【GiantPandaCV导语】这里主要是走读了一下TVM的Codegen流程,从Relay的前端一直梳理到了Graph节点的内存分配,Relay IR到TIR节点的转换,TIR图节点的Schedule优化以及Lower function发生在哪里。这篇文章只是关注了调用链,一些具体的操作比如Schedule的优化,IR到TIR节点的转化以及Lower Function没有具体解释,后面会结合更多实例去尝试理解。
0x0. 介绍¶
这篇文章主要是来介绍一下TVM的CodeGen流程。TVM自动代码生成的接口是tvm.build和tvm.relay.build,tvm.build是用来做算子的代码生成,而tvm.relay.build是用来做relay计算图的自动代码生成(这里代码生成已经包含了编译流程)。接下来我们就从这两个函数讲起,一直到TVM的Codegen的具体实现。阅读这篇文章之前建议先了解一下TVM的编译流程,即看一下【从零开始学深度学习编译器】六,TVM的编译流程详解 这篇文章。
0x1. 如何查看生成的代码¶
对于Relay要查看生成的代码示例如下:
from tvm import relay
from tvm.relay import testing
import tvm
# Resnet18 workload
resnet18_mod, resnet18_params = relay.testing.resnet.get_workload(num_layers=18)
with relay.build_config(opt_level=0):
graph, lib, params = relay.build_module.build(resnet18_mod, "llvm", params=resnet18_params)
# print relay ir
print(resnet18_mod.astext(show_meta_data=False))
# print source code
print(lib.get_source())
TVM给运行时Module提供了get_source来查看生成的代码,同时通过IRModule的astext函数可以查看ir中间描述。由于这里产生的的是指定设备(CPU)上的可运行的机器码,不具有可读性,就不贴了。
我们可以基于算子的自动代码生成例子来直观的感受TVM生成的代码是什么样子,因为在tvm.build接口中,target可以设置为c,即生成C语言代码。例子如下:
import tvm
from tvm import te
M = 1024
K = 1024
N = 1024
# Algorithm
k = te.reduce_axis((0, K), 'k')
A = te.placeholder((M, K), name='A')
B = te.placeholder((K, N), name='B')
C = te.compute(
(M, N),
lambda x, y: te.sum(A[x, k] * B[k, y], axis=k),
name='C')
# Default schedule
s = te.create_schedule(C.op)
ir_m = tvm.lower(s, [A, B, C], simple_mode=True,name='mmult')
rt_m = tvm.build(ir_m, [A, B, C], target='c', name='mmult')
# print tir
print("tir:\n", ir_m.astext(show_meta_data=False))
# print source code
print("source code:\n",rt_m.get_source())
生成的TIR和Source Code如下:
tir:
#[version = "0.0.5"]
primfn(A_1: handle, B_1: handle, C_1: handle) -> ()
attr = {"global_symbol": "mmult", "tir.noalias": True}
buffers = {C: Buffer(C_2: Pointer(float32), float32, [1024, 1024], []),
B: Buffer(B_2: Pointer(float32), float32, [1024, 1024], []),
A: Buffer(A_2: Pointer(float32), float32, [1024, 1024], [])}
buffer_map = {A_1: A, B_1: B, C_1: C} {
for (x: int32, 0, 1024) {
for (y: int32, 0, 1024) {
C_2[((x*1024) + y)] = 0f32
for (k: int32, 0, 1024) {
C_2[((x*1024) + y)] = ((float32*)C_2[((x*1024) + y)] + ((float32*)A_2[((x*1024) + k)]*(float32*)B_2[((k*1024) + y)]))
}
}
}
}
/* For debugging purposes the metadata section has been omitted.
* If you would like to see the full metadata section you can set the
* option to `True` when invoking `astext`.
*/
source code:
// tvm target: c -keys=cpu -link-params=0
#define TVM_EXPORTS
