SceneRF:具有辐射场的自监督单目三维场景重建¶
0. 笔者个人体会¶
之前一直都是在基于ColMap、OpenMVG、OpenMVS这些传统多视图几何的方法进行三维重建,但这些框架一方面无法在线端到端得完成重建,另一方面需要很多张高质量的RGB图。深度学习三维重建的方案往往又需要大量的标签来训练,泛化能力也比较弱,自监督3D重建方案一般也是去重建某个目标物体,直接对场景进行重建的工作还比较少。偶然间看到了SceneRF这篇论文,它可以基于单帧图像进行三维重建,感觉很神奇!
SceneRF这项工作是基于NeRF的,其实将NeRF应用到三维重建领域的工作已经有很多了,但应用到单目三维重建上的文章还比较少。因此笔者希望能够带领读者一起阅读一下这篇文章。当然笔者水平有限,若有理解不当的地方,欢迎各位一起探讨,共同学习。
注意,这篇论文也是2022 CVPR论文"MonoScene: Monocular 3D Semantic Scene Completion"同一作者的工作,其实两项工作的思路相同,只不过MonoScene是监督方案,SceneRF是自监督方案。MonoScene和SceneRF这两项工作都开源,读者可以在它们的基础上完成自己的工作。
1. 论文信息¶
标题:SceneRF: Self-Supervised Monocular 3D Scene Reconstruction with Radiance Fields
作者:Anh-Quan Cao, Raoul de Charette
机构:Inria (法国国家信息与自动化研究所)
原文链接:https://arxiv.org/abs/2212.02501v1
代码链接:https://astra-vision.github.io/SceneRF
2. 摘要¶
在文献中,从二维图像进行三维重建已经得到了广泛的研究,但往往仍然需要几何监督。在本文中,我们提出了SceneRF,一种自监督的单目场景重建方法,该方法使用神经辐射场(NeRF)从多个带有姿态的图像序列中学习。为了改进几何预测,我们引入了新的几何约束和一种新的概率采样策略,有效地更新了辐射场。由于后者是基于单帧的,场景重建是通过融合多个合成的新深度视图来实现的。这是由我们的球形解码器实现的,它允许超出输入帧视场的幻觉。深入的实验表明,我们在新的深度视图合成和场景重建的所有指标上都优于所有基线。
3. 算法分析¶
如图1所示是SceneRF的具体效果,也就是输入单帧图像,输出新深度/视点,并进行复杂场景的3D重建。

图1 SceneRF自监督单目场景重建结果
