论文链接:Context Reasoning Attention Network for Image Super-Resolution
Abstract¶
如图1中SAN[9]和RFANet[38]所示,由于CNN中的基本卷积层大多用于提取局部特征,从而缺乏对全局上下文建模的能力,因此导致恢复出来的纹理细节都不正确。然而,利用全局上下文信息的CSNLN[41]方法都是通过将全局上下文合并到局部特征表示中进行全局特征交互而忽略了挖掘上下文信息之间的关系。
有神经科学表明神经元是根据上下文动态调节的,这一理论被大多数基于CNN的SR方法所忽略。作者基于这些观察和分析,提出了上下文推理注意网络(CRAN)来根据全局上下文自适应调整卷积核。具体来说,作者是提取了全局上下文描述符,并通过语义推理进一步增强了这些描述符。然后引入通道和空间交互来生成上下文推理注意掩码,并应用上下文推理注意掩码自适应地修改卷积核。
在这项工作中,作者的主要贡献有:
- 作者提出了一种用于精确图像SR的上下文推理注意网络。我们的CRAN可以根据语义推理增强的全局上下文自适应地调整卷积核。
- 作者提出将上下文信息提取到潜在表示中,从而生成包含全局上下文描述符。作者进一步通过使用描述符与语义推理的关系来增强了描述符。
- 作者引入通道和空间交互来生成用于修改卷积核的上下文推理注意掩码。最后,我们得到了上下文推理注意卷积,这进一步作为构建图像SR块和网络的基础。
Method¶
上下文推理注意力卷积¶
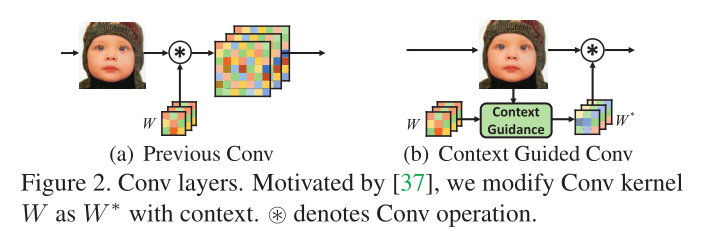
作者在设计自适应修改滤波器的卷积借鉴了Context Guided Conv[37],在中间添加了对应上下文的注意力关系以及对应的通道交互和空间交互操作,具体如下图: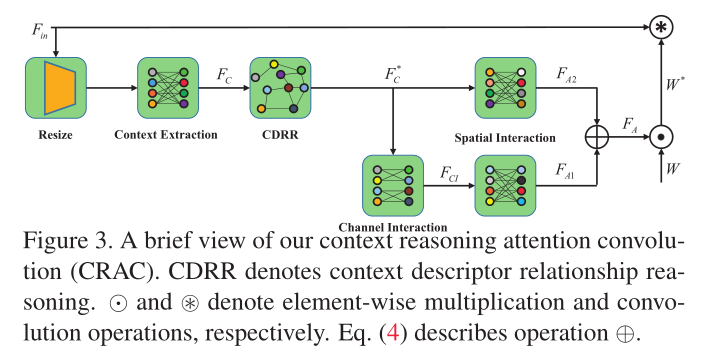
上下文信息提取¶
为了提取上下文信息,作者首先通过使用池层将输入特征F_{in}的空间c_{in}\times h \times w大小减小到c_{in}\times h' \times w',然后通过一个共享的线性层,其权重为W_E \in \mathbb{R}^{h'\times w' \times e}将每个通道投影到大小为e的潜在向量。