结合代码看深度学习中的Attention机制-Part2¶
【写在前面】¶
近几年,Attention-based方法因其可解释和有效性,受到了学术界和工业界的欢迎。但是,由于论文中提出的网络结构通常被嵌入到分类、检测、分割等代码框架中,导致代码比较冗余,对于像我这样的小白很难找到网络的核心代码,导致在论文和网络思想的理解上会有一定困难。因此,我把最近看的Attention、MLP和Re-parameter论文的核心代码进行了整理和复现,方便各位读者理解。本文主要对该项目的Attention部分做简要介绍。项目会持续更新最新的论文工作,欢迎大家follow和star该工作,若项目在复现和整理过程中有任何问题,欢迎大家在issue中提出,我会及时回复~
项目地址¶
https://github.com/xmu-xiaoma666/External-Attention-pytorch
11. Shuffle Attention¶
11.1. 引用¶
SA-NET: Shuffle Attention For Deep Convolutional Neural Networks[1]
论文地址:https://arxiv.org/pdf/2102.00240.pdf
11.2. 模型结构¶
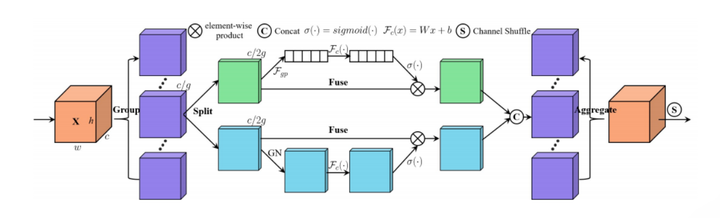
11.3. 简介¶
这是南大在ICASSP 2021发表的一篇论文,这篇文章同样是捕获两个注意力:通道注意力和空间注意力。本文提出的ShuffleAttention主要分为三步:
1.首先将输入的特征分为组,然后每一组的特征进行split,分成两个分支,分别计算 channel attention 和 spatial attention,两种 attention 都使用可训练的参数(当时看结构图的时候,以为是这里是用了FC,但是读了源码之后,才发现是为每一个通道创建了一组可学习的参数) + sigmoid 的方法计算。
2.接着,两个分支的结果concat到一起,然后合并,得到和输入尺寸一致的 feature map。
3.最后,用一个 shuffle 层进行通道Shuffle(类似ShuffleNet[2])。
作者在分类数据集 ImageNet-1K 和目标检测数据集 MS COCO 以及实例分割任务上做了实验,表明 SA 的性能要超过目前 SOTA 的方法,实现了更高的准确率,而且模型复杂度较低。
11.4. 核心代码¶
class ShuffleAttention(nn.Module):
def __init__(self, channel=512,reduction=16,G=8):
super().__init__()
self.G=G
self.channel=channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid=nn.Sigmoid()
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
#group into subfeatures
x=x.view(b*self.G,-1,h,w) #bs*G,c//G,h,w
#channel_split
x_0,x_1=x.chunk(2,dim=1) #bs*G,c//(2*G),h,w
#channel attention
x_channel=self.avg_pool(x_0) #bs*G,c//(2*G),1,1
x_channel=self.cweight*x_channel+self.cweight #bs*G,c//(2*G),1,1
x_channel=x_0*self.sigmoid(x_channel)
#spatial attention
x_spatial=self.gn(x_1) #bs*G,c//(2*G),h,w
x_spatial=self.sweight*x_spatial+self.sbias #bs*G,c//(2*G),h,w
x_spatial=x_1*self.sigmoid(x_spatial) #bs*G,c//(2*G),h,w
# concatenate along channel axis
out=torch.cat([x_channel,x_spatial],dim=1) #bs*G,c//G,h,w
out=out.contiguous().view(b,-1,h,w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out
11.5. 使用方法¶
from attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
12. MUSE Attention¶
12.1. 引用¶
MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning[3]
论文地址:https://arxiv.org/abs/1911.09483
12.2. 模型结构¶
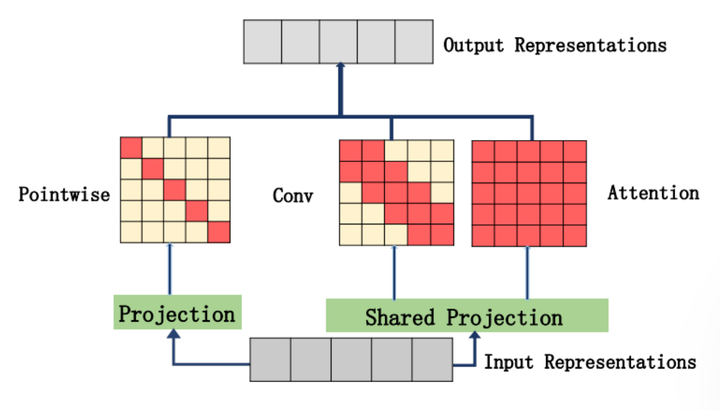
12.3. 简介¶
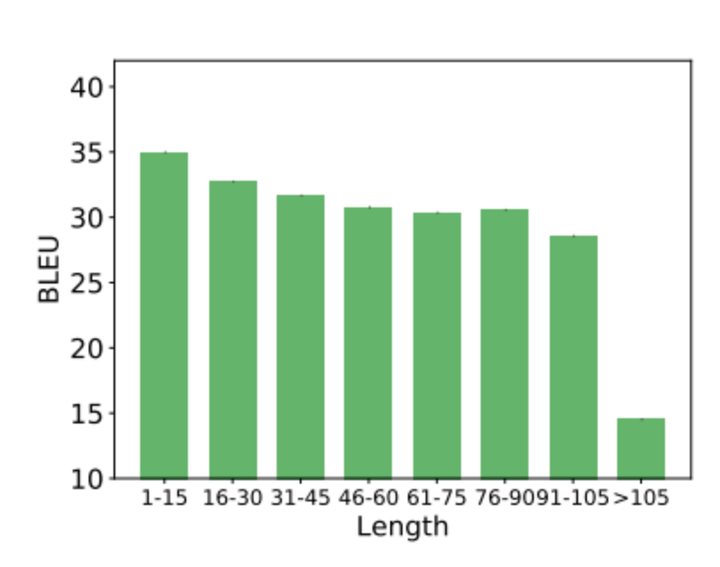
这是北大团队2019年在arXiv上发布的一篇文章,主要解决的是Self-Attention(SA)只有全局捕获能力的缺点。如下图所示,当句子长度变长时,SA的全局捕获能力变弱,导致最终模型性能变差。因此,作者在文中引入了多个不同感受野的一维卷积来捕获多尺度的局部Attention,以此来弥补SA在建模长句子能力的不足。