SceneRF首先给定序列的第一个输入帧(I1)并提取特征体积W。然后随机选择一个源帧Ij,从中随机采样像素。给定已知位姿和相机内参,沿着经过这些像素的射线有效地采样N个点。然后将每个采样点投影到一个球面上,这样就可以通过双线性插值检索出对应的输入图像特征向量。再传递给NeRF的MLP层,伴随观察方向和位置编码,就可以预测输入帧坐标中的体素密度和RGB颜色。
SceneRF这篇文章的主要创新点在于,在训练每条射线r时,显式地用重投影损失Lreproj来优化深度D,引入概率射线采样策略(PrSamp)来更有效地采样点,并提出了一个带有球形解码器的U-Net。
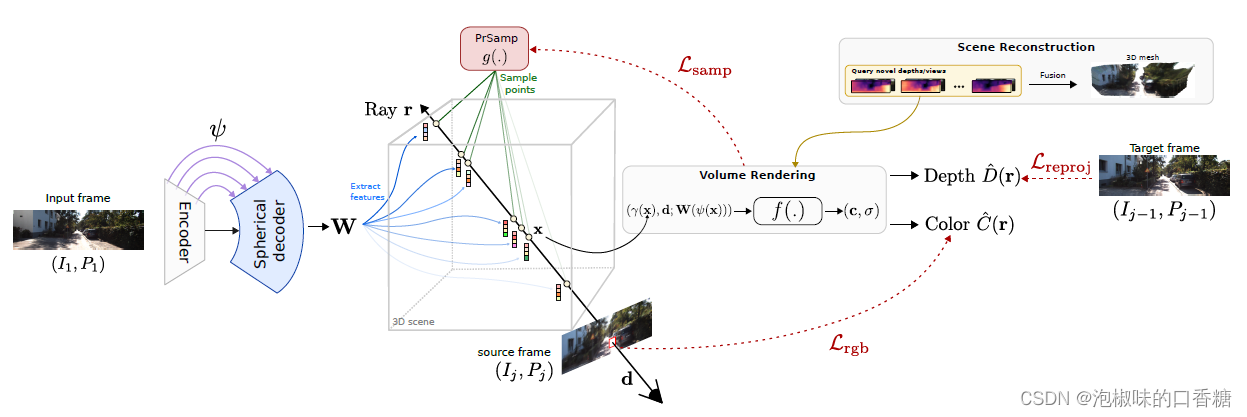
图2 SceneRF框架
综上所述,作者提出了一个完全自监督的3D重建模型,主要贡献如下:
1 在PixelNeRF的基础上明确优化深度,并提出了一个高效的球面U网(SU-Net),使得可以使用NeRF进行场景重建
2 介绍了一种概率射线采样策略(PrSamp)学习用高斯混合表示连续密度体积,提高性能和效率,
3 提出了第一个使用单视图作为输入的自监督大场景重建方法。在具有挑战性的驾驶场景上的结果表明,该方法甚至优于深度监督的基线。
3.1 用于新深度合成的NeRF¶
NeRF主要是优化连续的体积辐射场f,使得对于给定的三维点和方向,可以返回一个体素密度和RGB颜色。在SceneRF中,作者主要是基于PixelNeRF来实现NeRF的,这个过程可以表达为:
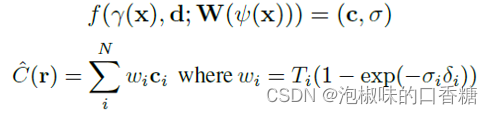
这个公式中规中矩,SceneRF主要创新点之一是在NeRF中引入一种新的深度损失。与大多数NeRF不同,SceneRF寻求从辐射体积中显式地解出深度,因此定义深度估计D为:
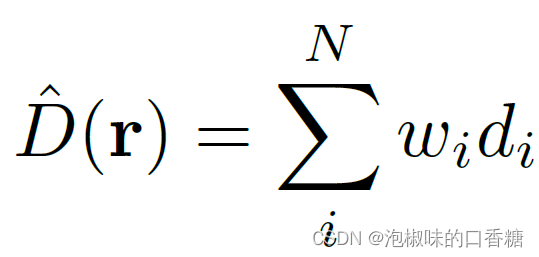
其中di为i点到采样位置的距离。
那么具体是什么深度损失呢?为了实现深度的无监督训练,作者借鉴了MonoDepth的思想。也就是在目标深度估计图像和源图像的变换之间添加了一个光度损失:
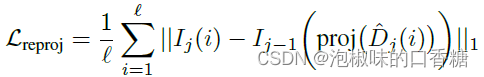
这个损失其实没有多新,大多数单目自监督深度估计网络都会使用这个损失,但是在NeRF中应用这个损失的文章还比较少。
3.2 概率射线采样¶
到这里问题就开始有意思了。
SceneRF是一个无监督3D重建网络,但需要注意的是,在没有真实深度的大型城市场景中,高效采样并不简单。因此,作者用一种概率射线采样策略(PrSamp)来解决这个问题,该策略实质上是将每条射线上的连续密度近似为引导采样点的一维高斯混合。由于混合体中的大值与表面位置相关,这使得每条射线上的点数显著减少,从而获得更好的采样效果。具体来说,作者只用了64个点来优化一条100m长的射线。

图3 概率射线采样步骤
