在微信公众号上本文的一些链接可能失效,为获得最好的阅读体验,读者可以到 https://blog.jongkhu.com/article/unsupervised-super-resolution 这里阅读原文以及获取最新状态。本文首发于 GiantPandaCV。
Unsupervised(unpaired) learning in blind super resolution¶
date: 2023/04/04 slug: unpaired-super-resolution status: Published tags: Super Resolution type: Post
本文简单讲述一下无监督学习在盲超分任务中的应用,主要有域适应、对比学习、模糊核估计等方法。
超分任务的无监督并不是很严格,很多无监督主要表现形式为:非配对,本质上还是需要HR图像的信息对网络进行监督。SimUSR: A Simple but Strong Baseline for Unsupervised Image Super-resolution等文中提出了一些不需要HR的无监督超分方法。
盲超分任务¶
盲超分任务:”Blind image super-resolution (SR), aiming to super-resolve low-resolution images with unknown degradation.”
其目的是解决真实世界的超分问题,一般的基于深度学习的超分往往只在简单的下采样核,例如:bicubic,的情况下使用神经网络对LR-HR图像对进行拟合,这会使得网络仅能处理几个经典的下采样核场景而无法在真实场景下完成超分。
引自”Blind Image Super-Resolution: A Survey and Beyond”, Anran Liu, Yihao Liu, Jinjin Gu, Yu Qiao, and Chao Dong
同时由于真实的、成对的LR-HR图像对难以获取,无监督方案越来越受到研究人员关注。
为方便叙述,后文中所有传统下采样核均被表述为bicubic;大多数文章的实验为正规的对比实验+消融实验,这里仅挑有意思的实验讲解
Domain Adaptation¶
在Cross Device Super Resolution那篇文章中专门提到了UDA在超分等图像复原任务中的难点:”Few are devoted to low-level vision, which is more challenging for UDA since it concentrates more on pixel-wise adaptation and is not easy just by simple feature alignment or sample distribution alignment like UDA in high-level vision.”
DASR¶
文章简介¶
文章全称:Unsupervised Real-world Image Super Resolution via Domain-distance Aware Training
文章链接:https://ar5iv.labs.arxiv.org/html/2004.01178v1
文章代码:https://github.com/ShuhangGu/DASR
一般基于深度学习的超分使用bicubic制作数据,该方案无法适用于真实场景,换句话说就是bicubic制作的LR图像与真实世界的LR图像存在差异。文章作者的想法十分简洁:如果我们需要对真实图像进行超分,拉进bicubic图像与真实图像的距离就好了。
笔者认为本文中心是原文abstract中的这句话:”Domain-gap aware training takes additional benefit from real data in the target domain while domain-distance weighted supervision brings forward the more rational use of labeled source domain data.” 这句话说明了文章的两个重点:
- domain-gap aware training是有非配对真实数据作为输入的,它的目的是拉进目标domain(真实图像域)与现有domain(bicubic图像域或由网络生成的图像域)的距离
- domain-distance weighted supervision能够更好的利用现有domain(bicubic图像域或由网络生成的图像域)的数据
综合起来就是用一系列手段拉进了bicubic域与真实图像域的距离,能够更好的超分真实图像了。
解决方案¶
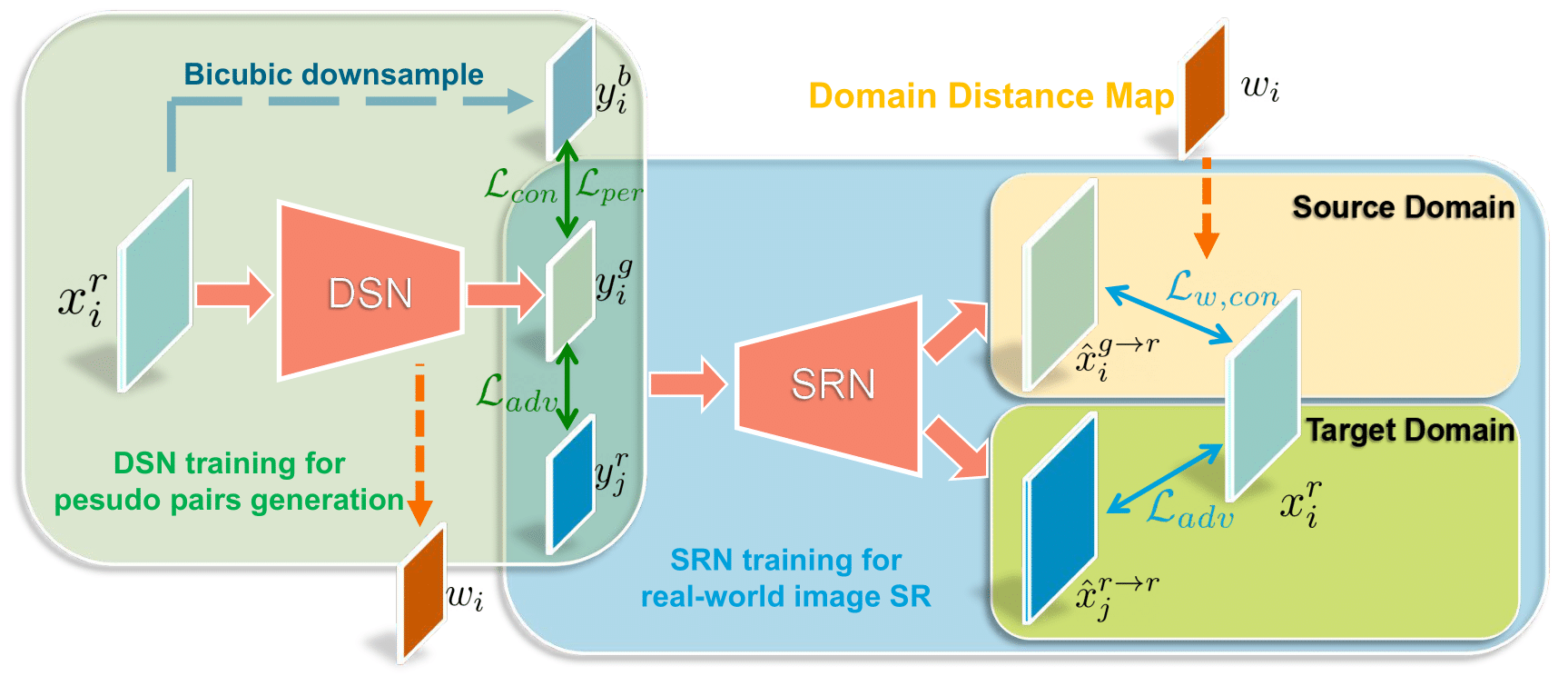
- Training of Down-Sampling Network
- Domain distance aware training of Super-Resolution Network
整个训练方案包含两部分:DSN和SRN,DSN负责从HR图像学习到真实的LR图像,SRN负责超分,接下来分别介绍这两个模块。
DSN本质上是一个Unpaired GAN网络,输入真实高分辨率图像,输入1. 真实低分辨率图像,2. domain distance map。为了避免unpaired训练导致的颜色偏移或者伪影出现,在实际训练中只把高频信息(细节部分,也就是退化更明显的部分)输入至判别器。
这里想法比较像同期的一篇”Deblurring by Realistic Blurring”。同时这个高频假设比较牵强,高频≠退化更明显,文章仅从实验角度简单分析了这一假设
domain distance map 表示了判别器认为的每一个patch的真实情况,值越高代表该patch越可能是真实图像。
DDM将被嵌入到SRN中辅助超分网络的训练,即在原始pixel loss基础上点乘domain distance map,使得domain distance map中值更小的部分也就是更真实的部分的loss被突出,使得网络更关注真实图像的超分问题。
同时为了进一步确定SRN生成的图像是真实的,作者加入了一个额外的对抗损失:
learned角标代表该图像由DSN生成,该loss的主要目的就是保证即使DSN学不到真实图像的下采样方法,也能有这个对抗损失给它兜底,让SRN学到对真实图像的上采样。
这个SRN虽然存在真实的LR输入,但是是非配对的任意真实LR图像,这不破坏非配对这一前提
一些疑问¶
这篇文章想法很简洁,方法比较精妙。但是个人觉得存在以下一个问题:
- 文章提取了图像的高频信息后输入DSN进入判别器,这里其实还暗含一个假设:图像高频信息代表的退化模式即为全图的退化模式,这是不合理的。
- 如果提取特征的高频信息呢?
