Simplifying Transformer Blocks 论文解读
前言¶
标准的Transformer Block并不简介,每个block由attention, MLP, skip connection, normalization各子模块构成。一些看似微小的修改可能导致模型训练速度下降,甚至导致模型无法收敛。
在本篇工作中,我们探索了Transformer Block精简的方式。结合了信号传播理论以及一些经验性的观察,我们在不损失训练速度的前提下,移除了skip connection, out project, value project, normalization操作 以及串行组织block的形式。在Decoder-only和Encoder-only两类模型上,我们减少了15%可训练参数,并提高了15%的训练速度。
官方仓库:
bobby-he/simplified_transformers
论文: Simplifying Transformer Blocks.
一些标记注解:¶

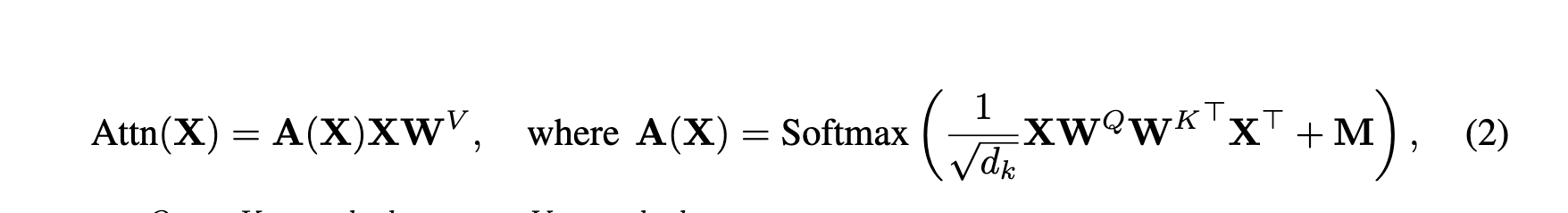
每个transformer block如上述公式组成,每个子模块都配备了一个系数,这个后续会使用到
Removing Skip Connection¶