按照之前Context Guided Conv的设计,我们将向量大小 e 设为\frac{k_1\times k_2}{2},从而获得具有上下文信息的新特征,表示为F_C\in \mathbb{R}^{c_{in}\times e}。然后作者又将全局上下文信息写成一组向量F_C=[\textbf{f}_1,\cdots, \textbf{f}_e] \in \mathbb{R}^{c_{in}\times e}。
上下文关系推理描述符¶
基于之前的卷积推理工作,作者构建了上下文描述符之间的关系推理模型。具体地说,通过权重参数W_{\varphi}, W_{\phi}将上下文描述符嵌入到两个嵌入空间中。然后,正对的关系函数可以表达为
R(\textbf{f}_i, \textbf{f}_j)=(W_{\varphi}\textbf{f}_i)^T(W_{\phi}\textbf{f}_j)
它获取每两个学习的上下文描述符\textbf{f}_i 和$ \textbf{f}_j之间的关系,从而生成一个图。然后通过一个残差学习将F_C$和原始输入桥接得到最终的全局上下文关系:
F_C^* = \sigma([(R{F_C}^TW_g)W_r]^T)\odot F_C + F_C
上下文推理注意卷积¶
作者采用增强的全局上下文信息F_C^*来更新卷积核,从而得到最终的注意力遮罩F_A \in \mathbb{R}^{c_{out}\times c_{in} \times k_1 \times k_2}。为了尽可能减少空间复杂度,作者将这个卷积遮罩分解成F_{A1}\in \mathbb{R}^{c_{out}\times k_1 \times k_2}和F_{A2}\in \mathbb{R}^{c_{in}\times k_1 \times k_2}。
然后分别利用空间交互和通道交互来得到F_{A1} 和F_{A2} 。
通道相互作用:其中通道相互作用采用了深度可分离卷积来减少计算量,通过一个权重为W_{ci}\in \mathbb{R}^{\frac{c_{in}}{g}\times \frac{c_{out}}{g}} 分组线性层进行投影。最后得到通道交互特征F_{CI}\in \mathbb{R}^{c_{out}\times e} 。