USR-DA¶
文章简介¶
文章全称:Unsupervised Real-World Super-Resolution: A Domain Adaptation Perspective
文章链接:https://ieeexplore.ieee.org/document/9711325
文章代码:https://github.com/anse3832/USR_DA (unofficial)
这篇文章把拉进bicubic域与真实图像域的问题视为domain adaptation问题,文章认为由深度神经网络学习如何真实的降采样是不稳定的(two-stage方法的通病)。所以,”We propose a novel unpaired SR training framework based on feature distribution alignment, with which we can obtain degradation-indistinguishable feature maps and then map them to HR images.”
上一篇在图像空间拉进两个domain的距离,这篇是在特征空间拉进两个domain的距离
所以,文章主要要解决的问题就是:
- *Feature Distribution Alignment:*如何将bicubic域与真实域的LR图像投影到一个特征空间中,保证网络(encoder)能够学习到与退化模型无关的特征
- *Feature Domain Regularization:*使得上述特征空间能够保留更多真实图像的信息,以确保超分网络在处理真实图像的特征
文章的图画的很好:
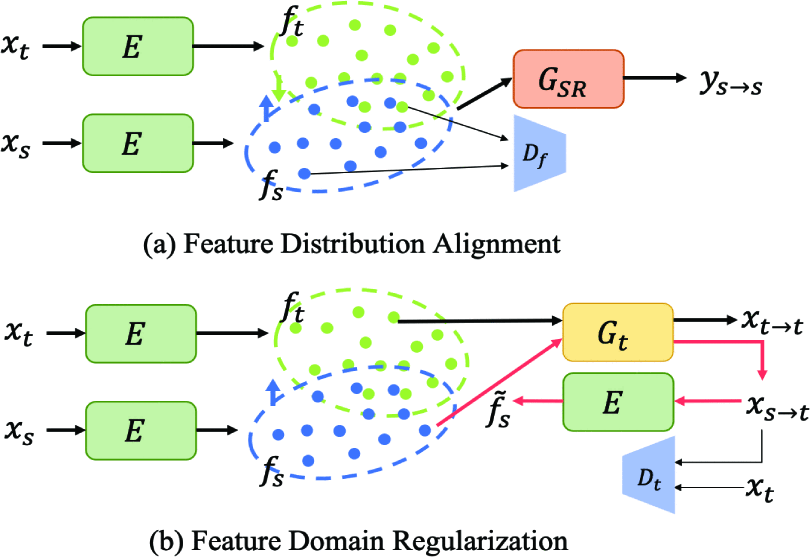
解决方案¶
这篇文章的解决方案比较复杂。
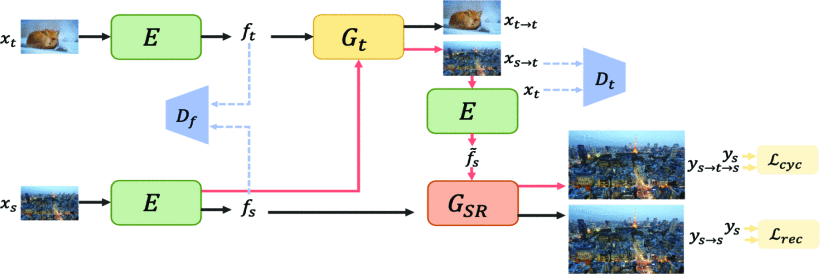
粉红色路线为推理路线
与上文一样,我们已知成对的bicubic域的LR-HR图像对,和一个随机的真实域的LR图像。
其中,Feature Distribution Alignment使用GAN完成,比较简单,我们主要关注Feature Domain Regularization部分。
Feature Domain Regularization需要做到以下两个目标:
- 共享特征空间不会损失bicubic域LR图像的内容
- 共享特征空间不会损失真实域LR图像的退化模型的抽象表征
当然是用CycleGAN:
- Gt负责把不同域图像的特征都映射到真实域中
- 图中右侧E负责从由Gt得到的真实域LR图像提取出共享特征空间的特征,它包含真实域的特征信息,并输入超分网络
- 超分网络存在两个输入,一个是bicubic域图像的在共享特征空间中的特征,一个是bicubic域图像经过了Gt所生成的真实域图像的在共享特征空间中的特征,分别输出对应的超分结果
- 拉进:输入超分网络的特征(权重较小,比较陷入两个特征完全一样的局部最优);超分网络两个输出与原始HR的距离;同时需要用GAN处理一下保证Gt输出的图像在判别器眼里是真实域的
一些疑问¶
这篇文章就是将UDA思想迁入超分任务中,并且loss很多不是很简洁。笔者对这篇文章还有一些疑问:
- 学习网络把bicubic和真实图像投射到同一特征空间这一操作其实就是做了一个,但是这样会导致真实LR的信息消失,笔者认为这种操作不是很好,放在去噪等任务可能更有说服力。
- 一开始把bicubic和真实图像投射到同一特征空间后又需要让该空间保留真实域的信息,这种对抗似乎比原始的GAN更难训练。
- 如果直接用共享空间信息与真实LR图像一起作为输入肯定比现有方案更好,这样就不需要把共享空间拉往真实域空间,但是这样就无法非配对了。这篇文章有一点为了这碟醋包饺子的嫌疑。
Contrastive Learning¶
DASR¶
又一个DASR,
文章简介¶
文章全称:Unsupervised Degradation Representation Learning for Blind Super-Resolution
文章链接:https://ar5iv.labs.arxiv.org/html/2104.00416v1
文章代码:https://github.com/The-Learning-And-Vision-Atelier-LAVA/DASR
目前盲超分任务很多文章主要目的是解决特定的退化核,有些盲超分方案甚至无法有效超分bicubic下采样的图像,这与盲超分任务的初衷背道而驰。为了能够解决现实中出现的未知退化,需要将退化模型从在像素空间的显式估计转移为在抽象表示,即原文abstract中的”Specifically, we learn abstract representations to distinguish various degradations in the representation space rather than explicit estimation in the pixel space.”
文章的introduction部分说明了该方案的两个优点:
- First, compared to extracting full representations to estimate degradations, it is easier to learn abstract representations to distinguish different degradations.