#include "tvm/runtime/c_runtime_api.h"
#include "tvm/runtime/c_backend_api.h"
#include <math.h>
void* __tvm_module_ctx = NULL;
#ifdef __cplusplus
extern "C"
#endif
TVM_DLL int32_t mmult(void* args, void* arg_type_ids, int32_t num_args, void* out_ret_value, void* out_ret_tcode, void* resource_handle) {
void* arg0 = (((TVMValue*)args)[0].v_handle);
int32_t arg0_code = ((int32_t*)arg_type_ids)[(0)];
void* arg1 = (((TVMValue*)args)[1].v_handle);
int32_t arg1_code = ((int32_t*)arg_type_ids)[(1)];
void* arg2 = (((TVMValue*)args)[2].v_handle);
int32_t arg2_code = ((int32_t*)arg_type_ids)[(2)];
void* A = (((DLTensor*)arg0)[0].data);
void* arg0_shape = (((DLTensor*)arg0)[0].shape);
void* arg0_strides = (((DLTensor*)arg0)[0].strides);
int32_t dev_id = (((DLTensor*)arg0)[0].device.device_id);
void* B = (((DLTensor*)arg1)[0].data);
void* arg1_shape = (((DLTensor*)arg1)[0].shape);
void* arg1_strides = (((DLTensor*)arg1)[0].strides);
void* C = (((DLTensor*)arg2)[0].data);
void* arg2_shape = (((DLTensor*)arg2)[0].shape);
void* arg2_strides = (((DLTensor*)arg2)[0].strides);
if (!(arg0_strides == NULL)) {
}
if (!(arg1_strides == NULL)) {
}
if (!(arg2_strides == NULL)) {
}
for (int32_t x = 0; x < 1024; ++x) {
for (int32_t y = 0; y < 1024; ++y) {
((float*)C)[(((x * 1024) + y))] = 0.000000e+00f;
for (int32_t k = 0; k < 1024; ++k) {
((float*)C)[(((x * 1024) + y))] = (((float*)C)[(((x * 1024) + y))] + (((float*)A)[(((x * 1024) + k))] * ((float*)B)[(((k * 1024) + y))]));
}
}
}
return 0;
}
直观的了解了一下TVM的代码生成接口(tvm.build和tvm.relay.build)之后,我们可以借助https://zhuanlan.zhihu.com/p/139089239这篇文章中总结的TVM的代码生成过程的流程图来更好的理解。
原文中的介绍是:
tvm代码生成接口上是IRModule到运行时module的转换,它完成tir或者relay ir到目标target代码的编译,例如c或者llvm IR等。下面的流程图描述整个代码的编译流程,深色表示C++代码,浅色表示python代码。算子编译时会首先进行tir的优化,分离出host和device部分,之后会调用注册的target.build.target函数进行编译。relay图编译相比算子稍微复杂一点,核心代码采用C++开发。它会通过relayBuildModule.Optimize进行relay图优化,之后针对module中的每个lower_funcs进行编译,合成最终的运行时module,其后部分的编译流程和算子编译相似。
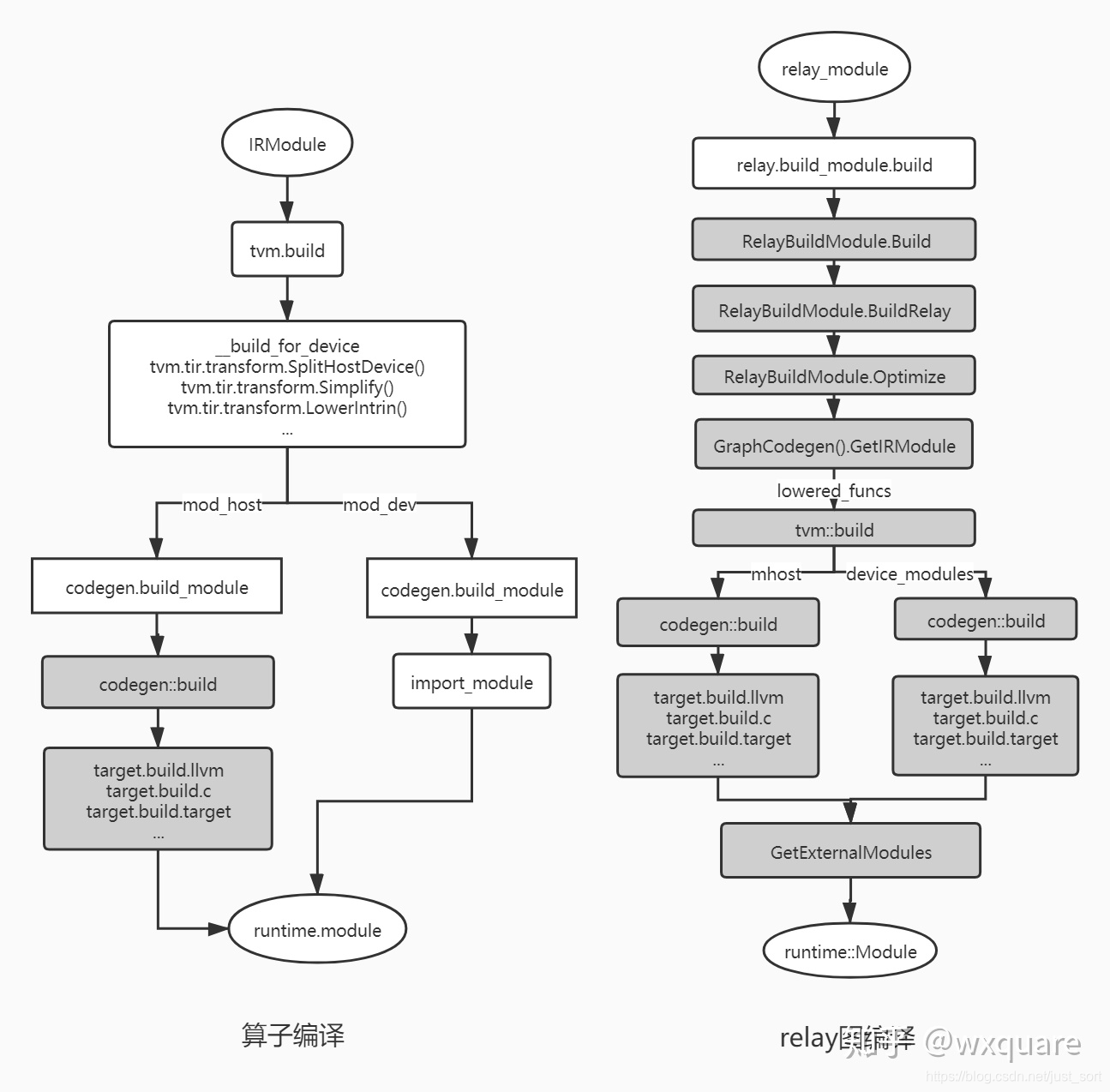
看上面的个流程图可以直观理解一下TVM Codegen的流程,这里以Relay为例子,在TVM的代码中简单的来对应一下。在上面的右图中展示了Relay Graph的完整编译流程,其中GraphCodeGen之前的部分我们已经在【从零开始学深度学习编译器】六,TVM的编译流程详解 讲过了,这里直接从创建GraphCodegen实例(graph_codegen_ = std::unique_ptr<GraphCodegen>(new GraphCodegen());)开始来梳理一下GraphCodegen的流程。这部分的代码如下:
void BuildRelay(IRModule relay_module,
const std::unordered_map<std::string, tvm::runtime::NDArray>& params) {
Target target_host = GetTargetHost();
// If no target_host has been set, we choose a default one, which is
// llvm if "codegen.LLVMModuleCreate" is accessible.
