Token Merging: Your ViT But Faster¶
1. 论文信息¶
标题:Token Merging: Your ViT But Faster
作者:Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, Judy Hoffman
原文链接:https://arxiv.org/pdf/2210.09461.pdf
代码链接:https://github.com/facebookresearch/ToMe
2. 介绍¶
自从Transformer的思想从NLP引入VISION——Vision Transformers(ViTs),计算机视觉开始快速发展。然而,与NLP不同的是,视觉信息冗余性相对较高,所以出现了很多特定的方法来试图提高计算的效率,减少不必要的注意力计算开销。添加视觉特定的感应模块使Vision Transformers能在更少的计算复杂度下获得更好的性能。然而,尽管以Swin-Transformer在速度上具有较为明显的优势,但普通而原始的的ViT仍然有许多较为优越的性质:
- 它们由简单的矩阵乘法组成,这使得它们比原始的浮点计算的速度要快;
- 它们支持强大的自我监督训练前技术,如MAE ,可以在快速训练的同时提供最先进的结果。
- 由于缺乏对数据的假设,它们可以在许多模式下不引入过多的变换情况下就可以成功应用。
- 而且它们在海量数据下也能很好地进行泛化,预训练之后的模型在下游任务中,如ImageNet-1K 图像分类和检测分割等各种经典的感知任务,具有较为卓越的表现。
但是在一些edge device上,受限于计算资源,在这上面计算 Transformer 则不太方便,因为 Transformer 模型较大,难以部署。自然而然的想法就是利用剪纸来对Vision Transformer 进行加速。但是它需要额外的训练过程,如果进行预训练那么这种计算开销就非常大。与此同时,token 剪枝限制了模型的泛化性能。如果 token 数量发生变化,批处理 (Batch Inference)就比较困难了。为了解决这个问题,大多数 token 剪枝的工作借助了 Mask,对冗余的 token 进行遮挡。但是这样又引入了额外的计算开销,这就导致了其实希望做到的模型复杂度降低没有完成。另一方面,token 剪枝也会带来一定的信息损失。
经过前面的陈述,其实本文想解决的问题就非常显而易见了:如果在保持ViT结构的时候,使得计算复杂度降低,从而增强ViT的实用性?本文希望做一个无需训练,而且可以较好完成性能和效率的trade-off的 token 的融合方法。对于大模型将会非常友好,无需重新训练是一个非常大的优势。在训练过程中使用 ToMe,可以观察到训练速度增长,而总训练时间缩短了一半。
3. 方法¶
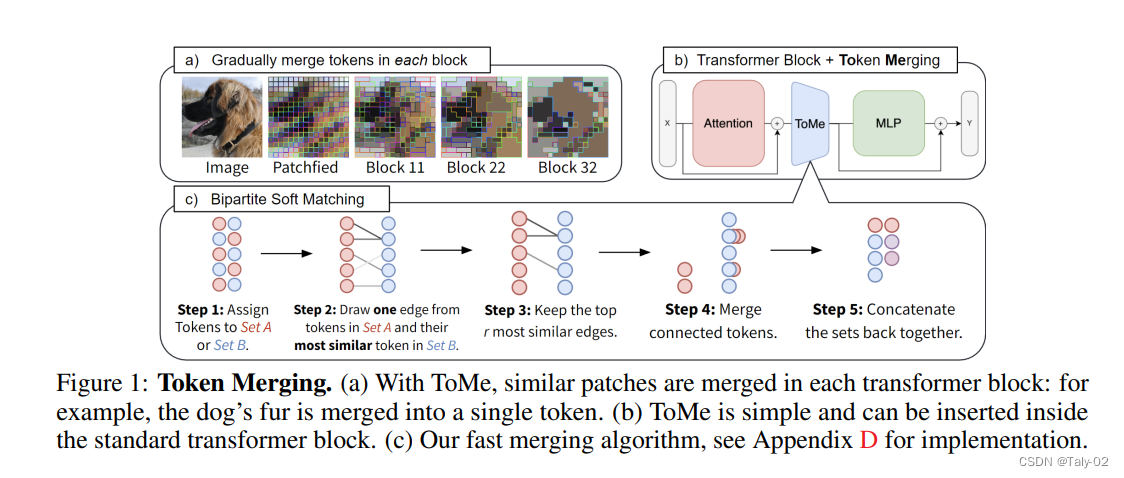
Token Merging的基本思路是在一个 ViT 模型中间插入一些减少token的模块, 通过这些模块来减少self-attention的计算量,从而减少计算的复杂度。基本作法是在每一个层之后减少m个token, 那么一个有n层的 Transformer 模型从头到尾减少的 token 数量就是m \times n。减少的 token 数量就越多,计算复杂度降低的就越多,随之而来的是更差的精度。而且值得注意的是, 无论一张输入图片有多少个 tokens,和token 剪枝算法不同,减少token的量都是固定的而不是随着token数量动态变化的。采用这种模式才能让ViT在实际部署中能完成Batch Inference,可以在真实应用场景下完成部署。