作者先前的一项工作Deep Transformers without Shortcuts: Modifying Self-attention for Faithful Signal Propagation 删除了残差连接,提出的操作Value-SkipInit,将自注意力相关操作修改为:

其中I代表的是一个Identity操作,A(X)表示原始注意力操作。这两个操作各自有一个可训练标量 \alpha 和 \beta,初始化为 \alpha=1, \beta=0。
这个设计的insight是每个token在训练前期更多的是关注自身相关性,类似的如Pre-LN操作,在Batch Normalization Biases Residual Blocks Towards the Identity Function in Deep Networks这项工作发现,Pre-LN相当于把 skip-branch 权重提高,降低residual-branch权重,以在较深的神经网络里仍然有良好的信号传播。
而The Shaped Transformer: Attention Models in the Infinite Depth-and-Width Limit 该工作里提出了Shape Attention,也是收到信号传播理论的启发,将注意力公式更改为:
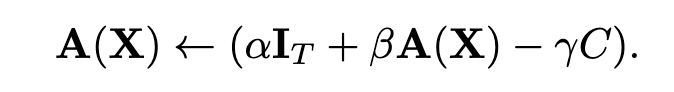
相比之下多了一个C矩阵,这是个常量矩阵(论文称其为centering matrix),不参与训练。他的值被设置为当 \frac{1}{\sqrt{d_k}}XW^QW^{K^T}X^T querykey dot 为0时候,A(x)的值,那么我们回去看A(x)公式,就剩一个mask值,因此代码里是这么写的:
# Centered attention, from https://arxiv.org/abs/2306.17759
uniform_causal_attn_mat = torch.ones(
(max_positions, max_positions), dtype=torch.float32
) / torch.arange(1, max_positions + 1).view(-1, 1)
self.register_buffer(
"uniform_causal_attn_mat",
torch.tril(
uniform_causal_attn_mat,
).view(1, 1, max_positions, max_positions),
persistent=False,
)
import torch
max_positions = 32
mask = torch.tril(torch.ones(max_positions, max_positions)) + torch.triu(torch.ones(max_positions, max_positions), 1) * -65536
