Deformable Attention Transformer¶
【GiantPandaCV导语】通过在Transformer基础上引入Deformable CNN中的可变性能力,在降低模型参数量的同时提升获取大感受野的能力,文内附代码解读。
引言¶
Transformer由于其更大的感受野能够让其拥有更强的模型表征能力,性能上超越了很多CNN的模型。
然而单纯增大感受野也会带来其他问题,比如说ViT中大量使用密集的注意力,会导致需要额外的内存和计算代价,特征很容易被无关的部分所影响。
而PVT或者Swin Transformer中使用的sparse attention是数据不可知的,会影响模型对长距离依赖的建模能力。
由此引入主角:Deformabel Attention Transformer的两个特点:
- data-dependent: key和value对的位置上是依赖于数据的。
- 结合Deformable 方式能够有效降低计算代价,提升计算效率。
下图展示了motivation:
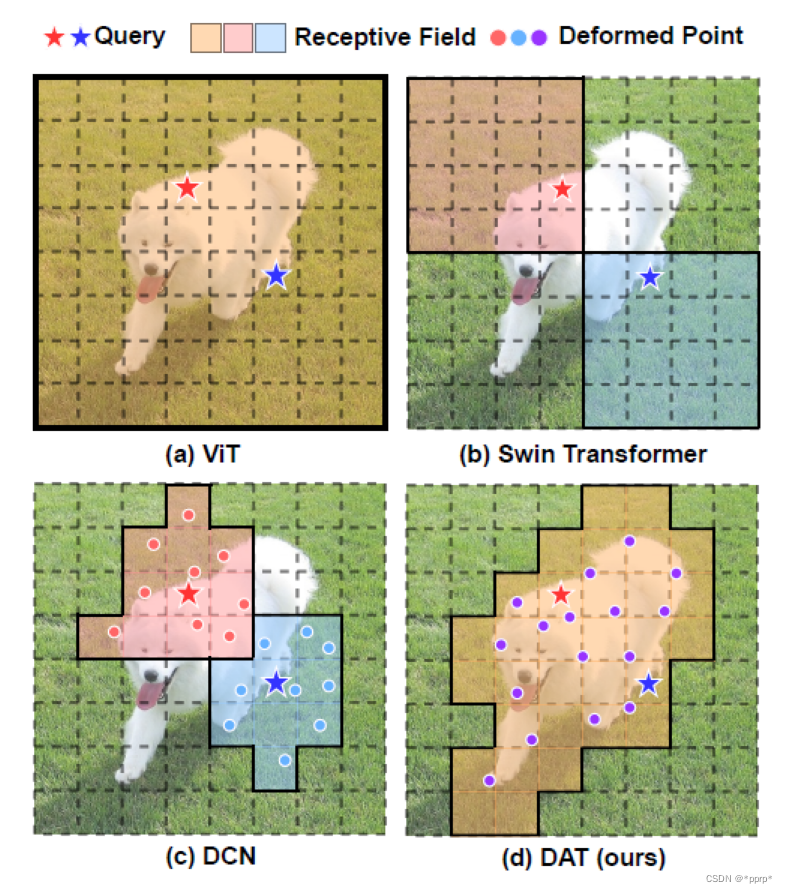
图中比较了几种方法的感受野,其中红色星星和蓝色星星表示的是不同的query。而实线包裹起来的目标则是对应的query参与处理的区域。
(a) ViT对所有的query都一样,由于使用的是全局的注意力,所以感受野覆盖全图。
