LightSeq Transformer高性能加速库
引言¶
Transformer,Bert模型在NLP领域取得巨大成功,得到广泛应用。而Transformer系列模型大小通常很大,在应用层提供相应服务是一个巨大的挑战。
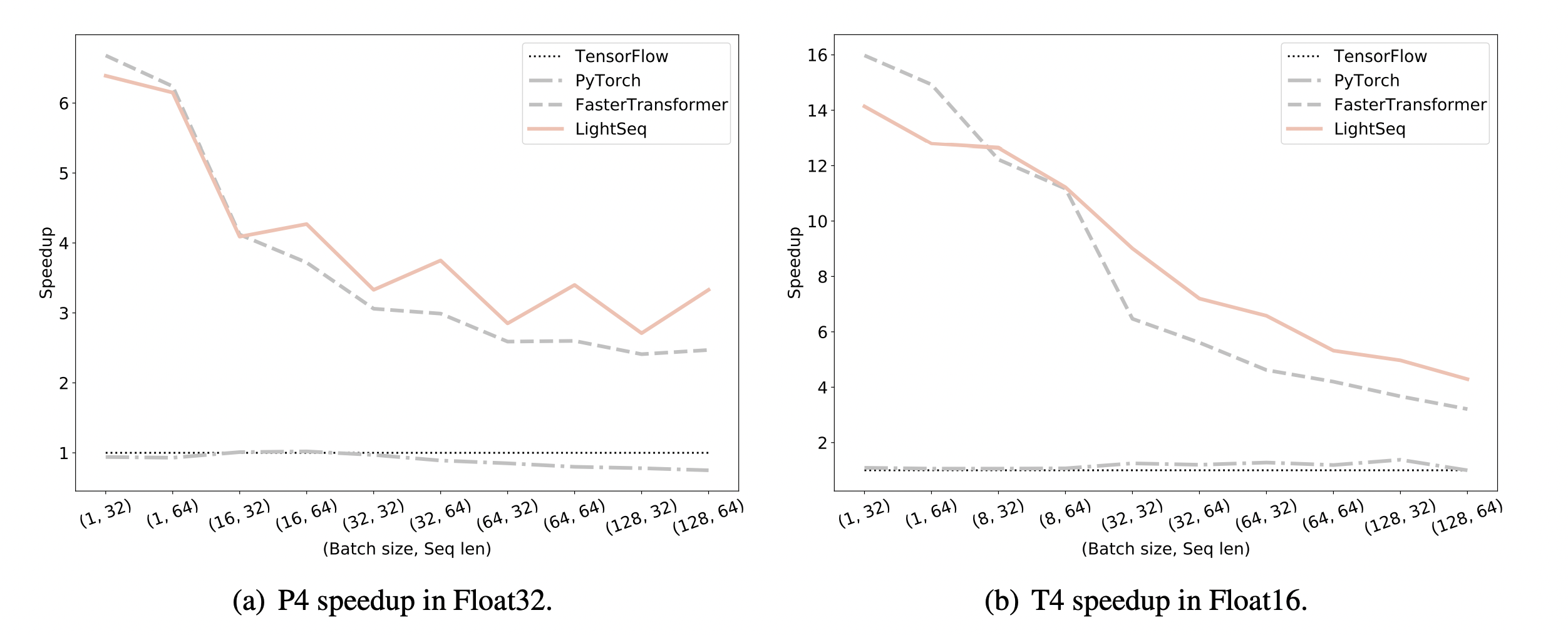
字节提出的lightseq是一款高性能训练,推理库,包含了各种GPU优化技术,并且能够很好兼容tf/torch的模型实现。相比Tensorflow原生实现能达到14倍加速,比英伟达出品的FasterTransformer能够加速1.4倍。
论文:https://arxiv.org/abs/2010.13887
仓库地址:https://github.com/bytedance/lightseq
介绍¶
类似LightSeq的高性能加速库也有很多,下面的三个主要特性是我们比别的加速库表现好的原因:
-
我们将Tensorflow/Pytorch实现中的一些细粒度Kernel,进一步融合实现成一个粗粒度的Kernel,从而避免大量核函数启动和GPU memory IO带来的时间成本
-
我们设计了一种hierarchical(层级) auto regressive search来替代auto regressive search,进一步加速
-
我们提出了一种动态显存复用策略,在NLP处理中,我们经常会遇到变长数据,给内存分配带来了困难。LightSeq预先定义了每个kernel最大可使用显存,并给不存在依赖关系的kernel进行共享,能够减少8倍内存分配。
方法¶
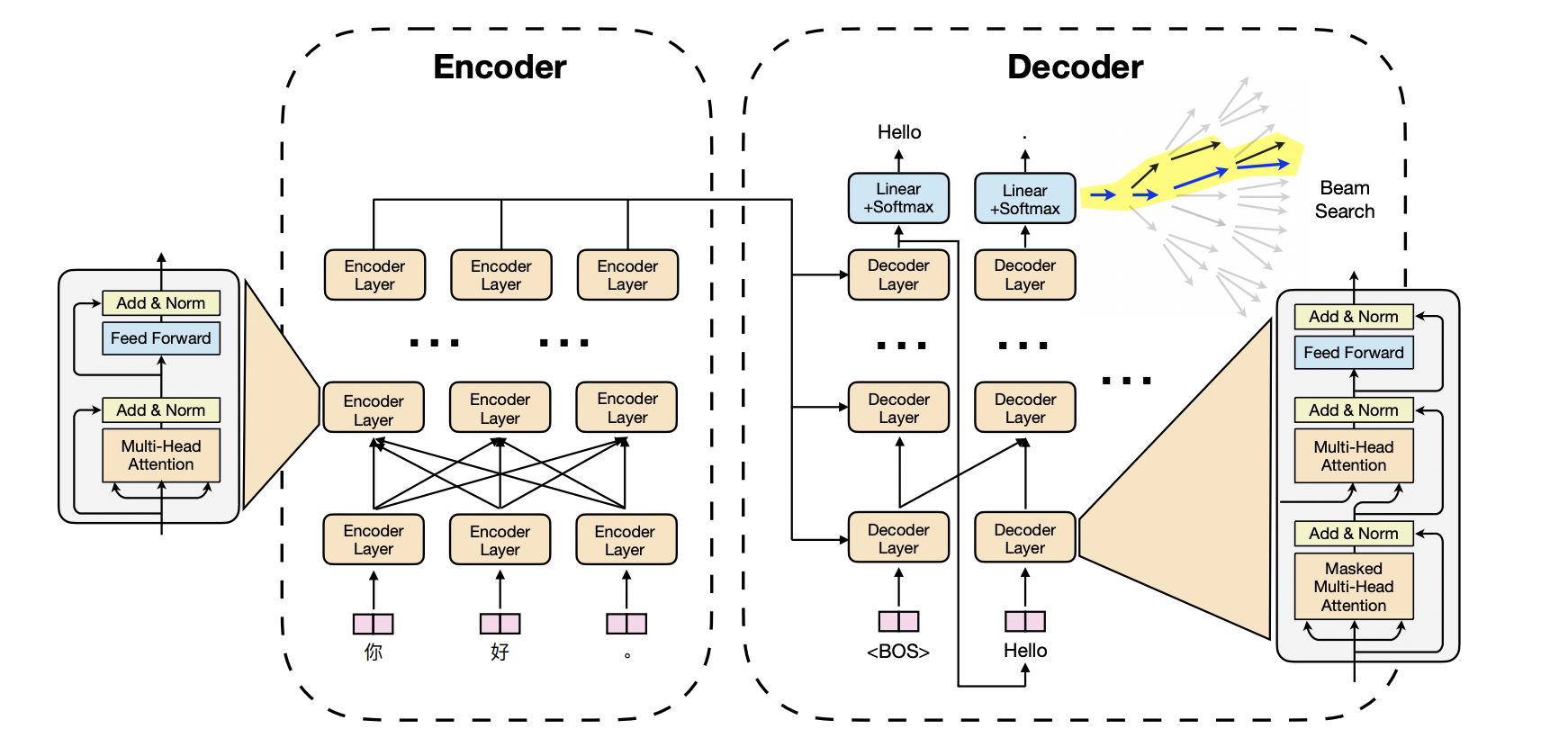
Transformer主要分为两部分,特征计算层和输出层。特征计算层就是自注意力机制+FFN这些,而输出层则会随着任务不同而有些许改变。在NLU上是分类,而在NLG上是搜索(用beam search)。
我们做了一下三个优化来分别解决前面提到的问题
kernel fusion¶
简单来说就是将多个kernel,融合进一个大kernel。
以LayerNormalization(tf版本)为例子,在XLA优化过后,仍然需要3次kernel launch和2个临时变量存储(mean和variance)。
我们可以借助cuda来自定义一个完整的LayerNorm Kernel。 (代码地址:https://github.com/bytedance/lightseq/blob/master/lightseq/training/csrc/kernels/normalize_kernels.cu#L35-L77)
template <typename T>
__global__ void ker_layer_norm(T *ln_res, T *vars, T *means, const T *inp,
const T *scale, const T *bias, int hidden_size) {
// step 0. compute local sum