const runtime::PackedFunc* pf = runtime::Registry::Get("codegen.LLVMModuleCreate");
if (!target_host.defined()) target_host = (pf != nullptr) ? Target("llvm") : Target("stackvm");
// Update all the targets in the targets_ TargetsMap
CheckAndUpdateHostConsistency(&targets_, &target_host);
// Relay IRModule -> IRModule optimizations.
relay_module = Optimize(relay_module, targets_, params);
// Get the updated function.
auto func = Downcast<Function>(relay_module->Lookup("main"));
// Generate code for the updated function.
graph_codegen_ = std::unique_ptr<GraphCodegen>(new GraphCodegen());
graph_codegen_->Init(nullptr, targets_);
graph_codegen_->Codegen(func);
ret_.graph_json = graph_codegen_->GetJSON();
ret_.params = graph_codegen_->GetParams();
auto lowered_funcs = graph_codegen_->GetIRModule();
// Generate a placeholder function that attaches linked params as its arguments.
if (target_host->GetAttr<Bool>("link-params").value_or(Bool(false))) {
CHECK(pf != nullptr) << "Unable to link-params with no target_host and no llvm codegen.";
auto param_ids = graph_codegen_->GetParamIds();
auto link_params = Map<String, tir::LinkedParam>();
for (auto param : ret_.params) {
link_params.Set(param.first, tir::LinkedParam(param_ids[param.first], param.second));
}
Map<String, ObjectRef> dict;
dict.Set(tvm::tir::attr::kLinkedParams, link_params);
dict.Set(tvm::attr::kGlobalSymbol, String(::tvm::runtime::symbol::tvm_lookup_linked_param));
DictAttrs attrs{dict};
auto prim = tir::PrimFunc(Array<tir::Var>(), tir::SeqStmt(Array<tir::Stmt>()), VoidType(),
Map<tir::Var, tir::Buffer>(), attrs);
if (lowered_funcs.find(target_host->str()) == lowered_funcs.end()) {
lowered_funcs.Set(target_host->str(), IRModule(Map<GlobalVar, BaseFunc>({})));
}
lowered_funcs[target_host->str()]->Add(
GlobalVar(::tvm::runtime::symbol::tvm_lookup_linked_param), prim);
}
// When there is no lowered_funcs due to reasons such as optimization.
if (lowered_funcs.size() == 0) {
if (target_host.defined() && target_host->kind->name == "llvm") {
// If we can decide the target is LLVM, we then create an empty LLVM module.
ret_.mod = (*pf)(target_host->str(), "empty_module");
} else {
// If we cannot decide the target is LLVM, we create an empty CSourceModule.
// The code content is initialized with ";" to prevent complaining
// from CSourceModuleNode::SaveToFile.
ret_.mod = tvm::codegen::CSourceModuleCreate(";", "", Array<String>{});
}
} else {
ret_.mod = tvm::build(lowered_funcs, target_host_);
}
auto ext_mods = graph_codegen_->GetExternalModules();
ret_.mod = tvm::codegen::CreateMetadataModule(ret_.params, ret_.mod, ext_mods, GetTargetHost());
}
首先这里创建了一个GraphCodegen对象,其中GraphCodegen这个结构体的定义在tvm/src/relay/backend/build_module.cc中的struct GraphCodegen部分,它封装了tvm/src/relay/backend/graph_executor_codegen.cc中GraphExecutorCodegenModule的几个和Codegen有关的函数,如init,codegen,get_graph_json,get_external_modules等等。例如初始化函数init的实现如下:
class GraphExecutorCodegenModule : public runtime::ModuleNode {
public:
GraphExecutorCodegenModule() {}
virtual PackedFunc GetFunction(const std::string& name, const ObjectPtr<Object>& sptr_to_self) {
if (name == "init") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
ICHECK_EQ(args.num_args, 2) << "The expected of arguments are: "
<< "runtime::Module mod and Map<int, Target> targets";
void* mod = args[0];
Map<Integer, tvm::Target> tmp = args[1];
TargetsMap targets;
for (const auto& it : tmp) {
auto dev_type = it.first.as<tir::IntImmNode>();
ICHECK(dev_type);
targets[dev_type->value] = it.second;
}
codegen_ = std::make_shared<GraphExecutorCodegen>(reinterpret_cast<runtime::Module*>(mod),
targets);
});
}
... 省略
const char* type_key() const final { return "RelayGraphExecutorCodegenModule"; }
private:
std::shared_ptr<GraphExecutorCodegen> codegen_;
LoweredOutput output_;
};
这个初始化函数就是通过mod和target生成了一个GraphExecutorCodegen对象,GraphExecutorCodegen这个类的定义如下(省略版):
/*! \brief Code generator for graph executor */
class GraphExecutorCodegen : public backend::MemoizedExprTranslator<std::vector<GraphNodeRef>> {
public:
// 初始化的时候准备好了
GraphExecutorCodegen(runtime::Module* mod, const TargetsMap& targets) : mod_(mod) {
compile_engine_ = CompileEngine::Global();
targets_ = targets;
}
LoweredOutput Codegen(relay::Function func) {
...