- Second, degradation representation learning does not require the supervision from ground truth degradation.
即,特异性 + 不需要GT。特异性指,这个方法能够使得退化估计模块能够针对不同图像得到不同的退化估计结果。
这一点其实有待商榷,成像结果的退化模型有很大一部分受硬件影响,在一些特殊领域可能是图像不同patch之间具有不同的退化模型。
解决方案¶
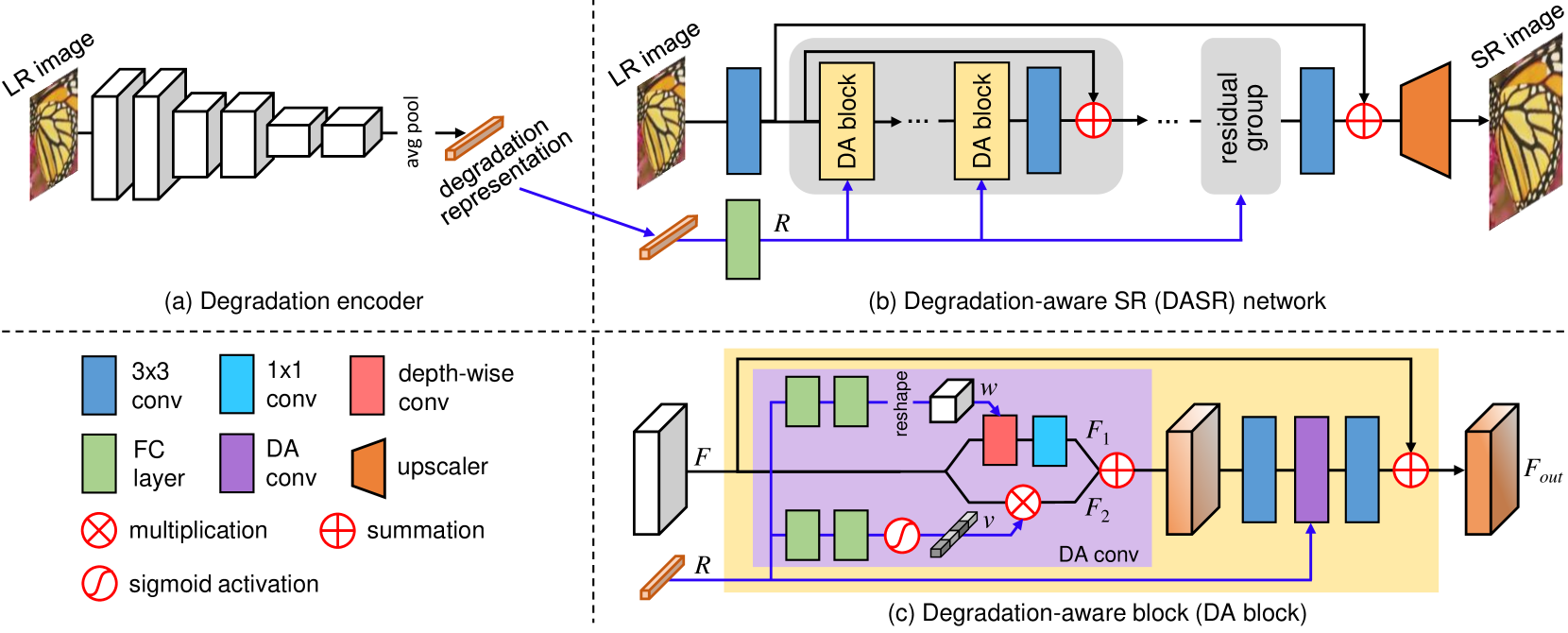
we assume the degradation is the same in an image but can vary for different images
- an image patch should be similar to other patches in the same image (i.e., with the same degradation)
- an image patch should be dissimilar to patches from other images (i.e., with different degradation)
文章通过拉进同一图像不同patch之间的退化估计结果、拉远不同图像patch之间的退化估计结果,进行对比学习。
把退化模型的抽象表述嵌入超分网络的方案类似于SFT,具体的特征整合方案烦请读者自行查看代码,在此不再赘述。
实验¶
这篇文章4.2的实验很有意思,他们用T-SNE可视化退化表征模块(就是把它当做分类问题)
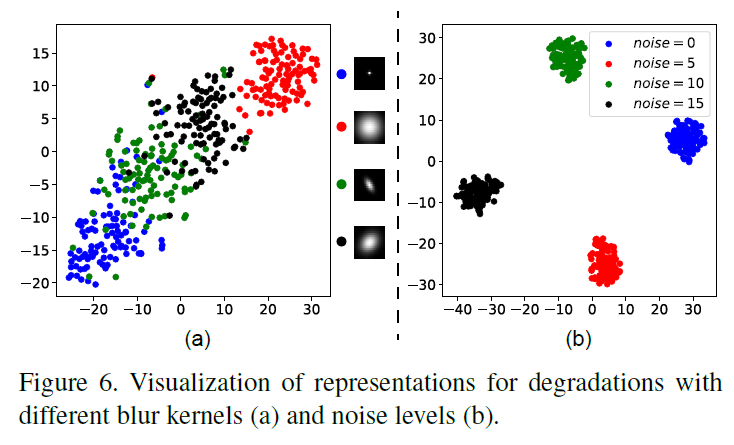
(a)是没用用退化表征模块的,(b)使用了。它表明该模块能够分辨出四种不同的退化核。
一些疑问¶
这篇文章其实就是把对比学习想个法子直接套在SR问题上。这篇文章个人感觉存在以下问题:
- 一张图像上不同patch的退化都是一致的嘛?这个跟上一篇DASR的想法也有些出入,上一篇DASR认为非细节的信息在判别是否真实的过程中是近乎无用的,那么非细节的信息的退化方法可能就是简单的bicubic等,而细节方法就是很复杂的退化方案。
- 文章使用卷积网络从LR得到退化的抽象表征,其实这种生成方案存在一定问题,我们假设LR = Func(SR),那么我们怎么能够单从LR图像得到Func的信息呢?同时,这里可以GradCAM看看网络是如何得到退化抽象表示的。
- 如果遇到训练集没有的退化模型,这个退化表征是否仍然有效?
CRL-SR¶
文章简介¶
文章全称:Blind Image Super-Resolution via Contrastive Representation Learning
文章链接:https://ar5iv.labs.arxiv.org/html/2107.00708v1
文章代码:null
这篇文章就是diss了上一篇文章的同一图像同一退化表征的问题,”We design CRL-SR, a contrastive representation learning network that focuses on blind SR of images with multi-modal and spatially variant distributions.”
文章的introduction部分说明了该文章的三个贡献:
- offers a new and effective blind SR approach while images suffer from multi-modal, spatially variant, and unknown degradation.
- design a contrastive decoupling encoding technique that leverages feature contrast to extract resolution-invariant features across LR and HR images.
- design a conditional contrastive loss that guides to generate the high-frequency details that are lost during the image degradation process effectively.
