【MICCAI 2022】PHTrans:并行聚合全局和局部表示以进行医学图像分割
目录¶
- 前言
- 概述
- 为什么要并行
- PHTrans 架构 overview
- Trans&Conv block
- 实验
- 总结
- 参考链接
前言¶
这是 MICCAI 2022 的第二篇论文阅读笔记,贴下第一篇的地址:https://mp.weixin.qq.com/s/cSRc0a2gMq3NbQ8loqudCQ 。我们已知的是,在医学图像分割上,已经有了许多基于 CNN 和 Transformer 的优秀混合架构,并取得了很好的性能。然而,这些将模块化 Transformer 嵌入 CNN 的方法,还有可以挖掘的空间。
概述¶
在这篇论文中,提出了一种新的医学图像分割混合架构:PHTrans,它在主要构建块中并行混合 Transformer 和 CNN,分别从全局和局部特征中生成层次表示并自适应聚合它们,旨在充分利用 Transformer 和 CNN 各自的优势以获得更好的分割性能。具体来说,PHTrans 沿用 U 形设计,在深层引入并行混合模块,其中卷积块和修改后的 3D Swin Transformer 块分别学习局部特征和全局依赖关系,然后使用 sequence-to-volume 操作统一输出维度以实现特征聚合,操作的具体细节在这篇阅读笔记的后面详细介绍。最后在 BCV 和 ACDC 数据集上验证了其有效性,并用 nnUNet 包预处理 BCV 和 ACDC 数据集。
为什么要并行¶
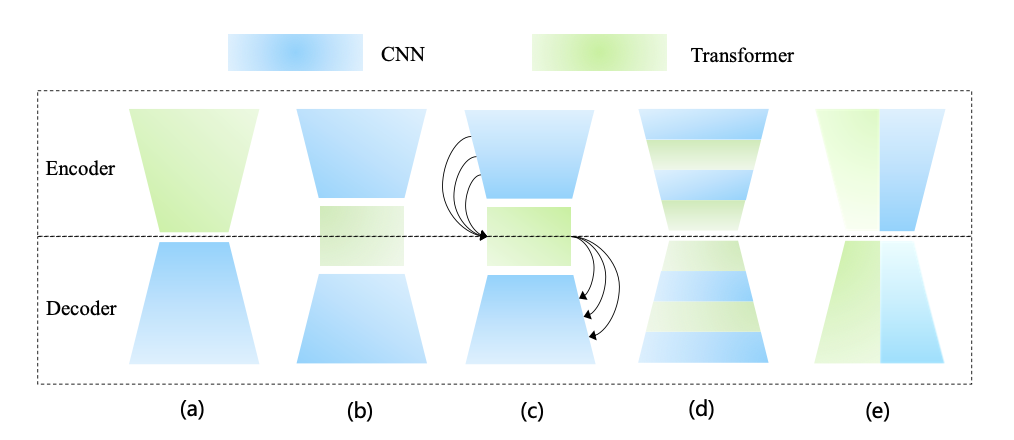