float l_sum = 0;
float l_square_sum = 0;
const float4 *inp_f4 = (const float4 *)inp + blockIdx.x * hidden_size;
for (uint idx = threadIdx.x; idx < hidden_size; idx += blockDim.x) {
float4 val = inp_f4[idx];
l_sum += val.x + val.y + val.z + val.w;
l_square_sum +=
val.x * val.x + val.y * val.y + val.z * val.z + val.w * val.w;
}
val.x, val.y, val.z, val.w来取。计算square sum是用于后面var的计算。
接着是做reduce sum操作了
// step 1. compute reduce sum
float mean_dim = float(hidden_size) * 4.f;
float reduce_val[2] = {l_sum, l_square_sum};
blockReduce<ReduceType::kSum, 2>(reduce_val);
__shared__ float s_mean, s_var;
if (threadIdx.x == 0) {
s_mean = reduce_val[0] / mean_dim;
if (means != nullptr) {
means[blockIdx.x] = s_mean;
}
s_var = reduce_val[1] / mean_dim - s_mean * s_mean + LN_EPSILON;
vars[blockIdx.x] = s_var;
s_var = rsqrtf(s_var);
}
__syncthreads();
这里的var用的是公式
得到,然后进行同步。注意这里的s_mean和s_var是一个shared变量,可以被同一个block内的其他线程得到。
最后就是减均值,除方差,拉伸变换这部分操作
// step 2. layer norm result
float4 *output_f4 = (float4 *)ln_res + blockIdx.x * hidden_size;
for (uint idx = threadIdx.x; idx < hidden_size; idx += blockDim.x) {
float4 vscale = __ldg((const float4 *)scale + idx);
float4 vbias = __ldg((const float4 *)bias + idx);
float4 val = inp_f4[idx];
val.x = (val.x - s_mean) * s_var * vscale.x + vbias.x;