实际来说,既然空域上退化表征存在变化,借鉴一下USR-DA中拉进学习到bicubic域与真实域LR的做法,我们拉进去掉低频&去掉复杂退化的图像的距离就好了,这样就能够避免空域上不同退化对对比学习的影响
为啥不利用不同patch的不同退化这一特点,反而要丢掉…
解决方案¶
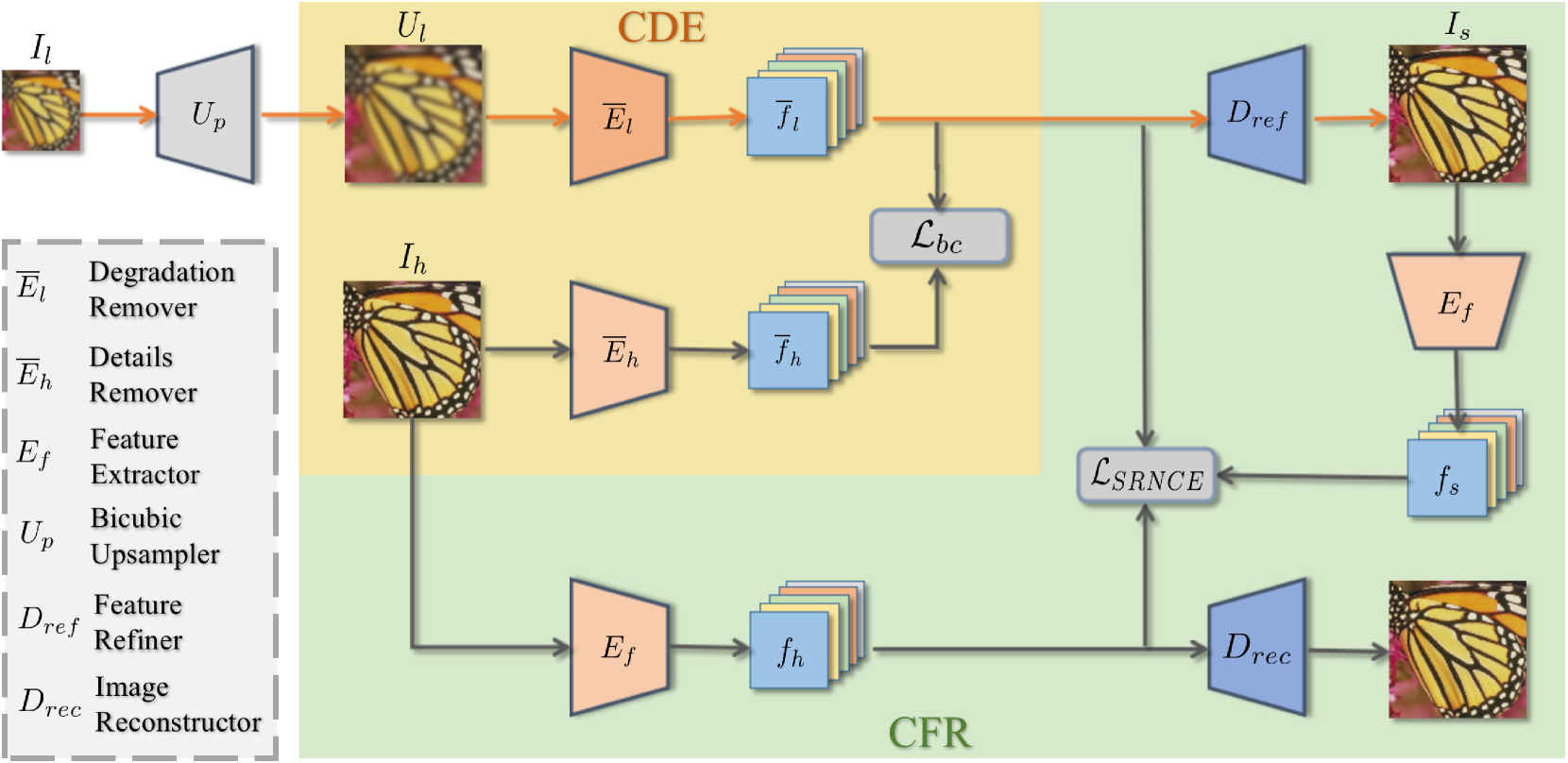
这一篇风格和思想都有点像USR-DA。
文章的核心解决思路:
CDE,上图的黄色部分:”which strives to disentangle and keep resolution-invariant features (i.e., clean low-frequency features)”
- El用于移除真实域LR图像的复杂退化,即把真实域LR图像特征映射到bicubic域LR图像特征
- Eh用于移除真实域LR图像的高频信息(或许可以用FFT代替)
这里使用了NCELoss拉进fl与fh,这意味着正负样本的选取为在M个fl’组成的fl中存在一一对应的fh’,这里的fl’与fh’互为正样本,并与其他fl中的特征互为负样本
这里需要注意,如果跟DASR一样选取不同图像的特征来做对比学习,会导致负样本过于简单,效果不好
CFR,上图的绿色部分:”CFR is designed to recover high-frequency details that are lost or corrupted during the image degradation process.”
- 我们使用低频&去除了复杂退化的fl输入超分网络中,得到的超分图像必然是缺失了很多高频信息的,需要在CFR过程中弥补回来
- 用低频&去除了复杂退化后超分的图像与真实的HR图像计算loss
这里仍然使用NCELoss,但是考虑到每张图像的高频信息不一致,作者在NCELoss的基础上增加了一个正则项
该正则项能够增强网络学到的fh与fl的差别,确保高频信息与bicubic域LR图像特征不一样(同时通过CDE,间接确保高频信息与去除了高频信息的图像的特征不一样)。
一些疑问¶
- 高频信息的移除个人觉得用一个Encoder去学有点小题大做,或许可以试试直接JPEG等操作在输入一个Encoder。
CDSR¶
文章简介¶
文章全称:Joint Learning Content and Degradation Aware Embedding for Blind Super-Resolution
文章链接:https://ar5iv.labs.arxiv.org/html/2208.13436v1
文章代码:https://github.com/ZhouYiiFeng/CDSR
这篇文章的introduction和motivation在它的github主页写的很清楚了,这里仅做一些翻译
目前的退化预测存在两种思路:
- Supervised Kernel Prediction: 显式或者隐式的学习退化核,退化核的估计会更为准确但是无法适用所有场景(或者跟segment anything一样来个1.1B的退化核种类?)
