0x0. 前言¶
2月份的时候评测过TeleChat-7B大模型,见星辰AI大模型TeleChat-7B评测。最近中电信 AI 科技有限公司针对TeleChat-7B进行了性能升级,并开源了一个更大的模型TeleChat-12B,受邀对这个大模型进行新的评测。本文主要关注TeleChat-7B在做一些文学创作和代码生成方面相比于TeleChat-7B的提升。TeleChat-7B不仅在模型结构上有所微调,而且相比于TeleChat-7B的1.5T Tokens,TeleChat-12B使用了3T Tokens进行预训练,取得了更好的性能结果。下面红框部分是TeleChat-12B相比于TeleChat-7B在通用能力,推理和代码能力,语言理解能力等维度的数据集上的性能提升:
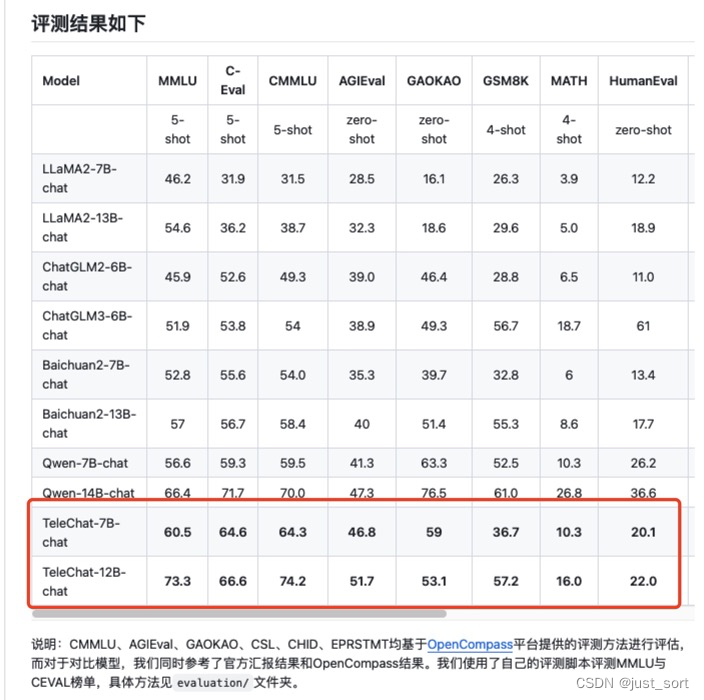
0x1. TeleChat-12B相比于TeleChat-7B的差异点¶
TeleChat-12B和TeleChat-7B均开源在https://github.com/Tele-AI/Telechat这个仓库中,并且在Huggingface,ModelScope等大模型托管平台进行托管,另外还开源了int8和int4两种低比特类型的模型方便部署。