val.y = (val.y - s_mean) * s_var * vscale.y + vbias.y;
val.z = (val.z - s_mean) * s_var * vscale.z + vbias.z;
val.w = (val.w - s_mean) * s_var * vscale.w + vbias.w;
output_f4[idx] = val;
}
kernel fusion这种优化也是在别的加速库很常见,nvidia出品的Megatron也有做layernorm,mask+softmax,triangle(取上三角)+mask+softmax的融合,具体可参考:https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/fused_kernels
Hierarchical Auto Regressive Search¶
auto regressive search方法如beam seach, diverse beam search等方法计算过于复杂。通常我们只需要置信度较高的几个label/tokens,而不是所有token都需要参与最终输出的计算。
我们简单回顾下beam search做法: 1. 使用softmax计算,并将结果写入gpu memory 2. 读取结果,并从中选取top-K的beams和tokens
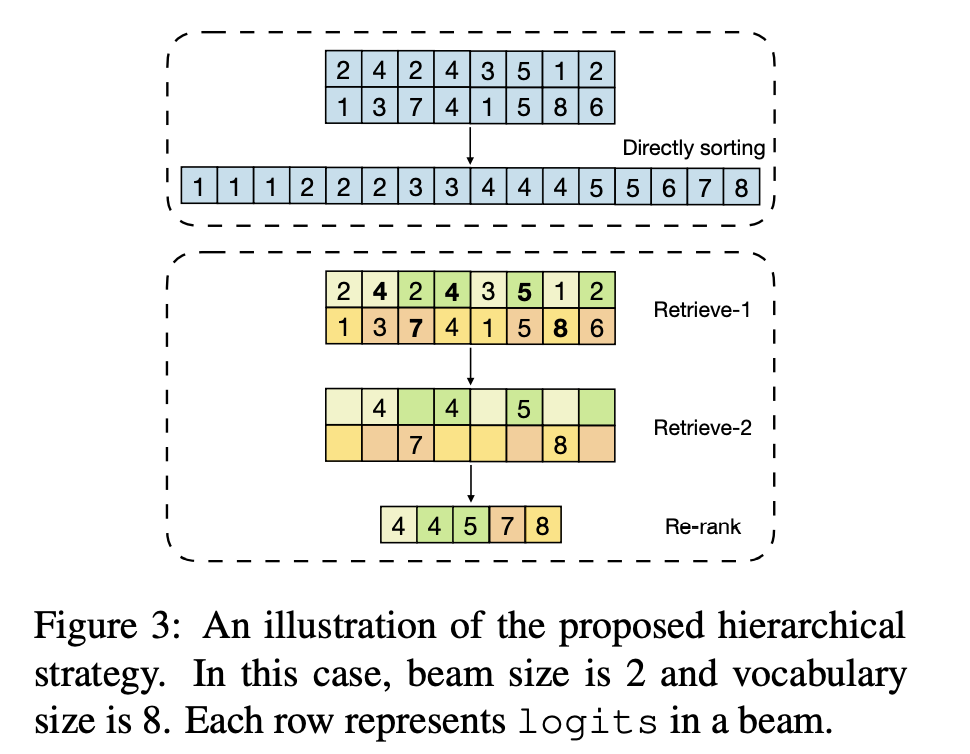
而lightseq受启发于推荐系统的检索+重排,采用了两阶段策略: 1. 随机将logits组分到k个组 2. 计算每个group(g_i)的最大值,记为m_i 3. 在m_i中,计算最小值R,可以看作是logits粗略的top-k值 4. 选择值大于R的logits,并写入到gpu memory
为什么这种做法是粗略的top-k呢?假设我们有[1, 2, 3, 4, 5, 6],我想要取top2,那这里应该是6。 按照lightseq做法,我们先随机分两组,如果是这种情况[1, 5, 6], [2, 3, 4]。那么每组最大值分别是6, 4。然后取最小值,得到top2是4。所以只能看作是一种粗略的topk
动态显存复用¶
LightSeq预先定义好动态shape的最大长度,在一开始先分配好最大显存,此外GPU显存将共享给不存在依赖关系的中间结果。
我理解这种做法是用于变长数据中,因为以往遇到变长数据,我们都会统一padding到一个固定长度,在最后计算loss也是加上一个padding mask。使用这种做法就能节省显存。
另外字节也出品了一个Effective Transformer,也是解决变长数据问题。通过对mask求一个前缀和,在计算attention前后进行相应的删除/恢复padding。具体可参考作者的知乎文章(https://www.zhihu.com/search?type=content&q=Effective%20Transformer)
结果¶
