本文构造了20个MLIR基础概念的问题以及使用OneFlow IR转换为Tosa IR的5个代码段来评测GPT4和Claude对于MLIR的掌握能力,我的结论是对于基础概念的理解Claude整体上和GPT4持平,而在阅读相关代码片段时Claude表现出了比GPT4更强一点的理解能力。
0x0. 前言¶
前面的文章中以Review一段MLIR相关的Pass代码为例子,对比了ChatGPT3.5,Claude,NewBing在该任务上的理解能力。我得出的结论是在该MLIR的相关任务上,Claude>ChatGPT3.5>>Newbing,评论区有人指出GPT4 >> Clude。我感觉上次的任务设计得不是特别好,并没有充分考察ChatGPT和Claude对MLIR的一些核心概念的理解。然后我今天借到了一个GPT4的官方账号 (daquexian 大老师提供的),我打算更全面的对比一下GPT4和Claude在对MLIR的掌握能力。接下来将从MLIR基础概念以及一个OneFlow IR转换为TOSA IR的任务出发,更全面的评价GPT4和Claude对于MLIR的掌握能力。
0x1. MLIR基础概念¶
Q1: MLIR中的IR是什么?为什么需要多层IR?
ChatGPT4的回答:
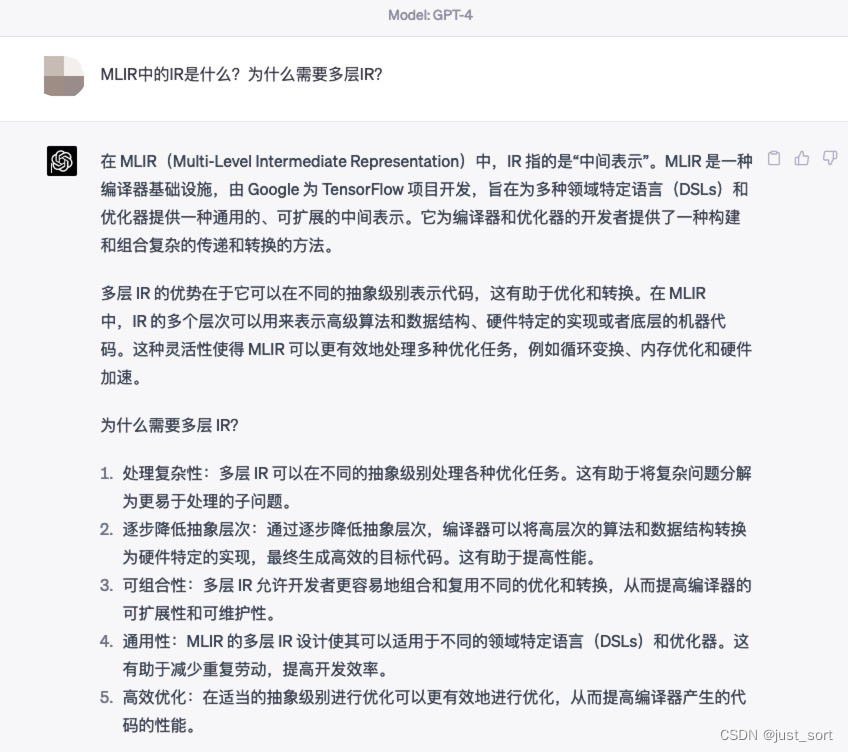
Claude回答:

对于MLIR中的IR是什么GPT4的回答更好一些,然后对于为什么需要多层IR这个问题Claude相比于GPT4更加细节一点。
Q2. 介绍一下MLIR Dialect的概念,并描述一下Dialect的相关组件。
GPT4:

Claude:

对于这个问题,GPT4的回答非常干净准确,而Claude虽然看起来更细节一些,但是总结得让人看起来很乱。
Q3: 在MLIR中如何定义和实现一个新的Dialect?
GPT4:
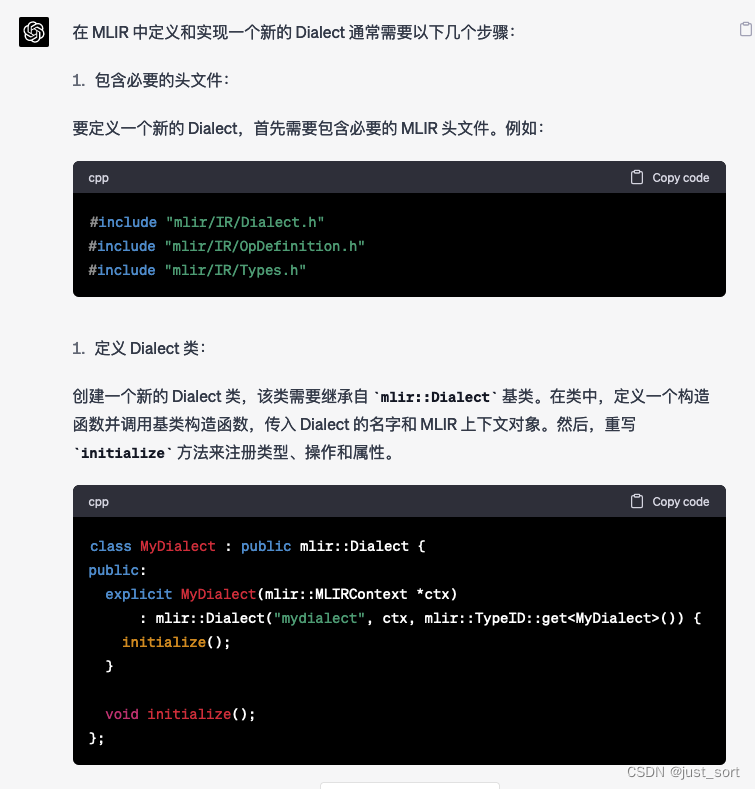
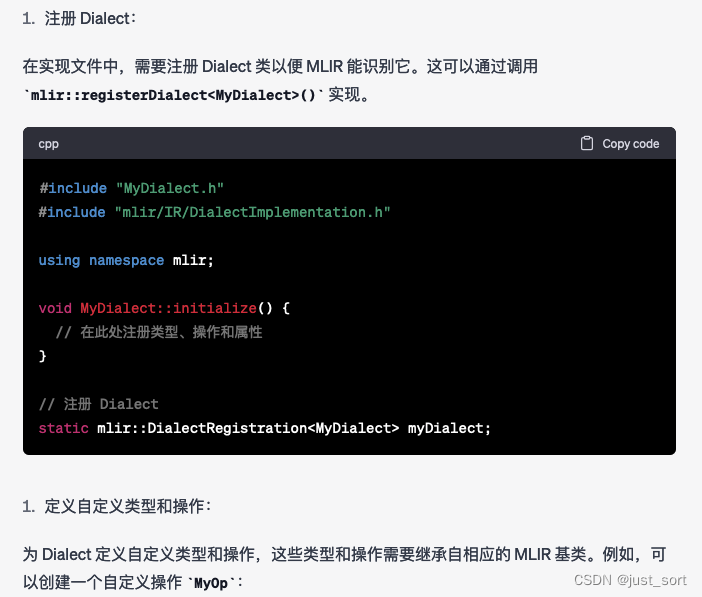
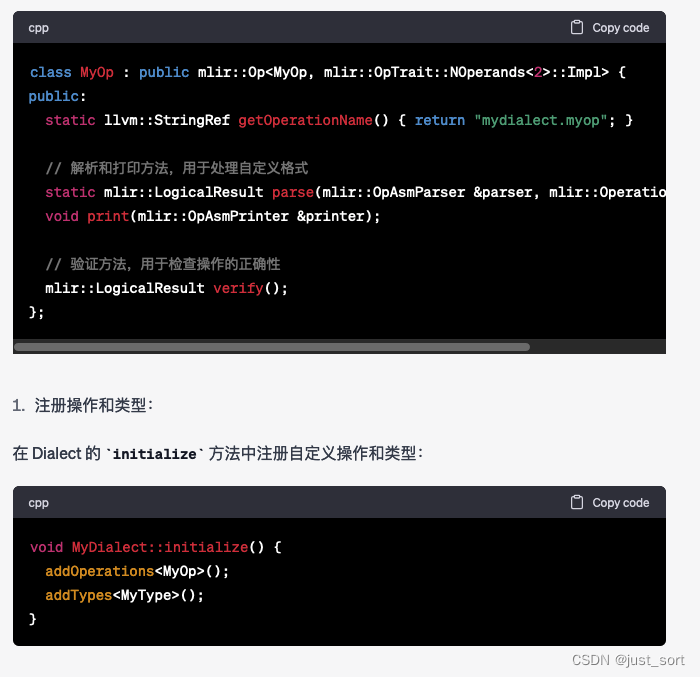