这里着重说明一下TeleChat-12B和TeleChat-7B的差异之处: - 数据方面,TeleChat-12B使用了3T tokens进行预训练,而TeleChat-7B则只用了1.5T tokens。 - 在模型结构方面,相比TeleChat-7B模型,TeleChat-12B模型采用了词嵌入层与输出层解耦的结构,将词嵌入层和输出lm head层参数分开,有助于增强训练稳定性和收敛性。 - 在训练方法方面,TeleChat-12B训练时使用更科学的数据配比学习与课程学习的方法,使用小参数模型在多种数据配比的数据上拟合,得到对各个数据集难度的先验估计;训练过程中每隔一段时间自动化评估当前模型在所有数据集上的loss,以及在评测集上的生成效果,动态提升较难学习的数据集权重,保证模型在各个数据集上都有较佳的拟合效果。 - 后续通过对比TeleChat-7B和TeleChat-12B在文创和代码方面的一些例子可以发现TeleChat-12B在指令跟随,幻觉,补全文本的指令以及代码创作上都有较大提升。
0x2. 环境配置¶
可以使用官方提供的Docker镜像,也可以自己按照 https://github.com/Tele-AI/Telechat/blob/master/requirements.txt 来配置。我这里是直接使用了官方的镜像,基本没踩什么坑,按照 https://github.com/Tele-AI/Telechat/blob/master/docs/tutorial.md 这个教程操作就可以。