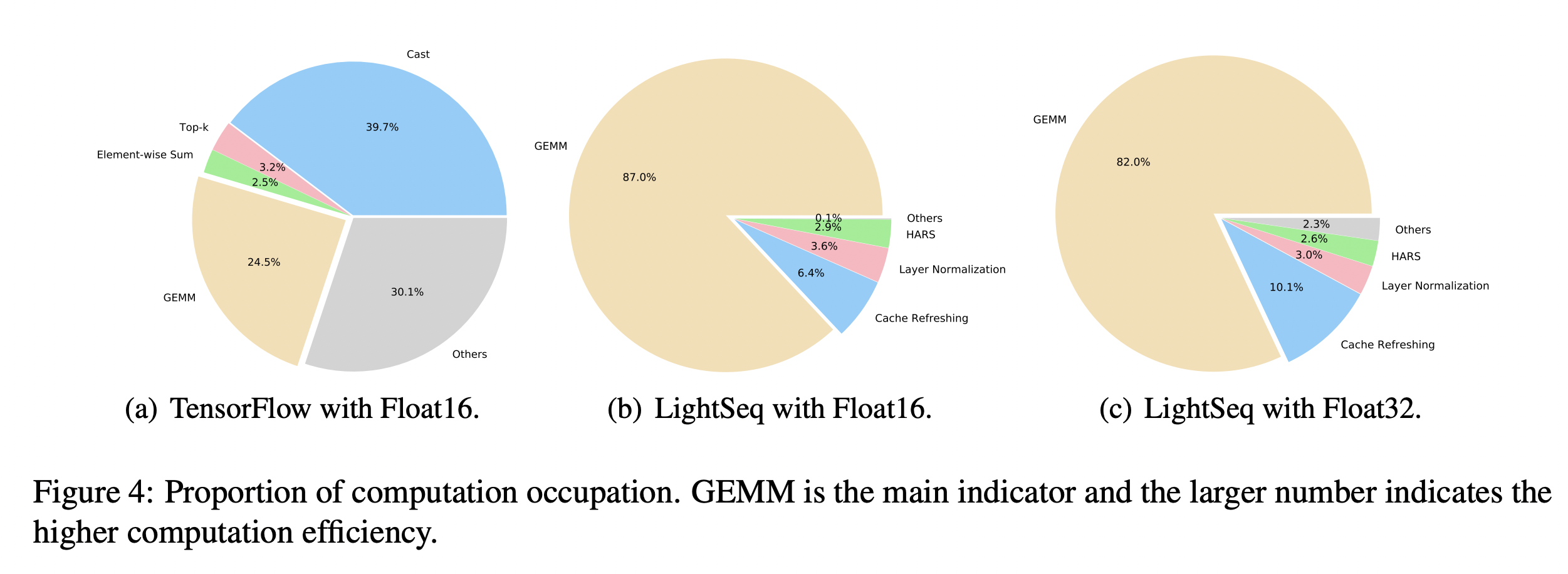
经过一系列优化后,在lightseq上,GEMM通用矩阵乘能够占大部分计算,计算效率更高。
引言¶
Transformer,Bert模型在NLP领域取得巨大成功,得到广泛应用。而Transformer系列模型大小通常很大,在应用层提供相应服务是一个巨大的挑战。
字节提出的lightseq是一款高性能训练,推理库,包含了各种GPU优化技术,并且能够很好兼容tf/torch的模型实现。相比Tensorflow原生实现能达到14倍加速,比英伟达出品的FasterTransformer能够加速1.4倍。
论文:https://arxiv.org/abs/2010.13887
仓库地址:https://github.com/bytedance/lightseq
介绍¶
类似LightSeq的高性能加速库也有很多,下面的三个主要特性是我们比别的加速库表现好的原因:
- 我们将Tensorflow/Pytorch实现中的一些细粒度Kernel,进一步融合实现成一个粗粒度的Kernel,从而避免大量核函数启动和GPU memory IO带来的时间成本
- 我们设计了一种hierarchical(层级) auto regressive search来替代auto regressive search,进一步加速
- 我们提出了一种动态显存复用策略,在NLP处理中,我们经常会遇到变长数据,给内存分配带来了困难。LightSeq预先定义了每个kernel最大可使用显存,并给不存在依赖关系的kernel进行共享,能够减少8倍内存分配。
方法¶
Transformer主要分为两部分,特征计算层和输出层。特征计算层就是自注意力机制+FFN这些,而输出层则会随着任务不同而有些许改变。在NLU上是分类,而在NLG上是搜索(用beam search)。
我们做了一下三个优化来分别解决前面提到的问题
kernel fusion¶
简单来说就是将多个kernel,融合进一个大kernel。
以LayerNormalization(tf版本)为例子,在XLA优化过后,仍然需要3次kernel launch和2个临时变量存储(mean和variance)。
我们可以借助cuda来自定义一个完整的LayerNorm Kernel。 (代码地址:https://github.com/bytedance/lightseq/blob/master/lightseq/training/csrc/kernels/normalize_kernels.cu#L35-L77)
template <typename T>
__global__ void ker_layer_norm(T *ln_res, T *vars, T *means, const T *inp,
const T *scale, const T *bias, int hidden_size) {
// step 0. compute local sum
float l_sum = 0;
float l_square_sum = 0;