}
这个构造函数里面的compile_engine_ = CompileEngine::Global();创建了一个编译器实例,用于后面的代码生成任务,target则指定了目标设备。
/*! \brief cache entry used in compile engine */
class CompileEngine : public ObjectRef {
public:
CompileEngine() {}
explicit CompileEngine(ObjectPtr<Object> n) : ObjectRef(n) {}
CompileEngineNode* operator->() { return static_cast<CompileEngineNode*>(get_mutable()); }
using ContainerType = CompileEngineNode;
/*! \brief The global compile engine. */
TVM_DLL static CompileEngine& Global();
};
接下来,我们再回到GraphExecutorCodegenModule类,看一下codegen这部分具体的调用逻辑:
else if (name == "codegen") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
Function func = args[0];
this->output_ = this->codegen_->Codegen(func);
});
}
这里的Func是经过了一系列Pass优化之后的Relay Func,this->output_ = this->codegen_->Codegen(func);这里就调用了Graph Codegen的核心实现函数,我们在下一节讲。
0x2. Graph CodeGen 内存申请¶
现在让我们来认识一下GraphExecutorCodegen这个类的核心函数LoweredOutput Codegen(relay::Function func),这个函数实现了内存的分配,Relay IR节点到TIR节点的转换,TIR图节点的调度优化。我们再对照一下这个函数的代码来讲解:
LoweredOutput Codegen(relay::Function func) {
auto pf = GetPackedFunc("relay.backend.GraphPlanMemory");
storage_device_map_ = (*pf)(func);
// First we convert all the parameters into input nodes.
for (auto param : func->params) {
auto node_ptr = GraphInputNode::make_node_ptr(param->name_hint(), GraphAttrs());
var_map_[param.get()] = AddNode(node_ptr, param);
}
heads_ = VisitExpr(func->body);
std::ostringstream os;
dmlc::JSONWriter writer(&os);
GetJSON(&writer);
LoweredOutput ret;
ret.graph_json = os.str();
ret.params = std::unordered_map<std::string, std::pair<int, const tvm::runtime::NDArray>>();
for (auto param : params_) {
ret.params.emplace(std::make_pair(
param.first,
std::make_pair(static_cast<int>(param_storage_ids_[param.first]), param.second)));
}
Graph Codegen的第一步是内存申请,即下面两行代码做的事:
auto pf = GetPackedFunc("relay.backend.GraphPlanMemory");
storage_device_map_ = (*pf)(func);
然后跟进到GraphPlanMemory的定义,在tvm/src/relay/backend/graph_plan_memory.cc中定义如下:
Map<Expr, Array<IntegerArray> > GraphPlanMemory(const Function& func) {
return StorageAllocator().Plan(func);
}
StorageAllocator和StorageAllocaInit两个类的实现相关,StorageAllocaInit是用来创建封装内存申请信息的TokenMap,收集不同算子的设备信息。StorageAllocaInit的GetInitTokenMap构造函数是用来遍历func的节点,获得每个节点的设备属性。GetInitTokenMap构造函数的实现如下:
/*! \return The internal token map */
std::unordered_map<const ExprNode*, std::vector<StorageToken*> > GetInitTokenMap(
const Function& func) {
node_device_map_ = CollectDeviceInfo(func);
this->Run(func);
return std::move(token_map_);
}
首先调用了CollectDeviceInfo这个函数来获取func中每个节点的设备属性,它具体是怎么做的呢?我们可以从tvm/src/relay/transforms/device_annotation.cc这里的注释了解到这个思路:
/*
* \brief Return device allocation map based on the post order traversed graph.
* For the following program:
* .. code-block:: python
* x = relay.var("x")
* y = relay.var("y")
* add = relay.add(x, y)
* sqrt = relay.sqrt(add)
* log = relay.log(add)
* subtract = relay.subtract(sqrt, log)
* exp = relay.exp(subtract)
*
* Suppose we have annotated add, sqrt, and log with device 1, 2, and 3,
* respectively. The fallback/default device is 4. After Rewriting the
* program, we can have the following graph, where each copy op has both
* source and destination device type denoting which device the data should be
* copied from and to.
*
* x y
* \ /
* add/1
* / \
* copy1 copy2
* | |
* sqrt/2 log/3
* | |
* copy3 copy4
* \ /
* subtract
* |
* exp
*
* To Get the device mapping of each expression, we need to propagate the
* device information from the copy ops. This can be done in two passes.
* -Pass 1: Propagating the source device type to ops in a bottom-up way to the
* ancestors until encountering another copy op. For example, this way
* provides add, x, and y device types from the copy operator, `copy1`.
* -Pass 2: Propagating the destination device type of "the last" copy op to the
* remain nodes. For instance, this offers `subtract` and `exp` the
* same device type as `copy3`.