0x3. 文学创作能力测试¶
为了更加真实的观察模型的文学创作能力,这里不使用TeleChat官方开源仓库提供的例子,而是使用我们自己的一些prompt来进行测试。其中部分例子取自:https://github.com/SkyworkAI/Skywork#chat%E6%A8%A1%E5%9E%8B%E6%A0%B7%E4%BE%8B%E5%B1%95%E7%A4%BA 。然后来关注TeleChat-7B和TeleChat-13B的输出结果,测试代码为:
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
question="通过对“红楼梦中的人,都散在眼前”的理解,尝试创作一首描绘梦境与现实的五言律诗。"
print('==============Prompt===================')
print(question)
print('==============TeleChat-7B==============')
tokenizer = AutoTokenizer.from_pretrained('/bbuf/telechat-7B/', trust_remote_code=True,)
model = AutoModelForCausalLM.from_pretrained('/bbuf/telechat-7B/', trust_remote_code=True, device_map="auto", torch_dtype=torch.float16)
generate_config = GenerationConfig.from_pretrained('/bbuf/telechat-7B/')
answer, history = model.chat(tokenizer = tokenizer, question=question, history=[], generation_config=generate_config, stream=False)
print(answer)
print('==============TeleChat-12B==============')
tokenizer = AutoTokenizer.from_pretrained('/mnt/data/cangshui/bbuf/TeleChat-12B/', trust_remote_code=True,)