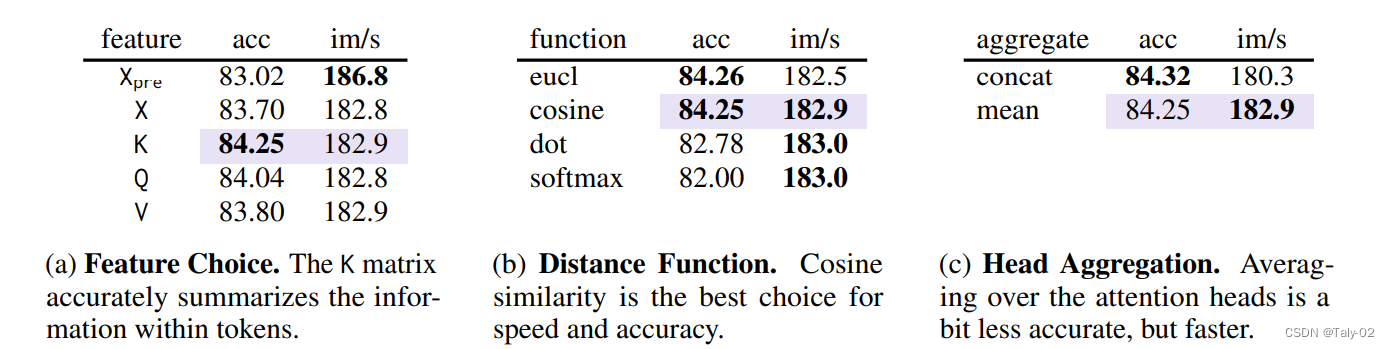
而如何完成tokens merging呢?本文定义了Token Similarity来完成这一步骤。根据之前的研究,现有的ViT实际上都overparameterized的,信息存在很强的冗余。而Transformer 本身就通过QKV的self-attention解决了这个问题。具体来说,Key已经总结了每个令牌中包含的信息,用于点积的相似度。因此,我们使用每个标记的键之间的点积相似度度量(例如,余弦相似度)来确定哪些包含相似的信息(是重合的。如上图,KQV都具有不错的表现,所以最后我们选择利用K的cosine相似度来计算distance。然后用mean来作为聚合的手段,而不是拼接在一起,可以提高效率。
之后就是完成Bipartite Soft Matching:
- 把该模块输入的所有tokens 分为相同大小的 2 个集合 。
- 把每个 token和与它最相似的 token之间画一条边。
- 只留下最相似的r条边, 其余删掉。
- 融合仍然相连的条边 ,对feature取均值。
- 把这两个集合拼在一起, 得到 ToMe 模块的融合结果。
之后对注意力权重进行调整。在 由于ToMe融合了多个token, Attention 矩阵的维度应该是增加的, 融合了 token 之后, 有的 Key 应该占的 Attention 比重大一些, 因为它融合了多个 token 的信息。
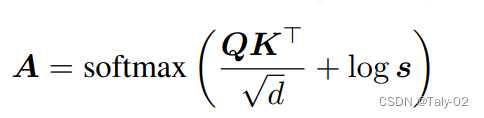
通过上式将行向量 直接加在 Attention 矩阵上面,相当于是人为增加了有些 Key 的 attention weight,而这些 key 恰好是发生了融合的 Key。
4. 实验¶
按照文章的顺序,首先来看消融实验
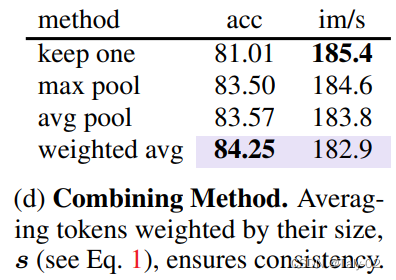
可以发现pool的方式来讲,根据token融合的数量来改变的策略上,加权平均改变attention还是具有较为明显的精度上的优势(虽然有效率上的劣势)。

可以看到MAE的预训练方式上,也有较为有趣的提升,

从这个实验结果也可以思考:为什么论文选择了匹配而不是聚类来作为减少token数量的方法。因为聚类算法没有限制每个类的具体数量,因此无法做到在每层精确地减少tokens的数量。而匹配算法不同,匹配算法可以做到精确地匹配定量的tokens,并把它们融合在一起。所以matching的方法相较于聚类(kmeans)有较为明显的优势。
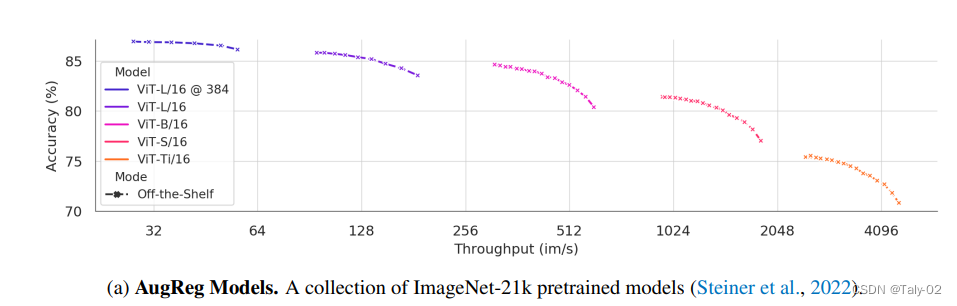
结果表明,无论模型的尺寸和类型,ToMe 都能够带来约2倍的吞吐量加速。即使减少 96-98% 的 tokens,最大下模型精度几乎保持一致。在2倍计算复杂度降低的设定下,AugReg (对比的另一种增速方法)得到的 ViT-B,ViT-S 和 ViT-Ti 都有大约 4-5% 的精度下降。由此可见ToMe的优势还是非常明显的。也可以发现ViT的冗余度有多高。
5. 结论¶
在这项工作中,我们引入了Token Merging(ToMe),通过逐步合并Token来增加ViT模型的计算焦虑。ToMe自然利用了输入视觉信息中的冗余,允许将其用于任何具有冗余的模式。ToMe在跨领域的大型模型上工作得很好,并且减少了训练时间和内存使用,这意味着它可以成为训练大型模型的核心组件。ToMe指出了一个非常有前景的方向,希望之后大家可以基于ToMe,创造出更好、更高效的Transformer。
本文总阅读量次