下图的 (a)~(d) 是几种流行的基于 Transformer 和 CNN 的混合架构,既将 Transformer 添加到以 CNN 为 backbone 的模型中,或替换部分组件。其中 © 与 (b) 的区别是通过 Transformer 桥接从编码器到解码器的所有阶段,而不仅仅是相邻的阶段,这就捕获了多尺度全局依赖。(d) 表示将 Transformer 和 CNN 交织成一个混合模型,其中卷积编码精确的空间信息,而自注意力机制捕获全局上下文信息。
图 (e) 表示二者的并行。在串行组合中,卷积和自注意力机制无法贯穿整个网络架构,难以连续建模局部和全局表示,因此这篇论文里认为并行可以充分发挥它们的潜力。
PHTrans 架构 overview¶
首先,我们从总体上分析一下 PHTrans 架构,然后在下一部分看它的细节。如下图 (b),其主要构建块由 CNN 和 Swin Transformer 组成,以同时聚合全局和局部表示。图 (a) 依旧遵循的 U 形架构设计,在浅层只是普通的卷积块,在深层引入了 sequence-to-volume 操作来实现 Swin Transformer 和 CNN 在一个块中的并行组合。我们上一篇解析的 UNeXT 也是只在深层使用 TokMLP 的,看来浅层的卷积还是必要的。也就是说,与串行混合架构相比,PHTrans 可以独立并行构建分层的局部和全局表示,并在每个阶段融合它们。
进一步解释下为什么输入的第一层也就是 U 型架构的浅层没有用 Trans&Conv Block?因为自注意力机制的计算复杂度高,Transformer 无法直接接收以像素为标记的输入。在论文的实现中,使用了级联卷积块和下采样操作来减小空间大小,逐步提取高分辨率的低级特征以获得精细的空间信息。 类似地,这些纯卷积模块也部署在解码器的对应层,并通过上采样恢复原始维度。
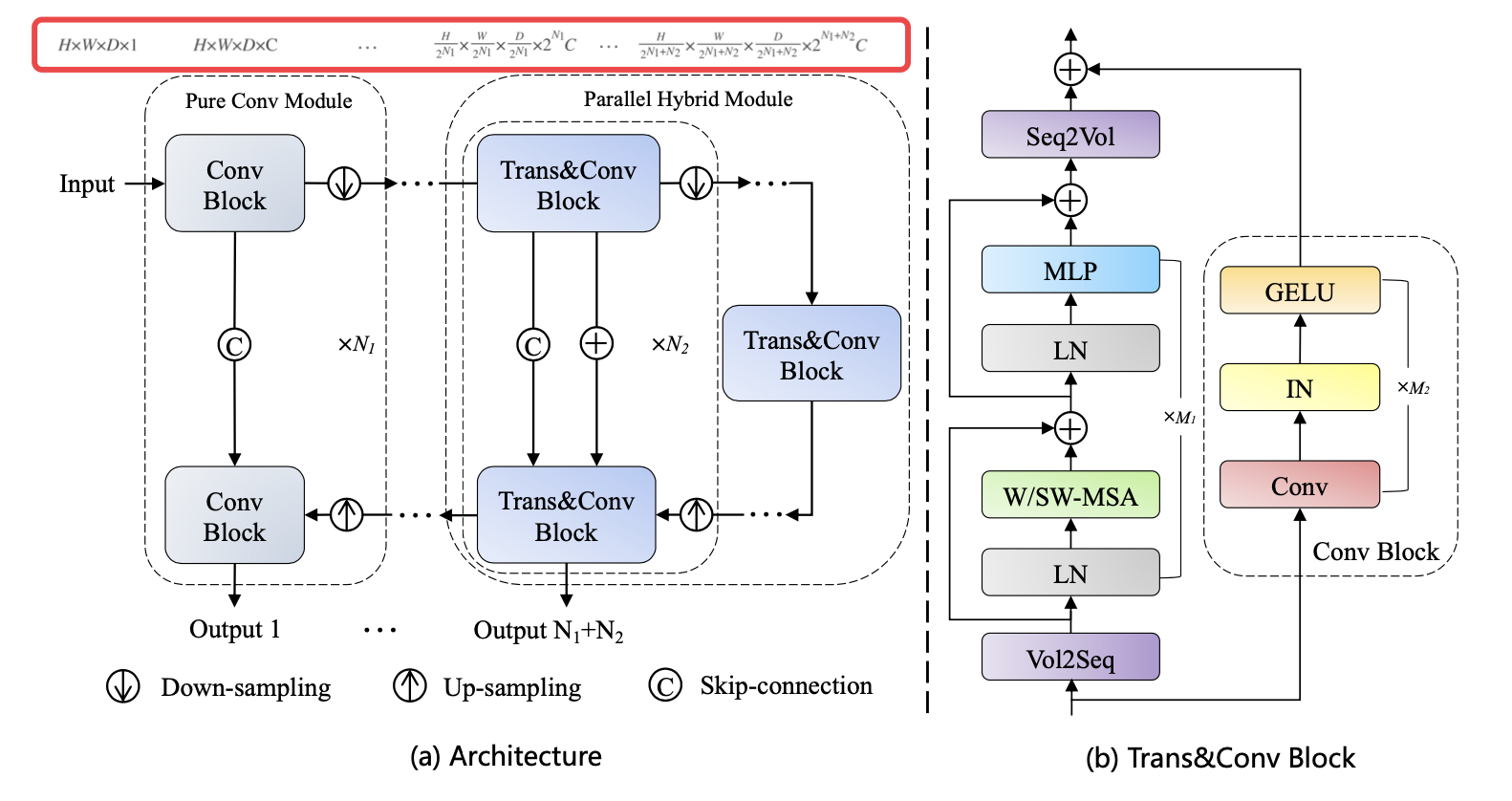