const float4 *inp_f4 = (const float4 *)inp + blockIdx.x * hidden_size;
for (uint idx = threadIdx.x; idx < hidden_size; idx += blockDim.x) {
float4 val = inp_f4[idx];
l_sum += val.x + val.y + val.z + val.w;
l_square_sum +=
val.x * val.x + val.y * val.y + val.z * val.z + val.w * val.w;
}
val.x, val.y, val.z, val.w来取。计算square sum是用于后面var的计算。
接着是做reduce sum操作了
// step 1. compute reduce sum
float mean_dim = float(hidden_size) * 4.f;
float reduce_val[2] = {l_sum, l_square_sum};
blockReduce<ReduceType::kSum, 2>(reduce_val);
__shared__ float s_mean, s_var;
if (threadIdx.x == 0) {
s_mean = reduce_val[0] / mean_dim;
if (means != nullptr) {
means[blockIdx.x] = s_mean;
}
s_var = reduce_val[1] / mean_dim - s_mean * s_mean + LN_EPSILON;
vars[blockIdx.x] = s_var;
s_var = rsqrtf(s_var);
}
__syncthreads();
这里的var用的是公式
得到,然后进行同步。注意这里的s_mean和s_var是一个shared变量,可以被同一个block内的其他线程得到。
最后就是减均值,除方差,拉伸变换这部分操作
// step 2. layer norm result
float4 *output_f4 = (float4 *)ln_res + blockIdx.x * hidden_size;
for (uint idx = threadIdx.x; idx < hidden_size; idx += blockDim.x) {
float4 vscale = __ldg((const float4 *)scale + idx);
float4 vbias = __ldg((const float4 *)bias + idx);
float4 val = inp_f4[idx];
val.x = (val.x - s_mean) * s_var * vscale.x + vbias.x;
val.y = (val.y - s_mean) * s_var * vscale.y + vbias.y;