- Unsupervised Degradation Prediction: 不需要显式或者隐式的估计退化,能够避免SKP只能处理特定模糊核的情况(DASR就是典型的代表)
SKP能够很好的解决训练集出现的所有退化,但是可能无法解决训练集以外的退化;UDP能够处理较多退化,但是可能难以招架复杂的退化。
这篇文章作者为了弥补UDP的精度问题,发现了一个很奇怪的现象:”Surprisingly, we observed that using a degradation-oriented embedding will fail to improve the network performance or even end up with poor results.”,即使用面向退化的嵌入将无法改善网络性能。因为退化核和图像内容本身存在domain gap,强行将模糊核嵌入超分网络会损害性能,应当将内容与退化同时embedding。这里可能从IKC获得的启发,在IKC中提到退化空间和内容空间的融合会造成伪影(因为如果只将退化与图像叠加在一起,实际上这一步是在人为制造LR数据,虽然在PDM等文章里面给出了该问题的解法)。
分析¶
文章专门分析了”*Degradation Embedding”: “The Higher Degradation Accuracy the Better?*”
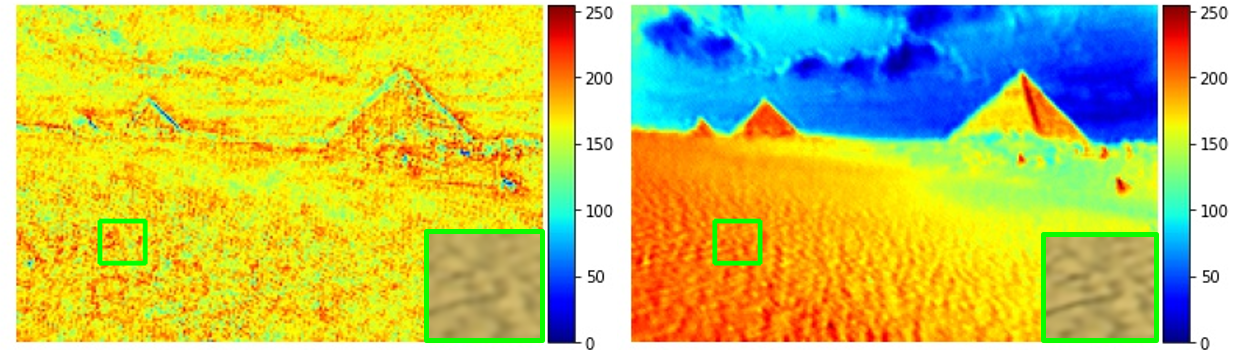
上图左侧是DASR超分特征可视化,右边的特征显得更有层次感(可以看出内容信息被embedding进来了,而非只有退化带来的局部差异)。
同时,本文提出的方案能够更使得学习到的退化表征有更丰富的内容信息,而非完全不一样(引入了内容信息之后,退化表征能够分布的更加分散而不展现出明显的曲线关系,这意味他们并不跟退化本身相关,还收到了其他因素影响,比如内容信息),如下图:
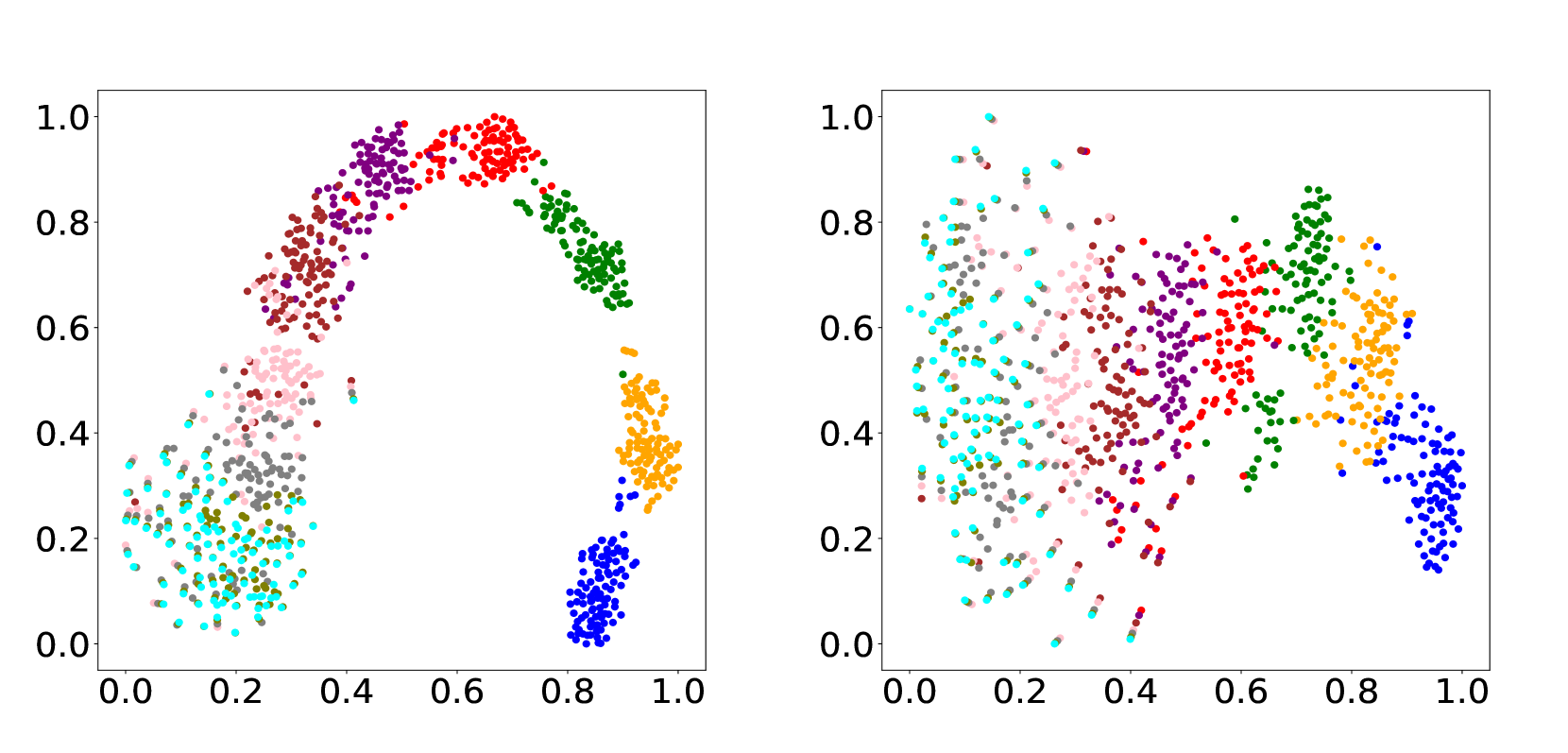
解决方案¶
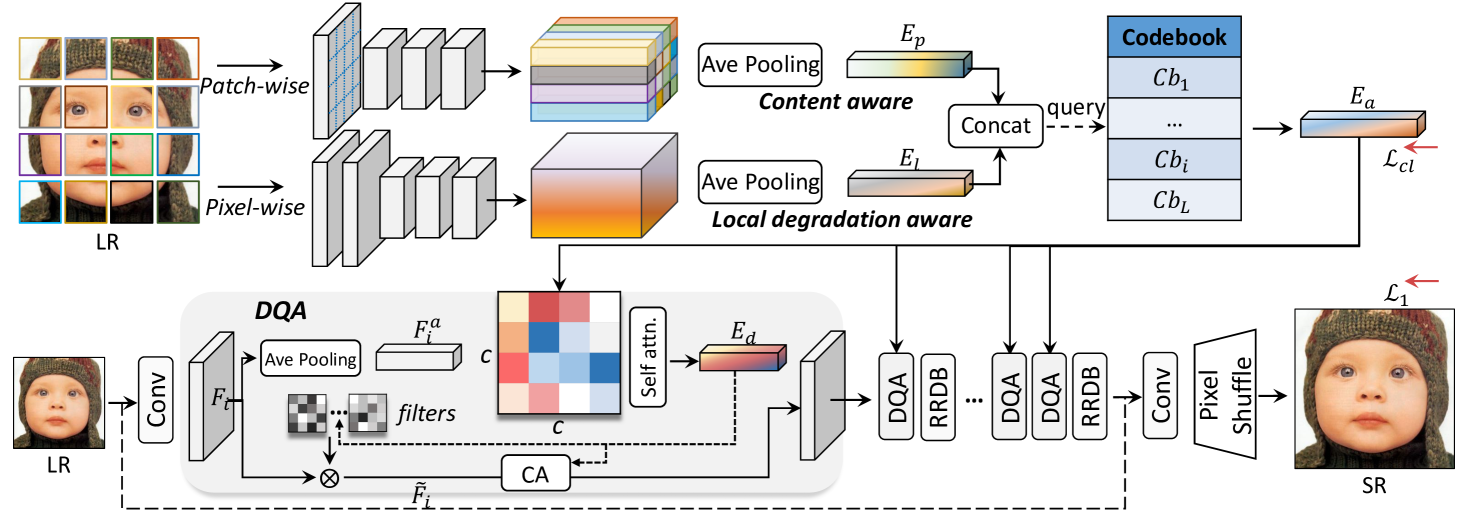
文章的claim的贡献就是针对文章的解决方案:
- a lightweight patch-based encoder (LPE) to extract content-aware degradation embedding features
- DQA to adaptively fuse the predicted content and degradation aware embedding into the SR network
- a Codebook-based Space Compress module (CSC) to limit the basis of feature space.