(b) Swin Transformer中则使用了基于window划分的注意力。不同query处理的位置是在一个window内部完成的。
© DCN使用的是3x3卷积核基础上增加一个偏移量,9个位置都学习到偏差。
(d) DAT是本文提出的方法,由于结合ViT和DCN,所有query的响应区域是相同的,但同时这些区域也学习了偏移量。
方法¶
先回忆一下Deformable Convolution:
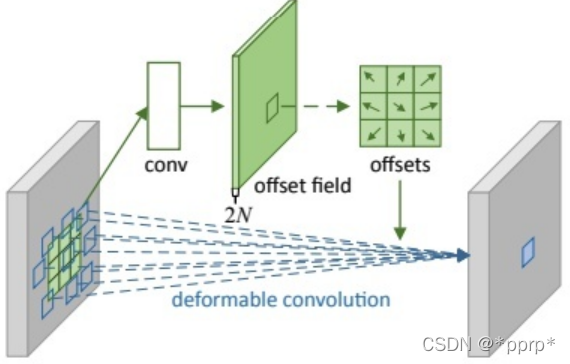
简单来讲是使用了额外的一个分支回归offset,然后将其加载到坐标之上得到合适的目标。
在回忆一下ViT中的Multi-head Self-attention:
有了以上铺垫,下图就是本文最核心的模块Deformable Attention。
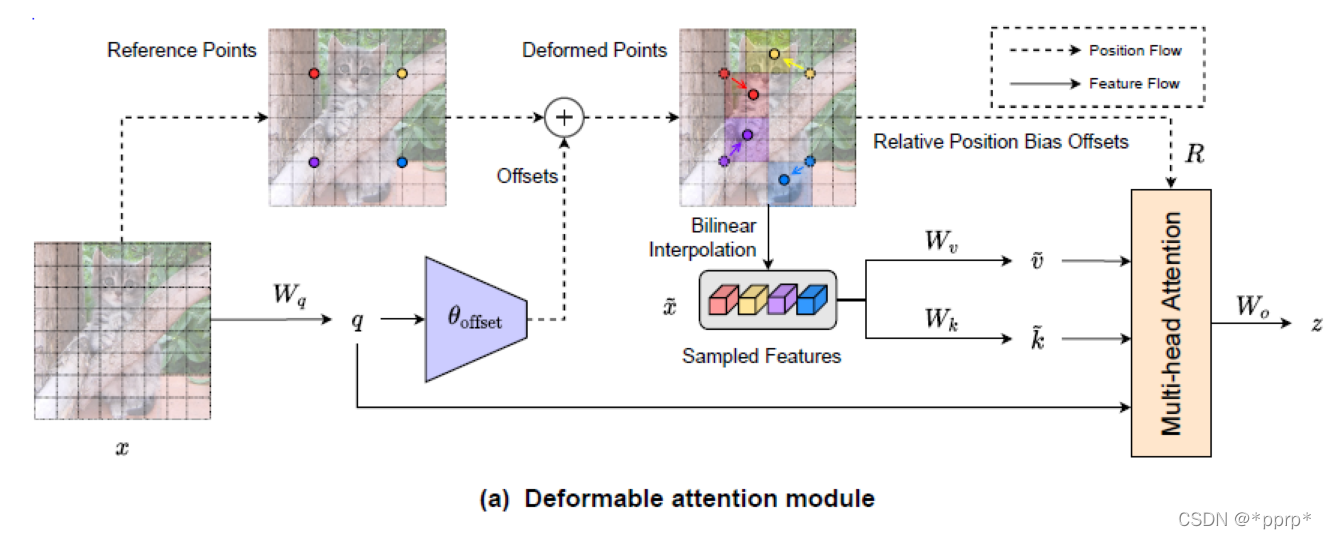
- 左边这部分使用一组均匀分布在feature map上的参照点
- 然后通过offset network学习偏置的值,将offset施加于参照点中。
- 在得到参照点以后使用bilinear pooling操作将很小一部分特征图抠出来,作为k和v的输入
x_sampled = F.grid_sample(
input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),
grid=pos[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B * g, Cg, Hg, Wg
