MICCAI 2022:使用自适应条形采样和双分支 Transformer 的 DA-Net
文章目录¶
- 前言
- 概述
- 网络简介
- DBTM:Local Patches Meet Global Context
- ASUB block
- 实验
- 讨论
- 参考链接
前言¶
这是 MICCAI 2022 上的第三篇阅读笔记了,之前两篇也都可以在 GiantPandaCV 公众号搜索到。如下图所示,目前的视网膜血管分割方法按照输入数据划分有两类:image-level 和 patches-level,每一种方法都有自己的优势,如何将两者结合起来是一个需要去解决的问题,这也是 DA-Net 这篇文章的贡献之一。此外,这篇文章还提出了一个自适应的条状 Upsampling Block,我们会在后面展开介绍。文章地址可在最后参考链接找到,SpringerLink 和 ACM 上都可以下载。
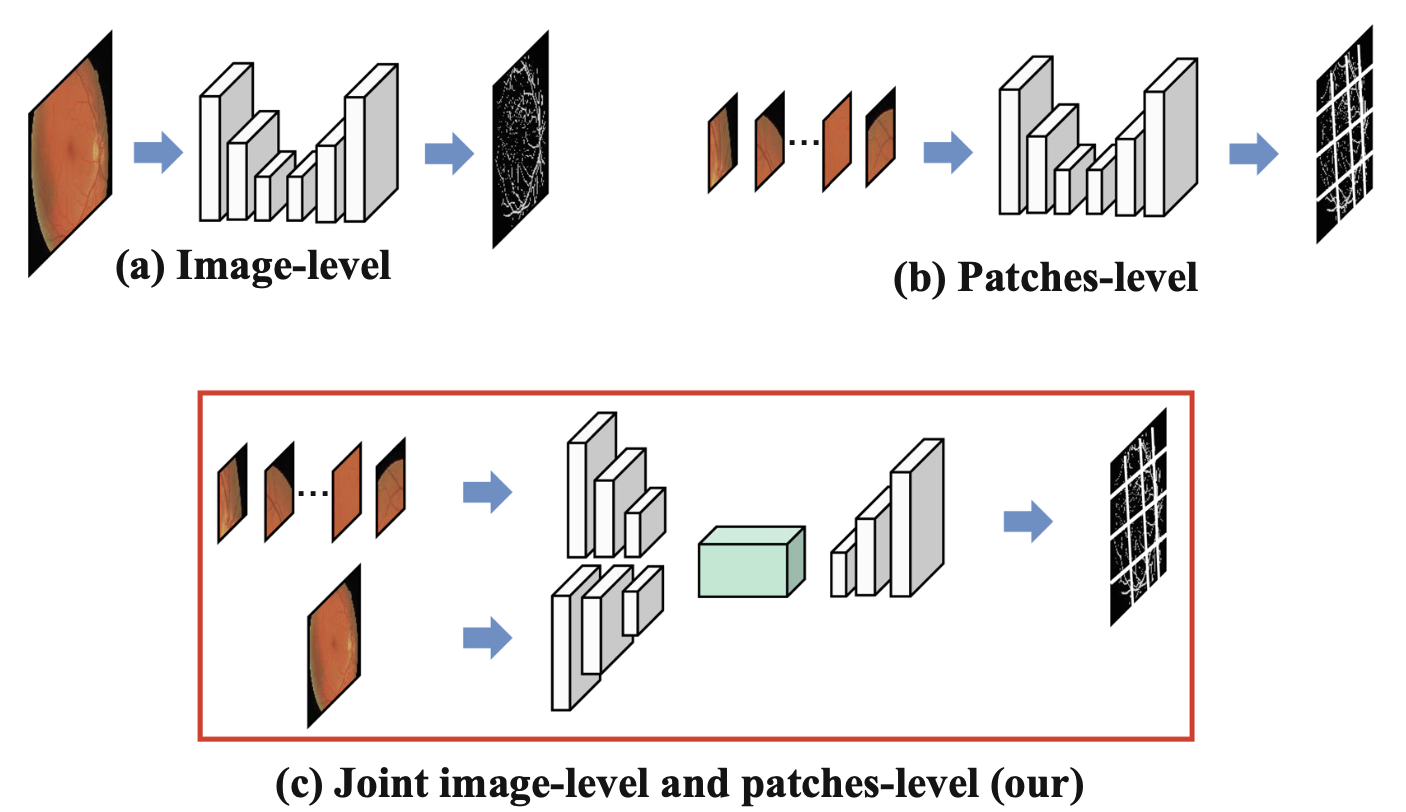
概述¶
目前的视网膜血管分割方法根据输入类型大致分为 image-level 和 patches-level 方法,为了从这两种输入形式中受益,这篇文章引入了一个双分支 Transformer 模块,被叫做 DBTM,它可以同时利用 patches-level 的本地信息和 image-level 的全局上下文信息。视网膜血管跨度长、细且呈条状分布,传统的方形卷积核表现不佳,也是为了更好地捕获这部分的上下文信息,进一步设计了一个自适应条状 Upsampling Block,被叫做 ASUB,以适应视网膜血管的条状分布。