我们仔细看下 PHTrans 的编码器,对于 H×W×D 的输入 volume(3D 医学图像),其中 H、W 和 D 分别表示高度、宽度和深度,首先使用几个纯卷积模块得到 H/2N1×W/2N1×D/2N1×2N1*C 的 volume,其中 N1 和 C 表示卷积块和通道的数量。然后输入到 Trans&Conv Block 重复 N2 次。对于解码器同样基于纯卷积模块和并行混合模块构建,并通过跳跃连接和加法操作融合来自编码器的语义信息。此外,在训练期间在解码器的每个阶段都使用深度监督机制,产生总共 N1 + N2 个输出,其中应用了由交叉熵和 DICE 的联合损失。深度监督(deep supervision)又称为中继监督(intermediate supervision),其实就是网络的中间部分新添加了额外的 Loss,跟多任务是有区别的,多任务有不同的 GT 计算不同的 Loss,而深度监督的 GT 都是同一个 GT,不同位置的 Loss 按系数求和。深度监督的目的是为了浅层能够得到更加充分的训练,避免梯度消失(有待研究)。在提供的 Github 代码里,提到的超参数有 N1、N2、M1 和 M2,M1 和M2 是并行混合模块中 Swin Transformer 块和卷积块的数量。
Trans&Conv block¶
Trans&Conv block 的设计是我们最感兴趣的地方。缩小比例的特征图分别输入 Swin Transformer (ST) 块和卷积 (Conv) 块,分别在 ST 块的开头和结尾引入 Volume-to-Sequence (V2S) 和 Sequence-to-Volume (S2V) 操作来实现 volume 和 sequence 的变换,使其与 Conv 块产生的输出兼容。