实现方式如模型结构所示的那样,将SA的结果和多个卷积的结果相加,不仅进行全局感知,还进行局部感知(这一点跟最近的VOLO[4]和CoAtNet[5]的motivation很像)。最终通过引入多尺度的局部感知,使模型在翻译任务上的性能得到了提升。
12.4. 核心代码¶
class Depth_Pointwise_Conv1d(nn.Module):
def __init__(self,in_ch,out_ch,k):
super().__init__()
if(k==1):
self.depth_conv=nn.Identity()
else:
self.depth_conv=nn.Conv1d(
in_channels=in_ch,
out_channels=in_ch,
kernel_size=k,
groups=in_ch,
padding=k//2
)
self.pointwise_conv=nn.Conv1d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
groups=1
)
def forward(self,x):
out=self.pointwise_conv(self.depth_conv(x))
return out
class MUSEAttention(nn.Module):
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
super(MUSEAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.conv1=Depth_Pointwise_Conv1d(h * d_v, d_model,1)
self.conv3=Depth_Pointwise_Conv1d(h * d_v, d_model,3)
self.conv5=Depth_Pointwise_Conv1d(h * d_v, d_model,5)
self.dy_paras=nn.Parameter(torch.ones(3))
self.softmax=nn.Softmax(-1)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
#Self Attention
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
v2=v.permute(0,1,3,2).contiguous().view(b_s,-1,nk) #bs,dim,n
self.dy_paras=nn.Parameter(self.softmax(self.dy_paras))
out2=self.dy_paras[0]*self.conv1(v2)+self.dy_paras[1]*self.conv3(v2)+self.dy_paras[2]*self.conv5(v2)
out2=out2.permute(0,2,1) #bs.n.dim
out=out+out2
return out
12.5. 使用方法¶
from attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
13. SGE Attention¶
13.1. 引用¶
Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks[6]
论文地址:https://arxiv.org/pdf/1905.09646.pdf
13.2. 模型结构¶

13.3. 简介¶
这篇文章是SKNet[7]作者在19年的时候在arXiv上挂出的文章,是一个轻量级Attention的工作,从下面的核心代码中,可以看出,引入的参数真的非常少,self.weight和self.bias都是和groups呈一个数量级的(几乎就是常数级别)。
这篇文章的核心点是用局部信息和全局信息的相似性来指导语义特征的增强,总体的操作可以分为以下几步:
1)将特征分组,每组feature在空间上与其global pooling后的feature做点积(相似性)得到初始的attention mask
2)对该attention mask进行减均值除标准差的normalize,并同时每个group学习两个缩放偏移参数使得normalize操作可被还原
3)最后经过sigmoid得到最终的attention mask并对原始feature group中的每个位置的feature进行scale
实验部分,作者也是在分类任务(ImageNet)和检测任务(COCO)上做了实验,能够在比SK[7]、CBAM[8]、BAM[9]等网络参数和计算量更小的情况下,获得更好的性能,证明了本文方法的高效性。
13.4. 核心代码¶
class SpatialGroupEnhance(nn.Module):
def __init__(self, groups):
super().__init__()
self.groups=groups
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.weight=nn.Parameter(torch.zeros(1,groups,1,1))
self.bias=nn.Parameter(torch.zeros(1,groups,1,1))
self.sig=nn.Sigmoid()