*/
这里解释一下这个例子,add,sqrt,log节点被标注为1,2,3号设备,那么可以用两种方式来推断其它节点设备号。
- 从一个copy节点由下而上遍历一直到遇到下一个copy,比如可以推断出add,x,y节点的设备号和copy1一样;
- 从最后一个copy节点向下遍历,那么可以推断出substract,exp设备号和copy3一样。
可以看到要获取func中每个节点的device信息主要是通过copy算子来进行推断,因为copy算子可以实现不同设备间的数据交换,这个和深度学习框架中的to类似。所以copy之后连接的算子就和这个copy算子具有相同的device信息。其实这里获取节点的device 信息也是一种Pass。在算法实现上继承了不少Pass Infra的东西,这里是通过从copy算子向前和向后遍历的方式来推断非copy节点的设备信息。具体的代码实现是:
static Map<Expr, Integer> GetDeviceMap(const Expr& expr) {
DeviceInfo device_info;
device_info.post_visitor_ = PostDfsOrderVisitor();
device_info.post_visitor_.Visit(expr);
if (device_info.post_visitor_.num_device_copy_ops_ > 0) {
device_info.PropagateDeviceId();
return device_info.device_map_;
} else {
return Map<Expr, Integer>();
}
}
这里首先运行了PostDfsOrderVisitor深度优先遍历来更新std::unordered_map<const ExprNode*, int> device_tag_;这个map,这个map会记录该节点是否存在相连的copy节点,为之后通过copy来推断节点设备信息使用。在深度优先遍历的过程中记录了copy节点的数量num_device_copy_ops_,当copy节点的数量大于0时执行PropagateDeviceId,
void PropagateDeviceId() {
int out_dev_type = post_visitor_.out_dev_type_;
for (auto& it : post_visitor_.device_tag_) {
if (it.second != -1) {
device_map_.Set(GetRef<Expr>(it.first), it.second);
} else {
device_map_.Set(GetRef<Expr>(it.first), out_dev_type);
}
}
}
通过这个函数,我们就可以获得copy之后节点的设备信息,收集完节点的设备信息之后返回device_info.device_map_,用于创建TokenMap。其中TokenMap中包含了节点的ttype,device_type的信息。具体实现如下,注意这个CreateToken函数是StorageAllocaInit这个类重载的基类StorageAllocaBaseVisitor的CreateToken虚函数。它只处理了节点的ttype,device_type信息。
void CreateToken(const ExprNode* op, bool can_realloc) final {
ICHECK(!token_map_.count(op));
std::vector<StorageToken*> tokens;
int device_type =
node_device_map_.count(GetRef<Expr>(op)) ? node_device_map_[GetRef<Expr>(op)]->value : 0;
if (const auto* tuple_type = op->checked_type().as<TupleTypeNode>()) {
for (Type t : tuple_type->fields) {
const auto* ttype = t.as<TensorTypeNode>();
ICHECK(ttype);
StorageToken* token = arena_->make<StorageToken>();
token->ttype = ttype;
token->device_type = device_type;
tokens.push_back(token);
}
} else {
const auto* ttype = op->checked_type().as<TensorTypeNode>();
ICHECK(ttype);
StorageToken* token = arena_->make<StorageToken>();
token->ttype = ttype;
token->device_type = device_type;
tokens.push_back(token);
}
token_map_[op] = tokens;
}
到这里,TokenMap的初始化完成。TokenMap初始化完成后会返回一个StorageToken列表,里面创建了Expr对应的Token,并对引用情况进行了计数,会记录各个OP的ttype。其中ttype对应OP的checked_type_属性。可以简单理解checked_type_是OP的部分属性集合,包含shape,数据类型等(对应上面代码中的if (const auto* tuple_type = op->checked_type().as<TupleTypeNode>())部分)。
接着,StorageAllocator类本身还要执行自己的CreateToken函数,这个函数给每个节点分配内存。TVM通过复用内存来优化内存申请。具体可以分成两种情况。
当can_realloc为真时,可以复用内存,调用Request函数来重新计算tok大小,然后将其push_back到tokens列表中。
// override create token by getting token as prototype requirements.
void CreateToken(const ExprNode* op, bool can_realloc) final {
ICHECK(!token_map_.count(op));
auto it = prototype_.find(op);
ICHECK(it != prototype_.end());
std::vector<StorageToken*> tokens;
for (StorageToken* tok : it->second) {
if (can_realloc) {
tokens.push_back(Request(tok));
} else {
// Allocate a new token,
StorageToken* allocated_tok = Alloc(tok, GetMemorySize(tok));
allocated_tok->device_type = tok->device_type;
// ensure it never get de-allocated.
allocated_tok->ref_counter += 1;
tokens.push_back(allocated_tok);
}
}
token_map_[op] = tokens;
}
这个prototype_是TokenMap创建时得到的ExprNode和std::vector<StorageToken*>的映射表。在StorageAllocaInit中只有CallNode 创建Token时,can_realloc会设置为True。然后我们先看一下can_realloc为False的时候的分支处理,主要是通过StorageToken* allocated_tok = Alloc(tok, GetMemorySize(tok));这个函数来生成新的StorageToken。GetMemorySize这个函数实现了Token的占用内存容量计算,代码实现如下:
size_t GetMemorySize(StorageToken* prototype) {
const TensorTypeNode* ttype = prototype->ttype;
ICHECK(ttype != nullptr);
size_t size = 1;
for (IndexExpr dim : ttype->shape) {
const int64_t* pval = tir::as_const_int(dim);
ICHECK(pval != nullptr) << "Cannot allocate memory symbolic tensor shape " << ttype->shape;
ICHECK_GE(*pval, 0) << "Cannot allocate memory for tensor with negative shape" << *pval;
size *= static_cast<size_t>(pval[0]);
}
size *= DivRoundUp(ttype->dtype.bits() * ttype->dtype.lanes(), 8);
return size;
}
这个函数先计算出元素个数,然后计算元素占用的空间(8字节对齐)。接着看Alloc的实现:
StorageToken* Alloc(StorageToken* prototype, size_t size) {
prototype->max_bytes = size;
prototype->storage_id = static_cast<int64_t>(data_.size());
data_.push_back(prototype);
return prototype;
}
可以看到Alloc函数,会将申请空间大小放入max_bytes字段。同时StorageToken中还有一个data_来记录经过处理后的StorageToken。Alloc完成之后还要更新StorageToken中的ref_counter字段,防止再次对当前这个Token申请内存。
接着来看一下can_realloc为True的分支,这里执行的是Request函数,这里会使用一个std::multimap<size_t, StorageToken*> free_;,默认为空的map。通过下面的函数插入元素到这个map,当前这里是在CallNode中调用的,因为只有CallNode才会将can_realloc设置为True。
// The call map
void VisitExpr_(const CallNode* op) final {
std::vector<StorageToken*> args;
// for each input, visit argument token.
for (Expr arg : op->args) {
for (StorageToken* tok : GetToken(arg)) {
args.push_back(tok);
}
}
// create token for the call node.