网络简介¶
下图是 DA-Net 的整体结构。共享 encoder 包含五个卷积块,DBTM 在 encoder 之后,最后是带 ASUB 的 decoder。首先,原眼底图像很常规的被分成 N^2 个 patches,N 为 patch 的大小,除此之外,将原眼底图像也下采样 N 倍,但是不做裁剪。将它们一起送入共享 encoder,分别得到相应的特征图 F(i) 和 F′,这里的共享指的是两个 encoder 分支的权重共享(那么你可以把它简单理解为用同一个卷积核扫描 N^1+1 个 patches,只不过其中 1 这个 patch 是完整的图像),两个分支可以通过合并批次并行操作,这意味着输入图像的编码可以在一次推理中完成,无需增加额外的参数和时间消耗。随后,这两个分支的输出通过 DBTM 进行通信,DBTM 可以向每个补丁广播长距离的全局信息。U 型网络中间还有普通的跨层连接,最后,再通过 ASUB 的 decoder后,得到预测的分割结果。
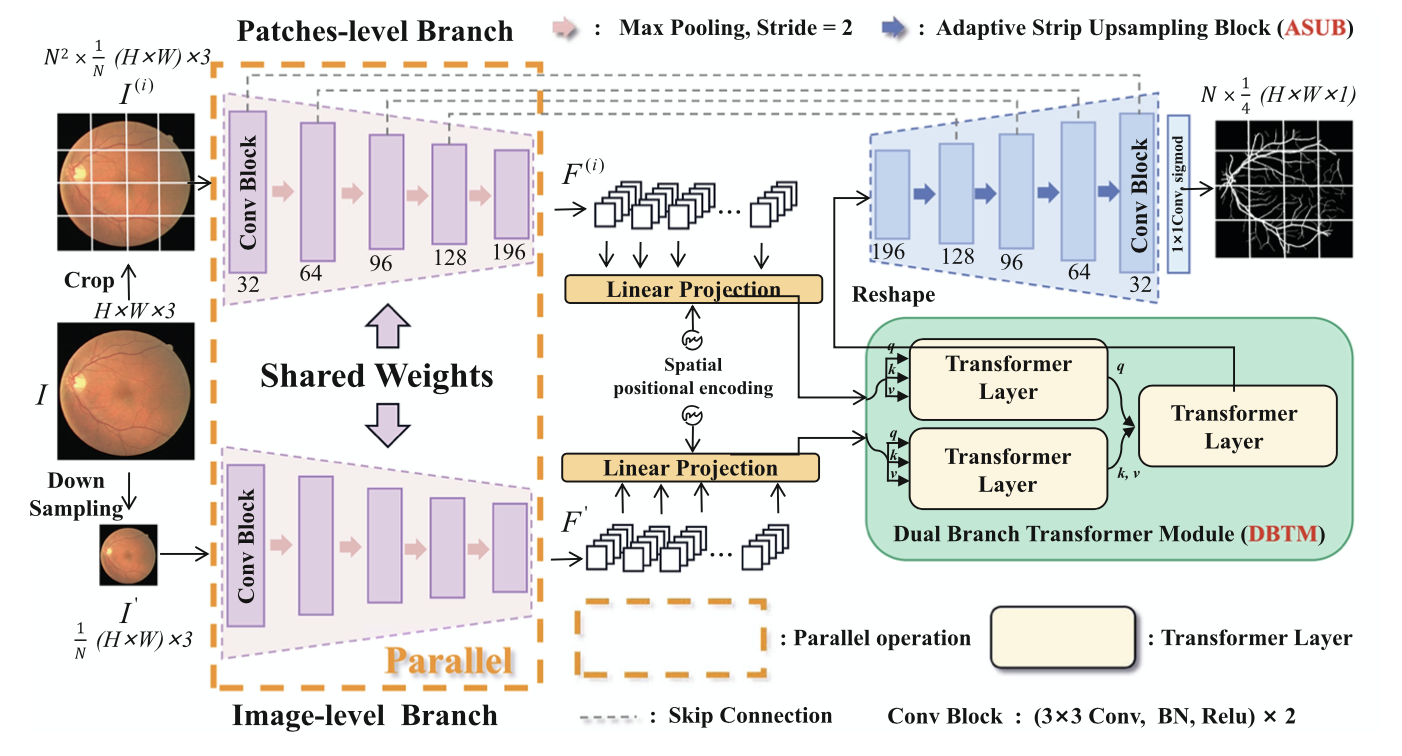
DBTM:Local Patches Meet Global Context¶
下面两部分,我们分别对 DBTM 和 AUSB block 展开介绍。
