Confluence: A Robust Non-IoU Alternative to Non-Maxima Suppression in Object Detection¶
【GiantPandaCV导语】主要介绍 Confluence: A Robust Non-IoU Alternative to Non-Maxima Suppression in Object Detection 这篇论文的原理,并复现了算法。觉得有些地方原文没有讲的很明白,在复现过程中才搞懂。不过目前复现算法的运行速度较慢,如果哪位小伙伴有更好的复现,记得分享一下。
arxiv 论文地址: https://arxiv.org/pdf/2012.00257.pdf
代码: https://github.com/Huangdebo/Confluence
1. 介绍¶

用以替代 NMS,在所有 bbox 中挑选出最优的集合。 NMS 仅考虑了 bbox 的得分,然后根据 IOU 来去除重叠的 bbox。而 Confluence 则是利用曼哈顿距离作为 bbox 之间的重合度,并根据置信度加权的曼哈顿距离还作为最优 bbox 的选择依据。
2. 算法原理¶
2.1 曼哈顿距离¶
两点的曼哈顿距离就是坐标值差的 L1 范数:
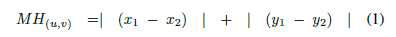
推广到两个 bbox 对的哈曼顿距离则为:

该算法便是以曼哈顿距离作为两个 bbox 的重合度,曼哈顿距离小于一定值的的 bbox 则被认为是一个 cluster。
2.2 归一化¶
因为 bbox 有个各样的 size 和 position,所以直接计算曼哈顿距离就没有可比性,没有标准的度量。所以需要对其进行归一化:
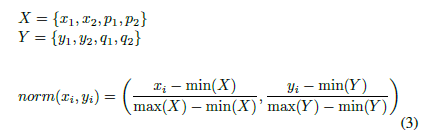
2.3 置信度加权曼哈顿距离¶
NMS在去除重合 bbox 是仅考虑其置信度的高低,Condluence 则同时考虑了曼哈顿距离和置信度,构成一个置信度加权曼哈顿距离:
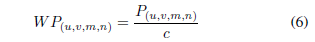
3. 算法实现¶

算法:
(1)针对每个类别挑出属于该类别的 bbox 集合 B
(2)遍历 B 中所有的 bbox bi,并计算 bi 和其他 boox的 曼哈顿距离 p,并归一化
-
2.1 选出 p < 2 的集合,作为一个 cluster,并计算加权曼哈顿距离 wp。
-
2.2 在该 cluster 中挑选出最小的 wp 作为 bi 的 wp。
(3)遍历完毕后,挑出 wp 最小的 bi 作为最优 bbox,添加进最终结果集合中,并将其从 B 去除
(4)把与最优 bbox 的曼哈顿距离小于阈值 MD 的的 bbox 从 B 中去除
(5)不断重复 (2) - (4),每次都选出一个最优 bbox,直到 B 为空
注意:
(1)原文伪代码第 5 行:optimalConfuence 初始化成一个比较大的值就可以,不一定要是 Ip
(2)原文伪代码第 12 行:应该是 Proximity / si
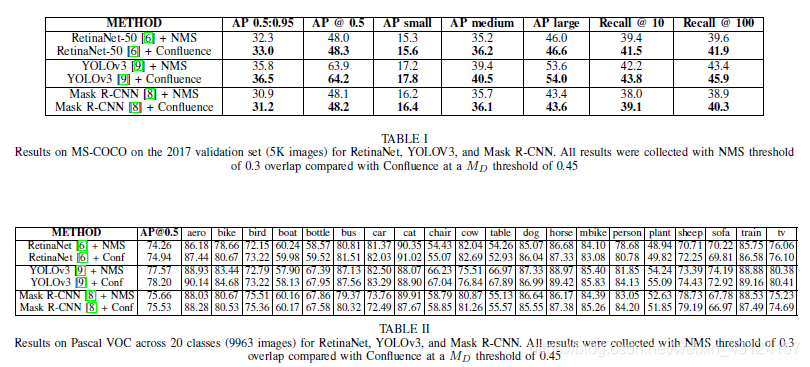
4. 实验结果¶
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次