其中LPE加入了Patch-Wise的语义信息用来增强内容在退化表征学习中的存在感,Pixel-Wise的退化特征提取抄的MANet。对比学习过程中仍然用的InfoNCE。
一些疑问¶
- 在分析中,作者说明其方法能够关注更全局的信息,可以放进LAM中看看(不过LAM有个问题,它对退化十分敏感,不能解释真实场景下的超分模型,这里可能有个大坑)
- 如果不是把内容和退化联合嵌入呢?比如:分割结果、检测结果、分类中的特征。
DAA¶
文章简介¶
文章全称:Blind Image Super-Resolution with Degradation-Aware Adaptation
文章代码:https://github.com/wangyue7777/blindsr_daa
这一篇文章提出了一个问题:在基于对比学习的DASR方案中,退化表征学习模块只能输出当前的退化表征,这会导致超分模块并不清楚当前输入的LR的退化复杂程度,而仅有真实LR与其对应的退化表征是不够的,还需要知道退化是否严重。
这个motivation(或者说故事)比较难理解,我们用老师与学生做例子:对比学习中一次仅有一位老师(Decoder),两位学生(输入的LR图像),会有一名助教(Encoder)帮助老师(Decoder)为学生辅导(超分),助教(Encoder)会先比较两位学生(LR图像)的差别、对他们的情况(退化表征)进行总结,并将学生(LR图像)和自己的总结(退化表征)递给老师。这种情况下,老师(Decoder)一次只能看到两个学生(LR图像)的情况,并做出下一步判断(如何超分)。
这种教学方法存在以下问题:
- 老师不知道学生的整体水平(所有数据集的情况)
- 老师不知道单个学生在整体水平中的位次(本文的出发点)
- 老师不知道单个学生的特性(这个问题在单纯的超分网络中不存在,但是在联合任务中,Encoder可能无法认知到噪声多还是模糊多,可能需要更复杂的Encoder设计)
本文着重强调了第二点,同时引出(套用)了Ranking Loss作为解决方案。
解决方案¶
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1LKFKCqR-1681378714924)(Unsupervised(unpaired)]%20learning%20in%20blind%20super%20res%207c711be298db4b159d52caad9ff0d09e/daa.png)
其中与DASR不一样的地方就在于Ranker这个模块,Ranker用于学习对退化表征进行排名(额外对Encoder增加了一个head)
同时,本文也提出一个空域上自适应的退化表征嵌入超分网络的策略,本质上也是认为全图一致的退化是有问题的。
即:
- Ranking loss is imposed on top to make correct decision on estimating the degree of degradation
- The degradation is spatially-invariant, different types of textures may have different sensitivity to the degradation
在RankSRGAN中,Ranker的作用是根据图像的感知得分对图像进行排名,而在本文Ranker的作用就是根据图像的Encoder结果对图像的退化模型难度进行排名,其他基本相同
同时,为了保证模型能够学习到不同退化图像的rank,数据的预处理也很重要,需要手动制作很多不同退化的数据,这一点是否对真实图像超分有利也有待商榷
一些疑问¶
其实这篇文章的出发点还是比较新颖的,但是论文语言组织的不是很好、实验也不是很充足,缺少了很多超分SoTA模型的消融实验,我有以下疑问:
- 可能这篇文章仅在轻量化模型(或者说欠拟合的模型上)表现良好,作者仅对比了IMDN、RCAN、EDSR的消融实验,这是否说明这一方法在已经具有较强表现能力的超分网络上效果不佳
LR Generator¶