model = AutoModelForCausalLM.from_pretrained('/mnt/data/cangshui/bbuf/TeleChat-12B/', trust_remote_code=True, device_map="auto", torch_dtype=torch.float16)
generate_config = GenerationConfig.from_pretrained('/mnt/data/cangshui/bbuf/TeleChat-12B/')
answer, history = model.chat(tokenizer = tokenizer, question=question, history=[], generation_config=generate_config, stream=False)
print(answer)
另外我还做了一个改动,把两个模型文件夹下的generation_config.json里面的do_sample都改成了true,让结果更加丰富。
针对相同的输入prompt分别使用7b和12b的模型进行推理,对比输出结果。
- 诗词创作

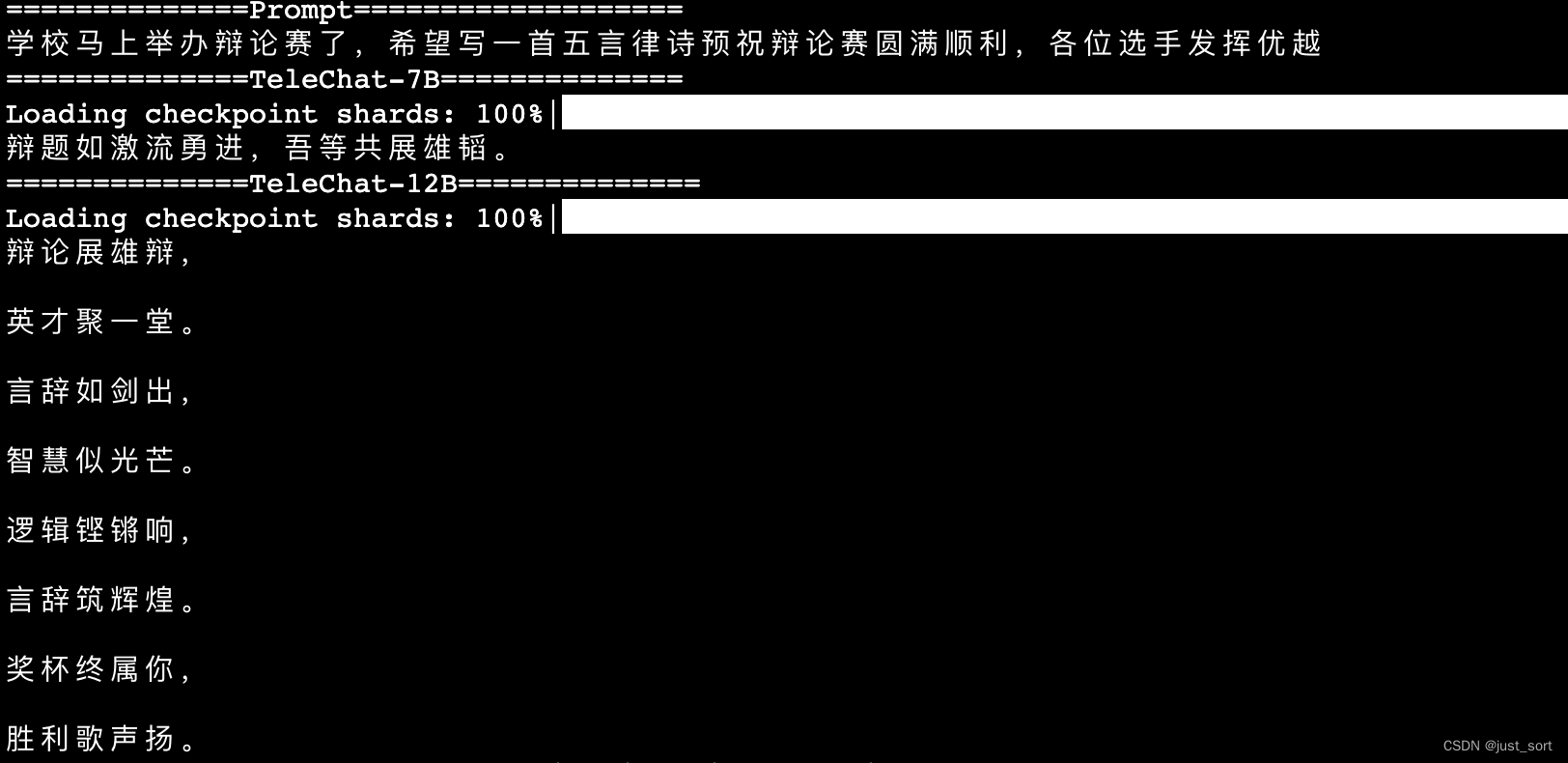

