MICCAI 2022:基于 MLP 的快速医学图像分割网络 UNeXt¶
文章目录¶
- 前言
- 方法概述
- UNeXt 架构
- TokMLP 设计思路
- 实验部分
- 一些理解和总结
- 参考链接
前言¶
最近 MICCAI 2022 的论文集开放下载了,地址:https://link.springer.com/book/10.1007/978-3-031-16443-9 ,每个部分的内容如下所示:
Part I: Brain development and atlases; DWI and tractography; functional brain networks; neuroimaging; heart and lung imaging; dermatology;
Part II: Computational (integrative) pathology; computational anatomy and physiology; ophthalmology; fetal imaging;
Part III: Breast imaging; colonoscopy; computer aided diagnosis;
Part IV: Microscopic image analysis; positron emission tomography; ultrasound imaging; video data analysis; image segmentation I;
Part V: Image segmentation II; integration of imaging with non-imaging biomarkers;
Part VI: Image registration; image reconstruction;
Part VII: Image-Guided interventions and surgery; outcome and disease prediction; surgical data science; surgical planning and simulation; machine learning – domain adaptation and generalization;
Part VIII: Machine learning – weakly-supervised learning; machine learning – model interpretation; machine learning – uncertainty; machine learning theory and methodologies.
其中关于分割有两个部分,Image segmentation I 在 Part IV, 而 Image segmentation II 在 Part V。计划对其中开放源代码和典型的方法注意解读,这次要分享的论文是其中的 UNeXt: MLP-based Rapid Medical Image Segmentation Network,arXiv 链接:https://arxiv.org/abs/2203.04967 。
随着医学图像的解决方案变得越来越适用,我们更需要关注使深度网络轻量级、快速且高效的方法。具有高推理速度的轻量级网络可以被部署在手机等设备上,例如 POCUS(point-of-care ultrasound)被用于检测和诊断皮肤状况。这就是 UNeXt 的动机。
方法概述¶
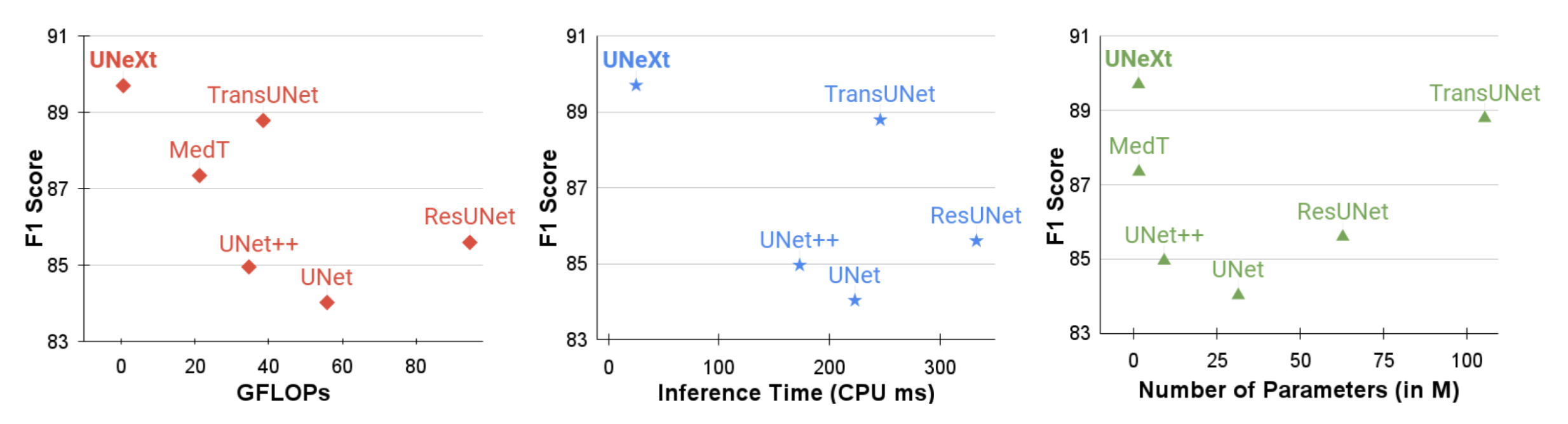
之前我们解读过基于 Transformer 的 U-Net 变体,近年来一直是领先的医学图像分割方法,但是参数量往往不乐观,计算复杂,推理缓慢。这篇文章提出了基于卷积多层感知器(MLP)改进 U 型架构的方法,可以用于图像分割。设计了一个 tokenized MLP 块有效地标记和投影卷积特征,使用 MLPs 来建模表示。这个结构被应用到 U 型架构的下两层中(这里我们假设纵向一共五层)。文章中提到,为了进一步提高性能,建议在输入到 MLP 的过程中改变输入的通道,以便专注于学习局部依赖关系特征。还有额外的设计就是跳跃连接了,并不是我们主要关注的地方。最终,UNeXt 将参数数量减少了 72 倍,计算复杂度降低了 68 倍,推理速度提高了 10 倍,同时还获得了更好的分割性能,如下图所示。
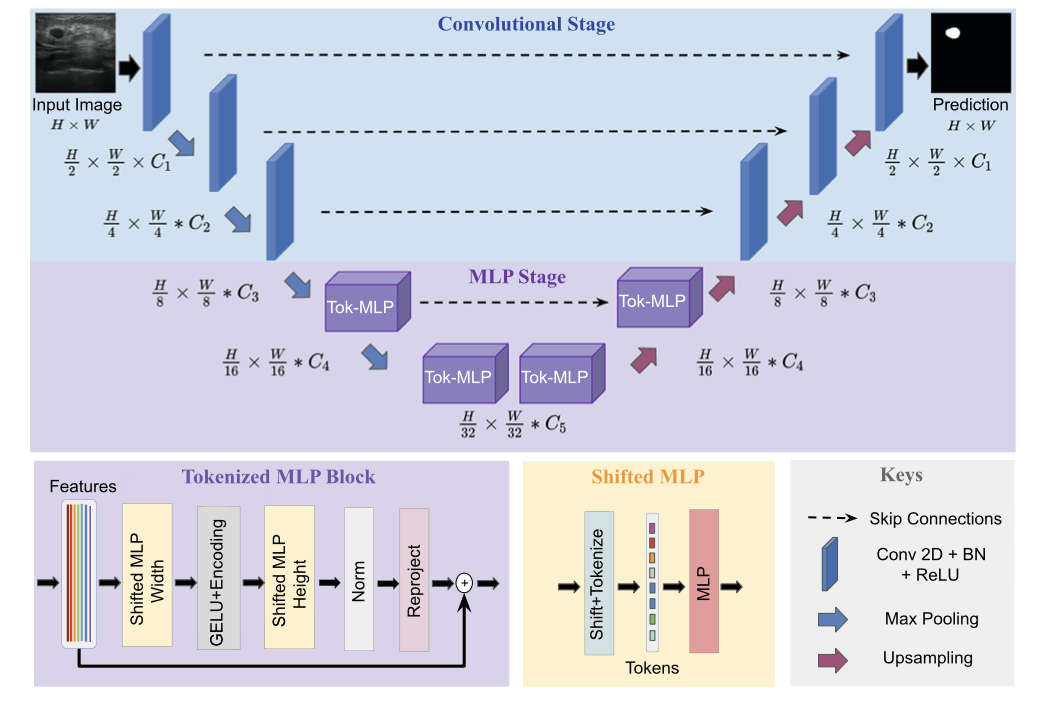
UNeXt 架构¶
UNeXt 的设计如下图所示。纵向来看,一共有两个阶段,普通的卷积和 Tokenized MLP 阶段。其中,编码器和解码器分别设计两个 Tokenized MLP 块。每个编码器将分辨率降低两倍,解码器工作相反,还有跳跃连接结构。每个块的通道数(C1-C5)被设计成超参数为了找到不掉点情况下最小参数量的网络,对于使用 UNeXt 架构的实验,遵循 C1 = 32、C2 = 64、C3 = 128、C4 = 160 和 C5 = 256。
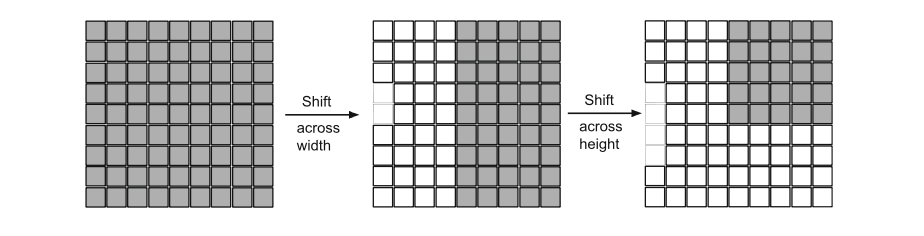
TokMLP 设计思路¶