数据增强(得到了估计的模糊核或者退化表示后,将其作用于HR图像得到成对的训练数据),因为其可以做到非配对,所以也纳入无监督方案中。
DSGAN¶
文章简介¶
文章全称:Frequency Consistent Adaptation for Real World Super Resolution
文章链接:https://ar5iv.labs.arxiv.org/html/2012.10102v1
文章代码:https://github.com/ManuelFritsche/real-world-sr
Guided Frequency Separation Network for Real-World Super-Resolution也是一篇类似的工作,基本思想类似
这篇文章的出发点为:”The domain gap between the LR images and the real-world images can be observed clearly on frequency density, which inspires us to explictly narrow the undesired gap caused by incorrect degradation.”作者发现在不同退化程度的图像之间的差异在频率域会更加明显,如下图:
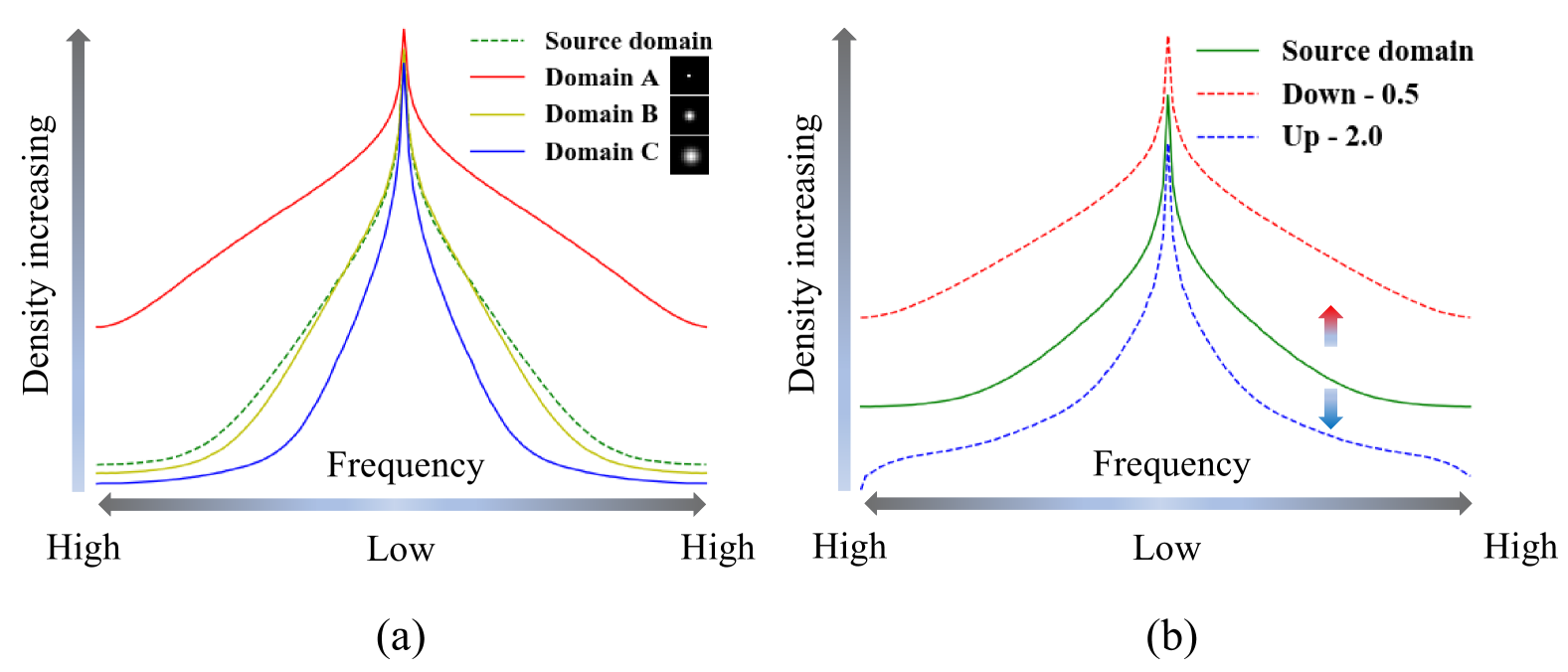
这张图含义如下:
- (a)为不同退化模糊核下图像的频率密度,模糊核本身方差越大(A > B ≈ Source > C),得到的图像的频率密度越小。
- (b)为上下采样的区别,对图像进行下采样后,图像的频率密度将变高;反之,上采样后,图像的频率密度将变小。
基于此规律,作者认为”The relationship between degradation and frequency density motivates us to keep frequency consistency between 𝐈_LR and source image 𝐱 . We focus on estimating 𝐤 with frequency domain regularization”模糊核的预测,应当受到频率的指导。本文提出的指导是一种领域迁移(image transfer)的想法。
解决方案¶
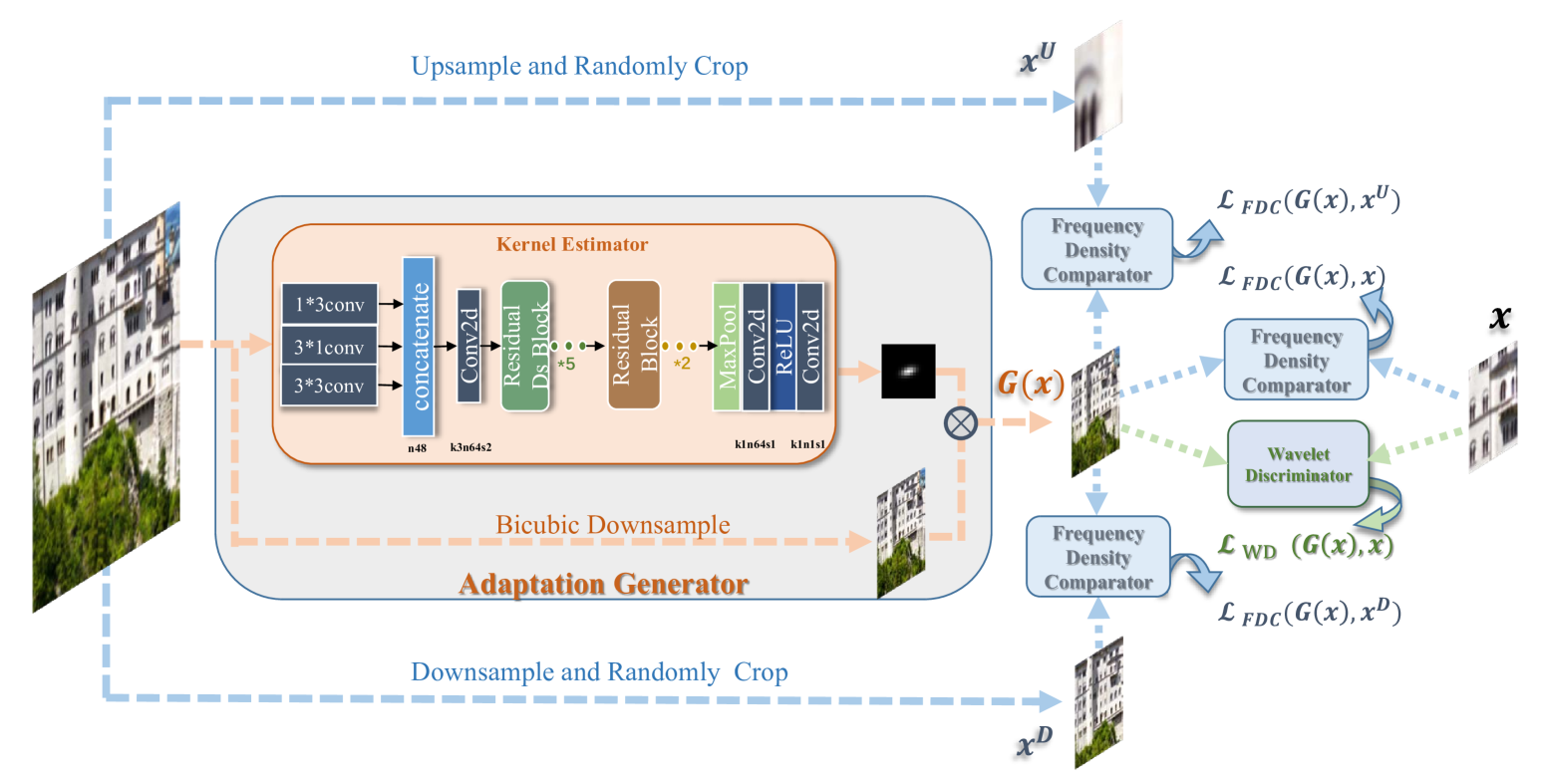
本文的LR-HR对中,LR的图像制作是从bicubic图像迁移的,迁移过程纳入了前文提到的频率密度先验。本质上是半个CycleGAN,判别器使用的与第一个DASR一样的小波判别器。
同期存在一篇Spectrum-to-Kernel Translation for Accurate Blind Image Super-Resolution文章也从证明了从频率域学习退化的有效性。遗憾的是,这两篇文章都只是从实验上证明了这一点。
一些疑问¶
- 从(a)中看,方差越小,模糊核之间的频率密度差异越小(越难以分辨),或许可以结合标准差等统计参数一起比较
- 老问题,判别器不应该只输入高频分量(在Guided Frequency Separation Network for Real-World Super-Resolution一文中有解决方案,就是一个减法)
MSSR¶
文章简介¶
文章全称:Learning the Degradation Distribution for Blind Image Super-Resolution
文章链接:https://ar5iv.labs.arxiv.org/html/2201.10747v2
文章代码:https://github.com/sangyun884/MSSR