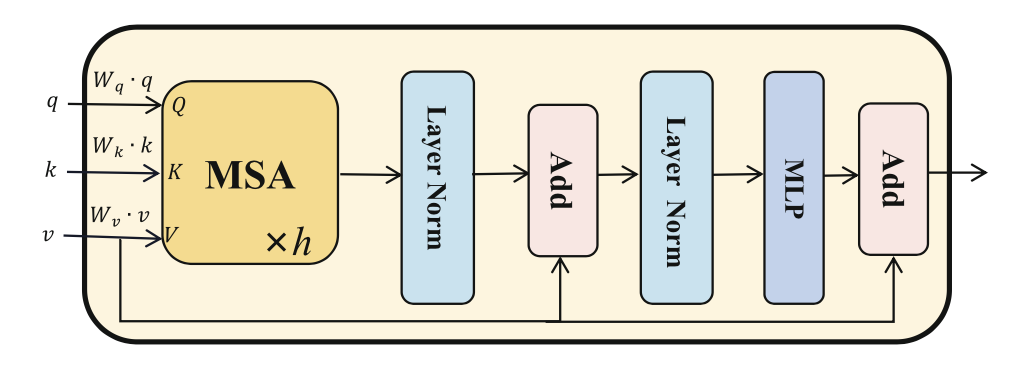
首先,将经过 flatten 和投影的特征图 F(i) 和 F′ 作为输入 tokens ,其中加入训练过的 position embeddings 以保留位置信息。然后,如下图所示,输入 tokens 被送入 Transformer Layer。不同的是,设计了一个特殊的 self-then-cross 的 pipeline,将两个分支的输入混合起来,称为双分支 Transformer 模块(看网络简介中的图)。第一个 Transformer Layer 作为 Q,第二个 Transformer Layer 作为 K 和 V。具体来说,首先,这两个分支的输入标记分别用自注意机制模拟 image-level 和 patches-level 的长距离依赖。然后,交叉注意机制被用于两个分支的 tokens 之间的通信。在交叉注意机制中,将 patches-level 的标记表示为查询 Q, image-level 分支的标记表示为下图中多头自我注意(MSA)层的键 Q 值 V。整体设计是很简单的,实现了”Local Patches Meet Global Context“。
ASUB block¶