CreateToken(op, true);
// check if there is orphaned output that can be released immediately.
for (StorageToken* tok : token_map_.at(op)) {
CheckForRelease(tok);
}
for (StorageToken* tok : args) {
tok->ref_counter -= 1;
CheckForRelease(tok);
}
}
这个函数的最后一个for loop会对ref_counter进行减法操作,如果这个标志变量ref_counter被减到0了,那么就会将StorageToken加入free_列表中。然后我们具体看一下Request函数的实现:
StorageToken* Request(StorageToken* prototype) {
// calculate the size;
size_t size = GetMemorySize(prototype);
// search memory block in [size / match_range_, size * match_range_)
if (match_range_ == 0) {
return this->Alloc(prototype, size);
}
auto begin = free_.lower_bound(size / match_range_);
auto mid = free_.lower_bound(size);
auto end = free_.upper_bound(size * match_range_);
// search for memory blocks larger than requested
for (auto it = mid; it != end; ++it) {
StorageToken* tok = it->second;
if (tok->device_type != prototype->device_type) continue;
ICHECK_EQ(tok->ref_counter, 0);
// Use exect matching strategy
tok->max_bytes = std::max(size, tok->max_bytes);
tok->ref_counter = prototype->ref_counter;
// find a exact match, erase from map and return
free_.erase(it);
return tok;
}
// then search for memory blocks smaller than requested space
for (auto it = mid; it != begin;) {
--it;
StorageToken* tok = it->second;
if (tok->device_type != prototype->device_type) continue;
ICHECK_EQ(tok->ref_counter, 0);
// Use exect matching strategy
tok->max_bytes = std::max(size, tok->max_bytes);
tok->ref_counter = prototype->ref_counter;
// erase from map and return
free_.erase(it);
return tok;
}
// cannot find anything return a new one.
return this->Alloc(prototype, size);
}
这里默认match_range_等于16,先搜索free_列表中,size大于请求的StorageToken。如果没有大于Request大小的空闲块则反着找到最大的一块空闲的内存。个人理解这里的TokenMap处理流程就是将TokenMap创建的StorageToken复用,实现内存申请优化。最终返回一个data_列表记录需要申请的StorageToken。
执行完Token的处理之后,我们再回头到0x2节开头的auto pf = GetPackedFunc("relay.backend.GraphPlanMemory");
storage_device_map_ = (*pf)(func);,这样整个GraphCodegen的内存申请流程就梳理清楚了。再回顾一下GraphPlanMemory的Plan函数的实现,从Map<Expr, Array<IntegerArray> > smap;这行开始到结束,主要做了数据Copy,可以看到Plan函数最后会返回一个Expr和一个数组的映射表。数组里存放了data_对应的StorageToken索引和对应的设备type。最终在LoweredOutput Codegen(relay::Function func)的开头部分使用storage_device_map_记录内存申请的结果。
// Run storage allocation for a function.
Map<Expr, Array<IntegerArray> > Plan(const Function& func) {
prototype_ = StorageAllocaInit(&arena_).GetInitTokenMap(func);
this->Run(func);
// The value of smap contains two integer arrays where the first array
// contains the planned storage ids and the second holds the device types.
Map<Expr, Array<IntegerArray> > smap;
int num_annotated_nodes = 0;
int num_nodes = 0;
for (const auto& kv : token_map_) {
std::vector<Integer> storage_ids;
std::vector<Integer> device_types;
for (StorageToken* tok : kv.second) {
if (tok->device_type) {
num_annotated_nodes++;
}
num_nodes++;
storage_ids.push_back(tok->storage_id);
device_types.push_back(tok->device_type);
}
smap.Set(GetRef<Expr>(kv.first), Array<IntegerArray>({storage_ids, device_types}));
}
// Either all or none of the nodes should be annotated.
if (num_annotated_nodes != 0 && num_annotated_nodes != num_nodes) {
LOG(FATAL) << num_annotated_nodes << " out of " << num_nodes
<< "expressions are assigned with virtual device types. Either all "
"or none of the expressions are expected to be annotated.";
}
return smap;
}
0x3. Graph Codegen¶
在获得Relay Func中节点的内存申请结果之后,接着来看一下Graph Codegen,即LoweredOutput Codegen(relay::Function func)这个函数剩下的部分。首先是将IR的参数转换成输入节点:
// First we convert all the parameters into input nodes.