测试一下写诗,发现TeleChat-7B和TeleChat-12B模型在诗词创作方面的能力都比较有限,虽然可以生成一些和prompt描述相关的文字,但是对五言,七言等诗歌形式往往不能正常理解。可能和数据里面没有特意微调这种情况有关系。
- 广告文案




从这几个例子可以看到TeleChat-12B的指令跟随能力比7B要更好一些,并且输出的内容质量也更高。
- 作文生成

 (上面2张图是一个prompt)
(上面2张图是一个prompt)


上面写了2篇作文,看起来12B的模型也是比7B的表现更好,重要的是对于字数的判断12B模型更加准确,而7B模型似乎忽略了prompt里面字数限制的指令。
- 演讲稿生成


上面两张图是同一个prompt。

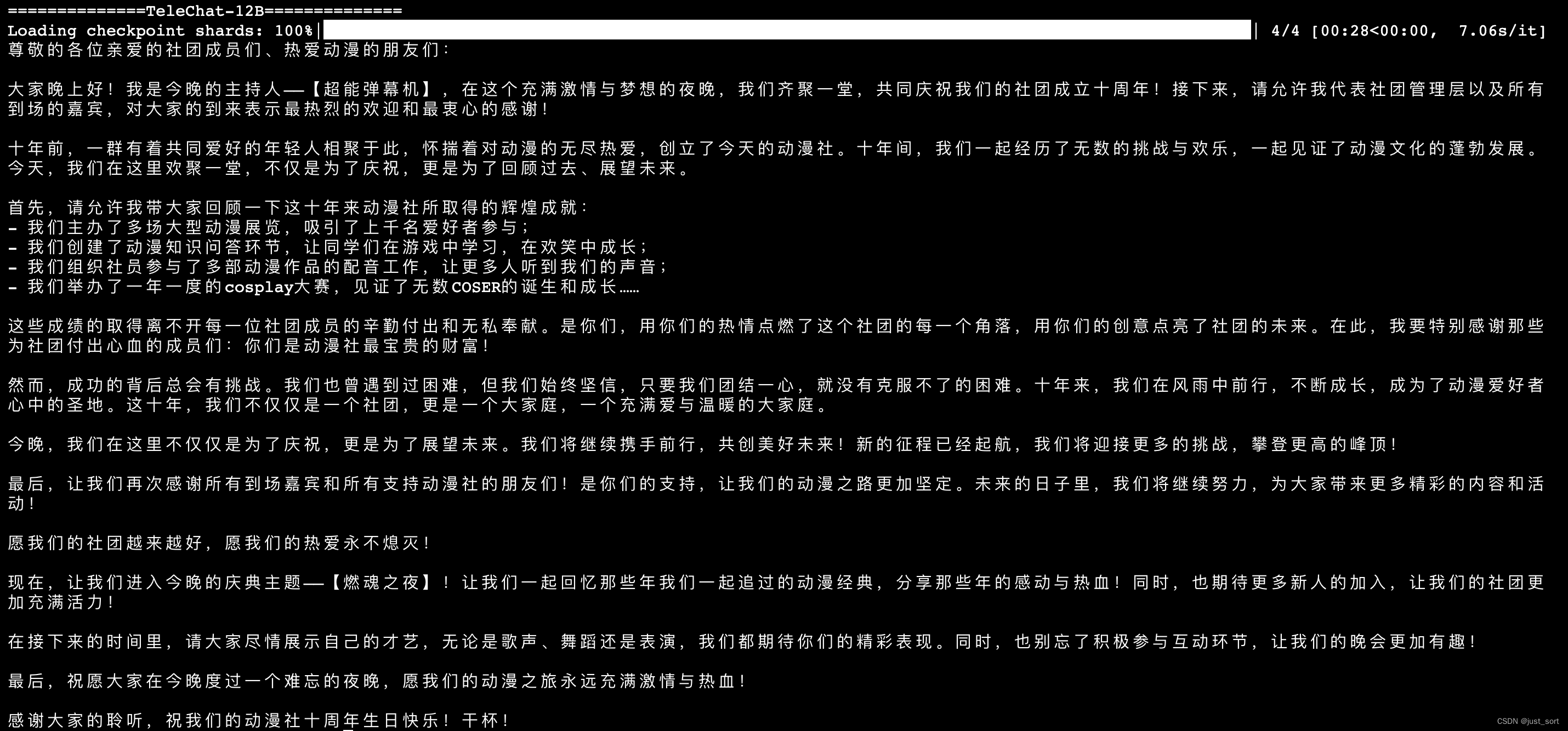
TeleChat-12B的创作质量相比于TeleChat-7B明显更高。
- 心得体会

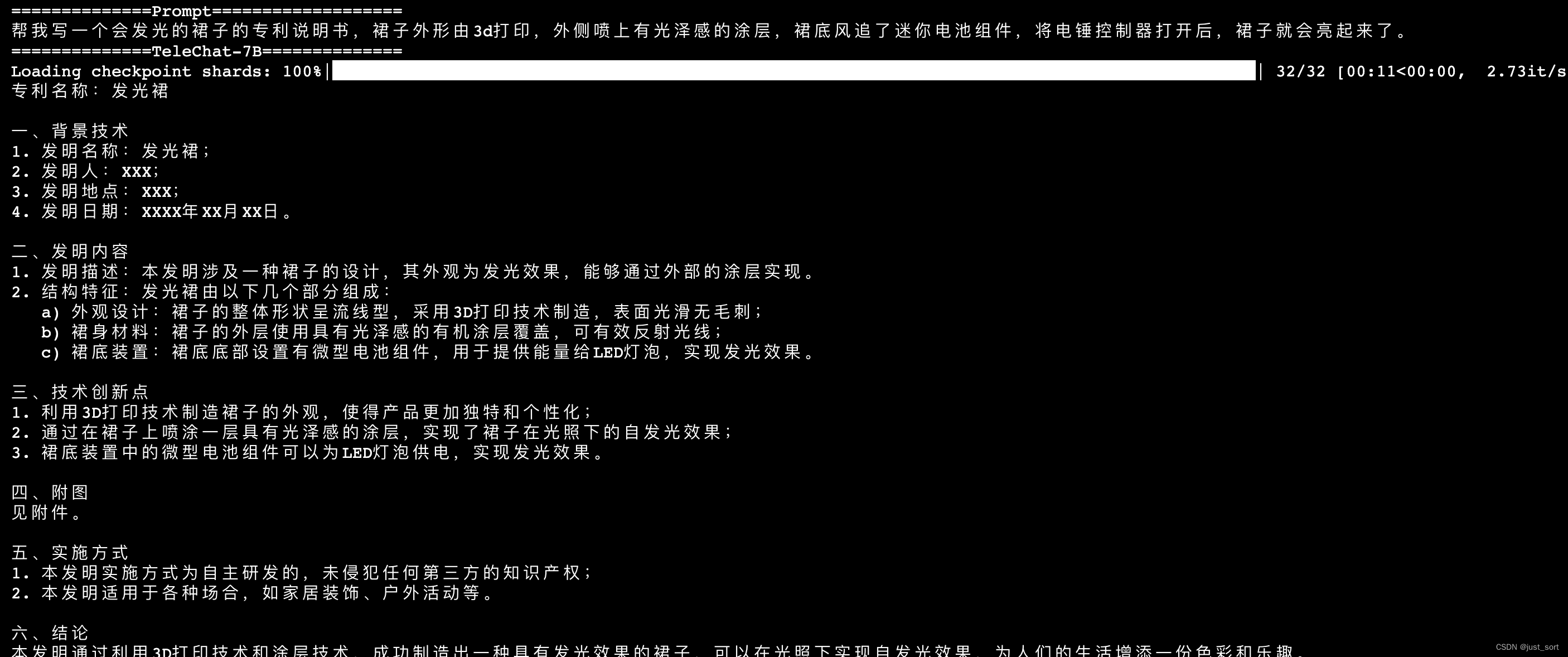
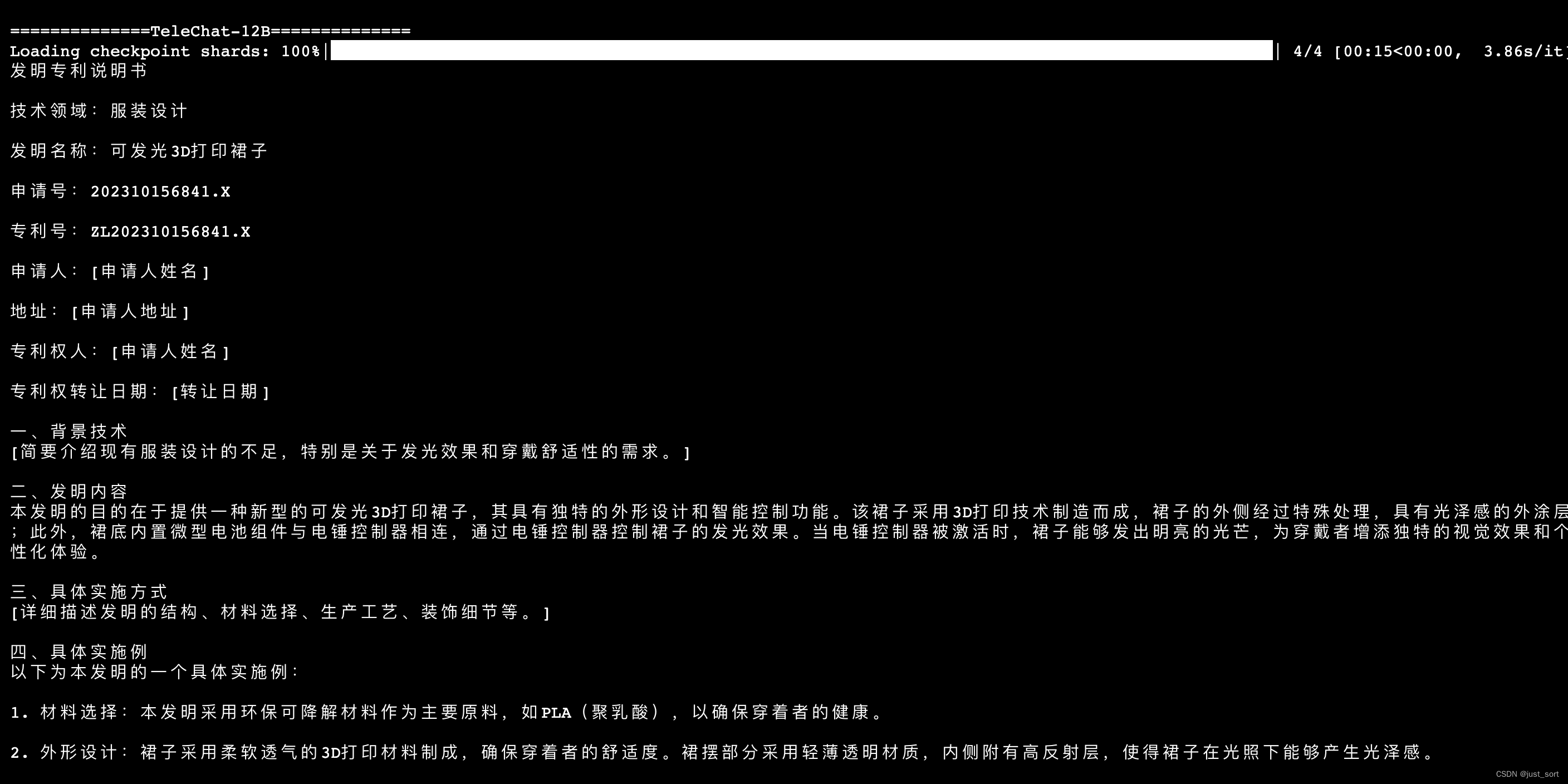

上面三张图是一个prompt的输出。
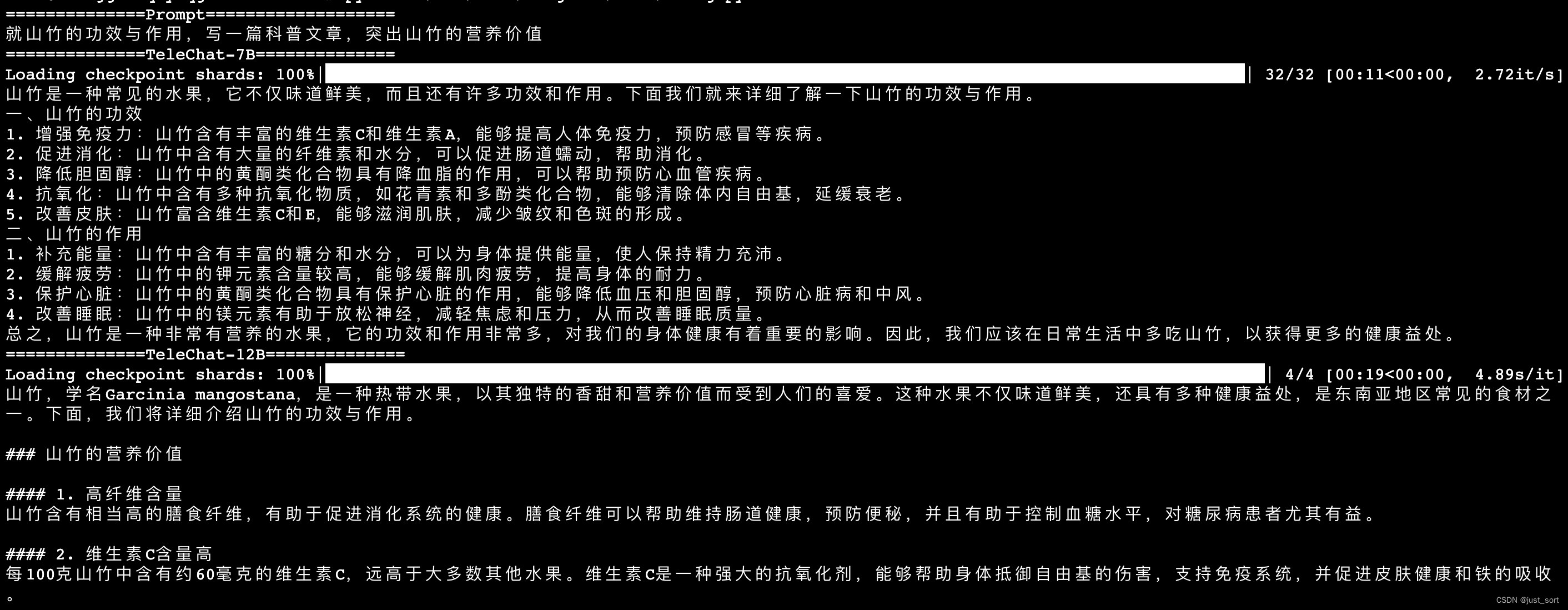

上面两张图是一个prompt的输出。