- 之后将得到的Q,K,V执行普通的self-attention, 并在其基础上增加relative position bias offsets。
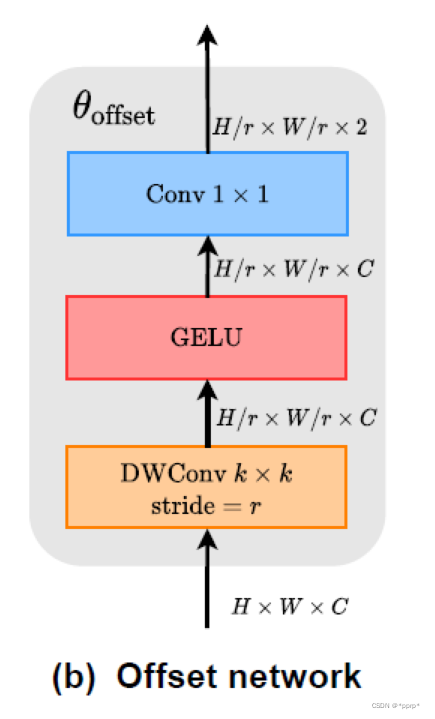
其中offset network构建很简单, 代码和图示如下:
self.conv_offset = nn.Sequential(
nn.Conv2d(self.n_group_channels, self.n_group_channels, kk, stride, kk//2, groups=self.n_group_channels),
LayerNormProxy(self.n_group_channels),
nn.GELU(),
nn.Conv2d(self.n_group_channels, 2, 1, 1, 0, bias=False)
)
最终网络结构为:
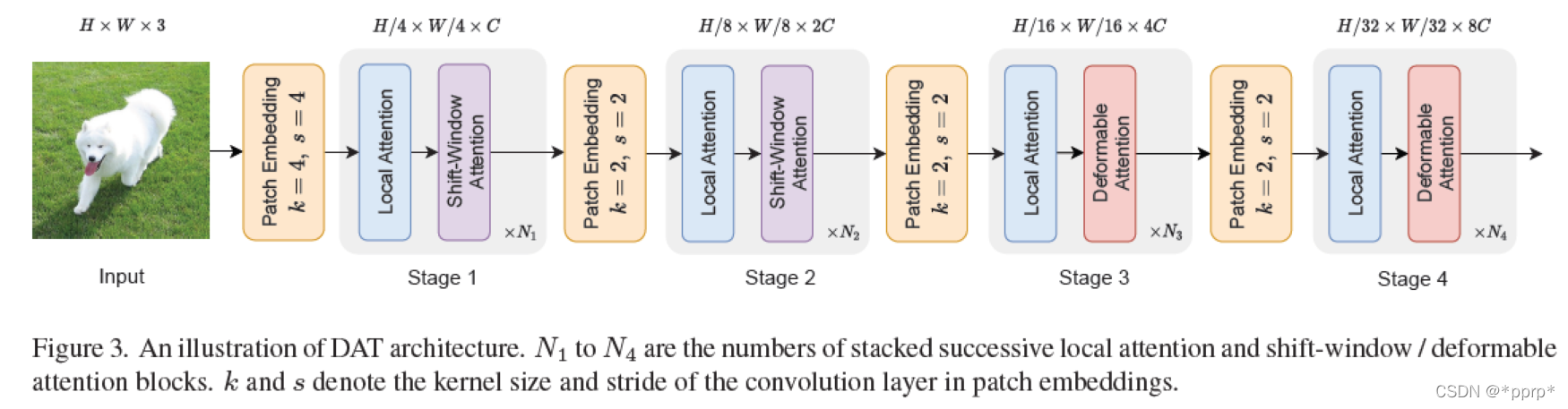
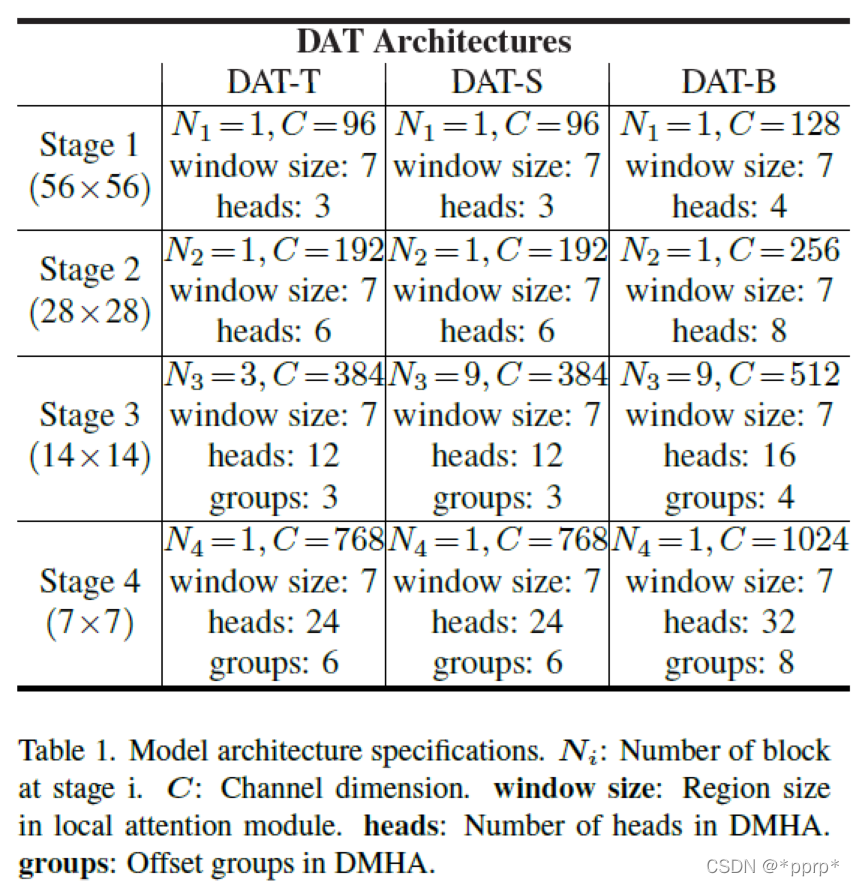
具体参数如下:
实验¶
实验配置:300epoch,batch size 1024, lr=1e-3,数据增强大部分follow DEIT
- 分类结果:
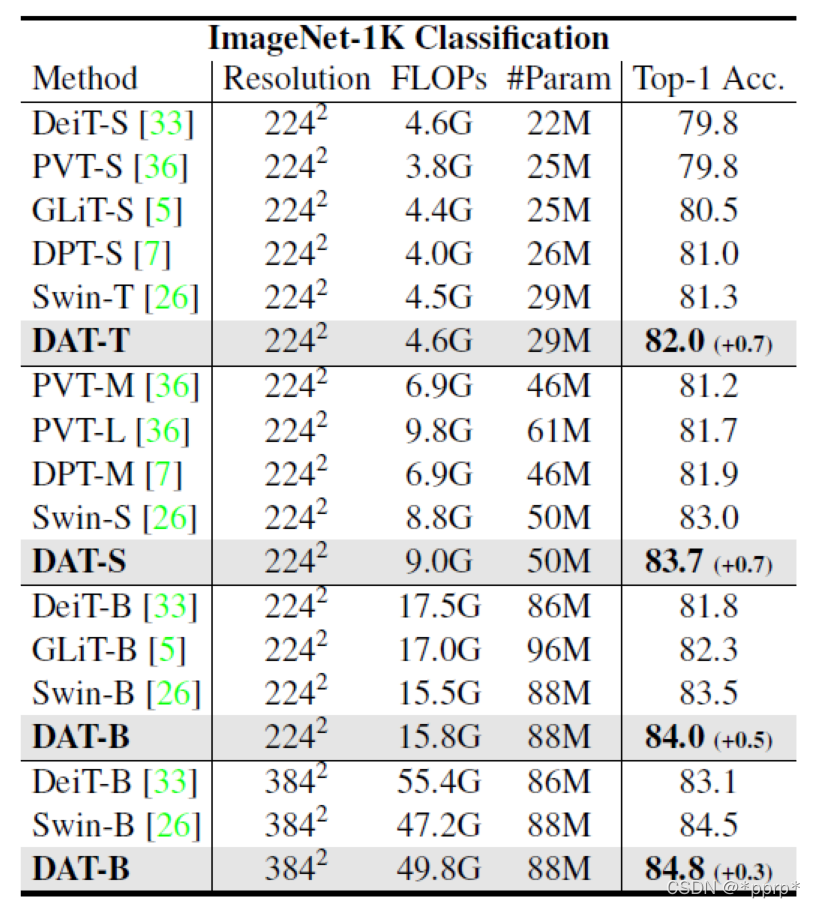
目标检测数据集结果:
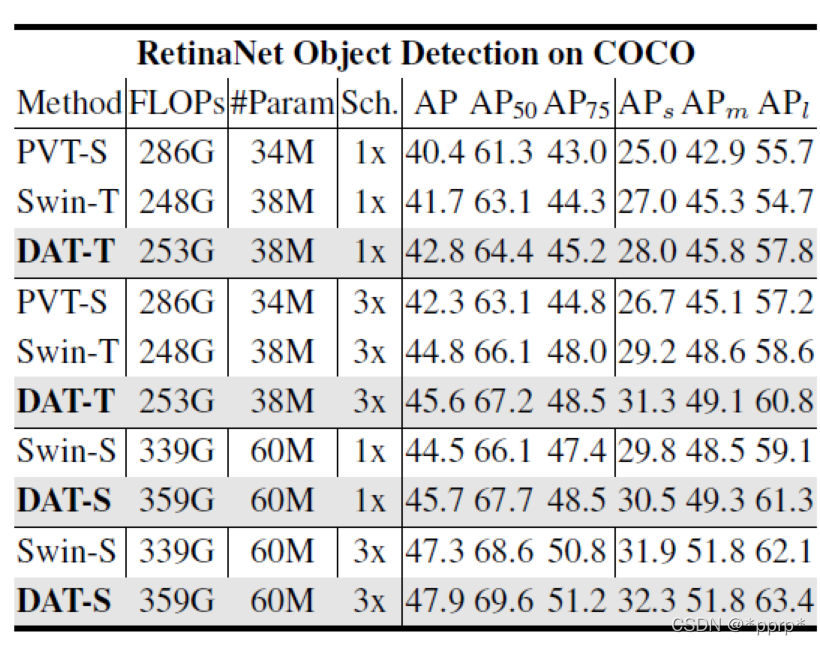
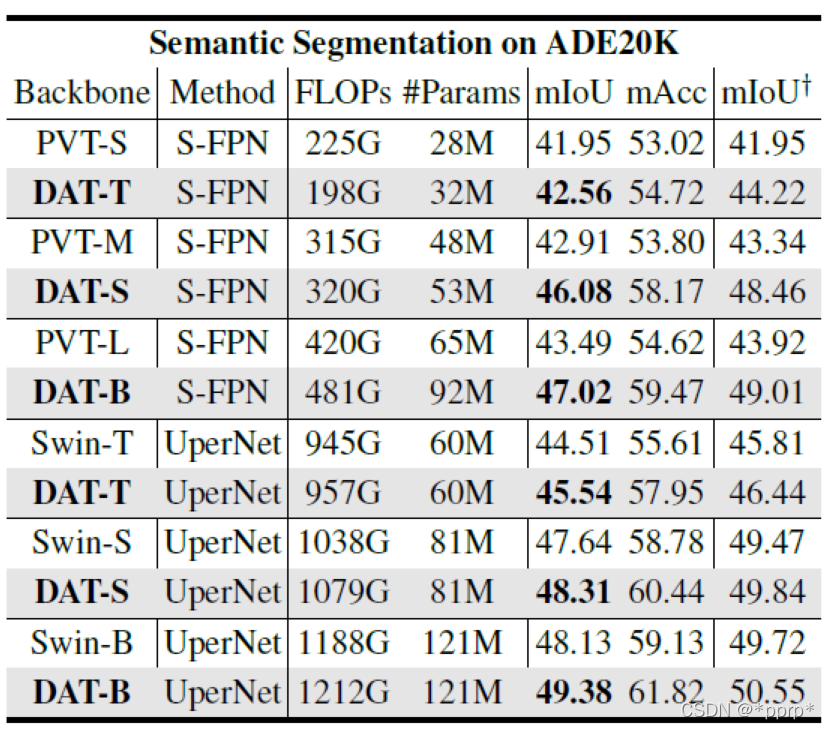
语义分割:
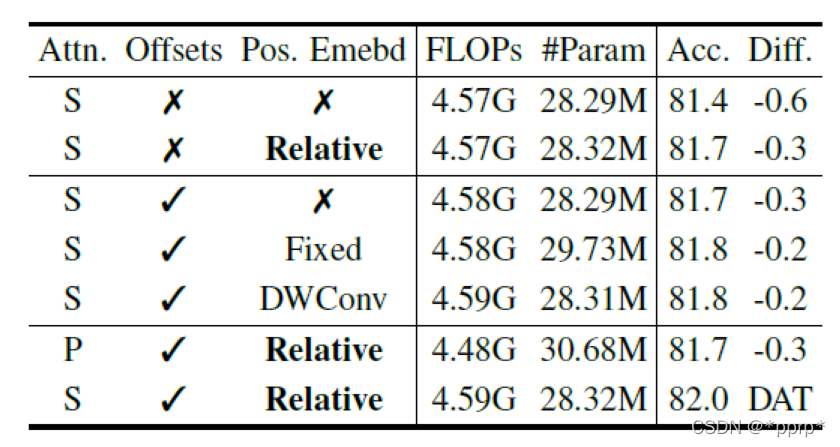
- 消融实验:
- 可视化结果:COCO

这个可视化结果有点意思,如果是分布在背景上的点大部分变动不是很大,即offset不是很明显,但是目标附近的点会存在一定的集中趋势(ps:这种趋势没有Deformable Conv中的可视化结果明显)
代码¶
- 生成Q
B, C, H, W = x.size()
dtype, device = x.dtype, x.device
q = self.proj_q(x)
- offset network前向传播得到offset
q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)
offset = self.conv_offset(q_off) # B * g 2 Hg Wg
Hk, Wk = offset.size(2), offset.size(3)
n_sample = Hk * Wk
- 在参照点基础上使用offset
offset = einops.rearrange(offset, 'b p h w -> b h w p')
reference = self._get_ref_points(Hk, Wk, B, dtype, device)