按照GPT4给出的步骤基本可以自定义一个Dialect以及相关的组件,不过现在一般对于Dialect以及Operation甚至Pass的定义都依靠了MLIR的ODS系统在相应的*.td文件中定义,并自动生成C++代码更加方便和通用。这里还可以发现GPT4在列举结果的时候,序号一直是1,并没有递增,不知道是不是BUG。
可以再看一下Claude的结果:


Claude的结果和GPT4的结果没有GPT4那么细节(比如GPT4把头文件的位置都列出来了),但是整体的步骤和GPT4基本一样,也算是比较好的理解了这个问题。
Q4: 介绍一下MLIR Dialect中的ModuleOp, FuncOp, Block
GPT4:
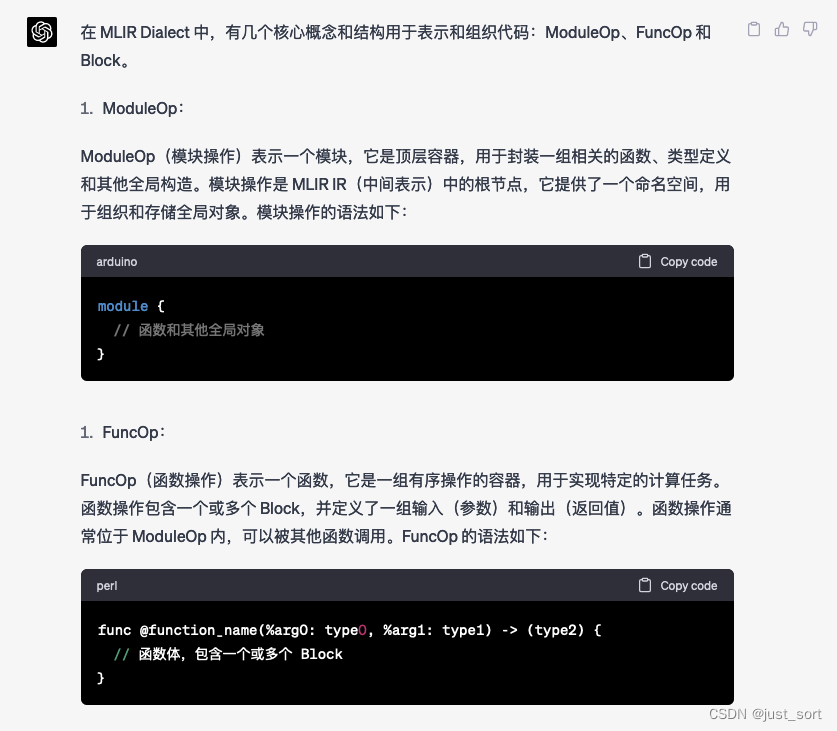
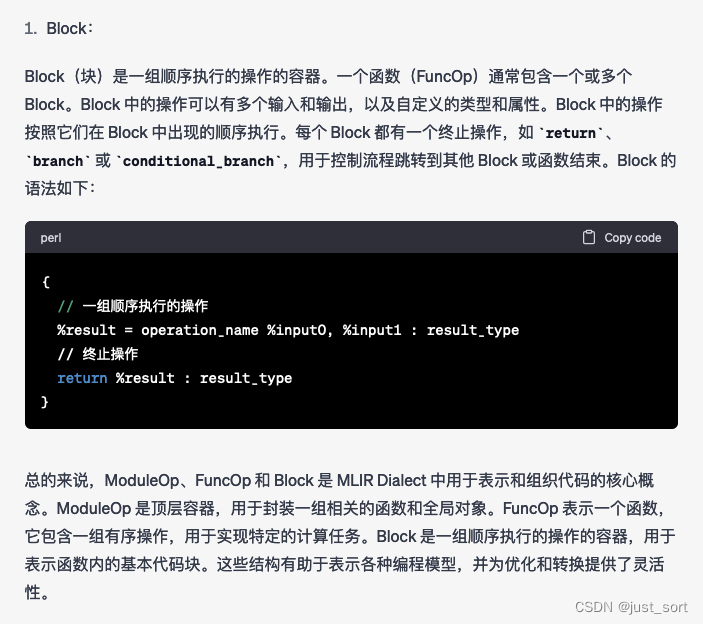
Claude:

GPT4的回答相比于Claude主要多了几个代码示例,但主体的内容两者是基本一样的。
Q5: 介绍一下MLIR Dialect中的Operation, Value, Type, Attribute
GPT4:


对概念的解释还是比较准确的,接下来看下Claude的结果:


对于这个问题,感觉Claude的回答是要比GPT4的回答好一点的。
为了进一步对比上述概念的理解,我们以MLIR的Toy Dialect示例中的transpose op定义为例,让GPT4和Claude分别详细解释下代码。
Q6: 详细解释下这行代码。%t_tensor = "toy.transpose"(%tensor) {inplace = true} : (tensor<2x3xf64>) -> tensor<3x2xf64> loc("example/file/path":12:1
GPT4:


Claude:


我们可以看到GPT4的源码分析更加细致,比如GPT4给我们解释了inplace的含义,但Claude并没有。
Q7:MLIR的Operation由Operation类和Op类的构成,请说一下它们的区别。 并说明一下ConstantOp和mlir::Operation *operation之间应该如何转换。
GPT4:

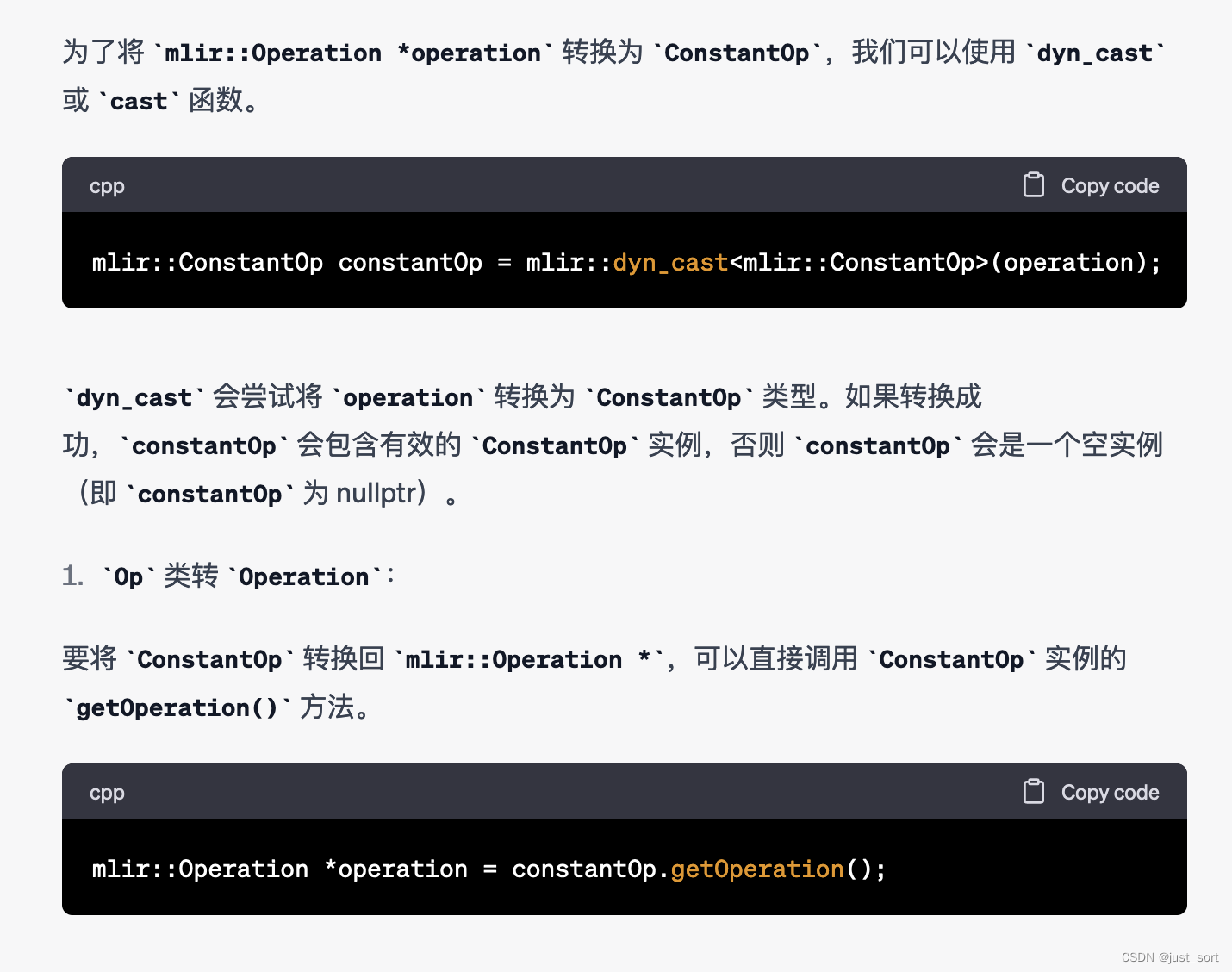

Claude:


GPT4和Claude的回答都还不错。
Q8:介绍一下MLIR Value的2个派生类BlockArgument和OpResult,并说明一下Value和mlir::Operantion *operation之间如何相互转换。

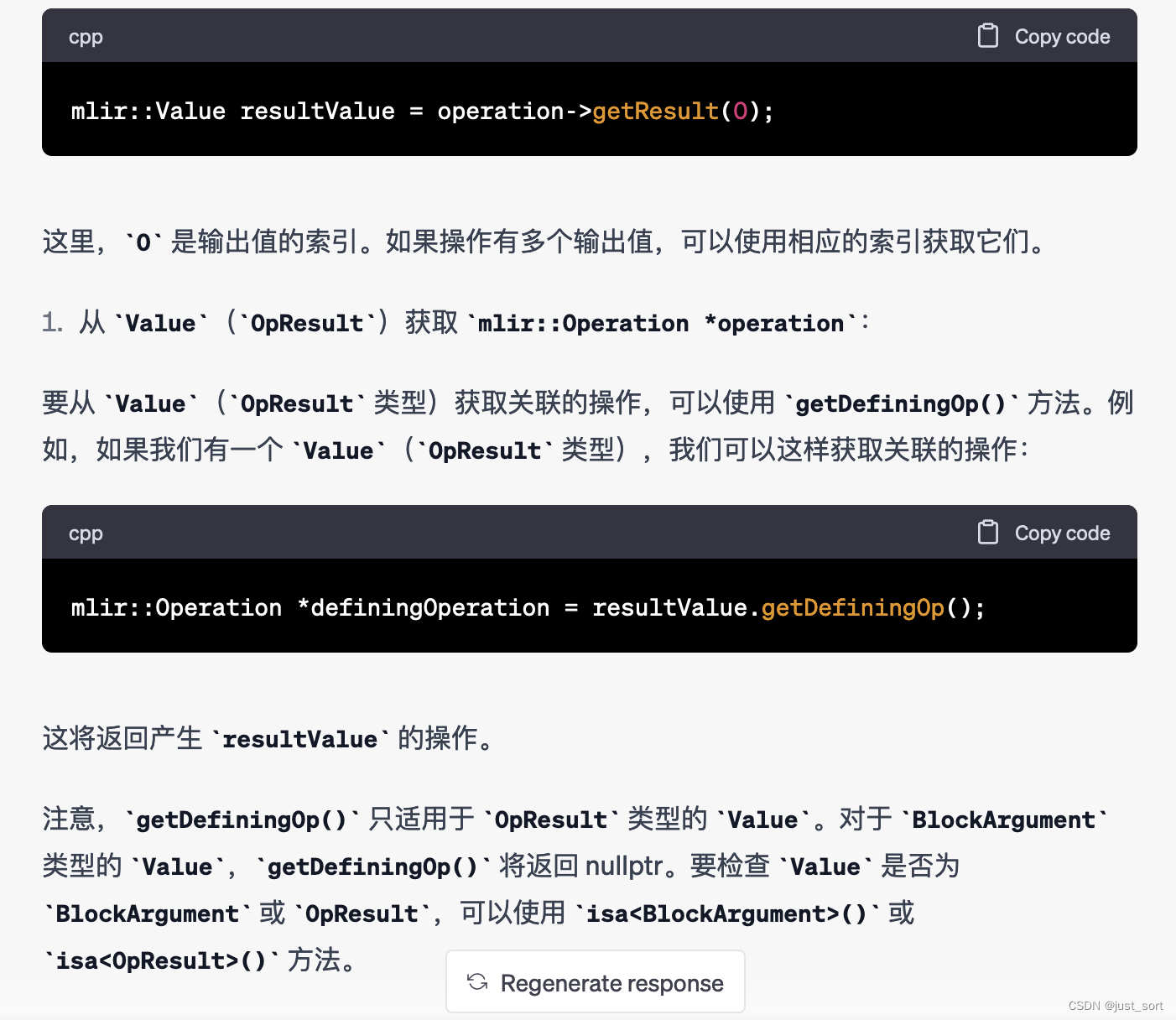

Claude:


对于Value的基础概念,GPT4和Claude都理解得不错。
Q9: 介绍一下mlir::Type,mlir::ShapedType以及mlir::TensorType
GPT4:


Claude:

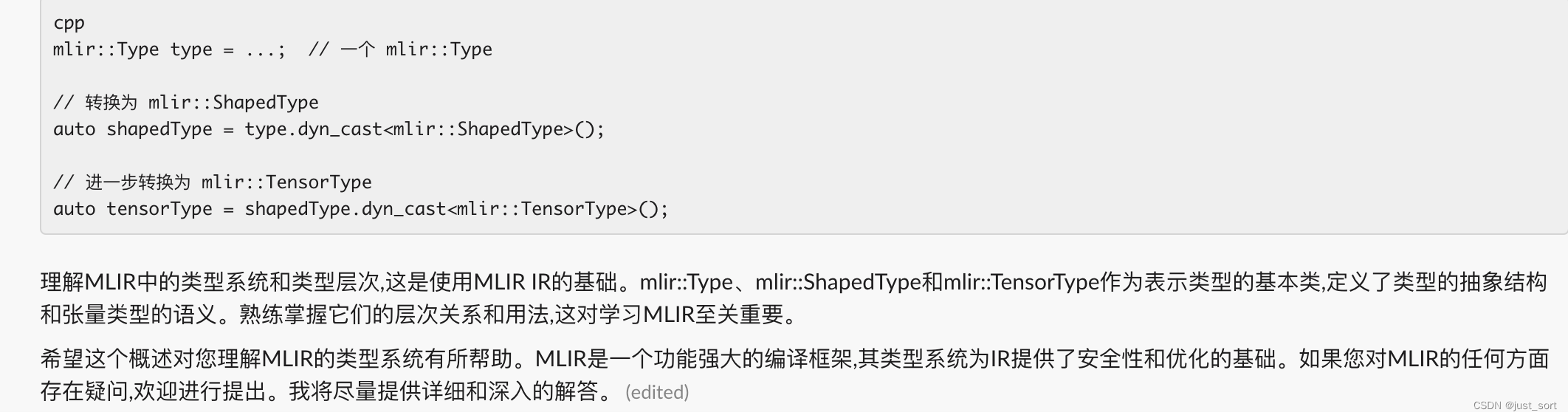
就这个回答来说,Claude的回答是超越了GPT4的。它不仅为我们解释了概念,还指出这三个Type的派生类之间应该如何转换。
Q10: TensorType又可以分成RankedTensorType和UnrankedTensorType,请说明一下它们的区别以及如何判断当前的TensorType是否是Ranked。
GPT4:


Claude:
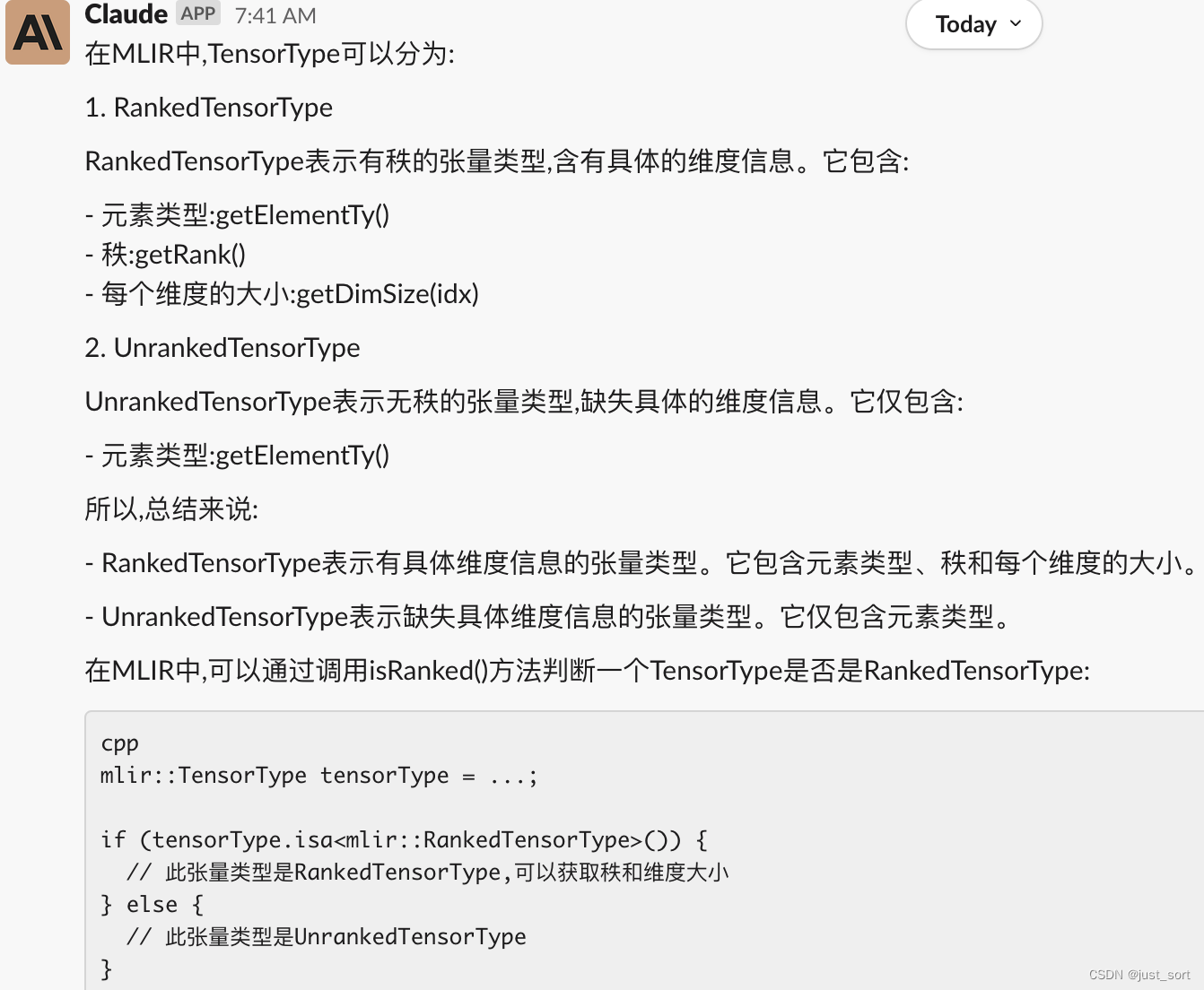
 相比于GPT4,针对这个问题Claude的回答显得更好一点。主要好在它列出了RankedTensorType和UnrankedTensorType的主要成员函数并做了对比。
相比于GPT4,针对这个问题Claude的回答显得更好一点。主要好在它列出了RankedTensorType和UnrankedTensorType的主要成员函数并做了对比。
Q11: 介绍一下MLIR的Attribute
GPT4:

 Claude:
Claude:


对于Attribute的解释,我感觉Claude也是比GPT4好一点。
Q12:介绍一下MLIR的Builder和OpBuilder。
GPT4:
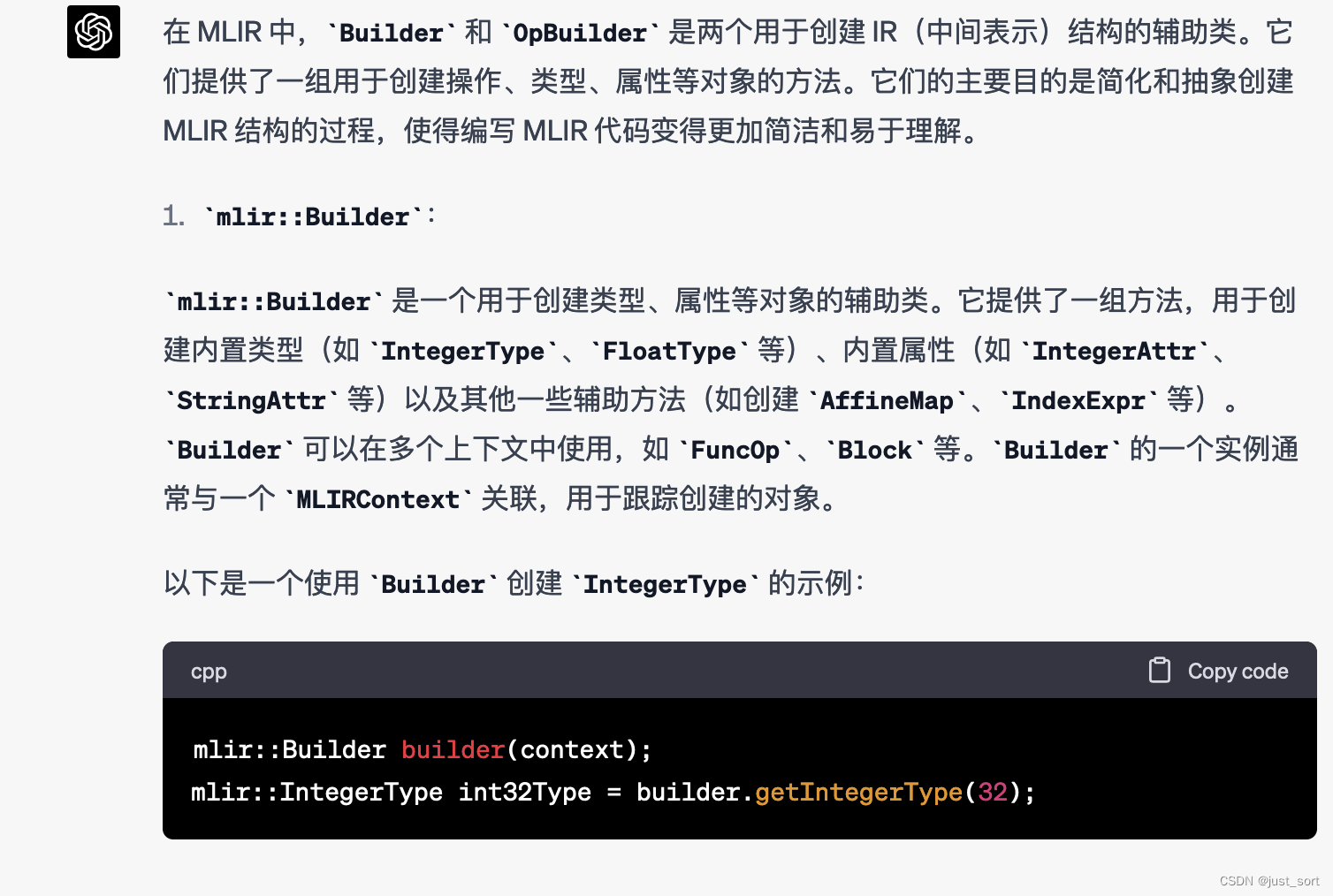