val.z = (val.z - s_mean) * s_var * vscale.z + vbias.z;
val.w = (val.w - s_mean) * s_var * vscale.w + vbias.w;
output_f4[idx] = val;
}
kernel fusion这种优化也是在别的加速库很常见,nvidia出品的Megatron也有做layernorm,mask+softmax,triangle(取上三角)+mask+softmax的融合,具体可参考:https://github.com/NVIDIA/Megatron-LM/tree/main/megatron/fused_kernels
Hierarchical Auto Regressive Search¶
auto regressive search方法如beam seach, diverse beam search等方法计算过于复杂。通常我们只需要置信度较高的几个label/tokens,而不是所有token都需要参与最终输出的计算。
我们简单回顾下beam search做法:
- 使用softmax计算,并将结果写入gpu memory
- 读取结果,并从中选取top-K的beams和tokens
而lightseq受启发于推荐系统的检索+重排,采用了两阶段策略:
- 随机将logits组分到k个组
- 计算每个group(g_i)的最大值,记为m_i
- 在m_i中,计算最小值R,可以看作是logits粗略的top-k值
- 选择值大于R的logits,并写入到gpu memory
为什么这种做法是粗略的top-k呢?假设我们有[1, 2, 3, 4, 5, 6],我想要取top2,那这里应该是6。 按照lightseq做法,我们先随机分两组,如果是这种情况[1, 5, 6], [2, 3, 4]。那么每组最大值分别是6, 4。然后取最小值,得到top2是4。所以只能看作是一种粗略的topk
动态显存复用¶
LightSeq预先定义好动态shape的最大长度,在一开始先分配好最大显存,此外GPU显存将共享给不存在依赖关系的中间结果。
我理解这种做法是用于变长数据中,因为以往遇到变长数据,我们都会统一padding到一个固定长度,在最后计算loss也是加上一个padding mask。使用这种做法就能节省显存。
另外字节也出品了一个Effective Transformer,也是解决变长数据问题。通过对mask求一个前缀和,在计算attention前后进行相应的删除/恢复padding。
具体可参考作者的知乎文章(https://www.zhihu.com/search?type=content&q=Effective%20Transformer) 相关代码在(https://github.com/bytedance/effective_transformer)
结果¶
经过一系列优化后,在lightseq上,GEMM通用矩阵乘能够占大部分计算,计算效率更高。
本文总阅读量次