OutLook Attention:具有局部信息感知能力的ViT¶
【写在前面】¶
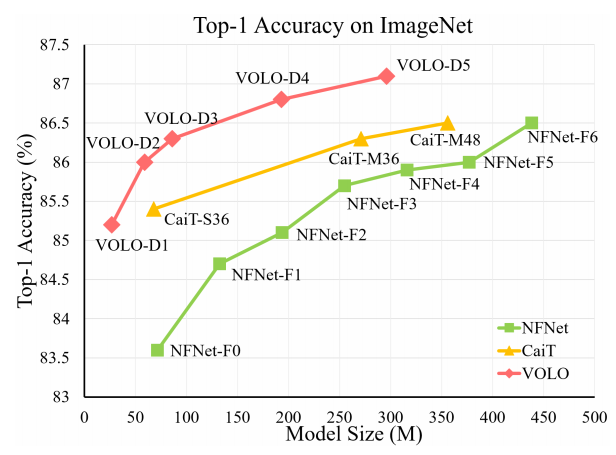
近段时间,Transformer-based模型在Visual Recognition领域取得了非常大的进展。但是如果不借助额外的训练数据,Transformer-based模型离CNN-based模型还是具有一定的差距(NFNet-F5(CNN-based):86.8%,CaiT(Transformer-based):86.5%)。作者认为,这是因为token embedding并没有进行细粒度特征表示,因此本文提出了一种新的Attention方式,通过局部信息的感知,能够获得更加细粒度的特征表示。
1. 论文和代码地址¶
VOLO: Vision Outlooker for Visual Recognition
论文地址:https://arxiv.org/abs/2106.13112
官方代码:https://github.com/sail-sg/volo
2. Motivation¶
前面说到了,token embedding进行特征表示是粗粒度的。为什么是token embedding就是粗粒度的呢?因为一张图片的size往往是比较大的(e.g., 224x224),CNN因为只对局部的信息进行感知(在正常图片上进行滑动窗口操作),所以计算复杂度和图片大小呈线性关系。如果将图片进行token embedding,直接进行Transformer的操作,那就会导致计算复杂度“爆炸”,因为Transformer中的Self-Attention(SA)的复杂度与输入特征的大小是呈平方关系的。
所以Vision Transformer需要将图片先进行token embedding到比较小的size(e.g., 14x14),才能保证计算量在一个合理的范围内。但这就导致了一个信息损失的问题,因为token embedding到较小的size会丢失一些细粒度的信息。
“Embedding的图片太大,会导致计算量过大;embedding的图片过小,会导致信息损失太大”,如何在保证合理计算量的情况下,获得更加细粒度的特征表示,这就是本文要解决的问题。
3. 方法¶
本文的模型可以分为两步:
第一步,通过一系列Outlooker获得更加细粒度的特征表示。
第二步,通过一系列的Transformer结构聚合global的信息
3.1. Outlooker¶