关于 Convolutional Stage 我们不做过多介绍了,在这一部分重点专注 Tokenized MLP Stage。从上一部分的图中,可以看到 Shifted MLP 这一操作,其实思路类似于 Swin transformer,引入基于窗口的注意力机制,向全局模型中添加更多的局域性。下图的意思是,Tokenized MLP 块有 2 个 MLP,在一个 MLP 中跨越宽度移动特征,在另一个 MLP 中跨越高度移动特征,也就是说,特征在高度和宽度上依次移位。论文中是这么说的:“我们将特征分成 h 个不同的分区,并根据指定的轴线将它们移到 j=5 的位置”。其实就是创建了随机窗口,这个图可以理解为灰色是特征块的位置,白色是移动之后的 padding。
解释过 Shifted MLP 后,我们再看另一部分:tokenized MLP block。首先,需要把特征转换为 tokens(可以理解为 Patch Embedding 的过程)。为了实现 tokenized 化,使用 kernel size 为 3 的卷积,并将通道的数量改为 E,E 是 embadding 嵌入维度( token 的数量),也是一个超参数。然后把这些 token 送到上面提到的第一个跨越宽度的 MLP 中。
这里会产生了一个疑问,关于 kernel size 为 3 的卷积,使用的是什么样的卷积层?答:这里还是普通的卷积,文章中提到了 DWConv(DepthWise Conv),是后面的特征通过 DW-Conv 传递。使用 DWConv 有两个原因:(1)它有助于对 MLP 特征的位置信息进行编码。MLP 块中的卷积层足以编码位置信息,它实际上比标准的位置编码表现得更好。像 ViT 中的位置编码技术,当测试和训练的分辨率不一样时,需要进行插值,往往会导致性能下降。(2)DWConv 使用的参数数量较少。
这时我们得到了 DW-Conv 传递过来的特征,然后使用 GELU 完成激活。接下来,通过另一个 MLP(跨越height)传递特征,该 MLP 把进一步改变了特征尺寸。在这里还使用一个残差连接,将原始 token 添加为残差。然后我们利用 Layer Norm(LN),将输出特征传递到下一个块。LN 比 BN 更可取,因为它是沿着 token 进行规范化,而不是在 Tokenized MLP 块的整个批处理中进行规范化。上面这些就是一个 tokenized MLP block 的设计思路。
此外,文章中给出了 tokenized MLP block 涉及的计算公式:
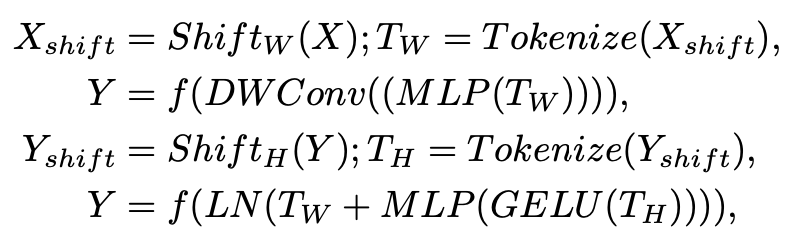