视网膜血管的一些固有特征导致了其分割困难,比如视网膜血管的分支很细,边界很难区分,而且视网膜血管之间的关系很复杂。在这些情况下,视网膜血管周围的背景信息对视网膜血管的分割至关重要。如下图所示,传统的方形卷积核在正常的上采样块中不能很好地捕捉线性特征,并且不可避免地引入了来自邻近的不相关信息。为了更好地收集视网膜血管周围的背景信息,提出了 Adaptive Strip Upsampling Block(ASUB),它适合于长而细的视网膜血管分布。
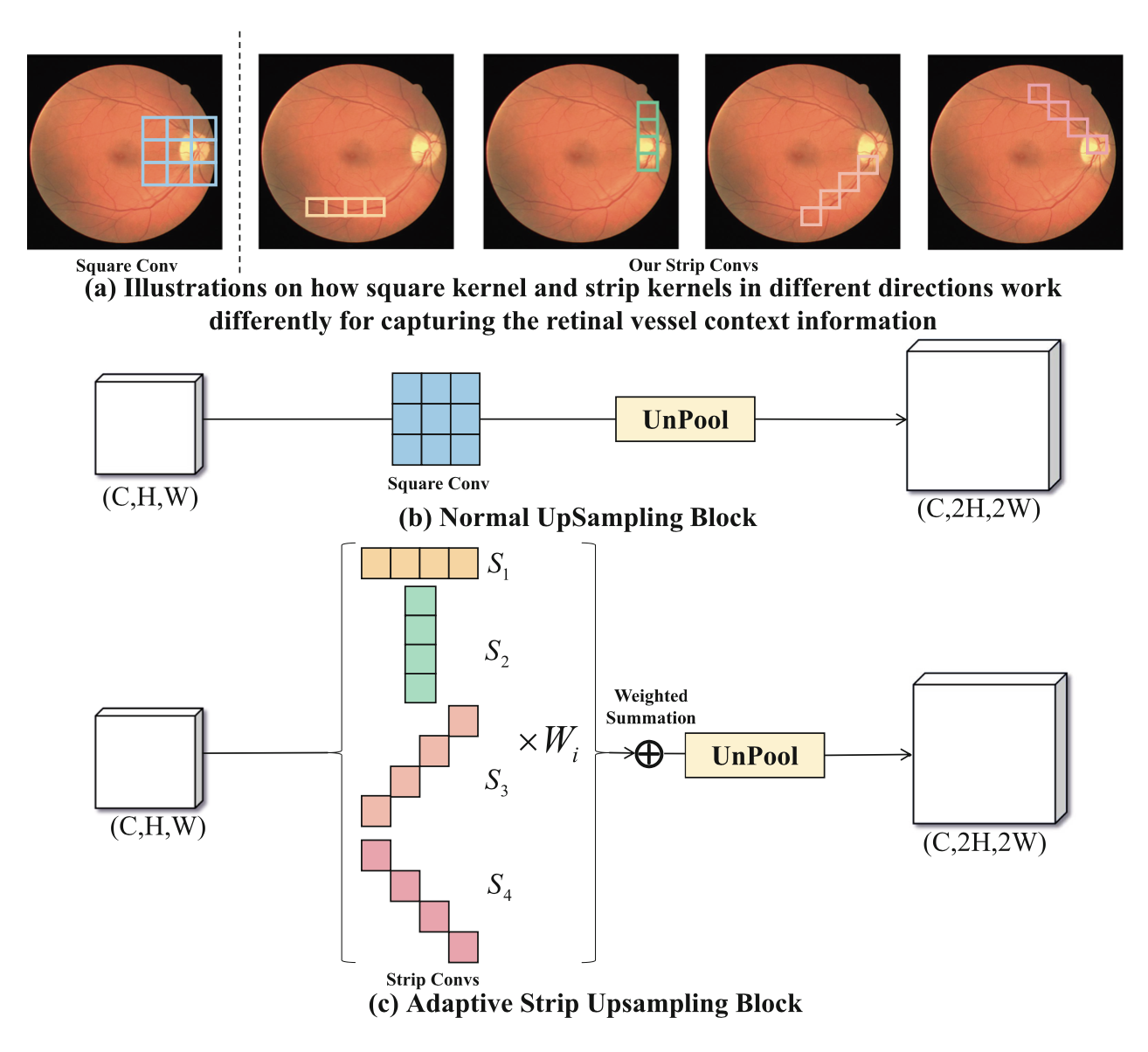
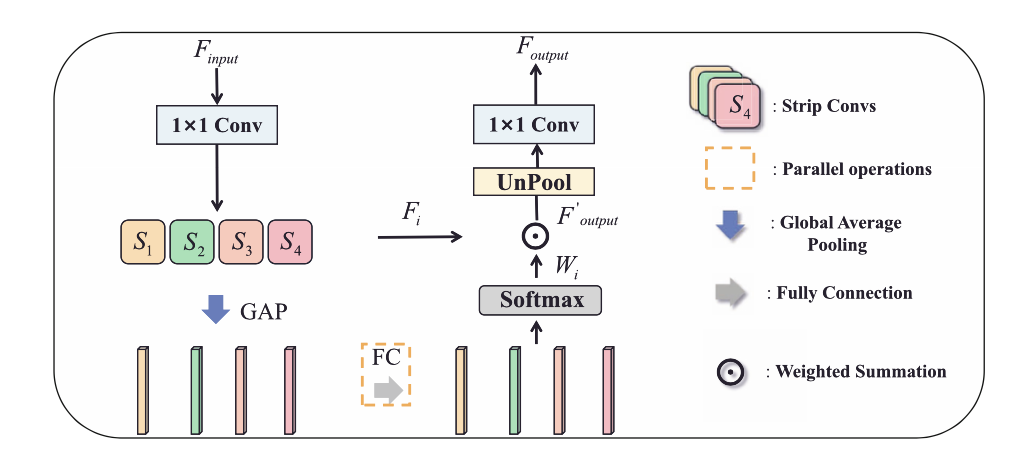
粗略看一下,在 © 中,一共有四种类型的条状卷积核,捕捉水平(S1)、垂直(S2)、左对角线(S3)和右对角线(S4)方向上的信息。接下来,我们仔细分析下 ASUB 的思路,首先,使用一个 1×1 的 Conv 来将特征图的维度减半,以减少计算成本。然后,利用四个带状卷积来捕捉来自不同方向的上下文信息。此外,做全局平均池化(GAP)来获得通道维度的特征图。在特征图的通道维度上获得特征向量,并使用全连接层来学习每个带状卷积的通道方向的注意立向量。之后,应用万能的 softmax 来产生通道融合权重Wi , i∈{1, 2, 3, 4}。 最后,我们用学到的自适应权重对每个带状卷积 Fi 的输出进行加权,得到特征图,特征图是 4 个 Fi*Wi 求和。 最后用 1×1 的 Conv 恢复维度,得到最终输出 Foutput。同时,这部分是会增加网络学习负担的。
实验¶
