CVPR 2022: GroupViT: Semantic Segmentation Emerges from Text Supervision¶
1. 论文信息¶
标题:GroupViT: Semantic Segmentation Emerges from Text Supervision
作者:Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang
代码链接:https://github.com/NVlabs/GroupViT
2. 介绍¶
CLIP是近年来在多模态方面的经典之作,得益于大量的数据和算力对模型进行预训练,模型的Zero-shot性能非常可观,甚至可以在众多数据集上和有监督训练媲美。简单来说,CLIP的high-level的idea非常直接,就是通过对比学习,对图像特征空间和文本特征空间进行对齐,给定任意图像和文本都可以映射到这个空间中,然后这些图像和文本就可以直接计算相似度。通过这种方式,CLIP填平了文本和视觉信息的gap。
CLIP是基于分类任务完成的,那么相应的,我们就不免思考其在检测和分割领域能否也发挥比较好的效果。如何不依赖于手工标注的分割标注,如何能真真的做到去用文本来作为监督信号来指导模型训练,就是非常值得思考的一个问题。下面我们就来介绍一个基于CLIP的zero-shot实例分割方法。
对于传统做分割的模型的一种方法就是通过像素相似度进行语义分割。
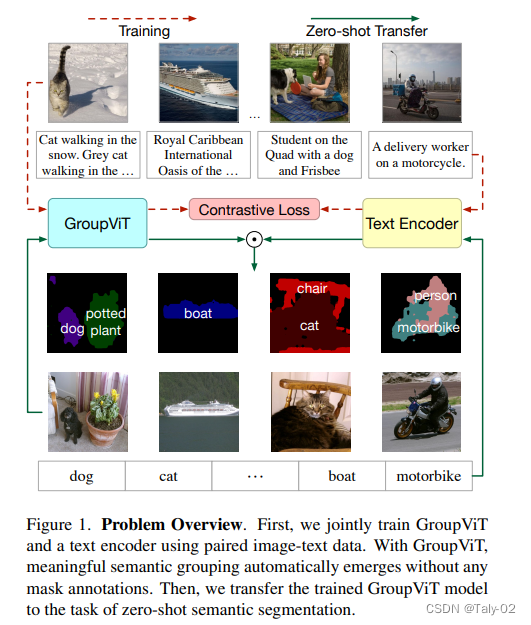
首先在图上找一些中心点,然后通过像素相似然后将附近像素给到不同的目标区域,最终获得segmentation mask区域。如上图所示,为了实现摆脱手工标注这一目标,论文提出将分割中经典的group机制引入到深度网络中,通过这种机制,语义的信息段可以在只需要文本监督的情景下自动出现。
通过对具有对比损失的大规模成对vision-language数据进行训练,我们可以将模型zero-shot转移到多个语义分割到word table中,而不需要进一步的注释或微调。
总结论文的贡献如下:
- 在深度网络中,我们超越了规则形状的图像网格,引入了一种新的Group ViT体系结构,将视觉概念分层自下而上地分组为不规则形状的组。
- 在不依赖任何像素级的标注情况下,只采用图像级文本监督,成功地学会了将图像区域分组,并以zero-shot的模式迁移到多个语义分割词汇表。
