CVPRW22|《Underwater Light Field Retention : Neural Rendering for Underwater Imaging》¶
论文链接:https://arxiv.org/abs/2203.11006 代码链接:https://github.com/Ephemeral182/UWNR
GiantPandaCV成员做的一点小工作~目前已经CVPR 2022 Workshop接收~ 当时做这个工作主要的motivation如下: * 基于物理模型的水下图像生成方法效果并不理想,视觉效果差。 * 在RGB图像的channel和spatial层面同时模拟水下退化不均匀分布特性。 * 高分辨率图像的实时渲染是一个比较challenge的问题。
————————————————————————————
1. Introduction¶
水下图像的渲染(合成)可以应用于各种实际应用,例如水下图像增强、相机滤镜和虚拟游戏,且对目前获取水下数据集的成本相对高昂,特别是水下成对数据集的ground-truth大多数都是由算法生成的,这会造成一定的偏差。因此我们旨在用干净的图像来生成逼真的水下图像,我们探讨了水下图像渲染中两个关注点不高但具有挑战性的问题,即 (1) 如何通过单个神经网络渲染不同的水下场景? (2) 如何从自然样本中自适应地学习水下光场,即真实的水下图像?我们设计了一个基于水下光场保留的水下神经渲染架构(UWNR)来解决以上问题。
水下图像的成像公式可以表达如下:
文章的主要工作: \bullet 我们开发了一种自然光场保留模块,借助我们提出的水下暗通道损失和光场一致性损失,将地面图像的特征尽可能接近水下情况。
\bullet 据我们所知,这是第一个在没有物理模型和 GAN 方法的情况下渲染水下图像的工作,可以轻松渲染逼真的风格多样的水下图像。
\bullet 我们进行了广泛的实验来证明我们的方法在客观评价方面实现了最先进的渲染性能。
\bullet 我们我们利用我们方法(UWNR)合成了一个大型的神经渲染水下数据集(LNRUD),其中包含大量由陆地干净图像合成的水下图像。
2. Method¶
Overall Architecture¶
我们的UWNR架构在训练阶段采用Paired的图像进行训练,在渲染(推理)阶段从任意选择一张干净图像和一张水下图像便可以生成逼真的水下图像,总体流程图如下图所示
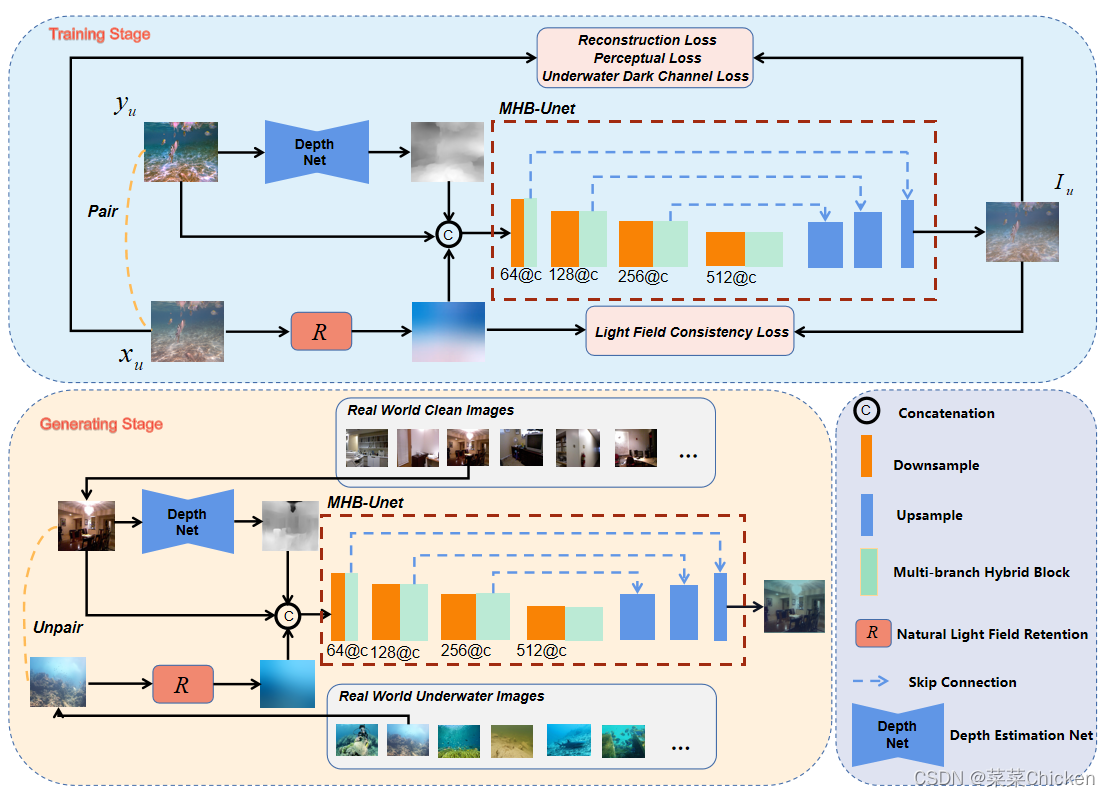
Natural Light Field Retention¶
考虑到introduction中的两个问题,根据水下图像的成像公式我们可以发现有三个关键的参数需要估计( i.e, d(x), \beta, B(x) ),水下环境复杂多样,难以准确的cover他们,因此我们设计了一个光场保留模块来获取水下的光信息。
根据Retinex理论,我们将水下图像分解为照明光 x_{l} 和物体信息光 x_{r} :
我们运用多尺度高斯低通滤波来获取水下图像光场:
同时考虑到高斯滤波器可能仍然包含物体细节,我们将其转换为对数域并对其进行缩放以得到最终的水下光场图:
水下光场图中的保留特征侧重于不同水下场景的自然风格信息,而尽可能忽略原始水下图像的详细的结构化信息。 理论上,水下光场图包含两个用于水下特征传递的重要信息: B(x) 和 \beta 。 之前的方法忽略了 \beta 对于水下成像的重要性,我们的方法集中在使用纠缠方式对上述两个系数进行隐式估计。效果图如下所示