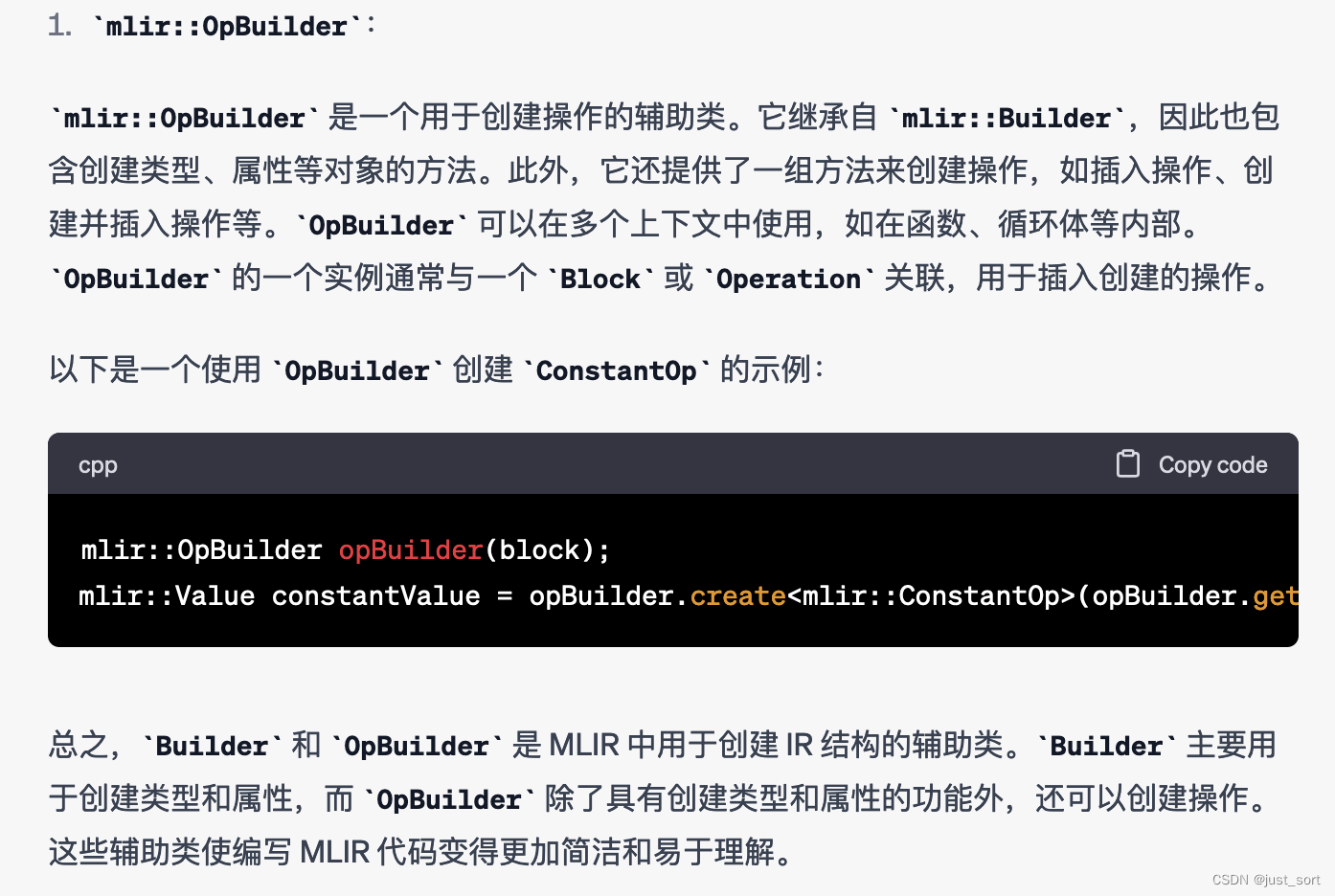 Claude:
Claude:
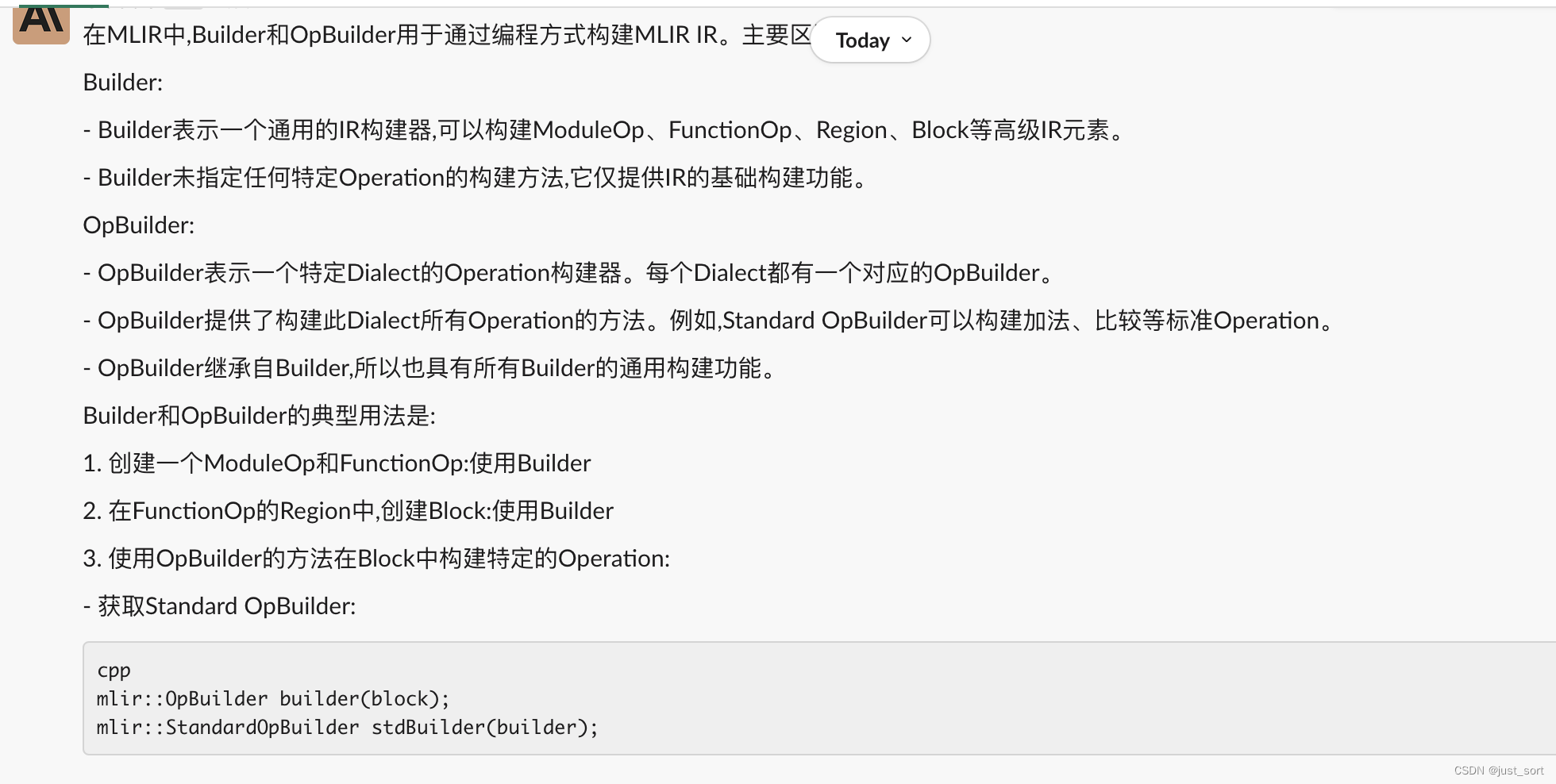