- 本文是第一份在不使用任何像素标签的情况下探索从文本监督到多个语义分割任务的零镜头转移的工作,并为这一新任务建立了坚实的基线。
3. 方法¶
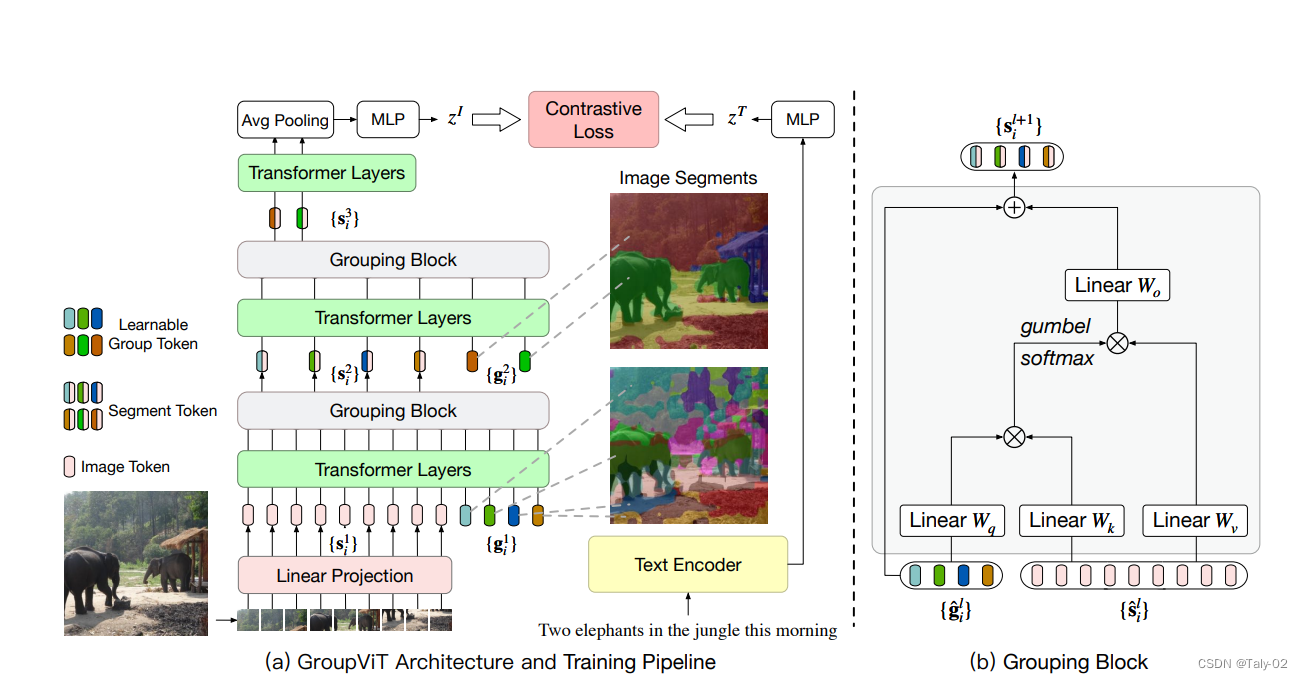
如上图所示,本文提出的结构在ViT基础上进行设计,是一个dual-encoder的结构。训练过程主要分为三部:
第一步:把原始的image作为输入,利用ViT结构的encoder进行图像编码。将图像分成若干个patch之后,将每个patch作为path embedding的向量信息,构建出 s_i 部分的数据矩阵,然后利用线性层映射出一个embedding的数据。然后将图像中的不同patch得到的embedding进行分类,构建出64*384大小的group token矩阵块。
这里有两种实现的方式,第一种,对于2-stage类型的GroupViT,
- 在GroupViT的第一阶段,经过Transformer layers操作后可以得到64个group tokens,然后在6层Transformer层后插入grouping block。
- 在GroupViT的第二阶段,grouping之后,都会得到8个segment tokens。对于1-stage类型的GroupViT,就非常简单直接了,在grouping block之前,将64个group tokens通过MLP-Mixer layer映射成8个segment tokens。然后Grouping Block将学到的group tokens 和image segment tokens作为输入,通过Grouping Block更新image tokens,利用这些tokens将相似的images归并到一起。每经过一个grouping stage,能够得到更大更少的image segments。
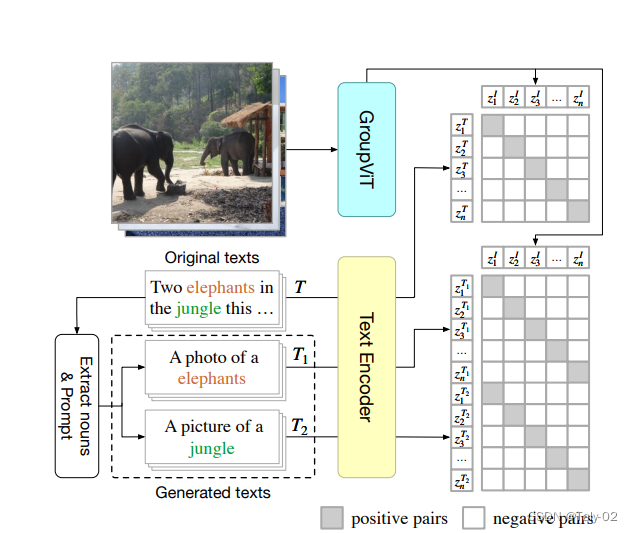
第二步:基于上一步输出的8\times384的group token后把文本数据和得到的数据联合进行训练。为了和Text信息进行关联,能够机选Clip的内积,需要把8维映射为1维,为了方便简单,论文直接用avg pooling处理;
论文的训练loss有两项,包括image-text loss和multi-label contrastive loss with text prompting。
image-text loss包括image to text和text to image两项:
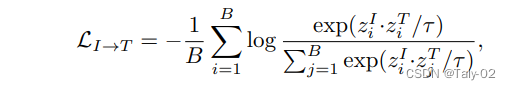
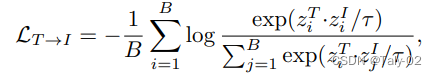
multi-label contrastive loss with text prompting涉及到较为复杂的操作,可以参考原文进一步了解:

第三步:通过设计好的GroupViT结构,模型能够自动将image分组成一个个的segment,所以可以很容易的zero-shot transfer到语义分割任务上,而不需要微调。由于GroupViT自动将图像分组为语义相似的片段,它的输出可以很容易地转移到语义分割,而无需进一步的微调。如图4所示。为了推断图像的片段属于对象类的有限词汇table,论文通过Group VIT来传递一个测试图像,而不对其最终的L输出段应用AvgPool,并得到每个片段的嵌入为。每个段标记对应于输入图像的任意形状的区域。然后,我们计算每个段标记的嵌入与数据集中所有语义类的文本嵌入之间的相似性。我们将每个图像片段分配给图像文本embedding相似度最高的语义类定为最终分割结果。
4. 实验结果¶
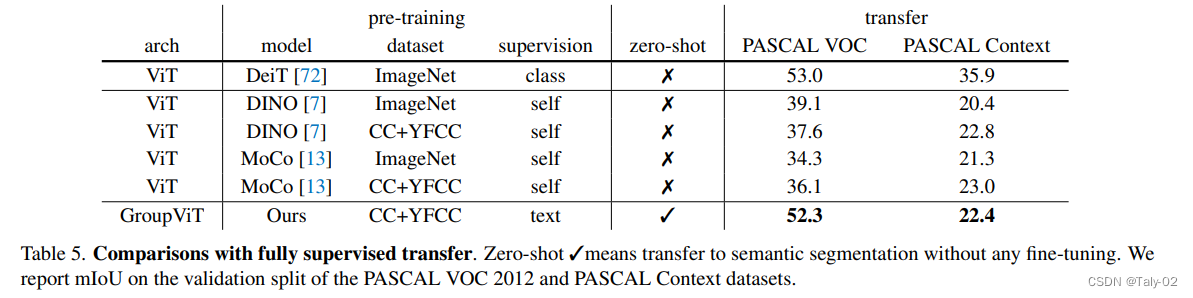
在无监督的情况下,自然是相较于其他的对比学习方式有了比较明显的提升,但显然和有监督的setting表现还是有一定的gap的(如VOC可以达到80%+),由此可见,无监督的语义分割还是有一定进步的空间的。

为了将CLIP zero-shot转换为语义分割,在推理过程中首先对其输出特征进行non-parametric的分组。然后计算每组的特征均值与数据集分割标签的文本embeddings之间的相似度。这样,任何结合CLIP的ViT非参数分组方法都可以被认为是一个零镜头的语义分割基线。如表4所示,分组ViT的性能大大优于其他分组方法。这表明,与使用CLIP训练的ViT相比,我们的GroupViT在zero-shot转换到语义分割方面更有效。
5. 结论¶
本文迈出了学习零样本语义分割的第一步,也是重要一步,在只有文本,没有任何明确的人类标注的监督下进行自监督。我们证明,使用GroupViT,从大规模噪声图像-文本对中学习到的表示可以以零镜头的方式转移到语义分割。这项工作也证明了除了图像分类之外,文本监督也可以转移到更细粒度的视觉任务中,这是以前没有探索过的,开辟了一个非常有趣的研究方向。
本文总阅读量次