具体来说,V2S 用于将整个 3D 图像重塑为具有窗口大小的 3D patches 序列。 S2V 是相反的操作。如上一节的图 (b) 所示,一个 ST 块由一个基于移位窗口的多头自注意力 (MSA) 模块组成,然后是一个 2 层 MLP。在每个 MSA 模块和每个 MLP 之前应用一个 LayerNorm (LN) 层,在每个模块之后应用一个残差连接。在 M1 个连续的 ST 块中,W-MSA 和 SW-MSA 交替嵌入到 ST 块中,W-MSA能够降低计算复杂度,但是不重合的窗口之间缺乏信息交流,这样其实就失去了 Transformer 利用 Self-Attention 从全局构建关系的能力,于是用 SW-MSA 来跨窗口进行信息交流(跨窗口连接),同时保持非重叠窗口的高效计算。
对于医学图像分割,需要将标准 ST 块修改为 3D 版本,该版本在局部 3D 窗口内计算自注意力,这些窗口被安排为以非重叠方式均匀划分体积。计算方法是下面这样的:假设 x ∈ H×W×S×C 是 ST 块的输入,首先将其 reshape 为 N×L×C,其中 N 和 L = Wh × Ww × Ws 分别表示 3D 窗口的数量和维度。每个 head 中的 self-attention 计算如下:
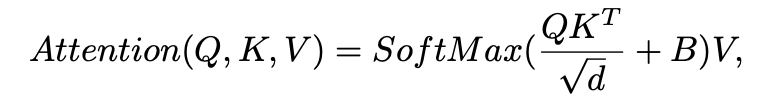
Q, K, V ∈ L×d 是查询、键和值矩阵,d 是查询/键维度,B ∈ L×L 是相对位置偏差。B 的取值在论文和代码里都可以找到,这里我们就不仔细探究了。(b) 中的卷积块以 3 × 3 × 3 卷积层、GELU 非线性和实例归一化层为单位重复 M2 次。最后,通过加法运算融合 ST 块和 Conv 块的输出。 编码器中 Trans&Conv 块的计算过程(抽象成并行)可以总结如下:
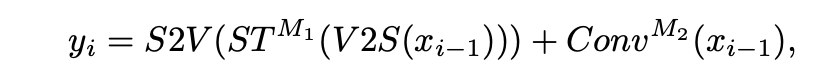
xi−1 是编码器第 i−1 阶段的下采样结果。值得注意的是,在解码器中,除了跳跃连接之外,还通过加法操作来补充来自编码器的上下文信息(图 (a) 中的圈 C 和 圈 +)。因此,解码器中的 Trans&Conv 块计算(抽象成并行)可以表示为:
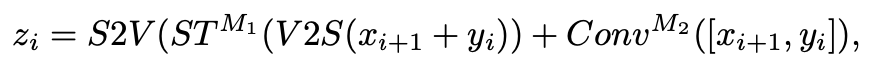
实验¶
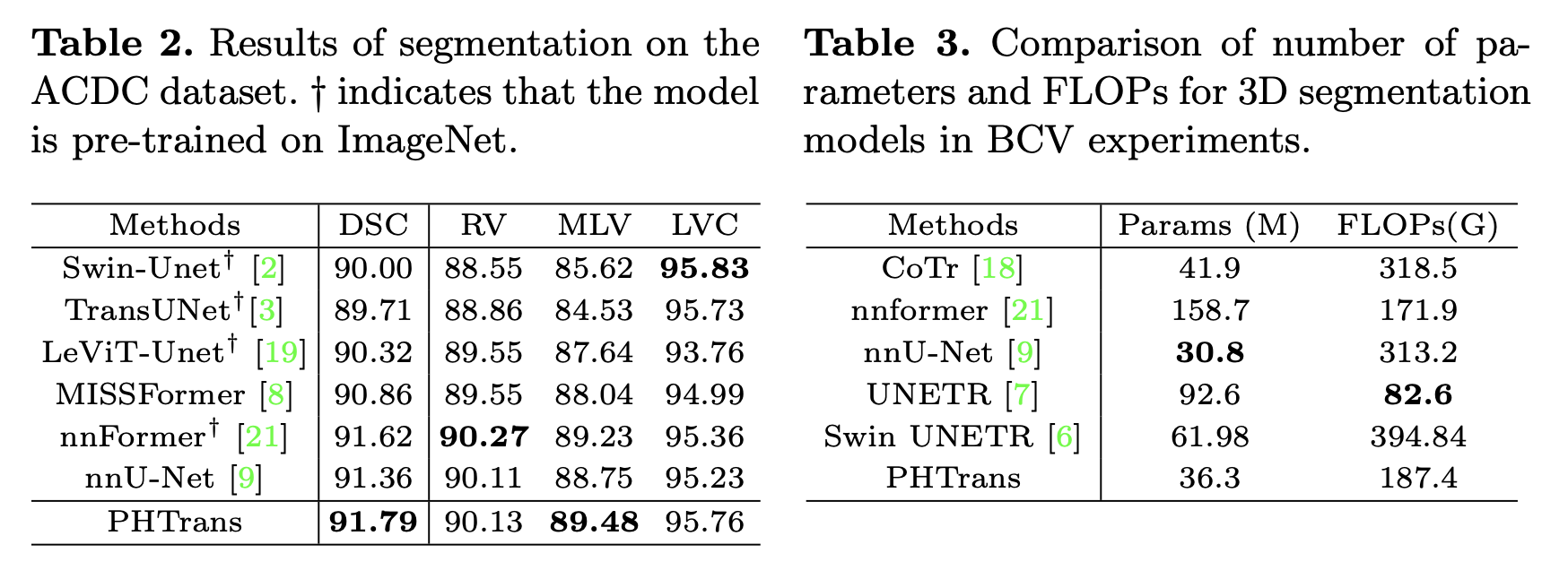
实验在 BCV 和 ACDC 数据集上,BCV 分割腹部 CT 多个目标,ACDC 是 MRI 心脏分割,标记了左心室 (LV)、右心室 (RV) 和心肌 (MYO)。在 BCV 上和其他 SOTA 方法的比较如下表:

在 ACDC 上和其他 SOTA 方法的比较如 Table 2 所示,Table 3 中的参数量和 FLOPS 和其他方法比也没有很夸张,参数量甚至和 nnU-Net 相近。
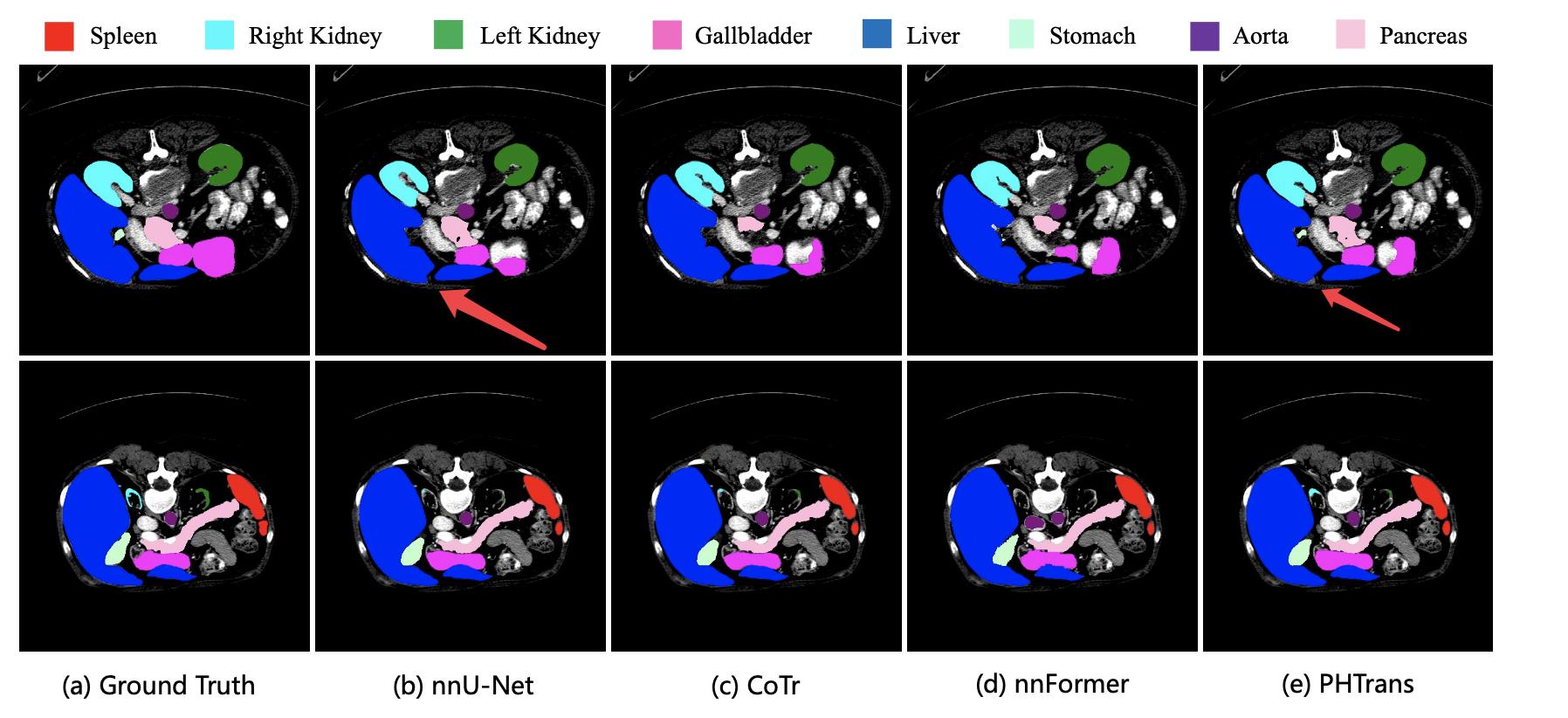
可视化分割结果如下图,我们只定位蓝色肝脏的分割效果,箭头位置表明分割的效果 PHTrans 是更优秀的。
总结¶
PHTrans 也许为更多下游医学图像任务开发了新的可能性。在 PHTrans 中,都是普通的 Swin Transformer 和简单的 CNN 块,这表明性能提升源于并行混合架构设计,而不是 Transformer 和 CNN 块。此外,PHTrans 没有经过预训练,因为到目前为止还没有足够大的通用 3D 医学图像数据集。
参考链接¶
本文总阅读量次