1. 介绍¶
本文使用Kaggle的Deepfake比赛数据集,使用CNN+LSTM架构,对视频帧做二分类,该项目部署在百度的aistudio上进行训练。
2. 确定整体架构¶
- 首先是对视频进行抽帧,并将抽帧图片保存至文件夹内。
- 其次是对视频帧截取人脸,这里我直接使用了paddlehub的预训练人脸检测模型
- 删除图片数量过少的文件夹,一开始我们保存了15帧图片,我们最后模型是使用10帧,而经过人脸检测模型,有些图片检测不到人脸,因此就不会截取出来。我们会写一个代码删除掉人脸图片少于10的文件夹
- 数据装载器,不同于以往的CNN数据装载器,由于我们要输入到RNN,是以一个序列输入,因此这里我们要额外增加一个维度,形如(batch, timestep, channel, height, width),也就是将一个文件夹里的10张图片作为一个batch。
- CNN卷积网络,这里使用的是EfficientNet,我是针对pytorch版本改写得到的
- LSTM网络,这里我用的是卷积版本的LSTM,同样也是由pytorch版本改写得来(
https://github.com/ndrplz/ConvLSTM_pytorch) - 网络训练代码
- 网络验证代码
3. 生成数据¶

第一步是解压我们的数据集,然后是针对视频进行抽帧,这里我们的策略是从0到中间位置随机选取起始帧,每隔2帧进行帧的抽取。这里我们使用的是cv2库里的VideoCapture函数,参数是视频位置,返回一个视频流对象,然后我们调用set方法获取指定视频帧,最后以 视频文件名_标签_帧数的格式保存截图文件。并且由于样本极度不平均(真:假=4:1),我加入了一个下采样,进行样本平衡,使得真假视频比例维持在1比1,具体代码位于SaveFrameImage.py。

你可以在代码里面修改你想保存图片至指定的文件夹路径
我们需要生成训练集和验证集,因此我们后续修改文件夹名字为validate_frame_image。验证集所需图片数量不需要太多,我们运行一段时间可以通过上面的中断按钮,终止验证集图片生成。
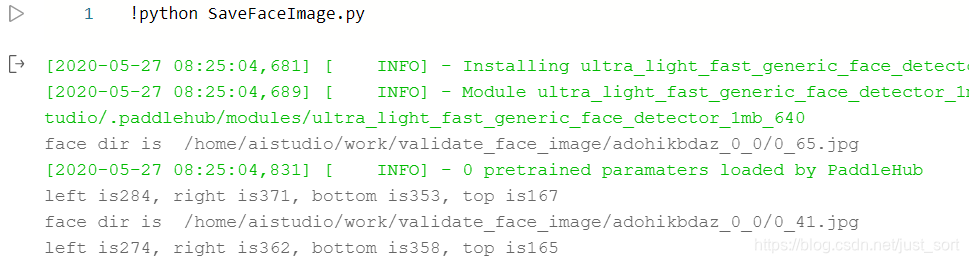
接着是安装paddlehub的人脸检测模型

创建文件夹face_image和validate_face_image,通过指定SaveFaceImage.py里面的文件夹名字,分别对视频帧进行人脸检测,并截取人脸图片保存至刚刚我们创建的文件夹中
4. 图片筛选¶
由于存在人脸漏检的情况,我们这里运行testScript.py 将少于10张图片的文件夹删除掉
这里使用的是shutil.rmtree模块
5. 数据装载器¶
5.1 数据增强¶
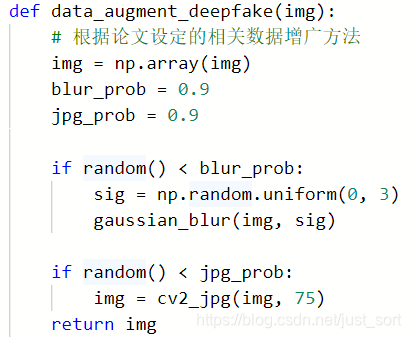
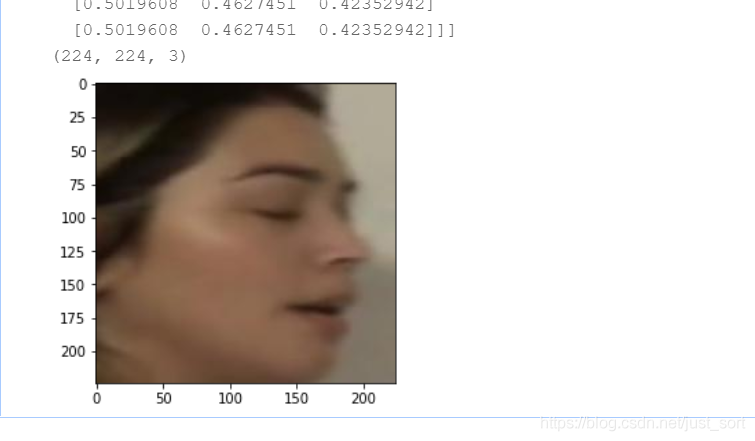
我们使用了之前论文里面提到的JPEG+Blur的图像预处理方法,resize图片至224x224分辨率,最后做归一化
5.2 数据生成器¶
我们通过文件名,将文件夹的人脸帧,按照帧位置进行排序