def forward(self, x):
b, c, h,w=x.shape
x=x.view(b*self.groups,-1,h,w) #bs*g,dim//g,h,w
xn=x*self.avg_pool(x) #bs*g,dim//g,h,w
xn=xn.sum(dim=1,keepdim=True) #bs*g,1,h,w
t=xn.view(b*self.groups,-1) #bs*g,h*w
t=t-t.mean(dim=1,keepdim=True) #bs*g,h*w
std=t.std(dim=1,keepdim=True)+1e-5
t=t/std #bs*g,h*w
t=t.view(b,self.groups,h,w) #bs,g,h*w
t=t*self.weight+self.bias #bs,g,h*w
t=t.view(b*self.groups,1,h,w) #bs*g,1,h*w
x=x*self.sig(t)
x=x.view(b,c,h,w)
return x
13.5. 使用方法¶
from attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
14. A2 Attention¶
14.1. 引用¶
A2-Nets: Double Attention Networks[10]
论文地址:https://arxiv.org/pdf/1810.11579.pdf
14.2. 模型结构¶
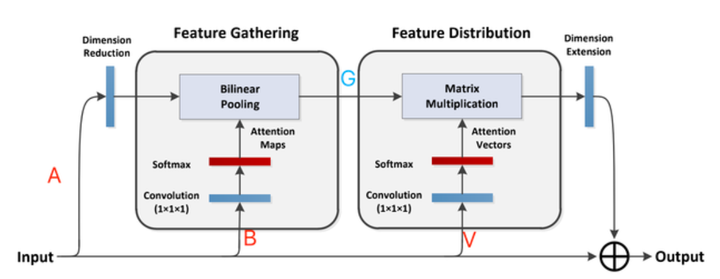
14.3. 简介¶
这是NeurIPS2018上的一篇文章,这篇论文主要是做空间注意力的。并且这篇文章的方法跟做法跟self-attention非常相似,但是包装上就比较“花里胡哨”。
input用1x1的卷积变成A,B,V(类似self-attention的Q,K,V)。本文的方法主要分为两个步骤,第一步,feature gathering,首先用A和B进行点乘,得到一个聚合全局信息的attention,标记为G。然后用G和V进行点乘,得到二阶的attention。(个人觉得这个有点像Attention on Attention(AOA)[11],ICCV2019的那篇文章)。
从实验结果上看,这个结构的效果还是非常不错的,作者在分类(ImageNet)和行为识别(Kinetics , UCF-101)任务上做了实验,都取得非常好的效果,相比于Non-Local[12]、SENet[13]等模型,都有不错的提升。
14.4. 核心代码¶
class DoubleAttention(nn.Module):
def __init__(self, in_channels,c_m,c_n,reconstruct = True):
super().__init__()
self.in_channels=in_channels
self.reconstruct = reconstruct
self.c_m=c_m
self.c_n=c_n
self.convA=nn.Conv2d(in_channels,c_m,1)
self.convB=nn.Conv2d(in_channels,c_n,1)
self.convV=nn.Conv2d(in_channels,c_n,1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)
def forward(self, x):
b, c, h,w=x.shape
assert c==self.in_channels
A=self.convA(x) #b,c_m,h,w
B=self.convB(x) #b,c_n,h,w
V=self.convV(x) #b,c_n,h,w
tmpA=A.view(b,self.c_m,-1)
attention_maps=F.softmax(B.view(b,self.c_n,-1))
attention_vectors=F.softmax(V.view(b,self.c_n,-1))
# step 1: feature gating
global_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*w
tmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,w
if self.reconstruct:
tmpZ=self.conv_reconstruct(tmpZ)
return tmpZ
14.5. 使用方法¶
from attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
15. AFT Attention¶
15.1. 引用¶
An Attention Free Transformer[14]
论文地址:https://arxiv.org/pdf/2105.14103v1.pdf
15.2. 模型结构¶
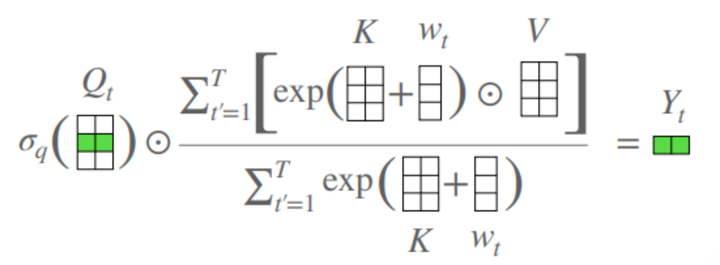
15.3. 简介¶
这是苹果团队2021年6月16日在arXiv上发布的工作,主要工作是简化Self-Attention。
Transformer近几年被用于各种任务中,但是由于Self-Attention的与输入数据大小呈平方关系的时间和空间复杂度,它不能被用于太大的数据中。近几年,基于简化SA的复杂度,很多工作也被提出:稀疏注意力、局部哈希、低质分解...
