论文原文¶
https://arxiv.org/pdf/1411.4038.pdf
创新点¶
提出了一种端到端的做语义分割的方法,
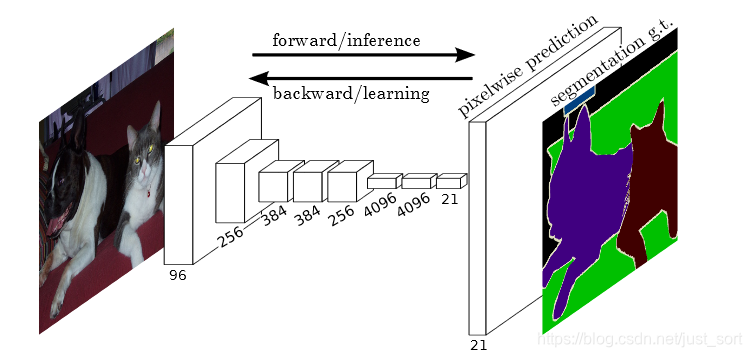
如图,直接拿分割的ground truth作为监督信息,训练一个端到端的网络,让网络做p像素级别的预测。
如何设计网络结构¶
如何做像素级别的预测¶
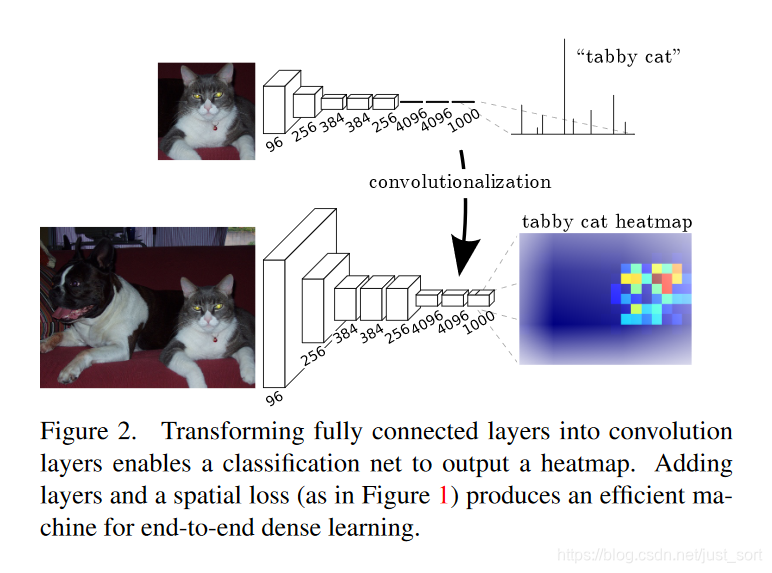
在VGG16中的第一个全连接层的维度是25088x4096的,将之解释为512x7x7x4096的卷积核,这样最后就会得到一个featuremap。这样做的好处在于可以实现迁移学习的fine-tune。最后我们对得到的feature map进行bilinear上采样,就是反卷积层。就可以得到和原图一样大小的语义分割后的图了。
如何保证精度¶
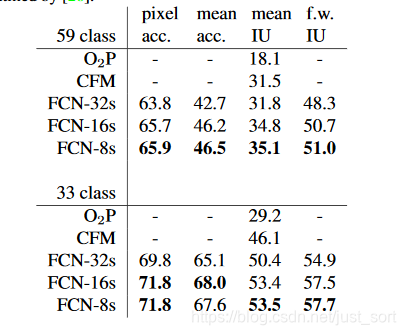
我们在做upsampling时,步长是32,输入为3x500x500的时候,输出是544x544,边缘很不好。所以我们采用skip layer的方法,在浅层处减小upsampling的步长,得到的fine layer 和 高层得到的coarse layer做融合,然后再upsampling得到输出。这种做法兼顾local和global信息,即文中说的combining what and where,取得了不错的效果提升。FCN-32s为59.4,FCN-16s提升到了62.4,FCN-8s提升到62.7。可以看出效果还是很明显的。
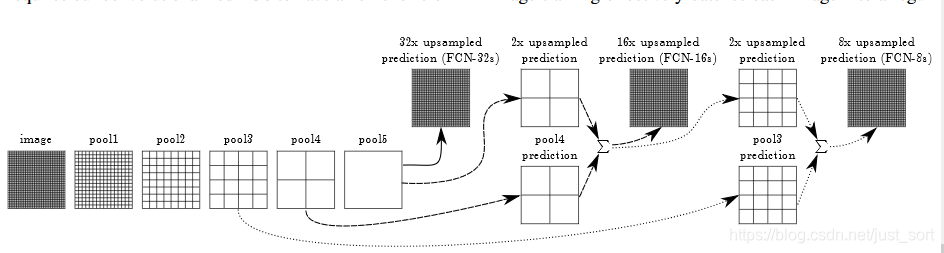
论文结果¶

代码实现¶
FCN8
#coding=utf-8
from keras.models import *
from keras.layers import *
import os
def crop(o1, o2, i):
o_shape2 = Model(i, o2).output_shape
outputHeight2 = o_shape2[1]
outputWidth2 = o_shape2[2]
o_shape1 = Model(i, o1).output_shape
outputHeight1 = o_shape1[1]
outputWidth1 = o_shape1[2]
cx = abs(outputWidth1 - outputWidth2)
cy = abs(outputHeight2 - outputHeight1)
if outputWidth1 > outputWidth2:
o1 = Cropping2D(cropping=((0,0), (0, cx)))(o1)
else:
o2 = Cropping2D( cropping=((0,0) , ( 0 , cx )))(o2)
if outputHeight1 > outputHeight2 :
o1 = Cropping2D( cropping=((0,cy) , ( 0 , 0 )))(o1)
else:
o2 = Cropping2D( cropping=((0, cy ) , ( 0 , 0 )))(o2)
return o1, o2
def FCN8(nClasses, input_height=416, input_width=608, vgg_level=3):
img_input = Input(shape=(input_height, input_width, 3))
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
f1 = x
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
f2 = x
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
f3 = x
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
f4 = x
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
f5 = x
x = Flatten(name='flatten')(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
#x = Dense(1000, activation='softmax', name='predictions')(x)
#vgg = Model(img_input, x)
#vgg.load_weights(VGG_Weights_path)
o = f5
o = (Conv2D(4096, (7, 7), activation='relu', padding='same'))(o)
o = Dropout(0.5)(o)
o = (Conv2D(4096, (1, 1), activation='relu', padding='same'))(o)
o = Dropout(0.5)(o)
o = (Conv2D(nClasses, (1, 1), kernel_initializer='he_normal'))(o)
o = Conv2DTranspose(nClasses, kernel_size=(4, 4), strides=(2, 2), use_bias=False)(o)