Underwater Image Generation Module¶
Depth Estimation Network¶
获得了光场信息之后,另一个关键的因素是深度信息。考虑到RGBD获取的难度,我们并不需要配对的RGBD图像,我们运用pre-trained的深度预测模型1进行协同工作,以提高了适用性。
ulti-branch Hybrid Unet (MHB-Unet)¶
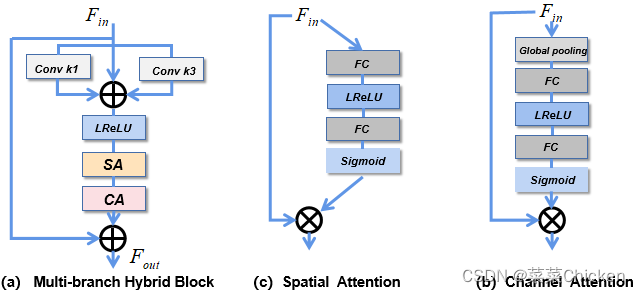
对于网络结构的设计,我们采用ED结构来抽取特征并进行图像的重建,在下采样层后面我们添加了一个多分支混合block,考虑到水下场景的局部特征复杂多样,我们首先通过1×1和3×3卷积得到不同的感受野,进行多重特征融合。 同时,我们还使用了残差连接,可以解决梯度消失的问题,并考虑到水下图像中某些区域的空间结构和颜色不受场景退化的影响。 在多分支融合之后,我们应用了空间注意模块如图 (b)和通道注意模块如图(c)的组合。 空间注意力机制提高了网络对水下图像中光场分布、深度信息等复杂区域的关注能力,通道注意力机制则关注网络对特征中重要通道的表达,从而提高整体模型的表达性能。我们的模型在推理渲染1024 \times 1024的图片时仅需要0.0023s,可以快速生成大量图片。
Training Losses¶
Underwater Dark Channel Loss¶
对于水下图像的合成,其要符合水下的统计特性,UDCP2将暗通道先验原理应用于水下。 我们定义了一个水下暗通道损失,使生成的水下图像与干净图像在暗通道层面一致:
水下暗通道损失表达如下:
Light Field Consistency Loss¶
为了有效保持真实水下图像的光场特性,我们引入了基于自然光场图的光场一致性损失,以获得更好的渲染性能。 我们利用多尺度高斯滤波器来捕获光场图:
光场一致性损失表示如下:
除此之外我们使用了感知损失和L1重建损失来进行pixel级别的监督,总的损失表达如下:
3.Experiment¶
在实验部分我们采用 FID3 评估度量来客观地评估我们生成的图像的效果,然后我们采用 PSNR、SSIM 和 UIQM 度量来衡量我们生成的水下图像数据集与其他水下图像生成方法相比对水下增强网络Shallow uwnet4的效果。

除此之外我们还在论文和补充材料中展示了大量的Vsual Comparison:


在最后我们利用我们的UWNR方法创建了一个大型水下合成数据集包含由5000张真实水下图像合成的5w张合成水下数据集,具体数据集可以在github中找个链接,以下放几张效果图

Authors: Tian Ye†(集美大学 本科三年级), Sixiang Chen†(集美大学 本科三年级), Yun Liu(西南大学), Erkang Chen(集美大学)*, Yi Ye, Yuche Li(中国石油大学)
参考:¶
本文总阅读量次