本文提出了一个Attention Free Transformer(AFT),AFT也是由QKV三部分组成,不同的是QK不是做点积。而是将KV直接融合了,从而来保证对应位置的交互,然后Q与融合后的特征进行了对应位置相乘,来减少计算量。
总体上原理跟Self-Attention相似,不同的是Self-Attention用的是点积,而这里用的是对应位置相乘,所以大大减少了计算量。
15.4. 核心代码¶
class AFT_FULL(nn.Module):
def __init__(self, d_model,n=49,simple=False):
super(AFT_FULL, self).__init__()
self.fc_q = nn.Linear(d_model, d_model)
self.fc_k = nn.Linear(d_model, d_model)
self.fc_v = nn.Linear(d_model,d_model)
if(simple):
self.position_biases=torch.zeros((n,n))
else:
self.position_biases=nn.Parameter(torch.ones((n,n)))
self.d_model = d_model
self.n=n
self.sigmoid=nn.Sigmoid()
def forward(self, input):
bs, n,dim = input.shape
q = self.fc_q(input) #bs,n,dim
k = self.fc_k(input).view(1,bs,n,dim) #1,bs,n,dim
v = self.fc_v(input).view(1,bs,n,dim) #1,bs,n,dim
numerator=torch.sum(torch.exp(k+self.position_biases.view(n,1,-1,1))*v,dim=2) #n,bs,dim
denominator=torch.sum(torch.exp(k+self.position_biases.view(n,1,-1,1)),dim=2) #n,bs,dim
out=(numerator/denominator) #n,bs,dim
out=self.sigmoid(q)*(out.permute(1,0,2)) #bs,n,dim
return out
15.5. 使用方法¶
from attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
【写在最后】¶
目前该项目整理的Attention的工作确实还不够全面,后面随着阅读量的提高,会不断对本项目进行完善,欢迎大家star支持。若在文章中有表述不恰、代码实现有误的地方,欢迎大家指出~
【参考文献】¶
[1]. Zhang, Qing-Long, and Yu-Bin Yang. "Sa-net: Shuffle attention for deep convolutional neural networks." ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2021.
[2]. Zhang, Xiangyu, et al. "Shufflenet: An extremely efficient convolutional neural network for mobile devices." Proceedings of the IEEE conference on computer vision and pattern recognition . 2018.
[3]. Zhao, Guangxiang, et al. "Muse: Parallel multi-scale attention for sequence to sequence learning." arXiv preprint arXiv:1911.09483 (2019).
[4]. Yuan, Li, et al. "VOLO: Vision Outlooker for Visual Recognition." arXiv preprint arXiv:2106.13112 (2021).
[5]. Dai, Zihang, et al. "CoAtNet: Marrying Convolution and Attention for All Data Sizes." arXiv preprint arXiv:2106.04803 (2021).
[6]. Li, Xiang, Xiaolin Hu, and Jian Yang. "Spatial group-wise enhance: Improving semantic feature learning in convolutional networks." arXiv preprint arXiv:1905.09646 (2019).
[7]. Wu, Weikun, et al. "SK-Net: Deep learning on point cloud via end-to-end discovery of spatial keypoints." Proceedings of the AAAI Conference on Artificial Intelligence . Vol. 34. No. 04. 2020.
[8]. Woo, Sanghyun, et al. "Cbam: Convolutional block attention module." Proceedings of the European conference on computer vision (ECCV). 2018.
[9]. Park, Jongchan, et al. "Bam: Bottleneck attention module." arXiv preprint arXiv:1807.06514 (2018).
[10]. Chen, Yunpeng, et al. "$ A^ 2$-Nets: Double Attention Networks." arXiv preprint arXiv:1810.11579 (2018).
[11]. Huang, Lun, et al. "Attention on attention for image captioning." Proceedings of the IEEE/CVF International Conference on Computer Vision . 2019.
[12]. Wang, Xiaolong, et al. "Non-local neural networks." Proceedings of the IEEE conference on computer vision and pattern recognition . 2018.
[13]. Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition . 2018.1
[14]. Zhai, Shuangfei, et al. "An Attention Free Transformer." arXiv preprint arXiv:2105.14103 (2021).
关于文章有任何问题,欢迎在评论区留言或者添加作者微信: xmu_xiaoma

本文总阅读量次