空间相互作用:然后,我们分别对F_C^* 和$ F_{CI}$ 分别进行空间相互作用,得到相应的张量F_{A1} 和$ F_{A2}。具体来说就是利用两个权重共享的线性层将这两个特征F_C^和F_{CI}$ 映射为$ F_{A1}$ 和F_{A2},记作F_{A1} = F_{CI}W_{A1} 和$ F_{A2} = F^{C}W{A2}$。
上下文推理注意力卷积:在进行通道和空间交互之后, 作者直接利用$ F_{A1}$ 和$ F_{A2}$ 通过扩张通道数为c_{out}\times c_{in} \times k_1 \times k_2,然后再进行逐元素相加得到F_A。
F_A = F_{A1} \oplus F_{A2}
(F_A)_{h,i,j,k} = \sigma((F_{A1})_{h,j,k}+(F_{A2})_{i,j,k})
最后,我们可以应用注意掩码$ F_A$ 来调制卷积核权重$ W$ ,如下所示:
W^* = W \odot F_A
上下文推理注意力图像超分辨率网络¶
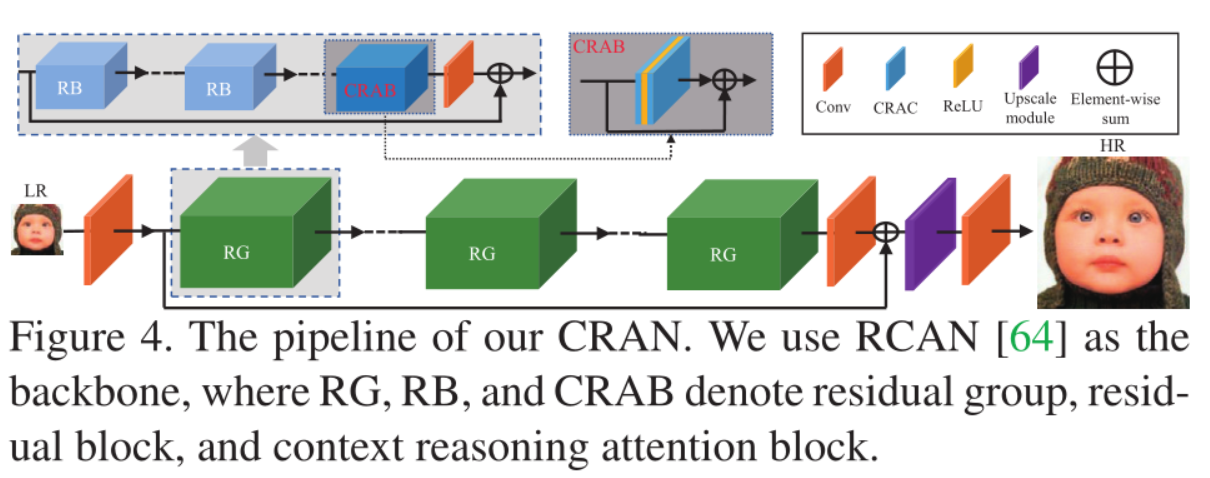
作者采用了RCAN的网络结构,将原有的RCAN中的RCAB模块替换成了CRAB模块,其中CRAB就是利用了作者提出的上下文推理注意力卷积来进行构建的。采用了和RCAN中的参数设置,并且进行了一系列的消融实验证明作者提出的模块的有效性。
Experiments¶
训练选用了DIV2K和Flickr2K作为训练数据,
消融实验¶

可以从表1中可以看出,包含注意力的模块可以获得比普通残差快更高的性能。作者提出的CRAB可以有效的考虑全局上下文的关系,从而获得好的性能,然后作者的模块通过CDRR,实现了进一步的性能提升,这证明了CDRR的有效性。
如表2所示,作者提供了空间交互和通道交互组件的几种组合,可以发现每个组件都有助于提高性能。这证明了空间交互和通道交互操作的有效性。
主要结果¶
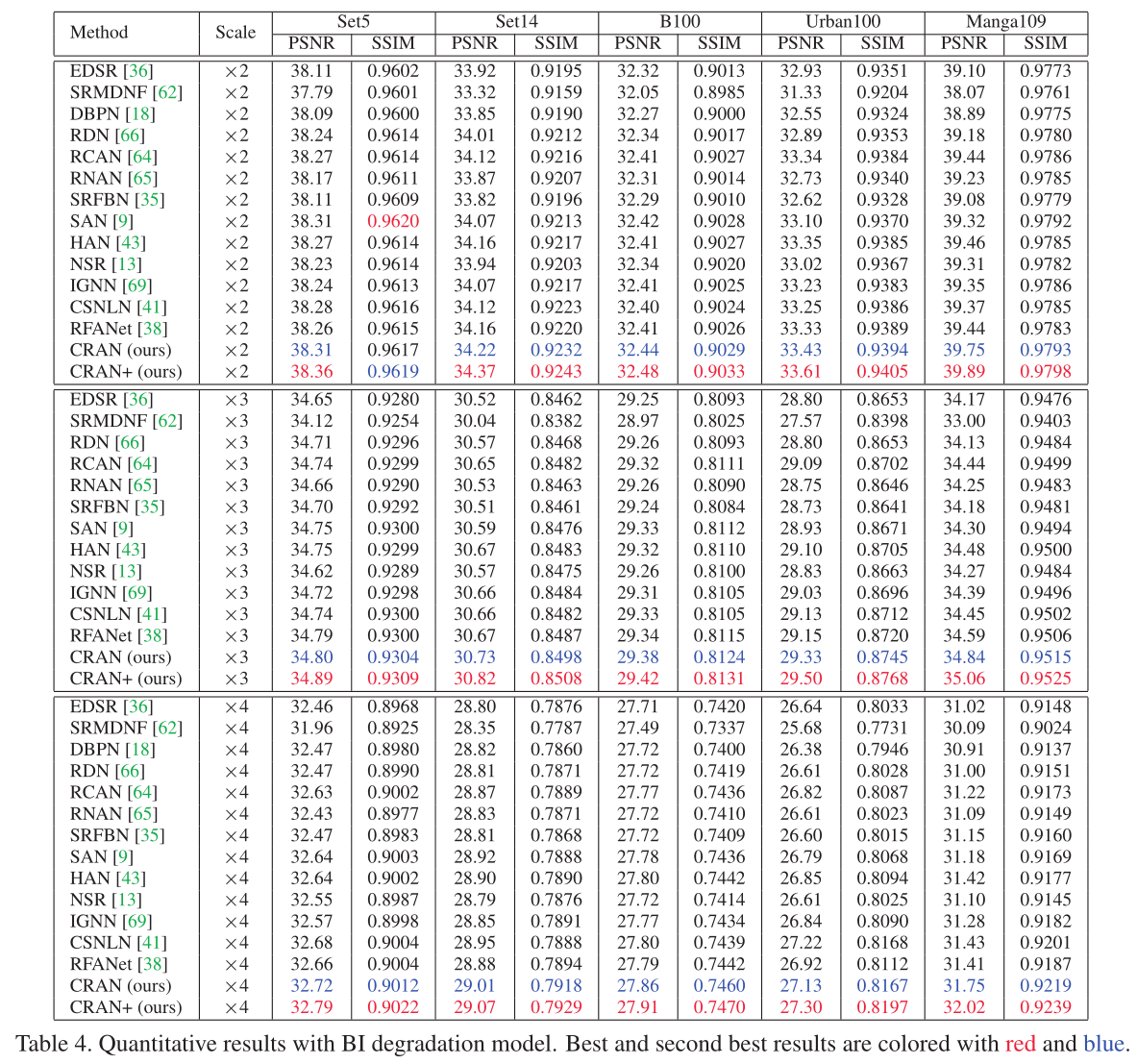
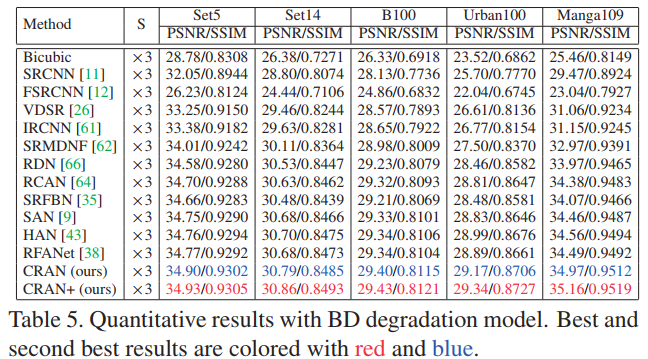
上表对比了不同注意力超分方案的性能,从中可以看到:
- 作者提出的方法在所有的数据集上可以获得最佳的PSNR和SSIM。、
- 与RCAN相比,作者的方法通过修改其中的注意力模块从而得到了卓越的性能,这进一步证明了作者提出的CRAN可以通过调整Conv层内核和全局上下文推理注意来进一步提高性能。
