论文原文¶
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7803544
摘要¶
\quad本文提出了一种用于像素级语义分割的深度全卷积神经网络结构SegNet。该网络包含一个编码网络和一个解码网络。其中编码网络使用了VGG16中的13层卷积。解码器的作用主要是将低分辨率的特征图还原到完整的输入分辨率上,从而用于像素级的分类任务。
\quadSegNet的创新点在于解码器对低特征图的上采样处理方式。具体来讲,解码器利用在max-pooling过程中计算出的池化indices,计算对应的编码器的非线性上采样。这个过程就省去了上采样学习的过程。上采样后的特征图是稀疏的,再用可学习的卷积层来计算稠密的特征图。
\quad我们比较了本文的结构与FCN,DeepLab-LargeFOV和DeconvNet结构。由于SegNet的设计思路源于场景理解,因此在内存和计算时间上效率很高,可学习参数量也比其他结构小,可以用SGD端到端进行训练。在道路和SUN RGB-D室内场景下进行了排名。
网络结构¶
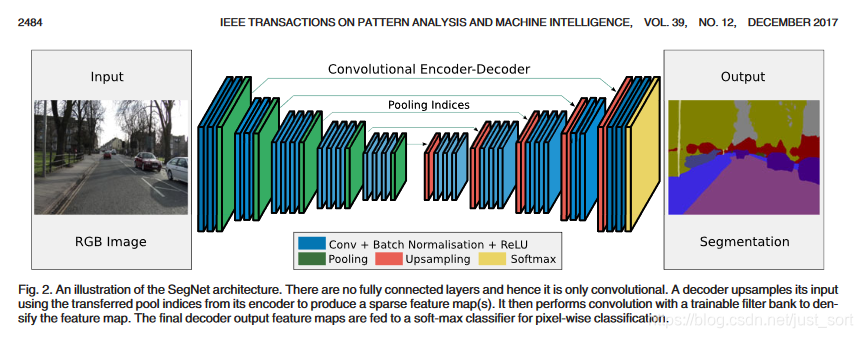
这是SegNet的网络结构,其中编码器含有13个卷积层,分别对应了VGG16的前13个卷积层,因此就可以用在ImageNet下训练得权重初始化网络。此外,作者丢弃了全连接层,从而保留了最深编码输出处的高分辨率特征图,同时与其他网络结构相比(如FCN和DeconvNet,具体见下表),大幅减少了SegNet编码部分的参数量(从134到14.7M)。
\quad编码器中的每一层都对应了解码器中的一层,因此解码器也有13层。解码器的输出随后传递给一个softmax分类器,生成每个像素点在个类别下的独立概率。
\quad编码器网络中的每一个encoder都用一组filter进行卷积计算,随后接一个bn层,再接一个relu激活函数。之后用一个窗口尺寸为2,步长为2的Max-Pooling,得到一个下采样结果。用Max pooling的原因是实现输入图像上小空间位移的平移不变性。下采样使得特征图中的每个像素点都对应了大输入图像内容。
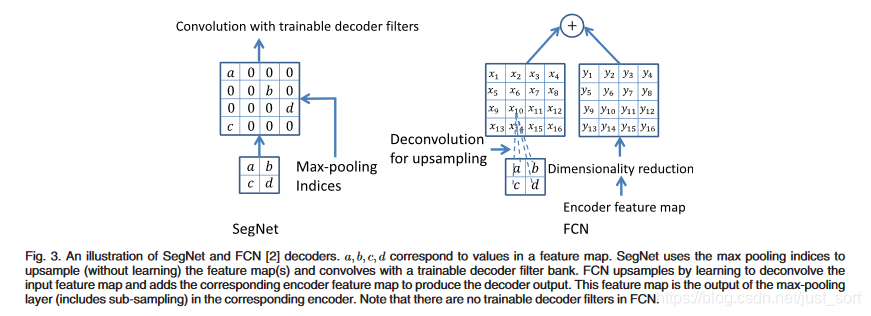
\quad尽管Max Pooling能够实现分类任务下更多的平移不变性,但这些操作也降低了特征图的空间分辨率。而这些逐渐损失的图像描述(例如边界信息)对于分割任务是非常重要的。因此,需要在下采样进行之前记录和保存这些边界信息。在不考虑内存的情况下,编码器中的每一层特征层都应该记录下来。但是这种方式在实际应用中是不现实的,因此本文提出了另外一种存储方式。这种方式只保存max-pooling indices,也就是每一个窗口内的最大特征值的位置。在实际应用中,这个信息可以用一个2位的二进制数来记录一个2*2的窗口,因此相比较记录整个特征图而言也就更加实用。后面会证明,这种方式损失了一定的精度,但是对于实际应用还是够用了。解码器用之前记录的max-pooling indices上采样输入的特征图。这个过程生成的特征图是稀疏的。解码技巧如下图所示:
\quad解码器的每个反卷积层后面也跟了bn层。与编码器第一层(最靠近输入图像的层)对应的解码器层有多通道(而非完全对应的三通道),除此之外的其他层与编码器具有相同的尺寸和通道数。解码器的输出送给一个可学习的soft-max classfier,该分类器对每一个像素都单独分类。分类器的输出有k个通道,每个通道上存储的都是该类别下的概率。最终的分割结果对应的是概率最大的类别。
\quadDeconvNet和U-Net与SegNet结构相似,但是也有不同。主要用于使用了全连接层(尽管是以卷积的形式使用),DeconvNet参数量非常大而且很难端到端训练(如前面Table6显示的)。而U-Net(为医学场景提出的)以消耗内存的方式,直接将整个特征图级联在后面,而没有使用pooling indices。而且U-Net没有conv5和max-pool five block,而SegNet用了完整的VGG结构和预训练的参数。
解码器变体¶
\quad许多分类结构的编码器都是相同的,不同之处在于使用了不同的解码器。为了与FCN比较(解码器部分),这里用了一个编解码器都只有4层的SegNet。解码器中在卷积后没有bias,也没有应用ReLU。整个编解码过程使用固定的7*7窗口,也就是说第4层特征图的一个像素对应了原图的106x106个像素。
\quad前面的Fig.3中左侧是SegNet中使用的技巧,不需要学习,但是得到稀疏特征图后需要卷积得到稠密的特征图。不同的是这个卷积过程只针对一个通道,也就是说每个卷积只处理自己对应的那层卷积,这也是MobileNet中的深度可分离卷积。Fig.3右侧是FCN解码技巧。FCN将整个特征图记录下来,这样是很消耗内存的。比如存储第一层的64个特征图,图像分辨率为180x240,以32bit浮点精度存储,需要11MB。
\quad除了上面的几种变体,我们还研究使用的固定的双线性插值权重做上采样,这样就没有权重学习的过程了。在另外一个极端下,可以把64层特征层都加到解码器上。内存消耗再大一些,可以没有尺度减小,也就是说解码器的最后一层也是跟第一层一样的通道数比如64,而不是类别个数K。
\quad我们还有一些其他变体,比如用replication上采样,或用固定的(稀疏的)indices array上采样。但是这些方法的表现相比较前面几种都不太好。没有max-pooling和sub-sampling的变体消耗的内存更大、收敛所需时间更长,且表现不好。
训练和结果分析¶
这部分我就不写了,可以参考论文原文。
SegNet的Keras实现¶
我的github链接: https://github.com/BBuf/Keras-Semantic-Segmentation
本文总阅读量次