NAS-RL(ICLR2017)¶
谷歌最早发表的有关NAS的文章,全称Neural Architecture Search with Reinforcement Learning
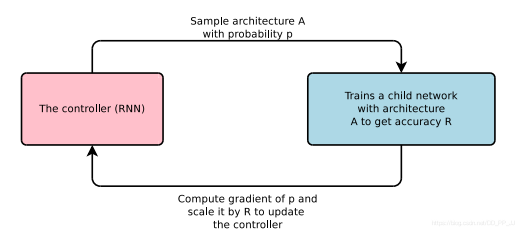
神经网络架构搜索经典范式是,首先通过controller以p概率采样一个网络结构,然后开始训练网络结构得到准确率R,根据准确率R和概率p可以使用梯度上升的方法更新controller的参数。
在NAS-RL中,使用了Policy Gradient算法来训练controller(通常实现是一个RNN或者LSTM)。训练完采样网络后在验证集上得到的准确率就是环境反馈的奖励值Reward,根据这个Reward可以通过梯度优化的方法得到最优的RNN和网络结构。
1.1 网络结构的表示¶
在神经网络搜索中,controller生成了一系列代表结构的超参数(tokens)。
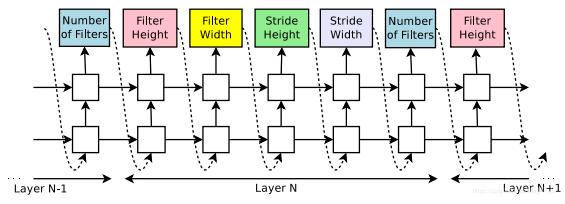
上图展示了一个RNN生成超参数的详细过程,每五个输出结果组成一个Layer,每个Layer中
包含了一个卷积所需要的参数,主要包含:
- 卷积核高
- 卷积核宽
- Stride高
- Stride宽
- 滤波器个数
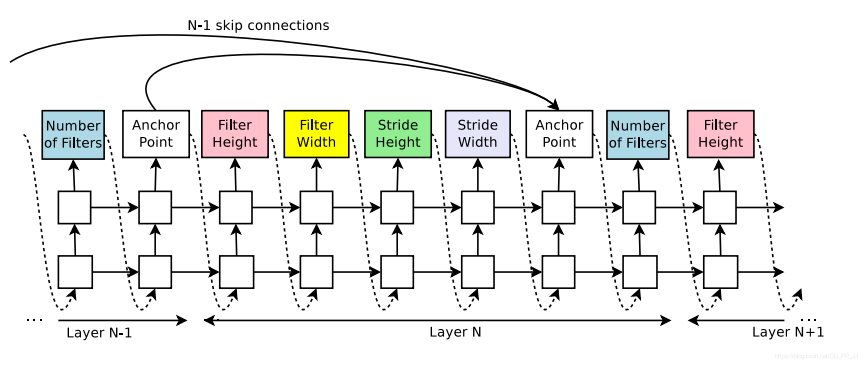
如果想要加上类似ResNet的skip connection结构,可以引入Anchor Point进行指向:
1.2 用REINFORCE进行训练¶
Controller预测的一系列tokens可以被视为一系列Action a_{1:T} , 根据token可以得到对应的网络结构,在训练集上训练生成的结构,在验证集上得到准确率 R, 相当于得到了奖励Reward,根据奖励值可以使用强化学习方法训练Controller。
将目标函数如下:
目标函数的意义是,在当前一系列Action并且Controller的参数为\theta_c的情况下,希望得到的奖励R的期望尽可能大。而R是不可微的,所以只能采用迭代的方式逼近最优结果。