for (auto param : func->params) {
auto node_ptr = GraphInputNode::make_node_ptr(param->name_hint(), GraphAttrs());
var_map_[param.get()] = AddNode(node_ptr, param);
}
这里首先创建了一个GraphInputNode对象,这个对象继承自GraphNode对象,而GraphNode的定义如下,有name,num_outputs等节点属性:
/*! \brief Base Node class */
class GraphNode {
public:
GraphNode() {}
virtual void Save(dmlc::JSONWriter* writer) const {}
virtual void Load(dmlc::JSONReader* reader) {}
virtual GraphNodeType Type() const { return kGraphNop; }
virtual ~GraphNode() {}
public:
int num_outputs_{1};
std::string name_;
GraphAttrs attrs_;
};
其中GraphAttrs attrs_;的定义是using GraphAttrs = std::unordered_map<std::string, dmlc::any>;。
然后遍历func的parameters,parameters转换为GraphInputNode。具体操作流程是先为每个parameters创建了一个GraphInputNode节点,再调用make_node_ptr函数申请一块内存,最后通过AddNode函数将parameters转换为GraphInputNode并加入到节点列表nodes_中。
static std::shared_ptr<GraphNode> make_node_ptr(const std::string& name,
const GraphAttrs& attrs) {
auto ptr = std::make_shared<GraphInputNode>(name, attrs);
return std::dynamic_pointer_cast<GraphNode>(ptr);
}
nodes_的定义为:std::vector<GraphObjectPtr> nodes_;,它是GraphExecutorCodegen这个类的成员变量。AddNode主要是在给node(这里说的node是GraphInputNode)设置attrs_属性。具体包含:
- 内存申请时分配的StorageToken的id,对应
node->attrs_["storage_id"] - 记录node的device类型,这个参数在StorageToken计算过程中确定,对应
node->attrs_["device_index"] - 记录node的
shape和dtype,分别使用了_ShapeToJSON和DType2String来获取。
最后,AddNode返回了一个node的引用并将其添加到var_map_中,var_map_的定义为:std::unordered_map<const Object*, std::vector<GraphNodeRef>> var_map_;。至此,就完成了将Relay Func的参数转换成了GraphInputNode。
接下来是节点遍历,使用std::vector<GraphNodeRef> heads_;来记录Graph节点。这里是通过调用VisitExpr函数来完成func的遍历的,在遍历的时候会将func转换成graphNode。对于varNode来说,因为它已经被记录在了var_map_中,所以VarNode的VisitExpr_函数实现就是直接返回引用。ConstantNode会转换为GraphInputNode,TupleNode会返回每个字段的graphNode。在遍历节点过程中,会将graphNode都添加到nodes_中。特别关注一下CallNode的VisitExpr_,先截取前半部分代码:
Expr expr = GetRef<Expr>(op);
Function func;
if (op->op.as<OpNode>()) {
LOG(FATAL) << "Operators should be transformed away; try applying"
<< "the fuse_ops transformation to the expression.";
} else if (op->op.as<GlobalVarNode>()) {
LOG(FATAL) << "Not implemented";
} else if (op->op.as<FunctionNode>()) {
func = GetRef<Function>(op->op.as<FunctionNode>());
} else {
LOG(FATAL) << "TVM runtime does not support calls to " << op->op->GetTypeKey();
}
if (!func->HasNonzeroAttr(attr::kPrimitive)) {
LOG(FATAL) << "TVM only support calls to primitive functions "
<< "(i.e functions composed of fusable operator invocations)";
}
这里可以看到CallNode走到编译,只支持OP是FunctionNode类型的,并且必须是经过融合的。我们之前讲过TVM的算符融合,里面也有提到这一点并针对这一点做了保护。算符融合中对FunctionNode做保护的代码如下:
Expr MakeNewFunction(GraphPartitioner::Group* group, Type ret_type, Expr body) {
// If the function has no call, it is not a primitive function.
struct HasCallVisitor : ExprVisitor {
bool has_call = false;
void VisitExpr_(const CallNode* op) final { has_call = true; }
} visitor;
visitor(body);
const GroupInfo& ginfo = ginfo_[group];
auto func = Function(ginfo.params, body, ret_type, {});
func = WithAttr(std::move(func), attr::kPrimitive, tvm::Integer(visitor.has_call));
return Call(func, ginfo.arguments, Attrs());
}
在这之后,就是CallNode的function生成部分了:
auto pf0 = GetPackedFunc("relay.backend._make_CCacheKey");
auto pf1 = GetPackedFunc("relay.backend._CompileEngineLower");
Target target;
// Handle external function
if (func->GetAttr<String>(attr::kCompiler).defined()) {
target = Target("ext_dev");
CCacheKey key = (*pf0)(func, target);
CachedFunc ext_func = (*pf1)(compile_engine_, key);
ICHECK(ext_func.defined()) << "External function is not defined.";
UpdateConstants(func, ¶ms_);
return GraphAddCallNode(op, ext_func->func_name, ext_func->func_name);
}
function生成时会走两个分支,一个是外部Function的codegen,一个是通用的Function的codegen。这里具体是通过func的attr::kCompiler来判定是否是外部codegen。
首先看对外部Function的处理,这里的relay.backend._make_CCacheKey和relay.backend._CompileEngineLower的定义如下。他们都实现在tvm/src/relay/backend/compile_engine.cc文件中。
CCacheKey::CCacheKey(Function source_func, Target target) {
auto n = make_object<CCacheKeyNode>();
n->source_func = std::move(source_func);
n->target = std::move(target);
data_ = std::move(n);
}
CachedFunc Lower(const CCacheKey& key) { return LowerInternal(key)->cached_func; }
这里首先创建一个CCacheKey类型作为_CompileEngineLower函数的参数传入。_CompileEngineLower函数的实现在tvm/src/relay/backend/compile_engine.cc中。调用链为Lower->LowerInternal(key)->cached_func,在LowerInternal的实现中对应的代码段为:
// No need to lower external functions for now. We will invoke the external
// codegen tool once and lower all functions together.