同样,TeleChat-12B的创作质量相比于TeleChat-7B明显更高,并且更加丰富,对于发明专利写得更专业。
- 记录文
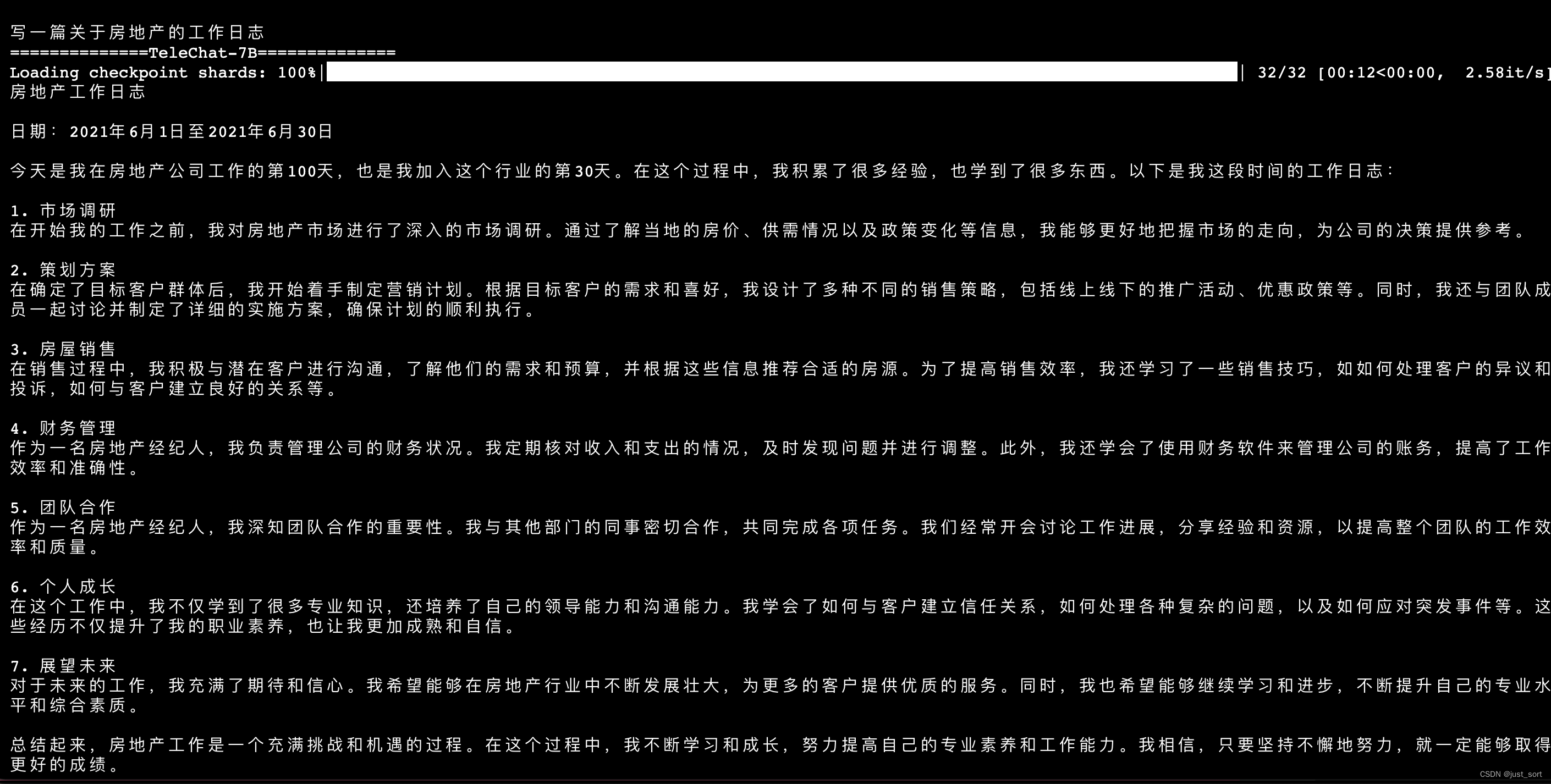
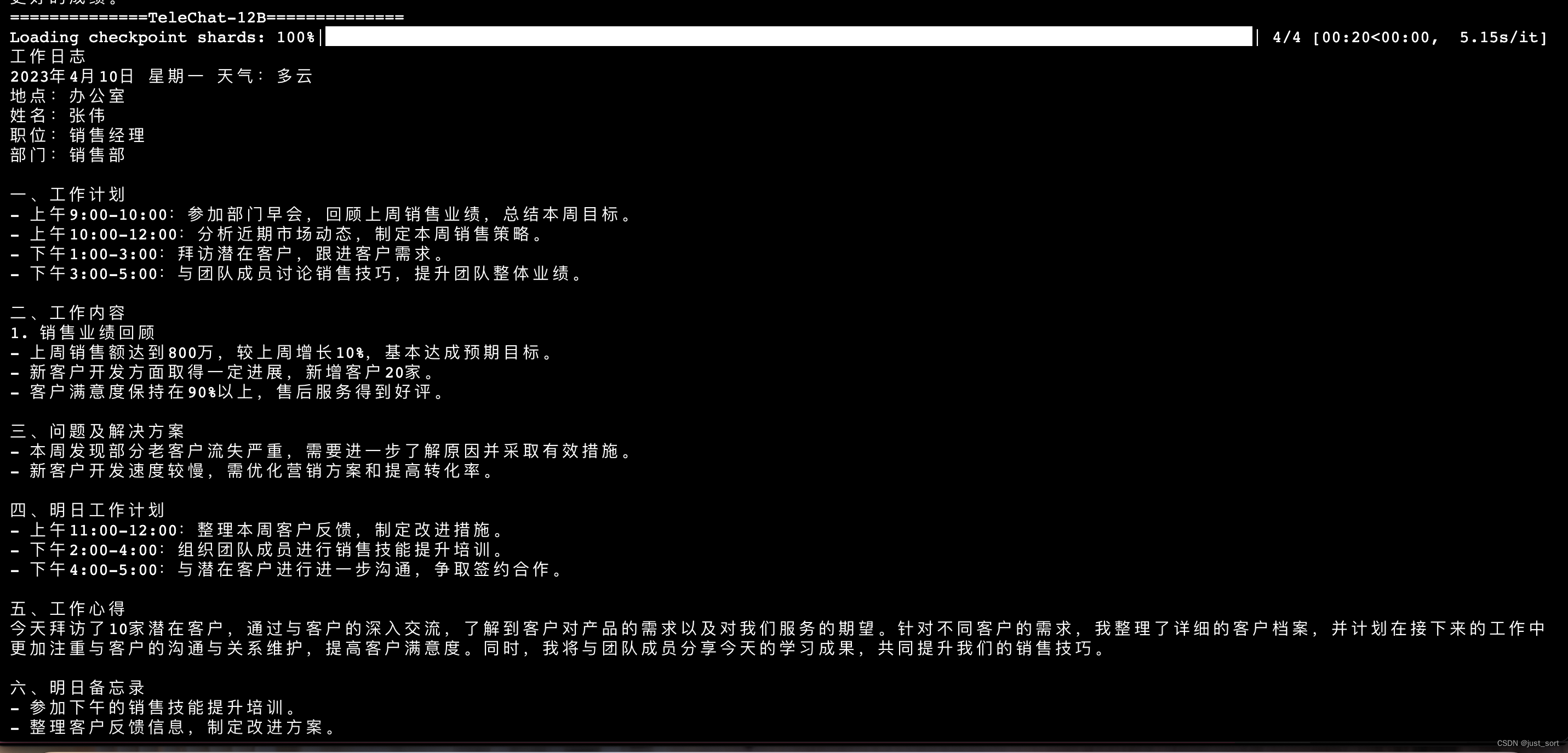
上面两张图片是同一个prompt的输出。
总的来说,在文学创作方面,TeleChat-12B相比于TeleChat-7B无论是在质量还是指令跟随上都更好一些,可以获得更好的创作效果。
0x4. 代码能力对比测试¶
- Python中的深拷贝和浅拷贝有什么区别? 请用代码示例解释这两种拷贝方式。


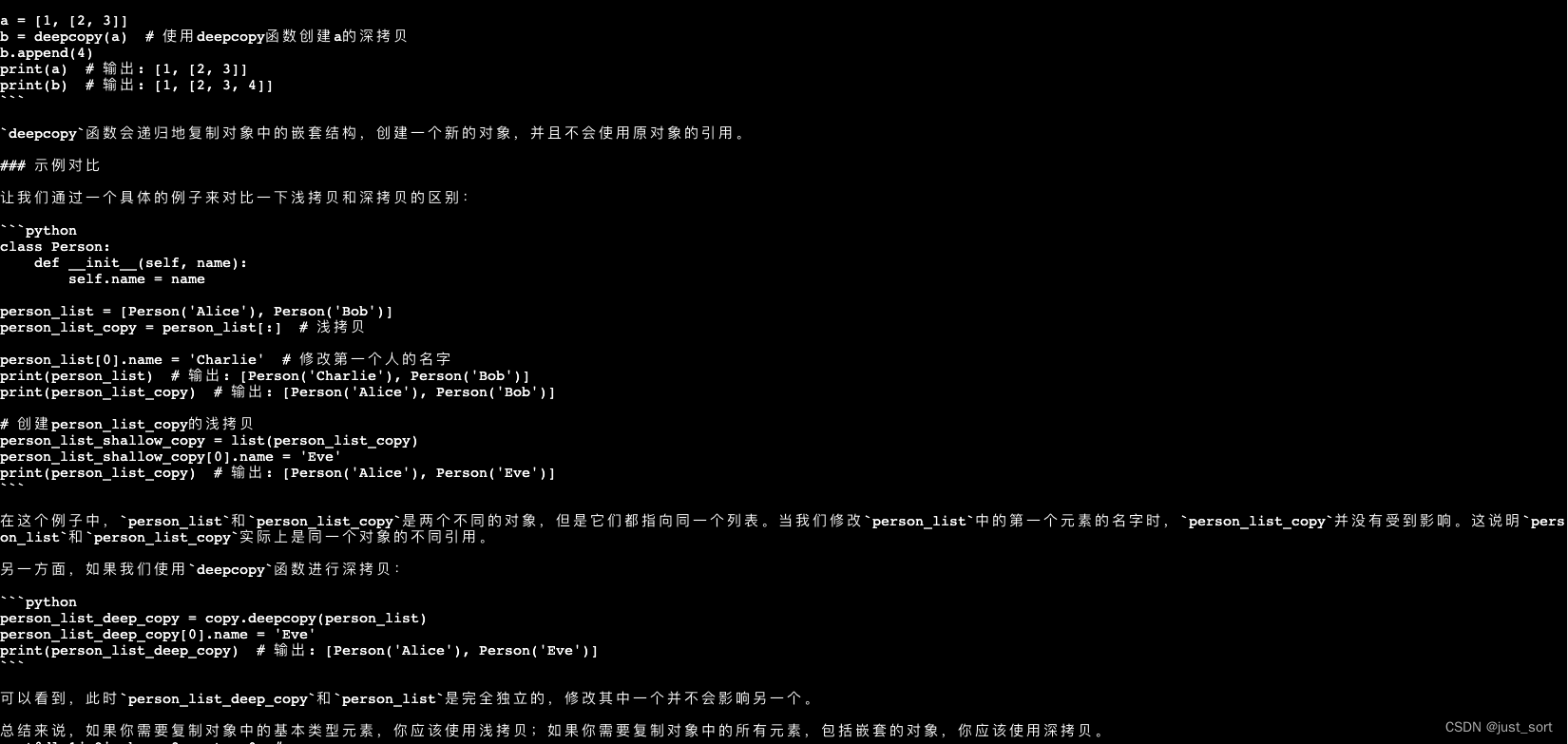
对于深浅拷贝,TeleChat-7B的答案完全错误,而TeleChat-12B的答案则更靠谱,指出了浅拷贝是副本共享内部对象的引用,而深拷贝的副本不共享内部对象的引用,但在对比的时候代码注释仍然有个小错误。
- 如何合并两个已排序的数组? 编写一个函数,将两个已排序的整数数组合并为一个排序后的数组。
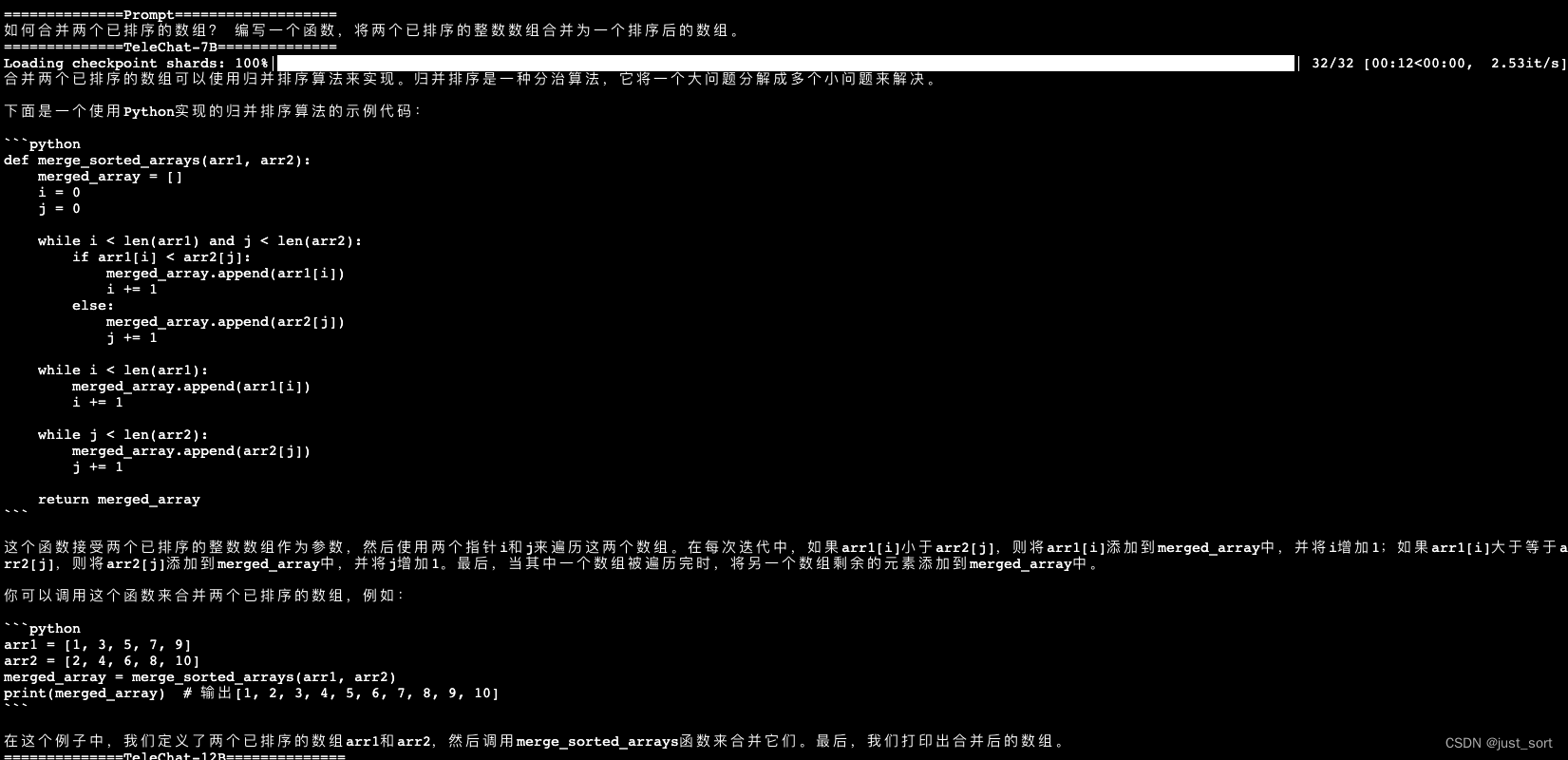
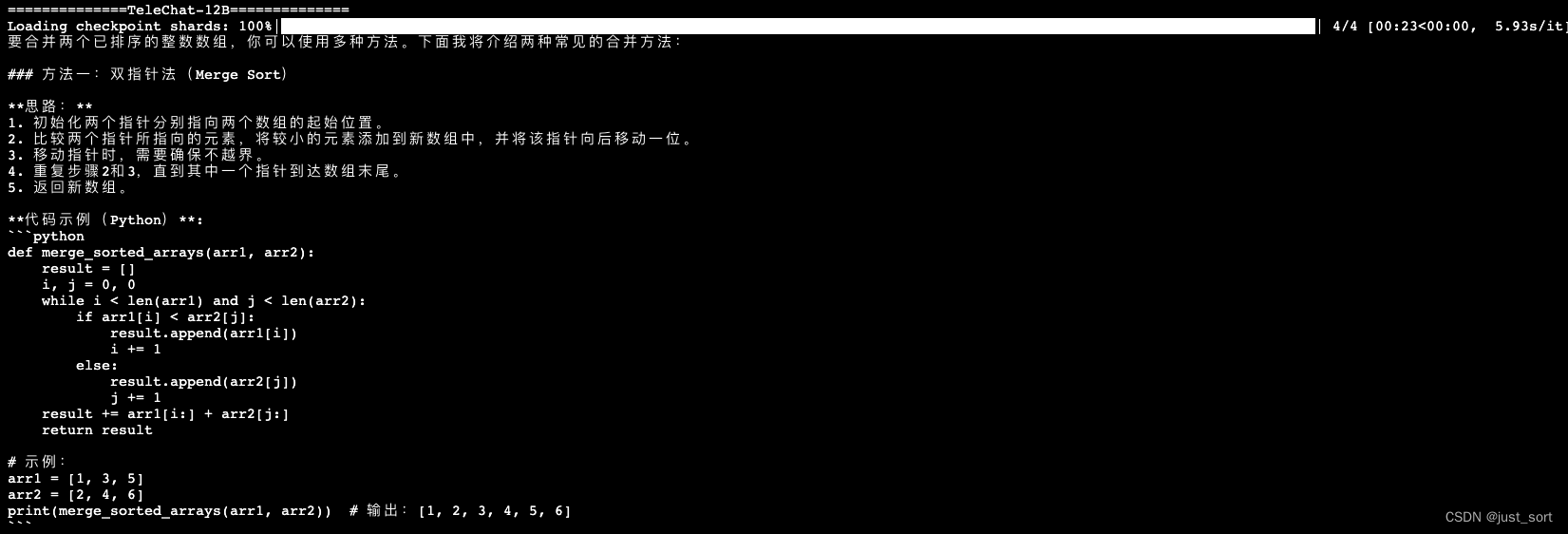