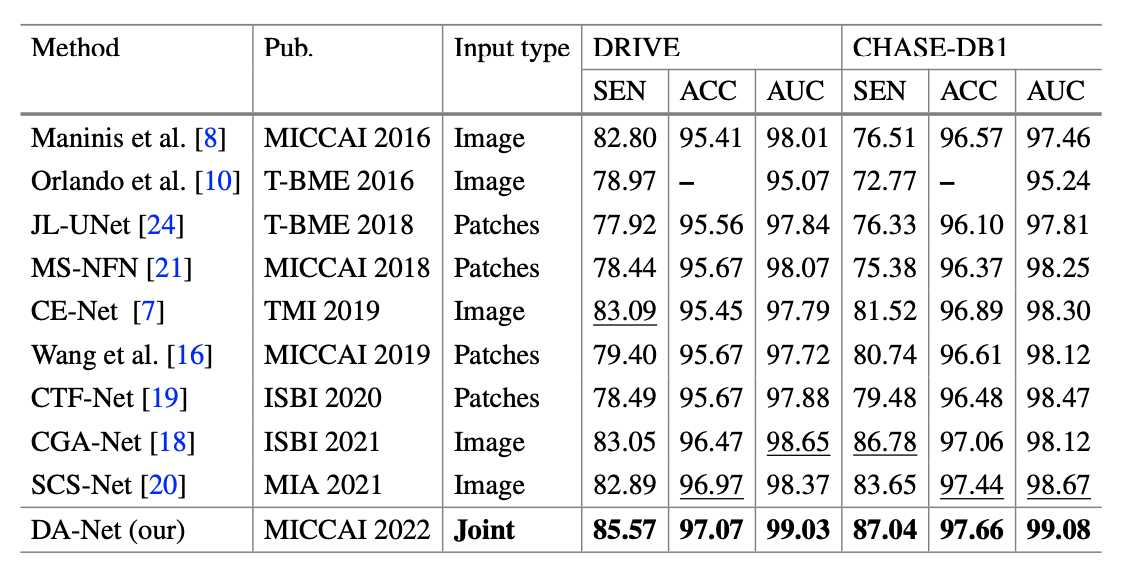
首先是和其他 SOTA 方法的比较,包括 image-level 和 patches-level 两种,如下表。
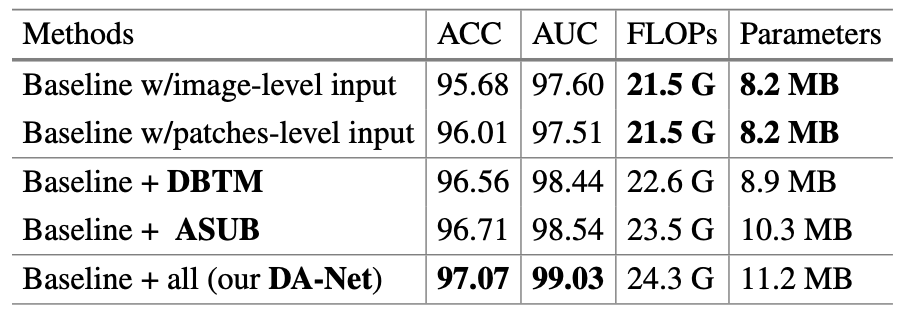
接下来是消融实验的部分,其中的 Baseline 指 U-Net。注意到,FLOPs 和 参数量的增加是可以接受的。
讨论¶
其实 ASUB 设置的条形采样方向也不一定与一些小血管的方向完全一致,这是可以进一步改进的地方。比如说尝试可变形卷积(Deformable ConvNetsV2)的方式。
参考链接¶
- https://link.springer.com/chapter/10.1007/978-3-031-16434-7_51
- https://static-content.springer.com/esm/chp%3A10.1007%2F978-3-031-16434-7_51/MediaObjects/539243_1_En_51_MOESM1_ESM.pdf
- https://openaccess.thecvf.com/content_CVPR_2019/html/Zhu_Deformable_ConvNets_V2_More_Deformable_Better_Results_CVPR_2019_paper.html
本文总阅读量次