o2 = f4
o2 = (Conv2D(nClasses, (1, 1), kernel_initializer='he_normal'))(o2)
o, o2 = crop(o, o2, img_input)
o = Add()([o, o2])
o = Conv2DTranspose(nClasses, kernel_size=(4, 4), strides=(2, 2), use_bias=False)(o)
o2 = f3
o2 = (Conv2D(nClasses, (1, 1), kernel_initializer='he_normal'))(o2)
o2, o = crop(o2, o, img_input)
o = Add()([o2, o])
o = Conv2DTranspose(nClasses , kernel_size=(16,16), strides=(8,8), use_bias=False)(o)
o_shape = Model(img_input, o).output_shape
outputHeight = o_shape[1]
outputWidth = o_shape[2]
o = (Reshape((-1, outputHeight*outputWidth)))(o)
o = (Permute((2, 1)))(o)
o = (Activation('softmax'))(o)
model = Model(img_input, o)
model.outputWidth = outputWidth
model.outputHeight = outputHeight
return model
FCN32
#coding=utf-8
from keras.models import *
from keras.layers import *
import os
def FCN32(n_classes, input_height=416, input_width=608, vgg_level=3):
img_input = Input(shape=(3, input_height, input_width))
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(img_input)
x = Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
f1 = x
# Block 2
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
f2 = x
# Block 3
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
f3 = x
# Block 4
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
f4 = x
# Block 5
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
x = MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
f5 = x
x = Flatten(name='flatten')(x)
x = Dense(4096, activation='relu', name='fc1')(x)
x = Dense(4096, activation='relu', name='fc2')(x)
x = Dense(1000, activation='softmax', name='predictions')(x)
#vgg = Model(img_input, x)
#vgg.load_weights(VGG_Weights_path)
o = f5
o = (Conv2D(4096, (7, 7), activation='relu', padding='same'))(o)
o = Dropout(0.5)(o)
o = (Conv2D(4096, (1, 1), activation='relu', padding='same'))(o)
o = Dropout(0.5)(o)
o = (Conv2D(n_classes, (1, 1), kernel_initializer='he_normal'))(o)
o = Conv2DTranspose(n_classes, kernel_size=(64, 64), strides=(32, 32), use_bias=False)(o)
o_shape = Model(img_input, o).output_shape
outputHeight = o_shape[1]
outputWidth = o_shape[2]
o = (Reshape((-1, outputHeight*outputWidth)))(o)
o = (Permute((2, 1)))(o)
o = (Activation('softmax'))(o)
model = Model(img_input, o )
model.outputWidth = outputWidth
model.outputHeight = outputHeight
return model
如何训练语义分割模型请看我的github工程: https://github.com/BBuf/Keras-Semantic-Segmentation
本文总阅读量次