- 判断一个数是否为质数。 编写一个函数,判断给定的整数是否是质数,并考虑优化算法的效率。
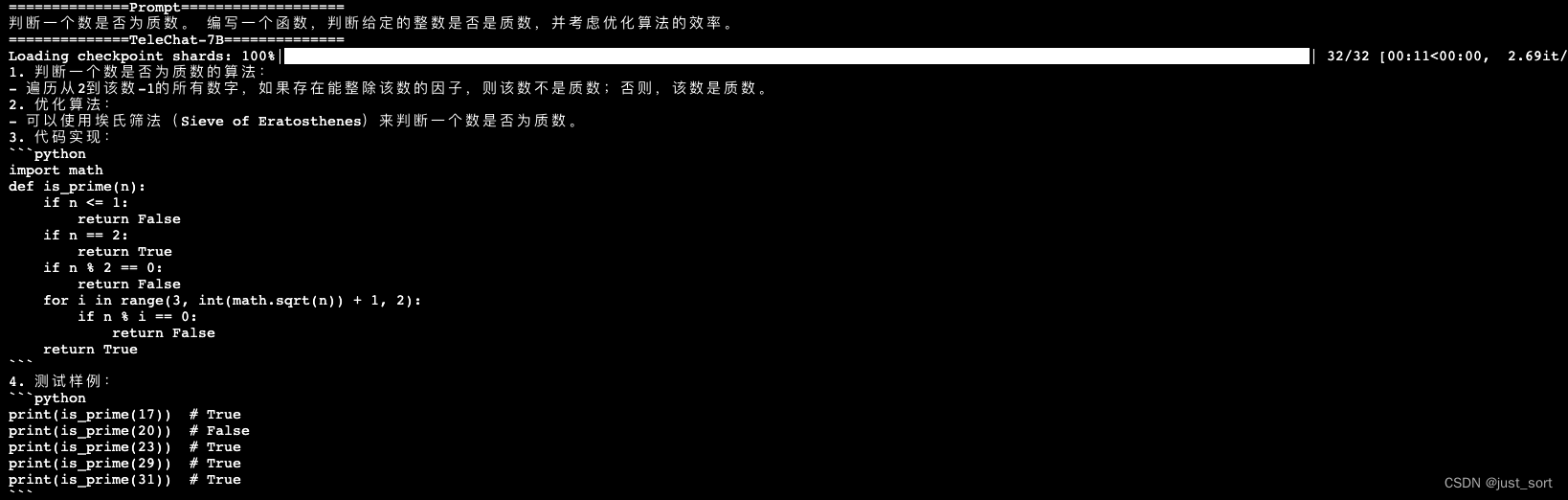
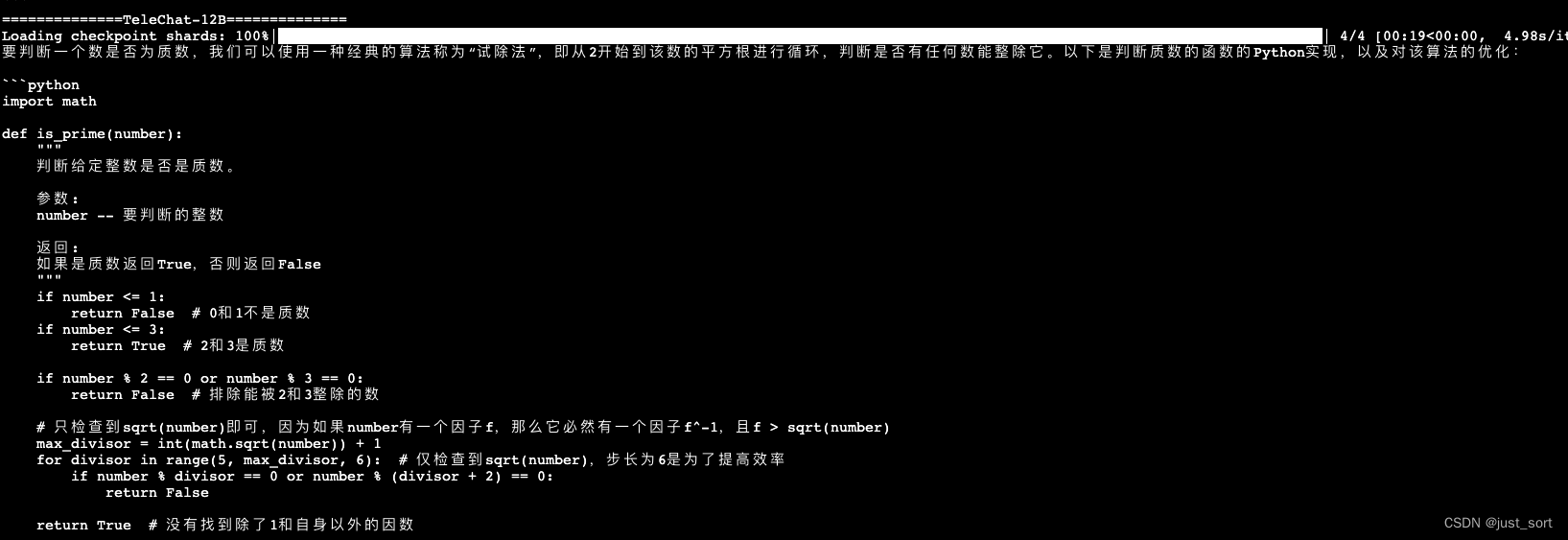

相比于TeleChat-7B的答案。TeleChat-12B提供了两种方法并指明了第二种方法的时间复杂度更小,回答的质量更高。
- c++编写一个函数,将字符串中所有指定的单词替换为另一个单词。
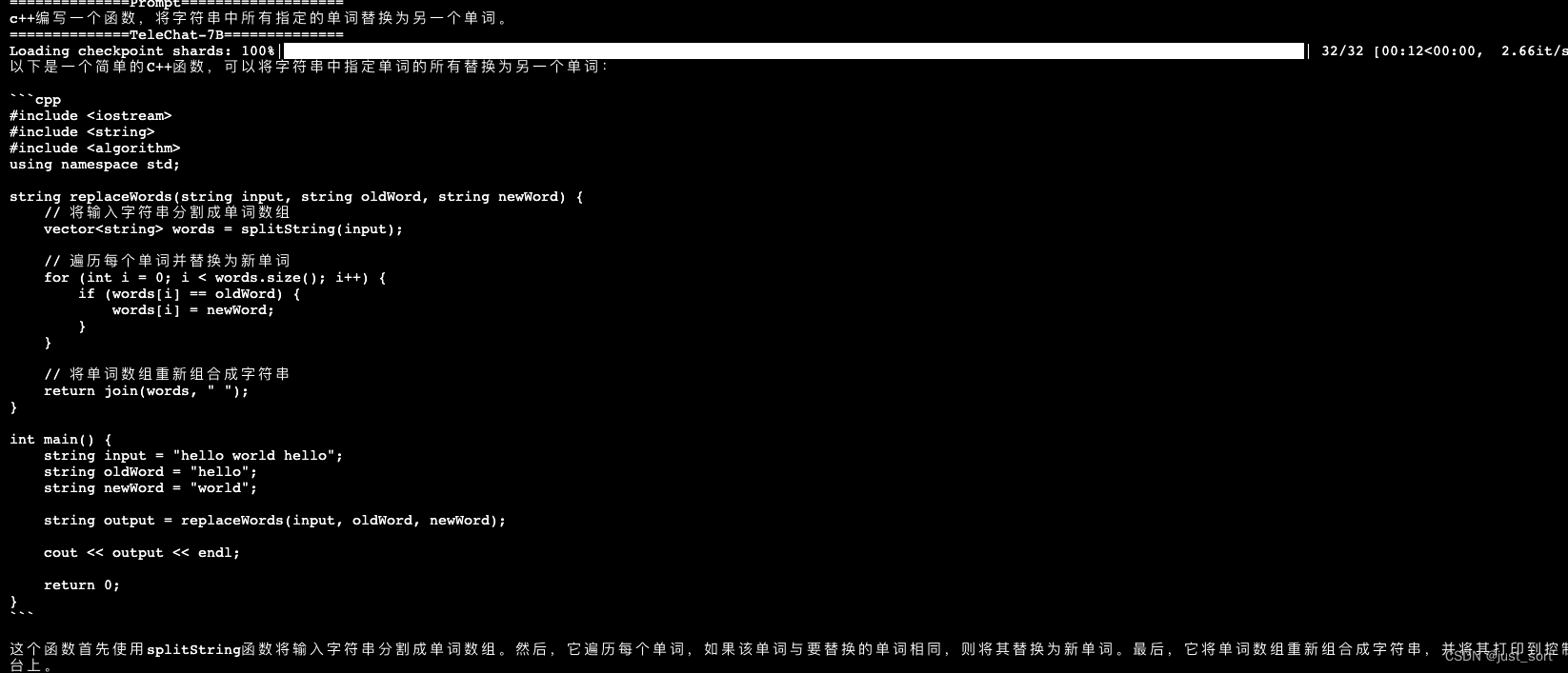
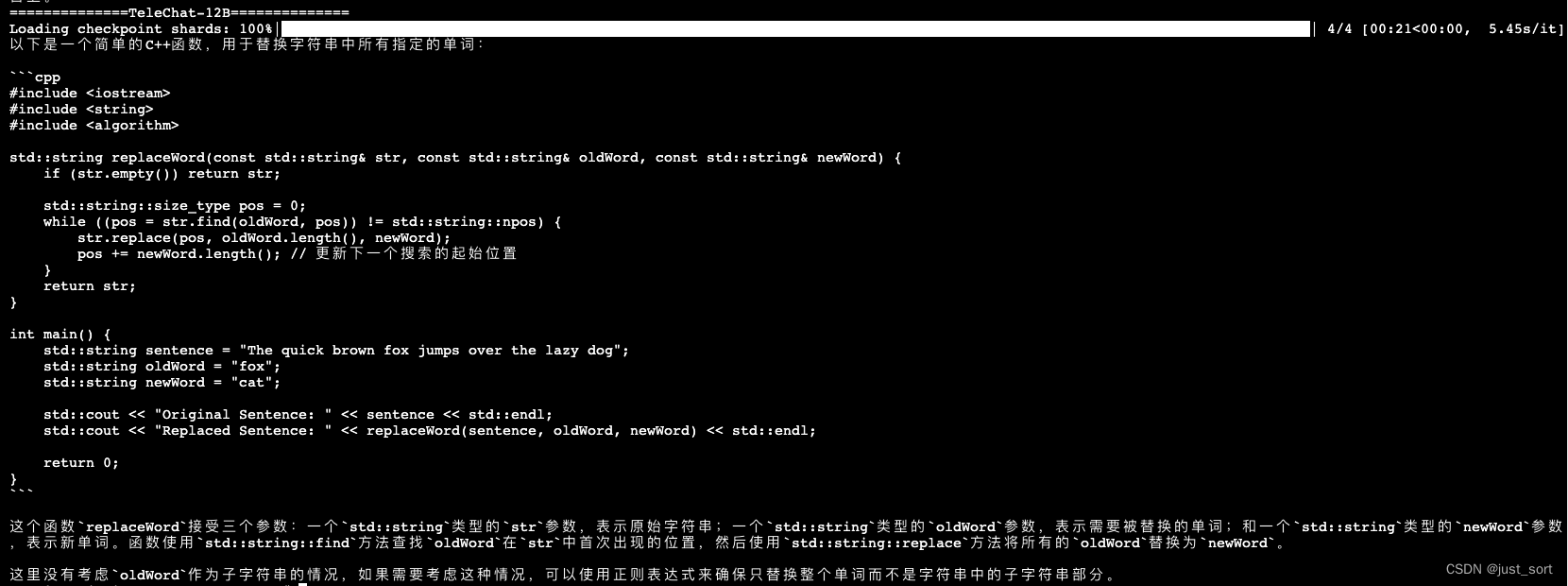
对于这个问题,TeleChat-12B可以正确理解并给出解决方案,而TeleChat-7B的答案是错误的。
通过上述一些编程问题,可以发现TeleChat-12B在编程能力上相比于TeleChat-7B有较大提升,这种提升的原因大概率是新增的1.5T数据包含了部分代码数据。
0x5. 总结¶
本文通过对比TeleChat-7B和TeleChat-12B在文创和代码方面的一些例子可以发现TeleChat-12B在指令跟随,幻觉,补全文本的指令以及代码创作上都有较大提升。希望后续能持续在网络结构,数据方面做出改进,做出更强的开源模型。
本文总阅读量次