R的表达式:\bar{R}_{\theta}=\sum_{\tau} R(\tau) p_{\theta}(\tau), 其中\tau代表一系列Action。
对\theta进行求偏导得到以下结果:
在本问题中,如果对J(\theta_c)进行求导,得到以下结果:
可以用以下式子进行近似:
虽然上式是梯度的无偏估计,但是方差比较大,所以添加一个baseline b:
1.3 并行训练¶
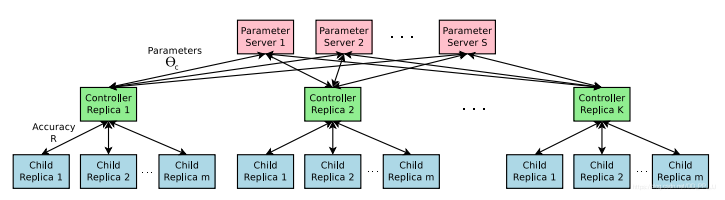
为了加速训练过程,采用了parameter-server机制,一共有S个参数服务器,保存的是K个Controller的复制,每个复制品会采样m个不同的子结构,这样可以同时进行训练,然后每个Controller收集m个子结构得到的梯度,然后将更新结果提交到参数服务器。
1.4 RNN的结构生成¶
RNN和LSTM都是接收x_t和h_{t-1}作为输入,得到输出h_t结果。可以将这个过程看作一个树,控制器RNN需要去标记每个节点的具体方法,比如加法、乘法、激活函数等,来合并两个输入得到一个输出结果。受LSTM的启发,引入c_{t-1}表示记忆状态。
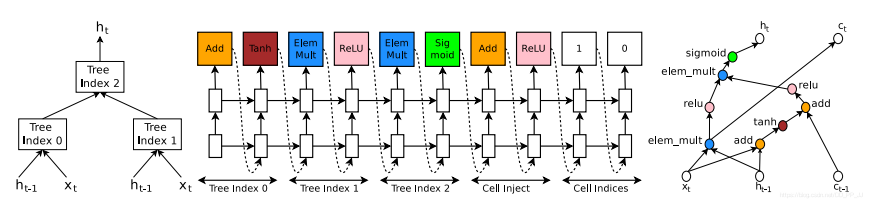
对照图很容易理解,需要解释的就是Cell Inject和Cell Indices,首先看最后的输出0,这代表需要计算Tree Index 0输出结果,具体计算方法是Cell Inject决定的;倒数第二个预测为1,这代表c_t的输出由Tree Index1的输出决定。
1.5 实验结果¶
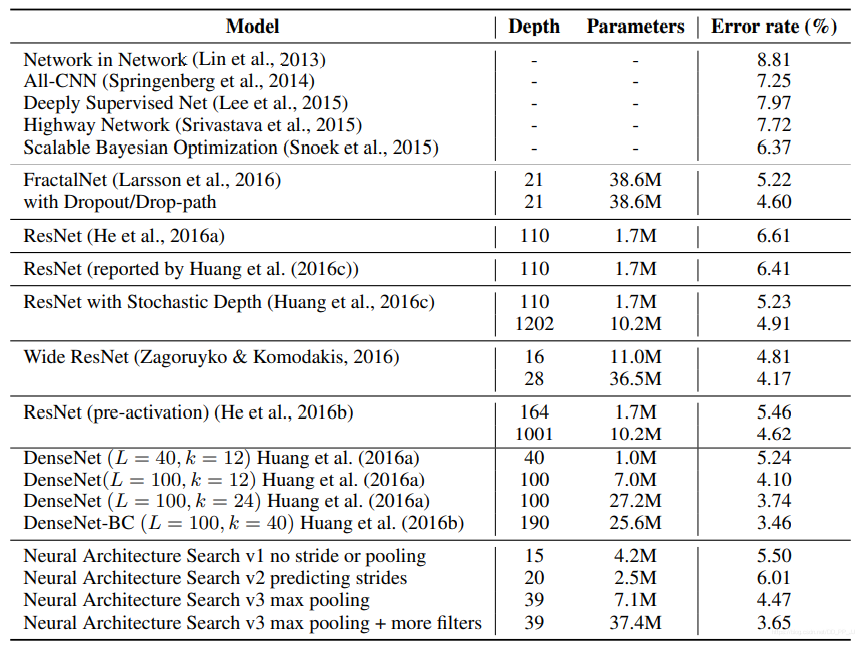
在训练了12800个结构以后,找到了在验证集上最优的结构。然后使用grid search方法搜索学习率、weight decay、batchnorm epsilon和衰减学习率的epoch。
可以看出,结果上和人工设计的网络架构差距不是很大,另外一个特点是NAS-RL得到的网络深度都很浅,否则搜索空间会过大,组合爆炸。
参考¶
文章链接:https://arxiv.org/pdf/1611.01578.pdf
本文总阅读量次