本文提出的Outlooker其实和Transformer的Multi-head Attention非常相似。不同之处在将Multi-head Attention中的Self-Attention换成了OutlookAttention,从而能够获取更加细粒度的特征表示。
Outlooker的计算步骤如下:
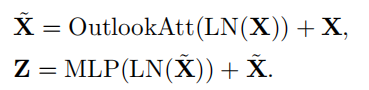
3.2. Outlook Attention¶
Outlook Attention的核心思想如下:
1)每个空间位置的特征足够丰富,用于产生局部聚合其相邻特征的注意力权重;
2)深层的和局部的空间聚合可以有效地编码细粒度的信息。
下面来看Outlook Attention的框架图:
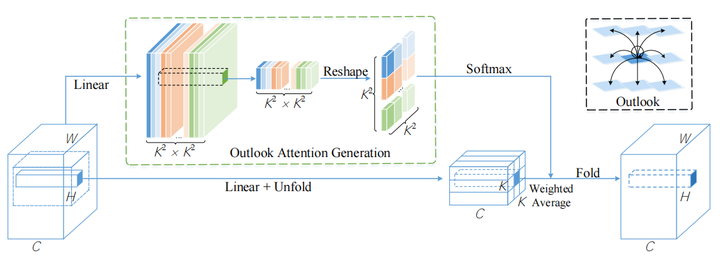
整个框架分为两个分支,上面的分支用于生成attention map,下面的分支用于生成投影后的value。
3.2.1. 生成Attention Map¶
首先看上面的分支,特征x首先被embedding到了K^2*K^2,其中K是局部感知的大小
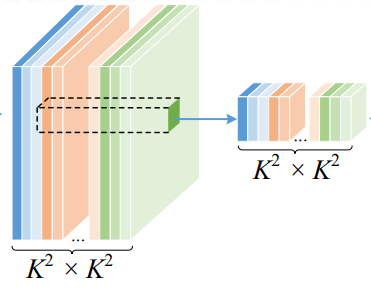
然后,我们将K^2*K^2的特征reshape成(K^2,K^2) 。
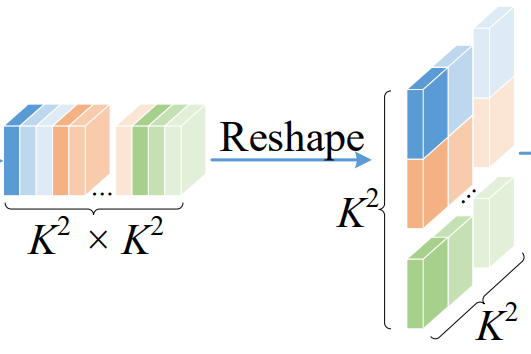
紧接着,我们将最后一个维度进行softmax,我们就能到了每个位置和周围K^2个位置的注意力权重。因此,我只需要将这个attention map和embedding后的value相乘就得到了新的feature。
3.2.2. 映射到新的特征v¶
下面我们来看下面的分支,由两部分组成。

第一部分是Linear,这个操作是为了将输入的特征x进行一个embedding,映射到一个新的特征V。
然后就是就是unfold操作,unfold操作就是卷积中的滑动窗口操作。不同的是这里只有“卷”,没有“积”。就是将特征中的KxK的区域给取出来。
3.2.3. 获取weighted特征¶
前面在3.2.2中,我们已经获得了每个位置的attention map,因此,我们在这一步中只需要做矩阵相乘,就可以得到Outlook Attention之后的结果。最后我们通过Fold函数,就能将feature map还原到输入的大小。
从下面这张图可以看出,在Outlook Attention中,每一个中心点的位置都要周围kxk个位置进行attention操作,这个步骤就有点类似卷积。
Outlook Attention的伪代码如下:

pytorch可执行的代码:
class OutlookAttention(nn.Module):
def __init__(self,dim,num_heads=1,kernel_size=3,padding=1,stride=1,qkv_bias=False,
attn_drop=0.1):
super().__init__()
self.dim=dim
self.num_heads=num_heads
self.head_dim=dim//num_heads
self.kernel_size=kernel_size
self.padding=padding
self.stride=stride
self.scale=self.head_dim**(-0.5)
self.v_pj=nn.Linear(dim,dim,bias=qkv_bias)
self.attn=nn.Linear(dim,kernel_size**4*num_heads)
self.attn_drop=nn.Dropout(attn_drop)
self.proj=nn.Linear(dim,dim)
self.proj_drop=nn.Dropout(attn_drop)
self.unflod=nn.Unfold(kernel_size,padding,stride) #手动卷积
self.pool=nn.AvgPool2d(kernel_size=stride,stride=stride,ceil_mode=True)
def forward(self, x) :
B,H,W,C=x.shape
#映射到新的特征v
v=self.v_pj(x).permute(0,3,1,2) #B,C,H,W
h,w=math.ceil(H/self.stride),math.ceil(W/self.stride)
v=self.unflod(v).reshape(B,self.num_heads,self.head_dim,self.kernel_size*self.kernel_size,h*w).permute(0,1,4,3,2) #B,num_head,H*W,kxk,head_dim
#生成Attention Map
attn=self.pool(x.permute(0,3,1,2)).permute(0,2,3,1) #B,H,W,C
attn=self.attn(attn).reshape(B,h*w,self.num_heads,self.kernel_size*self.kernel_size \