if self.no_off:
offset = offset.fill(0.0)
if self.offset_range_factor >= 0:
pos = offset + reference
else:
pos = (offset + reference).tanh()
- 使用bilinear pooling的方式将对应feature map抠出来,等待作为k,v的输入。
x_sampled = F.grid_sample(
input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),
grid=pos[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B * g, Cg, Hg, Wg
x_sampled = x_sampled.reshape(B, C, 1, n_sample)
q = q.reshape(B * self.n_heads, self.n_head_channels, H * W)
k = self.proj_k(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
v = self.proj_v(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
- 在positional encodding部分引入相对位置的偏置:
rpe_table = self.rpe_table
rpe_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
q_grid = self._get_ref_points(H, W, B, dtype, device)
displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups, n_sample, 2).unsqueeze(1)).mul(0.5)
attn_bias = F.grid_sample(
input=rpe_bias.reshape(B * self.n_groups, self.n_group_heads, 2 * H - 1, 2 * W - 1),
grid=displacement[..., (1, 0)],
mode='bilinear', align_corners=True
) # B * g, h_g, HW, Ns
attn_bias = attn_bias.reshape(B * self.n_heads, H * W, n_sample)
attn = attn + attn_bias
参考¶
https://github.com/LeapLabTHU/DAT
https://arxiv.org/pdf/2201.00520.pdf
本文总阅读量次