print(torch.softmax(mask, -1))
tensor([[1.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5000, 0.5000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.3333, 0.3333, 0.3333, ..., 0.0000, 0.0000, 0.0000],
...,
[0.0333, 0.0333, 0.0333, ..., 0.0333, 0.0000, 0.0000],
[0.0323, 0.0323, 0.0323, ..., 0.0323, 0.0323, 0.0000],
[0.0312, 0.0312, 0.0312, ..., 0.0312, 0.0312, 0.0312]])
而新的可训练标量 \gamma = \beta,以保证初始化时,\beta A(x) - \gamma C = 0
其中这些可训练标量如果改成headwise,即每个注意力头独立,则性能有部分提升。当然作者还是强调其中的一个重要的点是,显式的将MLP Block的系数降低:

论文里针对18层Transformer,设置为0.1
Recovering Training Speed¶
在引入shape attention并移除残差连接后,训是没问题了,但是会导致收敛变慢:
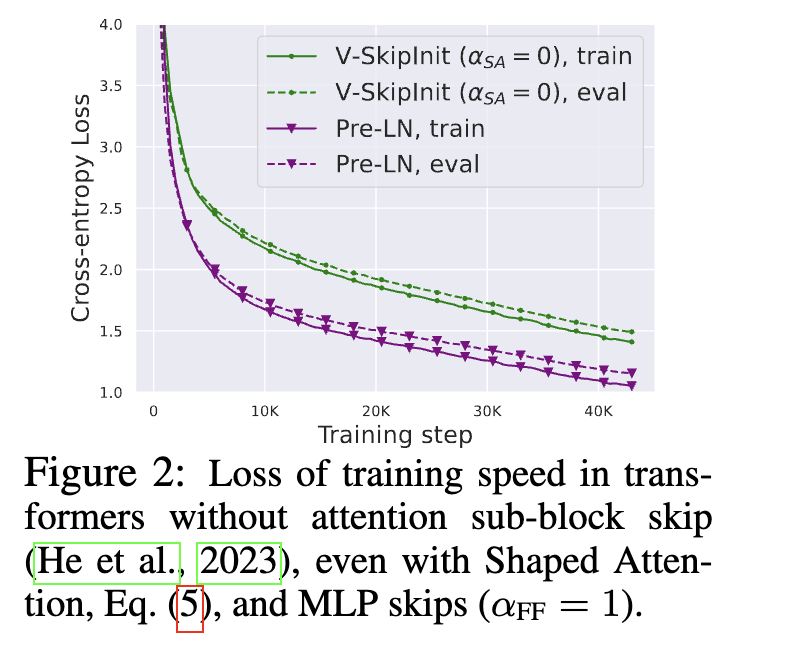
经过前面的修改,那么对于Attention模块里,在训练初期其实就简化成X和Vproject矩阵和OutProject矩阵做矩阵乘操作。
众所周知,这种没有残差连接的网络训练是要比带残差结构的网络要慢的。我们从别的工作也可以得知,Pre-LN操作,是会降低残差分支的占比系数,相当于降低了学习率,也缩减了线性层里参数更新的scale
X matmul W,那么计算X的梯度公式有一项就是W嘛
这促使我们开始引入重参数化操作思考V矩阵和OutProject矩阵

作者针对Vproject和Outproject两个矩阵乘操作,给残差分支和跳跃分支各引入一个可训练参数 \alpha, \beta,通过实验发现,大部分层最终系数比值 \frac{\beta}{\alpha}收敛到了0
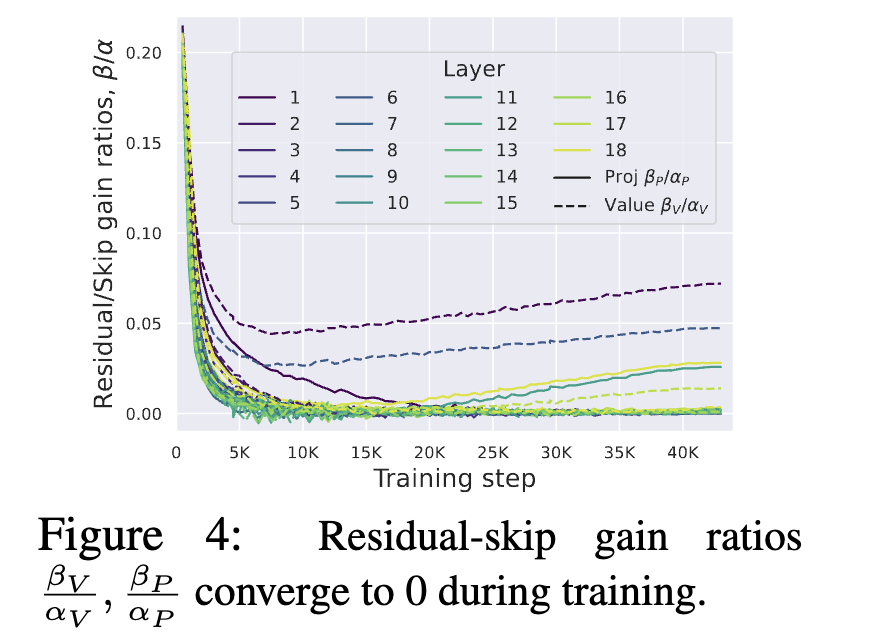
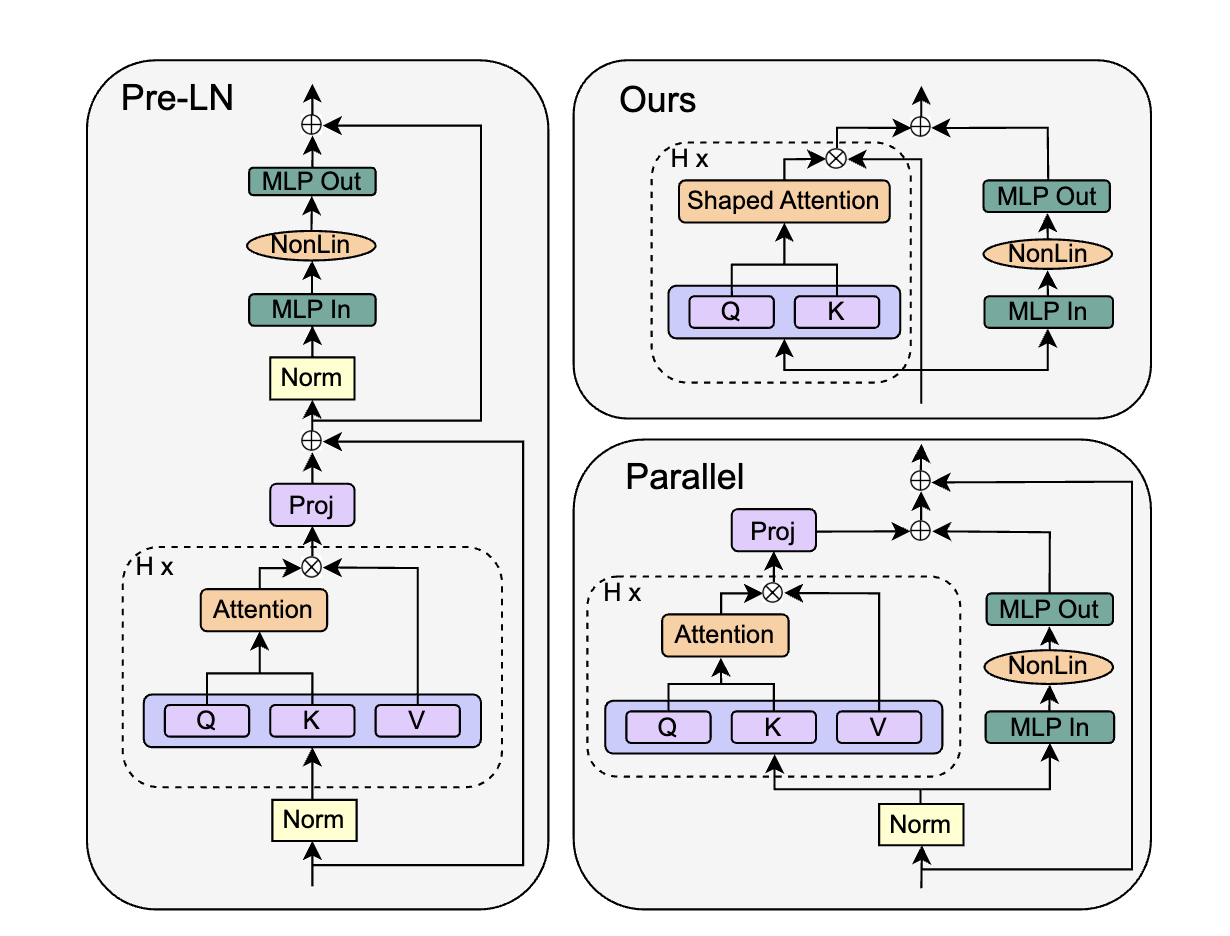
这意味着 W_V 和 W_P 两个矩阵是一个Identity矩阵,因此作者将这两个参数移除掉,并称为Simplified Attention Sub-block (SAS),使用SAS比原始Pre-LN block收敛更快了:
REMOVING THE MLP SUB-BLOCK SKIP CONNECTION¶
在这部分实验里,作者把目光投向了GPT-J里提出的Parallel Block,其移除了MLP的残差分支,保留了另外一个残差分支:
 对应公式为:
对应公式为:

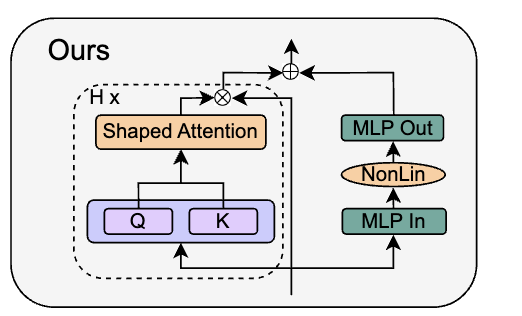
作者直接将SAS Block进行替换,得到Parallel形式的 SAS-P Block。我们比较下和原始串行的实现:

在训练初期,Attention部分是Identity输出,因此两种形式的SAS Block在训练初期是等价的。
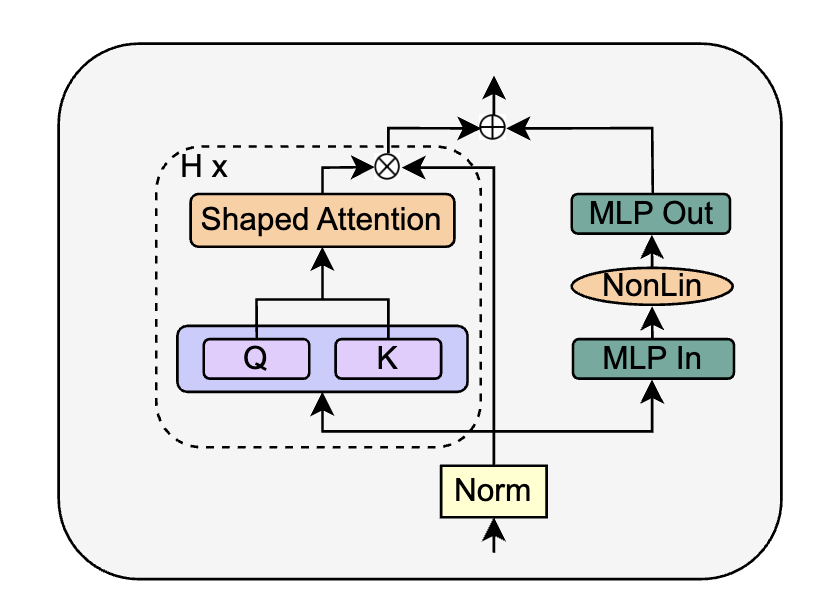
REMOVING NORMALISATION LAYERS¶
最后作者尝试将Norm层给移除,得到
作者的idea来自于,先前PreLN的作用(如把 skip-branch 权重提高,降低residual-branch权重)已经通过前面的一系列修改实现了,因此可以直接删除Norm层
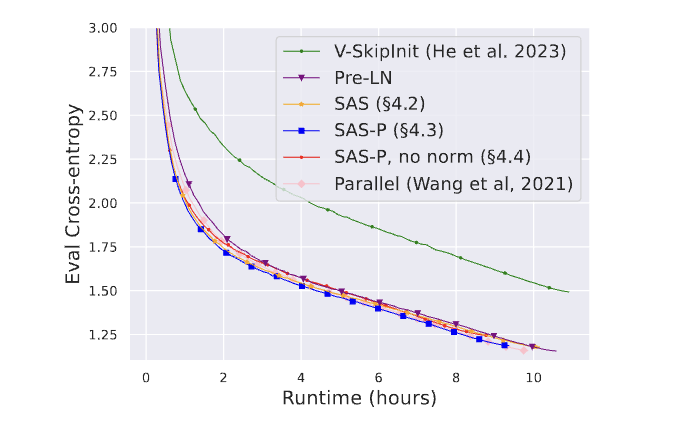 当然还是得看实验效果,回到这张图,可以看到移除了Norm对收敛还是有一定影响的。作者猜测在信号传播理论范围之外,Norm层能加速训练收敛,如Scaling Vision Transformers to 22 Billion Parameters