,self.kernel_size*self.kernel_size).permute(0,2,1,3,4) #B,num_head,H*W,kxk,kxk
attn=self.scale*attn
attn=attn.softmax(-1)
attn=self.attn_drop(attn)
#获取weighted特征
out=(attn @ v).permute(0,1,4,3,2).reshape(B,C*self.kernel_size*self.kernel_size,h*w) #B,dimxkxk,H*W
out=F.fold(out,output_size=(H,W),kernel_size=self.kernel_size,
padding=self.padding,stride=self.stride) #B,C,H,W
out=self.proj(out.permute(0,2,3,1)) #B,H,W,C
out=self.proj_drop(out)
return out
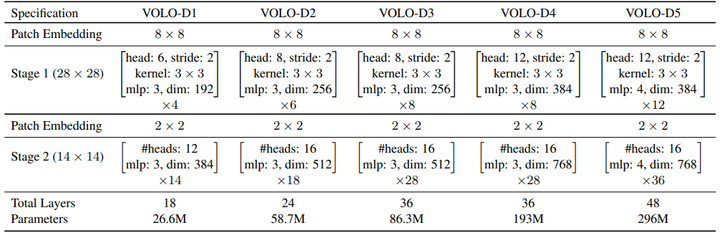
3.3. VOLO的不同变种¶
作者在文中给出了不同变种的VOLO,其中Stage 1为Outlook Attention+MLP,Stage 2为Self-Attention+MLP。
3.4. 复杂度分析¶
文中给出了Self-Attention、Local Self-Attention,和Outlook Attention的复杂度。通常NK^2<2C,所以OA的复杂度是低于SA和LSA的。
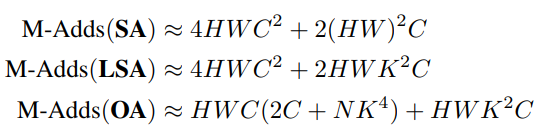
4. 实验¶
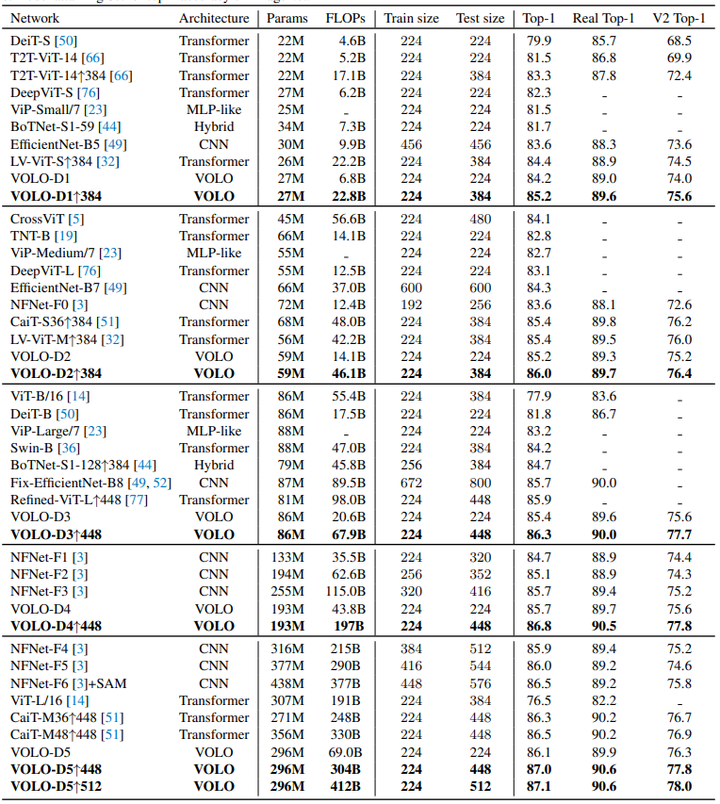
不同VOLO变种在Imagenet上的准确率对比
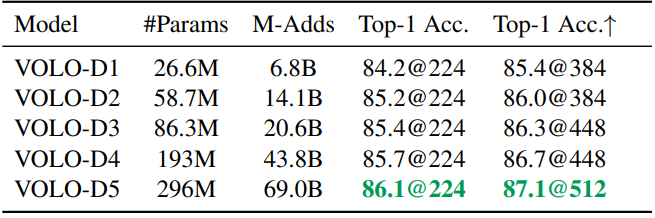
用不同模块进行局部感知的结果(说明OA确实比LSA和Conv更强一些)
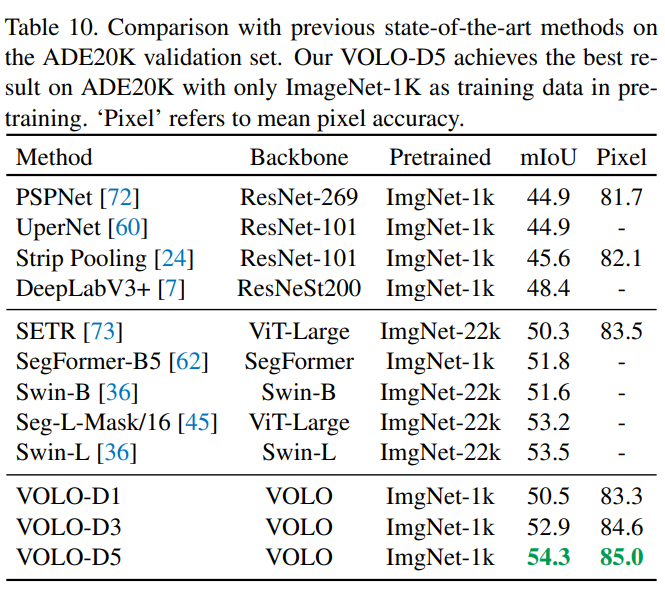
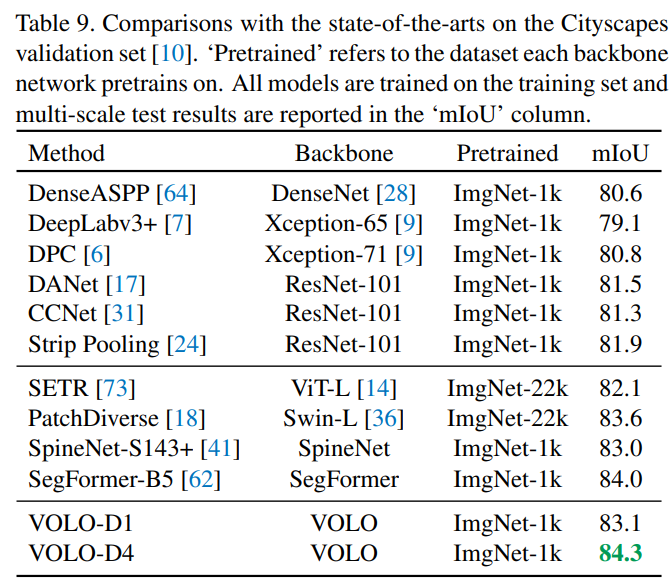
在分割任务上的performance
5. 总结¶
这篇论文其实也是在为了解决Self-Attention只有全局信息感知的缺点,Outlook Attention相当于是加入了一个局部感知的功能,使得模型能够感知局部特征,从而使最终提取的特征更加细粒度。这篇工作也是将ImageNet数据集上Performance刷到了一个新高度。
本文总阅读量次