if (key->source_func->GetAttr<String>(attr::kCompiler).defined()) {
auto cache_node = make_object<CachedFuncNode>();
const auto name_node = key->source_func->GetAttr<String>(tvm::attr::kGlobalSymbol);
ICHECK(name_node.defined()) << "External function has not been attached a name yet.";
cache_node->func_name = std::string(name_node.value());
cache_node->target = Target("ext_dev");
cache_node->funcs->Add(GlobalVar(cache_node->func_name), key->source_func);
value->cached_func = CachedFunc(cache_node);
return value;
}
如果是外部Function的Codegen,定义了一个cache_node,并将其封装成CachedFunc并返回。然后再通过GraphAddCallNode将器加入到nodes_中。在GraphAddCallNode中还执行了对op->args的深度优先遍历。
std::vector<GraphNodeRef> GraphAddCallNode(const CallNode* op, const std::string& op_name,
const std::string& func_name) {
std::vector<GraphNodeRef> inputs;
for (auto arg : op->args) {
auto res = VisitExpr(arg);
for (auto nr : res) {
inputs.push_back(nr);
}
}
auto node = GraphOpNode::make_node_ptr(op_name, GraphAttrs(), func_name, inputs, GraphAttrs());
return AddNode(node, GetRef<Expr>(op));
}
这样通过VisterExpr的遍历,就将各个节点转化成了对应的GraphNode并加入到了nodes_列表中。
接着看一下内存Function的Codegen,这里省掉了target的判断部分简化程序:
CCacheKey key = (*pf0)(func, target);
CachedFunc lowered_func = (*pf1)(compile_engine_, key);
if (!lowered_funcs_.count(target->str())) {
lowered_funcs_[target->str()] = IRModule(Map<GlobalVar, BaseFunc>({}));
}
lowered_funcs_[target->str()]->Update(lowered_func->funcs);
return GraphAddCallNode(op, _GetUniqueName(lowered_func->func_name), lowered_func->func_name);
也是通过相同的pf0和pf1函数。CcacheKey的创建过程一样,但是在lowerInternal中处理过程不一样,内部Function的处理在LowerInternal函数的实现代码中对应了:
// Enforce use the target.
With<Target> target_scope(key->target);
ICHECK(!value->cached_func.defined());
auto cfunc = CreateSchedule(key->source_func, key->target);
auto cache_node = make_object<CachedFuncNode>(*(cfunc.operator->()));
// Skip lowering for device copy node.
const Expr body = (key->source_func)->body;
if (const CallNode* call_node = body.as<CallNode>()) {
if (call_node->attrs.as<DeviceCopyAttrs>()) {
value->cached_func = CachedFunc(cache_node);
return value;
}
}
cache_node->func_name = GetUniqueName(cache_node->func_name);
// NOTE: array will copy on write.
Array<te::Tensor> all_args = cache_node->inputs;
for (te::Tensor arg : cache_node->outputs) {
all_args.push_back(arg);
}
// lower the function
if (const auto* f = runtime::Registry::Get("relay.backend.lower")) {
cache_node->funcs = (*f)(cfunc->schedule, all_args, cache_node->func_name, key->source_func);
} else {
using tvm::transform::PassContext;
With<PassContext> fresh_pass_ctx_scope(PassContext::Create());
std::unordered_map<te::Tensor, tir::Buffer> binds;
cache_node->funcs = tvm::lower(cfunc->schedule, all_args, cache_node->func_name, binds);
}
value->cached_func = CachedFunc(cache_node);
return value;
TVM算子遵循调度和计算分离的法则,这里先看一下CreateSchedule的定义:
CachedFunc CreateSchedule(const Function& source_func, const Target& target) {
return ScheduleGetter(target).Create(source_func);
}
这里定义了一个ScheduleGetter来获取指定target的schedule。这个Create函数会完成IR到TIR节点的转化以及对Schedule的优化。这个函数非常复杂,能力有限,暂时读不进去了。在Creat函数中还有一个Lower function的生成过程,具体调用了runtime::Registry::Get("relay.backend.lower"))这个函数来执行操作。
0x4. 总结¶
读到这里这篇文章就可以结束了,这里主要是走读了一下TVM的Codegen流程,从Relay的前端一直梳理到了Graph节点的内存分配,Relay IR到TIR节点的转换,TIR图节点的Schedule优化以及Lower function发生在哪里。这篇文章只是关注了调用链,一些具体的操作比如Schedule的优化,IR到TIR节点的转化以及Lower Function没有进一步读下去。
0x5. 同期文章¶
- 【从零开始学深度学习编译器】番外二,在Jetson Nano上玩TVM
- 【从零开始学深度学习编译器】八,TVM的算符融合以及如何使用TVM Pass Infra自定义Pass
- 【从零开始学深度学习编译器】七,万字长文入门TVM Pass
- 【从零开始学深度学习编译器】六,TVM的编译流程详解
- 【从零开始学深度学习编译器】五,TVM Relay以及Pass简介
- 【从零开始学深度学习编译器】番外一,Data Flow和Control Flow
- 【从零开始学深度学习编译器】四,解析TVM算子
- 【从零开始学TVM】三,基于ONNX模型结构了解TVM的前端
- 【从零开始学深度学习编译器】二,TVM中的scheduler
- 【从零开始学深度学习编译器】一,深度学习编译器及TVM 介绍
0x6. 参考¶
本文总阅读量次