具体的采样步骤是,对于给定的射线r,首先在近、远边界之间均匀采样k个点(蓝色点),然后:
1 将点及其对应的特征作为输入,用专门的MLP预测k个一维高斯混合。
2 在每一个高斯(橙色)上均匀采样m个点,再沿射线均匀采样32个点(绿色三角)。
3 将所有点传递给NeRF表达式,对颜色C和深度D进行预测。
4 渲染过程中推断的密度作为3D表面位置的线索,来获得新的高斯混合。
5 利用概率自组织映射(PrSOM)进行求解,更新高斯。简而言之,PrSOM从前者被后者观测到的可能性中为高斯分配点,同时严格保留了潜在的混合拓扑。
6 根据当前高斯和新高斯之间的KL散度的均值更新高斯预测器g:
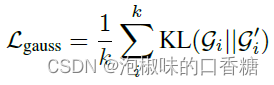
作者还添加了另一个损失,即最小化深度和最近高斯之间的距离,最终损失是两者相加:
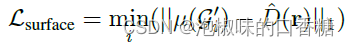
此外,NeRF表达式中的f的有效域被限制在特征体积W内,对于简单的U-Net,特征体积W在图像FOV内,无法在FOV外估计颜色和深度,这不适合场景重建。因此,作者为SU-Net设计了一个在球面域卷积的解码器。由于球面投影比平面投影具有更小的畸变,因此可以将视场(120°)放大,在源图像视场之外实现颜色和深度的幻觉
3.3 场景重建¶
到这一步,SceneRF已经具备了深度合成能力,可以利用这种能力将场景重建框定为多个深度视图的组合。如图4所示,给定一个输入帧,沿着一条假想的直线路径合成新的深度,然后将合成深度转换为TSDF。
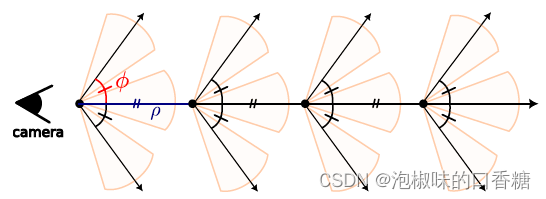
图4 对输入图像的深度合成原理
4. 实验¶
作者评估了SceneRF的两个主要任务:新深度合成和场景重建,以及一个辅助任务:新视点合成。对于主要任务,SceneRF在所有指标上都优于所有基线,而对于新视图合成,取得了和其他单目NeRF相竞争的结果。三个任务都是在SemanticKITTI上进行评估的,使用左目图像并调整分辨率为1220x370。
3D重建的评价指标使用占用体素的IoU、精度和召回率。深度估计使用传统的评价指标AbsRel、SqRel、RMSE、RMSE log、以及三个阈值精度。在视图合成上,使用结构相似性指数SSIM、PSNR和LPIPS感知相似性来评估。
在训练设置上,进行端到端训练,优化器为Adam W,batch size为4,GPU为4个Tesla v100。主要结果训练了50个epoch (5天),消融实验训练20个epoch (2天)。初始学习率设置为1e-5,衰减指数0.95。深度合成的对比基线为PixelNeRF、VisionNeRF和MINE,三维重建的对比基线为MonoScene、LMSCNetrgb、3DSketchrgb和AICNetrgb。
