4.2.1 解耦实例深度
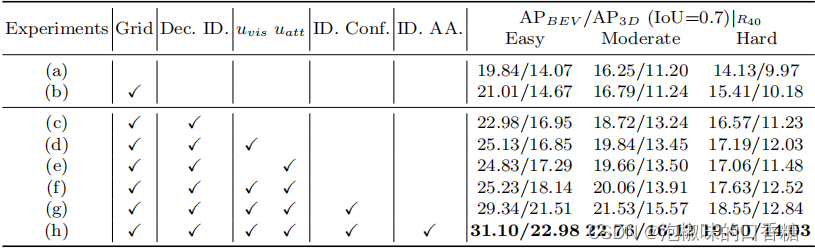
如表3所示是详细的解耦实例深度消融实验结果,实验(a)是使用直接实例深度预测的基线。为了进行公平的比较,对于基线,作者还采用了网格设计(实验(b))。这一结果表明,由于实例深度的耦合性质,网络的表现不佳。从实验©→(d,e)中可以看出,深度的不确定性带来了改善,因为不确定性稳定了深度的训练,有利于网络学习。当同时强制执行这两种类型的不确定性时,性能会进一步提高。请注意,解耦的实例深度是解耦的不确定性的前提条件。由于实现了两种类型的深度不确定性,可以得到最终的实例深度不确定性(实验(f)→(g))。这可以看作是三维位置置信度。将它与原始的二维检测置信度相结合,结果得到了明显的改进。最后,可以利用解耦的深度和相应的不确定性来自适应地获得最终的实例深度(实验(h))。综上所述,通过使用解耦的深度策略,可以提高了从16.79/11.24到22.76/16.12的基线性能(实验(b)→(h))。
表3 解耦实例深度消融实验
"Dec.":解耦; "ID.":实例深度; "uvis":视觉深度不确定性;
"uatt":属性深度不确定性; \" Conf.\":置信; "AA.":自适应聚合
4.2.2 基于仿射变换的数据增强
作者通过实验验证了基于仿射变换的数据增强的效果,比较结果如表4所示。可以看到,DID-M3D明显受益于基于仿射的数据增强。注意,适当的深度转换是非常重要的。当强制执行基于仿射的数据增强时,应该对视觉深度分别进行缩放,而属性深度不应因它们的仿射敏感性和仿射不变性而发生改变
如果在不缩放视觉深度的情况下改变属性深度,检测器甚至比没有基于仿射的数据增强的检测器的性能更差(AP3D从12.76降级到12.65)。这是因为这种方式用不正确的深度目标误导了训练网络。在修正视觉深度之后,网络可以受益于扩充的训练样本,在中等设置下将性能从19.05/12.76提高到21.74/15.48 AP。与不适当的属性深度相比,不适当的视觉深度对最终性能的影响更大,因为视觉深度具有更大的取值范围。当采用适当的视觉深度和属性深度变换策略时,可以获得最佳的性能。
表4 基于仿射变换的数据增强消融实验

4.2.3 视觉深度和属性深度的网格大小
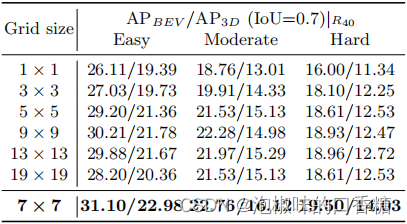
作者研究了网格大小所带来的影响。当增加网格大小m时,视觉深度和属性深度将变得更为精细。这种趋势使视觉深度更加直观,即接近于像素级的深度。然而,细粒度的网格将导致在学习对象属性方面的性能不佳,因为这些属性集中于整体对象。因此,作者对网格大小m进行消融实验,结果如表5所示。当m被设置为7时,获得了最佳的性能。
表5 视觉深度和属性深度上网格大小的消融
5. 结论¶
在2022 ECCV论文"DID-M3D: Decoupling Instance Depth for Monocular 3D Object Detection"中,作者提出了一种用于单目3D物体检测的解耦实例深度,并指出实例深度是由视觉深度和物体固有属性耦合而成的,这种纠缠性质使得用以前的直接方法很难精确估计。因此,作者建议将实例深度解耦为视觉深度和属性深度,这种方式允许网络学习不同类型的特征,通过聚集视觉深度、属性深度和相关的不确定性来获得实例深度。使用解耦的深度,可以有效地对图像执行基于仿射变换的数据增强,这在以前的工作中通常是受限的。
本文总阅读量次