- 作者提出的方法不仅在BI的降质过程上取得好的效果,在BD的降质表现上也取得了优异的性能。

上图对比了不同方法在纹理细节恢复上的效果对比,可以看到:通过作者提出的全局上下文推理注意力卷积可以有效的恢复出正确的纹理细节。
卷积核的多样性¶
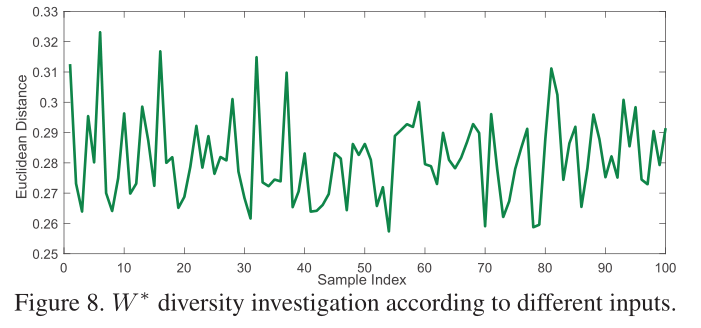
作者为了调查卷积核的多样性,作者考虑计算$ F_A$ 和全为1的矩阵$ I
$ 的欧氏距离,作者将100张图像随机转发到网络中,并计算每个样本的距离。如上图所示,可以看出:作者提出的卷积是根据图像进行自适应调整的,因此整个图像是波动的。
Conclusion¶
- 作者借鉴了Context Guided Conv方法提出了一种全局上下文推理注意力卷积CRAC。
- 作者借鉴了其他推理网络从而提出了上下文关系推理描述符(CDRR),从而进一步增强描述符的上下文关系。
- 将提出来的CRAC应用到RCAN中获得了卓越的超分辨率性能。
Reference¶
[9] Tao Dai, Jianrui Cai, Y ongbing Zhang, Shu-Tao Xia, and Lei Zhang. Second-order attention network for single image super-resolution. In CVPR, 2019.
[37] Xudong Lin, Lin Ma, Wei Liu, and Shih-Fu Chang. Context-gated convolution. In ECCV, 2020.
[38] Jie Liu, Wenjie Zhang, Y uting Tang, Jie Tang, and Gangshan Wu. Residual feature aggregation network for image super-resolution. In CVPR, 2020.
[41] Yiqun Mei, Y uchen Fan, Y uqian Zhou, Lichao Huang, Thomas S Huang, and Humphrey Shi. Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining. In CVPR, 2020.
本文总阅读量次