其中 T 表示 tokens,H 表示高度,W 表示宽度。值得注意的是,所有这些计算都是在 embedding 维度 H 上进行的,它明显小于特征图的维度 HN×HN,其中 N 取决于 block 大小。在下面的实验部分,文章将 H 设置为 768。
实验部分¶
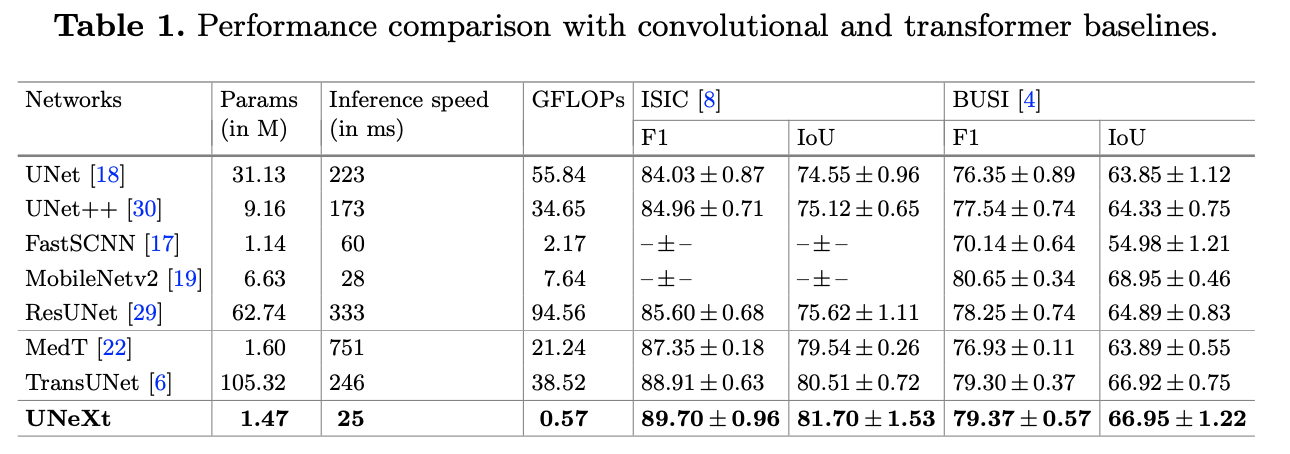
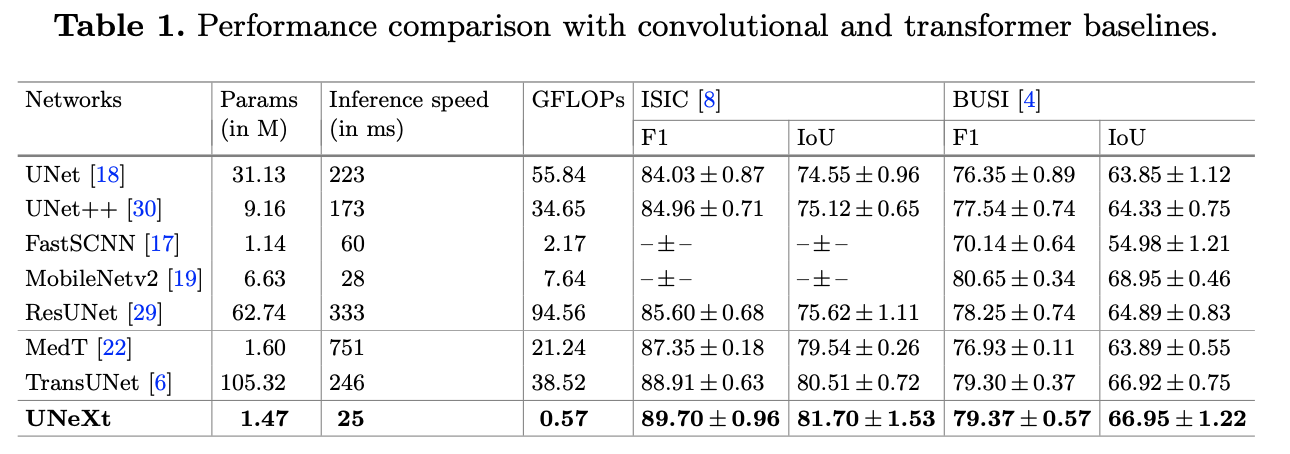
实验在 ISIC 和 BUSI 数据集上进行,可以看到,在 GLOPs、性能和推理时间都上表现不错。
下面是可视化和消融实验的部分。可视化图可以发现,UNeXt 处理的更加圆滑和接近真实标签。
消融实验可以发现,从原始的 UNet 开始,然后只是减少过滤器的数量,发现性能下降,但参数并没有减少太多。接下来,仅使用 3 层深度架构,既 UNeXt 的 Conv 阶段。显着减少了参数的数量和复杂性,但性能降低了 4%。加入 tokenized MLP block 后,它显着提高了性能,同时将复杂度和参数量是一个最小值。接下来,我们将 DWConv 添加到 positional embedding,性能又提高了。接下来,在 MLP 中添加 Shifted 操作,表明在标记化之前移位特征可以提高性能,但是不会增加任何参数或复杂性。注意:Shifted MLP 不会增加 GLOPs。
一些理解和总结¶
在这项工作中,提出了一种新的深度网络架构 UNeXt,用于医疗图像分割,专注于参数量的减小。 UNeXt 是一种基于卷积和 MLP 的架构,其中有一个初始的 Conv 阶段,然后是深层空间中的 MLP。 具体来说,提出了一个带有移位 MLP 的标记化 MLP 块。 在多个数据集上验证了 UNeXt,实现了更快的推理、更低的复杂性和更少的参数数量,同时还实现了最先进的性能。
我在读这篇论文的时候,直接注意到了它用的数据集。我认为 UNeXt 可能只适用于这种简单的医学图像分割任务,类似的有 Optic Disc and Cup Seg,对于更复杂的,比如血管,软骨,Liver Tumor,kidney Seg 这些,可能效果达不到这么好,因为运算量被极大的减少了,每个 convolutional 阶段只有一个卷积层。MLP 魔改 U-Net 也算是一个尝试,在 Tokenized MLP block 中加入 DWConv 也是很合理的设计。
参考链接¶
- https://jeya-maria-jose.github.io/UNext-web/
- https://arxiv.org/abs/2203.04967
- https://github.com/jeya-maria-jose/UNeXt-pytorch
本文总阅读量次