然后装进10x3x224x224的nparray当中
同理把标签装进nparray当中,大小为1
最后将人脸图片以及标签添加至列表,组合成一个batch,通过yield关键字转化成生成器,减少内存占用
最后我们测试一下数据生成器以及图像增广是否正确
6. 网络架构¶
6.1 EfficientNet¶
这里我采用的是EfficientNetB0结构,网络主体是EfficientNet.py,网络相关参数和其他操作是在model_utils.py文件里
6.2 LSTM¶
这里使用的是卷积版本的LSTM,相关代码在convlstm.py当中
7. 组合模型¶
这里采用的是CNN+全连接层+LSTM+两层全连接层的架构
具体代码在CNNRNNModel2.py当中
在CNNEncoder这个类中,我们的前向传播函数与传统CNN的有些区别
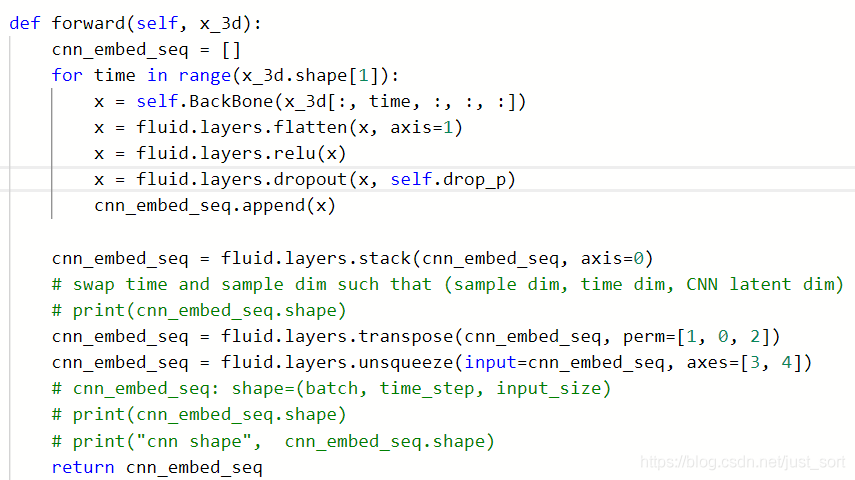
输入形如(batch, timestep, channel, height, width)
我们先根据时间步维度,对每一批做卷积,卷积的结果再调用stack函数堆叠到batch维度,由于使用了flatten函数,我们卷积结果会损失两个维度,为了输入进后续的RNN中,我们使用unsqueeze函数增加两个维度

我们这里设置LSTM隐层数为256,由于将视频抽取10帧,因此最后输出为10x256=2560
最后通过两次全连接层
这里使用shape为2x10x3x224x224的nparray进行测试
8. 训练¶
这里以batch=8,优化器为Adam(学习率=0.0001),采用交叉熵损失函数训练200轮

可以看到loss还是下降的很快的,如果发现准确率不变可能是初始化问题,重新启动一下训练程序即可
9. 验证¶
我们调用eval.py文件,后面跟网络权重名字,对模型进行测试
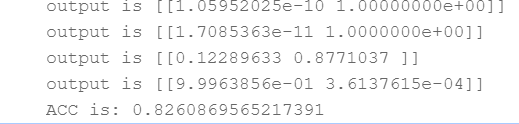
在20多条数据中,准确率接近83%,我们的模型还有很大的改进空间
10. 总结¶
这是我第一次做Kaggle的比赛,比赛期间提交失败,后续这几个月才弄出来。期间也踩了许多坑,改了很多Bug,以下几点是我的经验
- 通过可视化查看图像预处理是否正确
- 搭建好CNN,最好先放到一个简单的分类任务上,观察网络是否运行正确
- 搭建好整个模型,可以先在一个比较小的数据集上,调节学习率,batchsize等参数,以防后续训练不收敛无法定位问题
- 当代码没问题,模型运行结果不正确,比如每次运行eval.py所得的结果不一样,那么最好是查查是不是某些API被框架废弃不使用
- 结构越复杂效果不一定越好,为了更好泛化需要一定程度上减小模型复杂度
- 如果模型收敛不明显,可以对各个神经层进行参数初始化,初始化不同收敛快慢也不同
最后是项目地址
https://aistudio.baidu.com/aistudio/projectdetail/316583
本文总阅读量次