4.1 新深度合成¶
如表1所示,SceneRF在新深度合成上优于所有基线,并与次优方法VisionNeRF有显著差距。在新视点合成上,SceneRF与其他场景大致相当。具体来说,SceneRF在2个指标上优于PixelNeRF,这表明SceneRF的几何目标不会降低视图合成质量。
表1 在SemanticKITTI(val)上的深度/视图结果

在图5中,展示了新深度和不同输入帧、多个位置和角度的新视图。注意,SceneRF的深度边缘更锐利,远处质量更好。
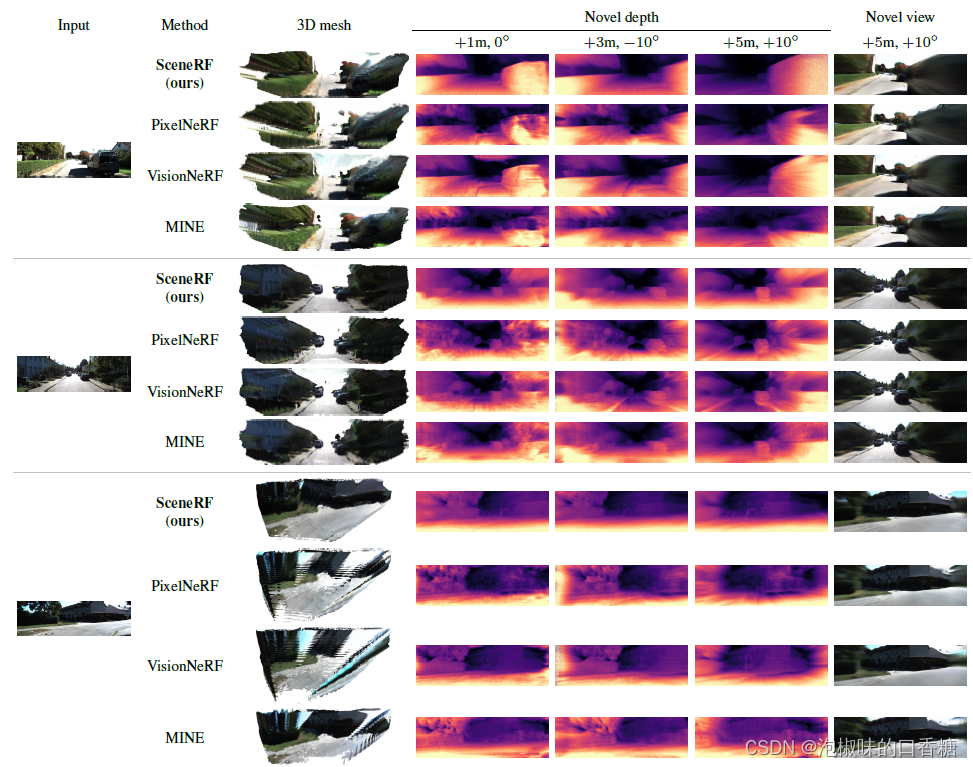
图5 SemanticKITTI (val)的定性结果
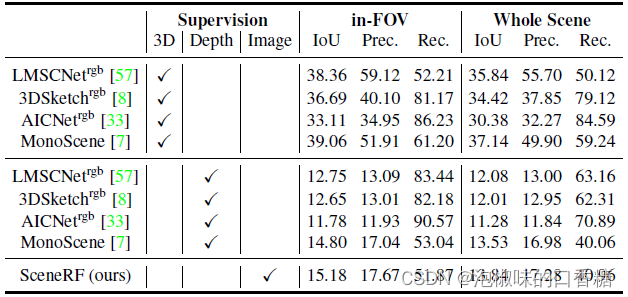
4.2 3D重建结果¶
如表2所示是三维重建的结果对比,其中3D表达的是使用来自激光雷达深度监督,Depth使用来自监督AdaBins方法的深度序列的TSDF融合作为监督。其中,3D这一系列的基线比其他任何基线都要好两倍,这很容易理解,不高才不正常呢。
然而,在比较Image和Depth监督基线时,可以发现SceneRF优于所有基线,这表明SceneRF可以有效地从图像序列中学习几何线索。有趣的是,与\"Depth\"基线相比,SceneRF的\"in-FOV\"和\"Whole Scene\"之间的IoU差距更大。但即便如此,所有方法的数值都很低,这也说明了这些方法还有很大的提升空间。
表2 SemanticKITTI (val)上的场景重建结果
4.3 消融实验¶
表3所示是针对损失、球形U-Net和概率射线采样的消融实现。其中SU-Net的消融实验是将球形解码器替换为标准解码器。结果显示每个模块都对性能提升有所帮助,特别是Lreproj和PrSamp对近距离深度估计有良好的效果。
表3 消融实验结果

5. 结论¶
这两年在各个领域,基本上都多了很多自监督、弱监督、半监督方面的工作,这应该是个研究是大趋势,毕竟数据标注很贵。本文带领读者阅读了文章"SceneRF: Self-Supervised Monocular 3D Scene Reconstruction with Radiance Fields",是一种使用NeRF进行自监督3D重建的工作。如果读者想深入了解的话,建议和2022 CVPR论文"MonoScene: Monocular 3D Semantic Scene Completion"一起学习。
此外,SceneRF的作者也提出他们的工作有两个主要问题,读者可以尝试去解决。首先,由于逐点推理而导致的耗时的深度/视图合成,可以通过射线推理来解决。第二,SceneRF对旋转的抵抗能力很差。
本文总阅读量次