这篇文章专注于解决训练一个更真实的退化图像生成器,作者认为:”previous works have heavily relied on the unrealistic assumption that the conditional distribution is a delta function and learned the deterministic mapping from the HR image to a LR image”。也就是以前的工作,只能从一个bicubic图像引导生成出一个确定的真实LR图像,这不是很病态(超分问题应该存在病态问题,而不是一一对应关系)。
为此,文章提出了一个十分简单的解决方案:”add a Gaussian noise multiplied by the learned standard deviation to intermediate feature maps of the degradation generator”。直接在特征层面引入噪声。
解决方案¶
文章的解决方案确实比较simple but powerful。
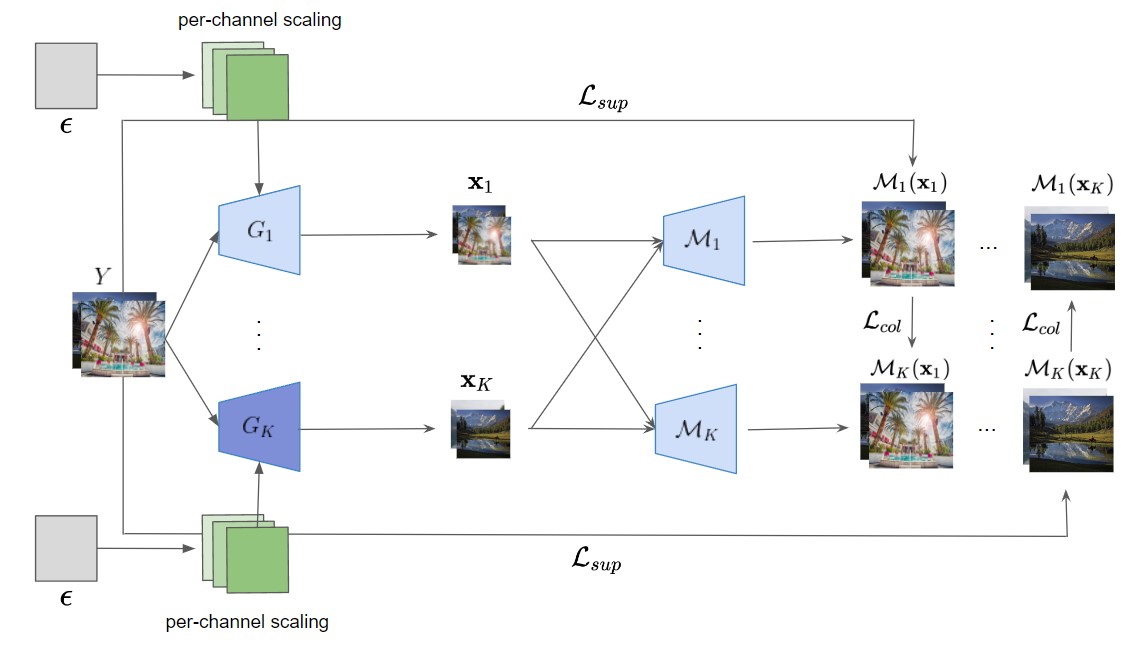
G1到Gk就是k个下采样网络,M1到Mk就是k个噪声添加器,同时”it is crucial for each generator to exclusively cover a certain area of the p(𝐱|𝐲) without redundancy”多个退化生成器可以带来更丰富的LR信息,使得网络能够处理更广泛的退化。最终构成的LR-HR对中,LR为k个退化后图像的平均值。
同时为了避免”Given the limited capacity of a model, it can be problematic as we train a model to invert the multiple degradation generators.”作者使用了Collaborative Learning(协作学习),也就是图中的Lcol的由来,它促使不同的LR图像互相不一致,这样避免了不同的G与M组合后会学到一致的退化(作者在这里提到”We initially tried to apply knowledge distillation in feature space and found that both yield similar results.”图像层面的蒸馏和特征层面的蒸馏效果差不多)
N*oise Injection between StyleGAN and this paper*¶
可以看到,这个公式右侧第二项跟StyleGAN的噪声是一样的。
一些疑问¶
- 在特征上直接引入噪声是否会难以训练,类似分类中mixup和cutmix的几个变体,原始的直接在图像操作,后续出来几个在特征层面操作的,或许可以借鉴一下。
- noise injection in GANs 是个大坑,这篇文章在超分问题中开了个头。
- 多个退化生成器是不是不够efficient,一个退化生成器输出很多不同的退化,这样可以避免引入额外的Collaborative Learning
PDM¶
文章简介¶
文章全称:Learning the Degradation Distribution for Blind Image Super-Resolution
文章链接:https://ar5iv.labs.arxiv.org/html/2203.04962v1
文章代码:https://github.com/greatlog/UnpairedSR
这一篇更是纯粹:退化核跟LR图像无关,所有的模糊核估计就是一种更复杂的数据增强方案。
解决方案¶
这篇文章沿用了先下采样
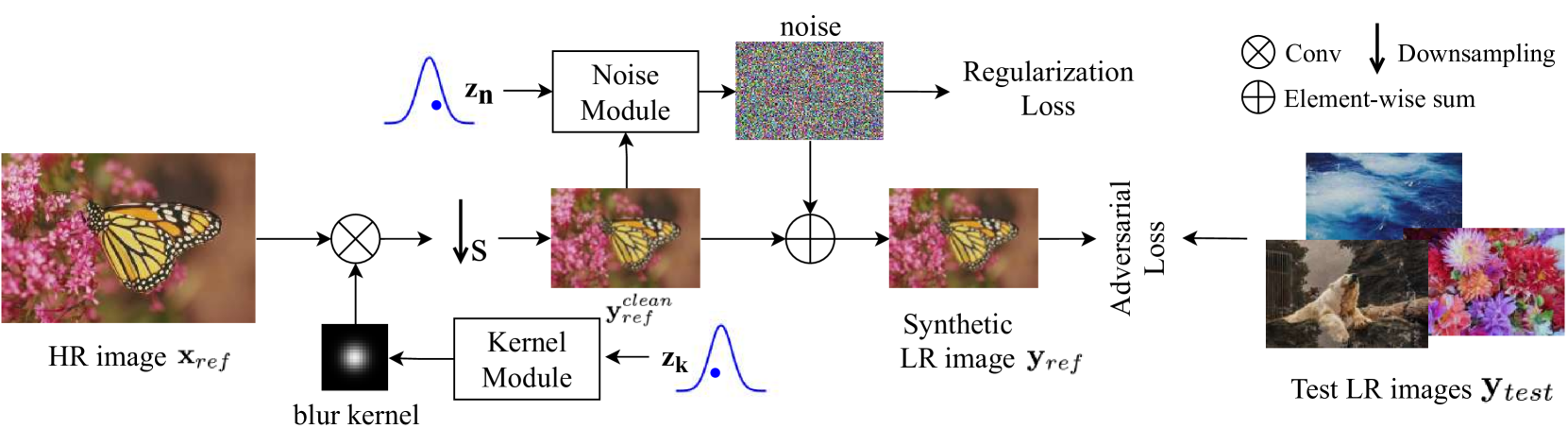
- kernel从一个噪声信号中直接学习得到(softmax,确保和为1)
- noise从LR后的图像与噪声信号中学习得到(为了确保0均值假设,会有个正则损失)
一些疑问¶
说实话这篇文章还能在之前卷翻天的盲超分上提点明显,有点意料之外
- 该模糊核生成方案没有办法确保模糊核的稀疏性(需要一些正则规范一下)
- 跟以前从噪声学GAN的问题一样,每次都得重新学一下退化
本文总阅读量次