个人感觉GPT4和Claude的回答都不是很完善,如果综合一下GPT4和Claude的结果会更好,这个问题双方算是平手。
Q13: 介绍一下MLIR Context和Region
GPT4:

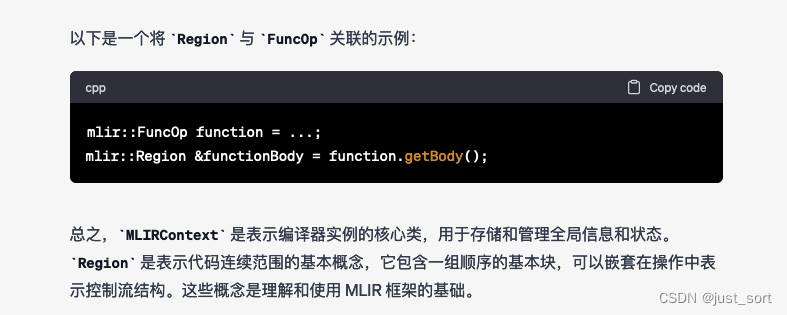
Claude:

这个问题的回答,感觉Claude更加准确,并且Claude指出了使用Context和Region的一般构建流程。
我们知道在MLIR中定义OP有2种方式,一种是直接在C++定义,另外一种是基于ODS进行定义。目前主流的做法就是基于ODS也就是在一个td文件中定义OP,然后利用TableGen自动生成相应的C++代码。MLIR在OpBase.td中已经定义了一些公共的结构,接下来我们就提问GPT4和Claude是否知道这些公共的结构。
Q14: MLIR的OpBase.td有哪些公共结构


Claude:

我期待的回答应该类似于:

显然,GPT4和Claude都没有给出理想的答案,而是随机挑选了一些OpBase.td定义的类,所以这个问题并没有很好的被语言模型理解。
Q15: 解释一下TF Dialect中对AvgPool Op使用ODS进行定义涉及到的TableGen语法,AvgPool Op定义的代码如下:
# https://github.com/tensorflow/tensorflow/blob/master/tensorflow/compiler/mlir/tensorflow/ir/tf_generated_ops.td#L965
def TF_AvgPoolOp : TF_Op<"AvgPool", [Pure]> {
let summary = "Performs average pooling on the input.";
let description = [{
Each entry in `output` is the mean of the corresponding size `ksize`
window in `value`.
}];
let arguments = (ins
Arg<TF_FloatTensor, [{4-D with shape `[batch, height, width, channels]`.}]>:$value,
ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$ksize,
ConfinedAttr<I64ArrayAttr, [ArrayMinCount<4>]>:$strides,
TF_AnyStrAttrOf<["SAME", "VALID"]>:$padding,
DefaultValuedOptionalAttr<TF_ConvnetDataFormatAttr, "\"NHWC\"">:$data_format
);
let results = (outs
Res<TF_FloatTensor, [{The average pooled output tensor.}]>:$output
);
TF_DerivedOperandTypeAttr T = TF_DerivedOperandTypeAttr<0>;
}
GPT4:

Claude:

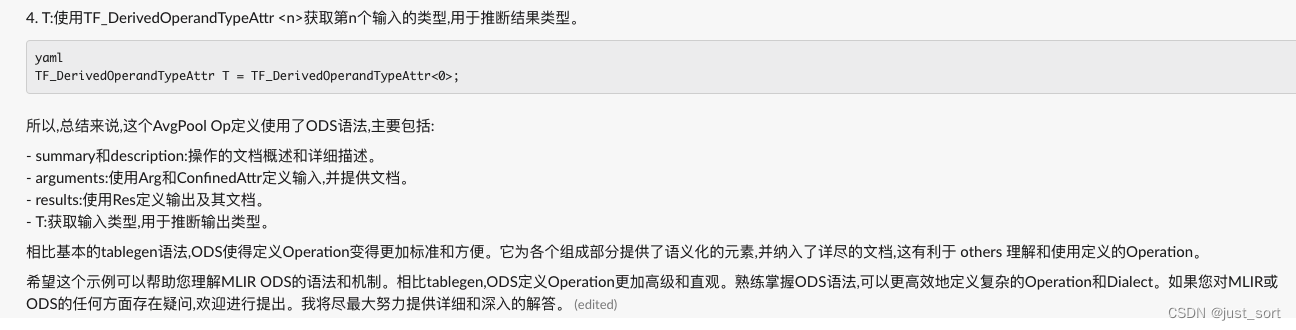
GPT4和Claude的结果比较类似,都是逐行解析了涉及到的TableGen语法。
Q16: 请解释一下MLIR中的Bufferization
GPT4:

Claude:


GPT4的回答宏观一些,Claude的回答更具体一些,都有优点。
Q17: 对于将分散的memref.alloc操作优化合并成单一的memref.alloc统一分配并通过类似memref.subview进行复用,你有什么建议吗,有现成的类似的pass实现吗
GPT4:


Claude:

对于这个问题,GPT4总结得比Claude更细一些。
Q18: 讲一下MLIR中One-Shot Bufferize设计的目的和目前成熟的应用
GPT4:

Claude:

两种回答差不多,不分高下。
Q19: https://mlir.llvm.org/docs/Bufferization/ 这个网页你能解读一下吗
GPT4:

Claude:

GPT4的总结稍微更贴合网页一些,但是自己去浏览网页可以发现还是有一些细节被漏掉了,如果要学习Bufferization还是建议去看下原始的网页。
Q20: 解释下linalg的算子融合算法
GPT4:
 Claude:
Claude:

对Linalg的学习有限,个人感觉这两个答案都是比较宏观的,需要查看Linalg的文档或者代码进一步获取相关信息。
上面一共问了20个问题,我个人感觉GPT4相比于Claude并没有很大的优势,我的初步结论是就MLIR的基础概念理解来看,GPT4和Claude几乎打成平手。
0x2. 代码阅读¶
这一节,我以OneFlow中的OneFlow Dialect中的Op转换为TOSA Dialect中的Op为例子,对比一下GPT4和Claude对相关代码的理解能力。这部分代码在 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/ir/lib/OneFlow/Conversion/OneFlowToTosa.cpp 这个c++文件中。
Code 1
解释一下
Type convertToSignless(MLIRContext* context, Type type) {
if (auto ranked_tensor = type.dyn_cast<RankedTensorType>()) {
if (auto intTy = ranked_tensor.getElementType().dyn_cast<IntegerType>()) {
if (!intTy.isSignless()) {
return RankedTensorType::get(
ranked_tensor.getShape(),
IntegerType::get(context, intTy.getWidth(),
mlir::IntegerType::SignednessSemantics::Signless));
}
}
}
return type;
}
FunctionType convertToSignlessFuncType(MLIRContext* context, FunctionType funcType) {
llvm::SmallVector<Type, 4> inputs;
llvm::SmallVector<Type, 4> results;
for (auto arg : funcType.getInputs()) { inputs.push_back(convertToSignless(context, arg)); }
for (auto res : funcType.getResults()) { results.push_back(convertToSignless(context, res)); }
return FunctionType::get(context, inputs, results);
}
GPT4:

Claude:

GPT4和Claude对这段代码的解释基本相同,并且都是正确的。
Code2 解释一下:
bool isSignLessTensorOrOther(Type type) {
if (auto ranked_tensor = type.dyn_cast<RankedTensorType>()) {
if (auto intTy = ranked_tensor.getElementType().dyn_cast<IntegerType>()) {
if (intTy.isUnsigned()) { return false; }
if (intTy.isSigned()) { return false; }
}
}
return true;
}
bool allSignless(mlir::TypeRange types) {
for (auto type : types) {
if (!isSignLessTensorOrOther(type)) { return false; }
}
return true;
}
bool allSignless(FunctionType funcType) {
for (auto arg : funcType.getInputs()) {
if (!isSignLessTensorOrOther(arg)) { return false; }
}
for (auto res : funcType.getResults()) {
if (!isSignLessTensorOrOther(res)) { return false; }
}
return true;
}
GPT4:

Claude:

GPT4和Claude的结果也比较类似,但Claude有个优点就是它对每个函数都给出了一个例子,可以帮助读者更方便的去理解这段代码的含义。
Code3
解释一下:
Value CreateTransposeValue(Location& loc, ConversionPatternRewriter& rewriter, Value input,
ArrayRef<int32_t> perms) {
int perms_size = perms.size();
auto transpose_perms = rewriter.create<tosa::ConstOp>(
loc, RankedTensorType::get({perms_size}, rewriter.getI32Type()),
rewriter.getI32TensorAttr(perms));
const auto shape_type = input.getType().cast<ShapedType>();
std::vector<int64_t> ranked_type;
for (const auto& index : perms) ranked_type.push_back(shape_type.getDimSize(index));
return rewriter.create<tosa::TransposeOp>(
loc, RankedTensorType::get(ranked_type, shape_type.getElementType()), input, transpose_perms);
};
RankedTensorType CreateTransposeType(ShapedType output, ArrayRef<int32_t> perms) {
std::vector<int64_t> ranked_type;
for (auto index : perms) ranked_type.push_back(output.getDimSize(index));
return RankedTensorType::get(ranked_type, output.getElementType());
};
GPT4:

Claude:

相比之下,感觉Claude的解释可以胜出。
Code4
解释一下:
Value CreateBNOp(Location loc, ConversionPatternRewriter& rewriter, Type output_type, Value x,
Value mean, Value variance, Value epsilon, Value gamma, Value beta) {
// sub_op = sub(input, mean)
auto sub_op0 = rewriter.create<tosa::SubOp>(loc, output_type, x, mean);
// add_op0 = add(var, epsilon)
auto add_op0 = rewriter.create<tosa::AddOp>(loc, variance.getType(), variance, epsilon);
// rsqrt_op = rsqrt(add_op0)
auto rsqrt_op = rewriter.create<tosa::RsqrtOp>(loc, variance.getType(), add_op0);
// op4 = mul(sub_op, rsqrt_op)
auto mul_op0 = rewriter.create<tosa::MulOp>(loc, output_type, sub_op0, rsqrt_op, 0);
// op5 = mul(mul_op0, gamma)
auto mul_op1 = rewriter.create<tosa::MulOp>(loc, output_type, mul_op0, gamma, 0);
// op6 = add(mul_op1, beta)
Value batch_norm = rewriter.create<tosa::AddOp>(loc, output_type, mul_op1, beta);
return batch_norm;
};
GPT4:

Claude:

感觉GPT4和Claude对代码的理解是一样的。
Code5
再看一个卷积Op,解释一下:
struct Conv2DOpLowering final : public OpConversionPattern<Conv2DOp> {
public:
using OpConversionPattern<Conv2DOp>::OpConversionPattern;
LogicalResult matchAndRewrite(Conv2DOp op, OpAdaptor adaptor,
ConversionPatternRewriter& rewriter) const override {
auto get_pair_int64_from_array = [](ArrayAttr arr) -> std::pair<int64_t, int64_t> {
return {arr.getValue()[0].cast<IntegerAttr>().getSInt(),
arr.getValue()[1].cast<IntegerAttr>().getSInt()};
};
auto stride_pairs = get_pair_int64_from_array(op.getStrides());
auto pad_pairs = get_pair_int64_from_array(op.getPaddingBeforeAttr());
auto dilation_pairs = get_pair_int64_from_array(op.getDilationRate());
const auto pad = rewriter.getDenseI64ArrayAttr(
{pad_pairs.first, pad_pairs.second, pad_pairs.first, pad_pairs.second});
const auto stride = rewriter.getDenseI64ArrayAttr({stride_pairs.first, stride_pairs.second});
const auto dilation =
rewriter.getDenseI64ArrayAttr({dilation_pairs.first, dilation_pairs.second});
auto bias = op.getBias();
auto loc = op.getLoc();
if (!bias) {
const auto output_shape = op.getOut().getType().cast<ShapedType>();
// support nhwc
const auto output_channels = output_shape.getDimSize(op.IsNCHW() ? 1 : 3);
const auto bias_elem_type = output_shape.getElementType();
const auto type = RankedTensorType::get(output_channels, bias_elem_type);
bias = rewriter.create<tosa::ConstOp>(
op.getLoc(), type, DenseElementsAttr::get(type, rewriter.getZeroAttr(bias_elem_type)));
}
auto in = op.getIn();
auto weight = op.getWeight();
auto out_type = op.getOut().getType().cast<ShapedType>();
if (out_type.getRank() != 4) {
LOG(FATAL) << "Failed to lowering oneflow op";
op->dump();
}
// support nhwc
if (op.IsNCHW()) {
const auto perms = {0, 2, 3, 1};
const auto reverse_perms = {0, 3, 1, 2};
in = CreateTransposeValue(loc, rewriter, in, perms);
weight = CreateTransposeValue(loc, rewriter, weight, perms);
out_type = CreateTransposeType(out_type, perms);
auto conv2d =
rewriter.create<tosa::Conv2DOp>(loc, out_type, in, weight, bias, pad, stride, dilation);
auto res = CreateTransposeValue(loc, rewriter, conv2d, reverse_perms);
rewriter.replaceOp(op, {res});
} else {
rewriter.replaceOpWithNewOp<tosa::Conv2DOp>(op, out_type, in, weight, bias, pad, stride,
dilation);
}
return success();
}
};
GPT4:

Claude:

我们再问一下,为什么format为"NHWC"的时候要加transpose操作?
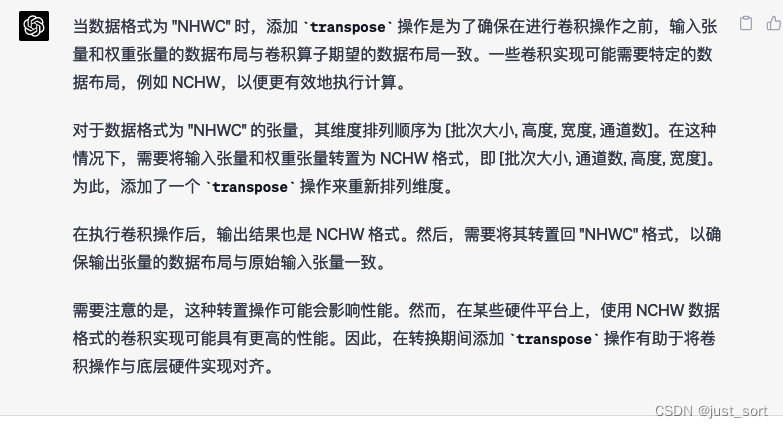

可以看到Claude理解了我的问题,并指出这是因为Tosa的conv2d不支持nhwc数据格式,所以需要加transpose。而GPT4在这个问题上就没有理解我的意思并字面意义的重复了我的问题。
0x3. 总结¶
本文构造了20个MLIR基础概念的问题以及使用OneFlow IR转换为Tosa IR的5个代码段来评测GPT4和Claude对于MLIR的掌握能力,我的结论是对于基础概念的理解Claude整体上和GPT4持平,而在阅读相关代码片段时Claude表现出了比GPT4更强一点的理解能力。
本文总阅读量次