当然还是得看实验效果,回到这张图,可以看到移除了Norm对收敛还是有一定影响的。作者猜测在信号传播理论范围之外,Norm层能加速训练收敛,如Scaling Vision Transformers to 22 Billion Parameters
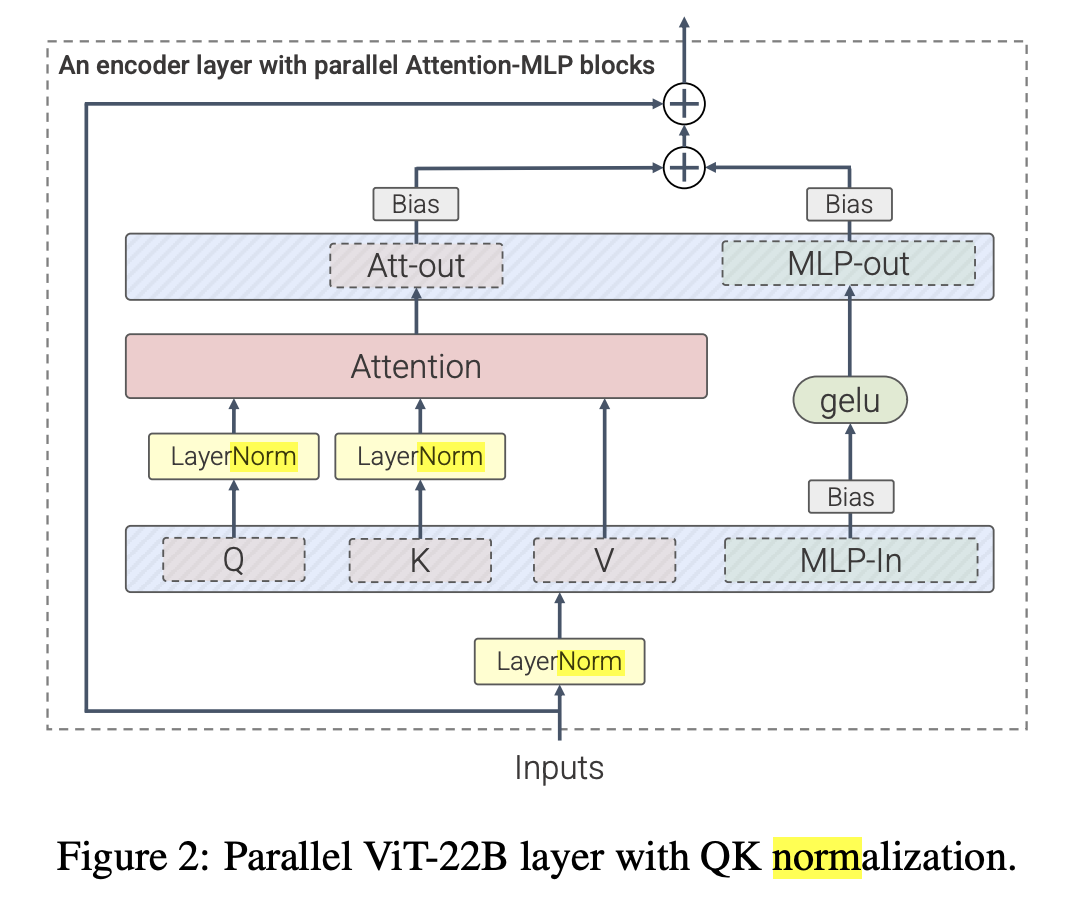 引入了更多LayerNorm层,将ViT缩放至22B参数量上
引入了更多LayerNorm层,将ViT缩放至22B参数量上
因此作者还是主张保留PreLN结构:
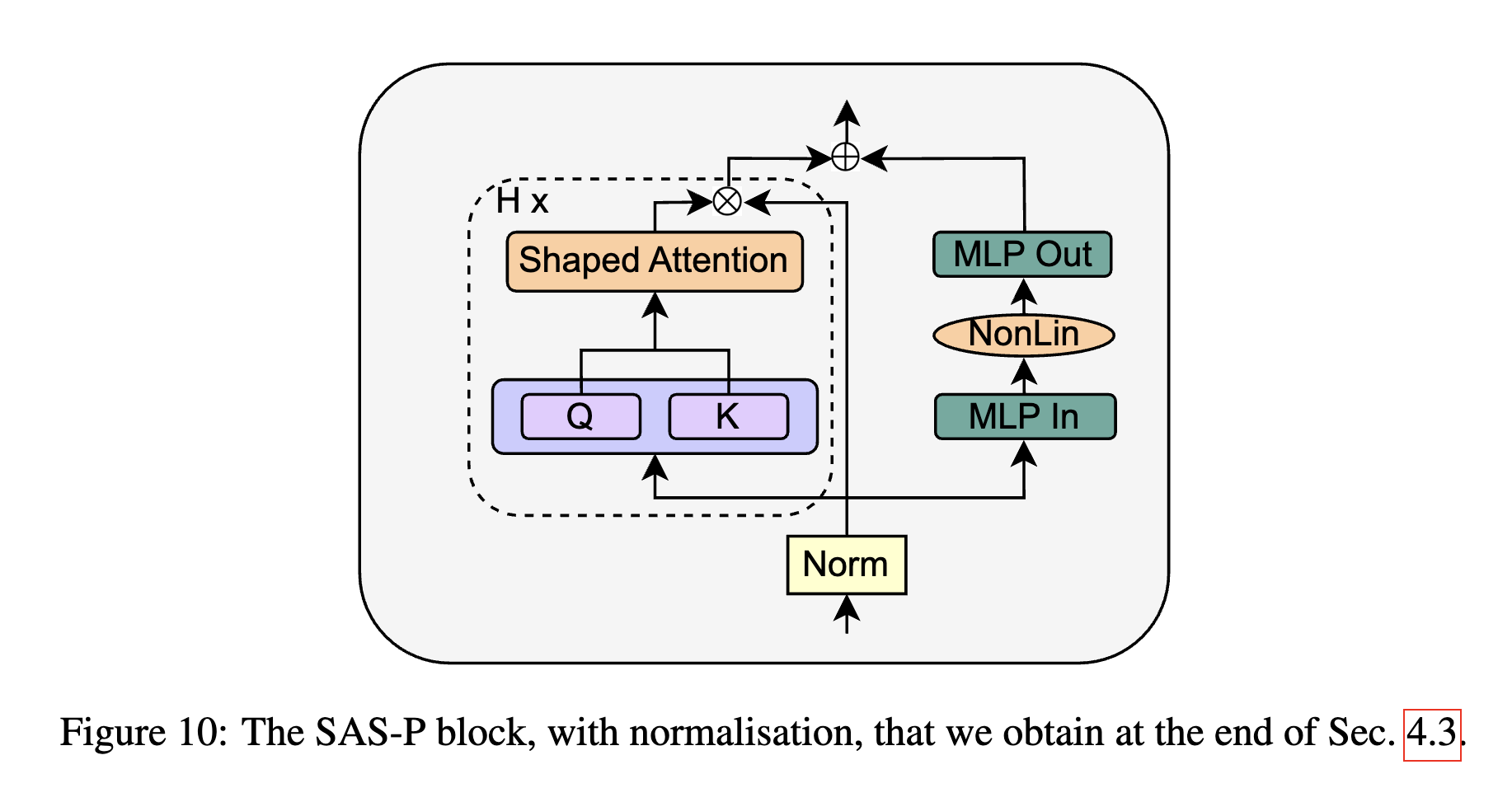
最后实验¶
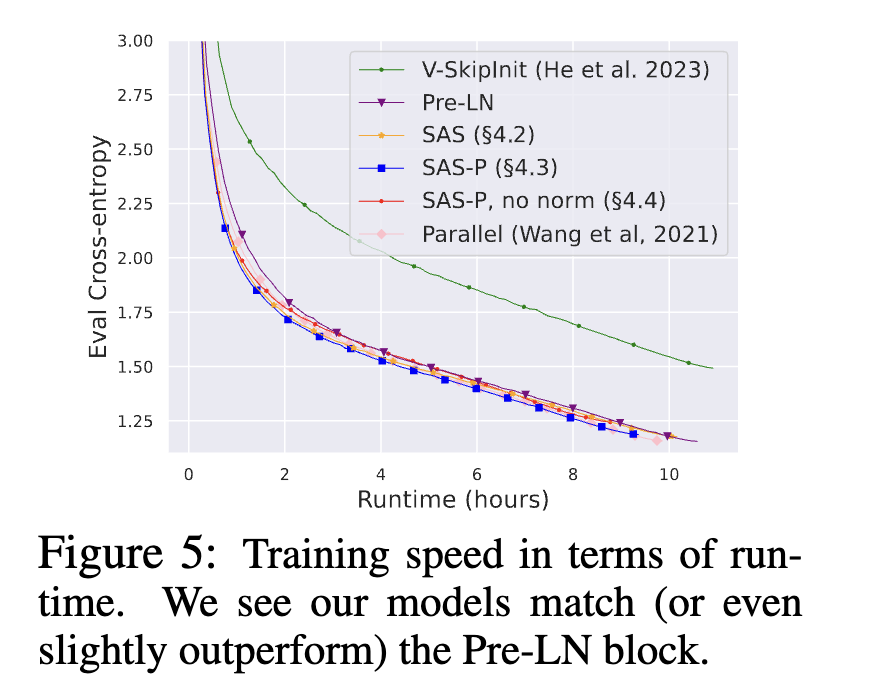
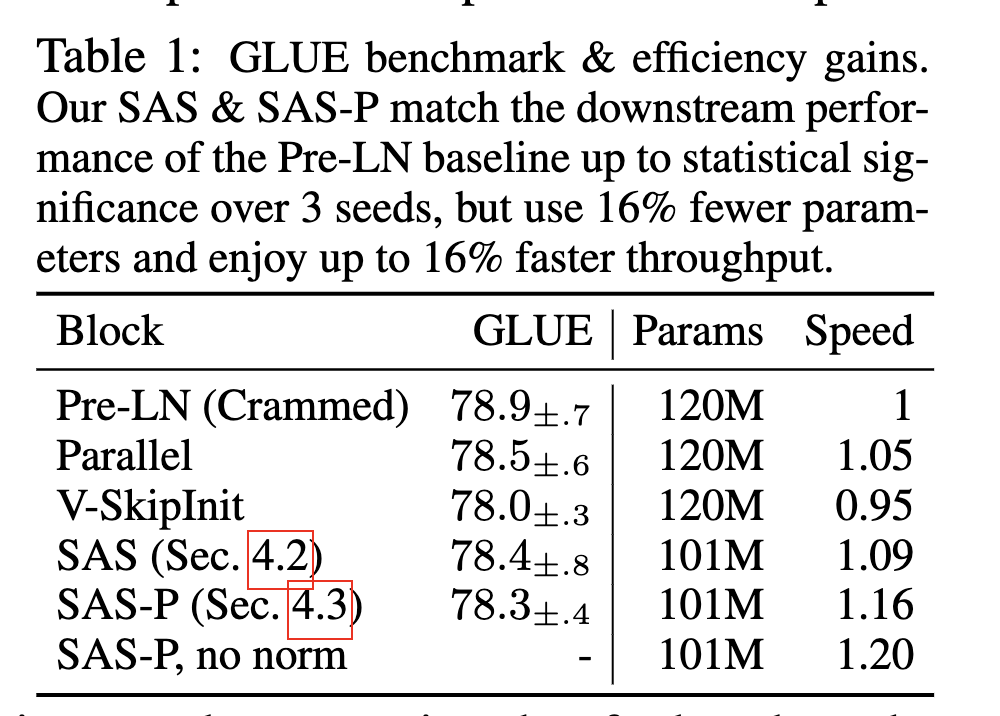
作者也补充了一些训练速度benchmark,模型准确率,以及收敛趋势的实验:

总结¶
作者对Transformer Block移除了各种参数,减少了15%参数量,提高了15%的训练速度,各个环节都有做充分的实验,但一些经验性得到的结论也并没有直接回答一些问题(如LN为什么影响收敛速度)。
实验规模并不大,而标准的TransformerBlock还是在各个Scale里得到广泛验证的,期待有人进一步试验
你说的对,但我还是套LLAMA结构
本文总阅读量次