这篇文章整理自我的知乎回答(id: Hanson),分别对深度学习中的多个loss如何平衡 以及 有哪些「魔改」损失函数,曾经拯救了你的深度学习模型 这两个问题进行了解答。
1. 深度学习的多个loss如何平衡?¶
1.1 mtcnn¶
对于多任务学习而言,它每一组loss之间的数量级和学习难度并不一样,寻找平衡点是个很难的事情。我举两个我在实际应用中碰到的问题。第一个是多任务学习算法MTCNN,这算是人脸检测领域最经典的算法之一,被各家厂商魔改,其性能也是很不错的,也有很多版本的开源实现(如果不了解的话,请看:https://blog.csdn.net/qq_36782182/article/details/83624357)。但是我在测试各种实现的过程中,发现竟然没有一套实现是超越了原版的(https://github.com/kpzhang93/MTCNN_face_detection_alignment)。下图中是不同版本的实现,打了码的是我复现的结果。
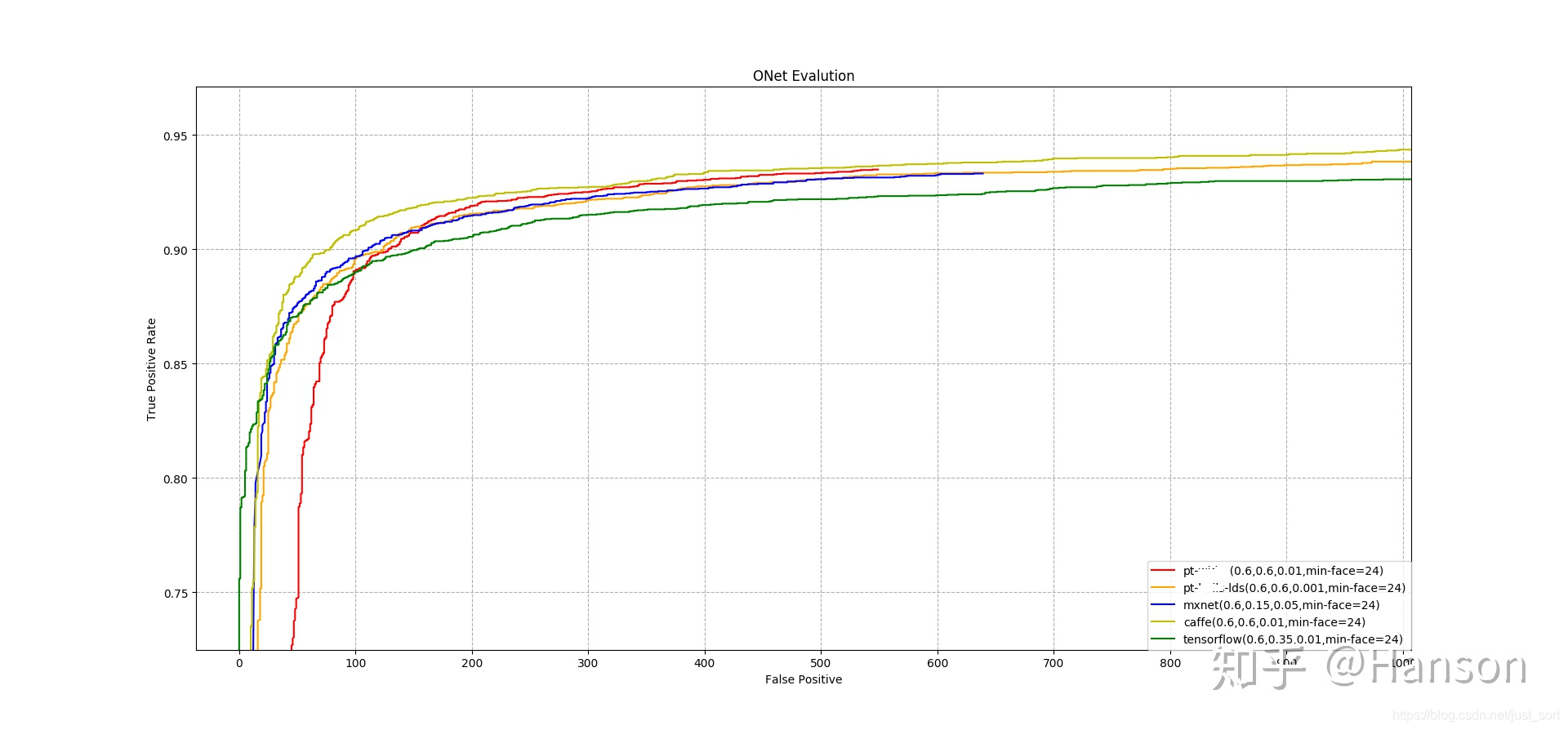
这是一件很困扰的事情,参数、网络结构大家设置都大差不差。但效果确实是迥异。
loss = a*clsloss+b*boxloss+c*landmarksloss
clsloss表示置信度score的loss,boxloss表示预测框位置box的loss,landmarksloss表示关键点位置landmarks的loss。
那么a,b,c这几个权值,究竟应该设置为什么样的才能得到一个不错的结果呢?
其实有个比较不错的主意,就是只保留必要的那两组权值,把另外一组设置为0,比如 a!=0,b!=0,c=0 。为什么这么做?第一是因为关键点的回归在人脸检测过程中不是必要的,去了这部分依旧没什么大问题,也只有在这个假设的前提下才能进行接下来的实验。
就比如这个MTCNN中的ONet,它回归了包括score、bbox、landmarks,我在用pytorch复现的时候,出现一些有意思的情况,就是将landmarks这条任务冻结后(即 a!=0,b!=0,c=0),发现ONet的性能得到了巨大的提升。能超越原始版本的性能。
但是加上landmarks任务后( a!=0,b!=0,c!=0 )就会对cls_loss造成影响,这就是一个矛盾的现象。而且和a、b、c对应的大小有很大关系。当设置成( )的时候关键点的精度真的是惨不忍睹,几乎没法用。当设置成( )的时候,loss到了同样一个数量级,landmarks的精度确实是上去了,但是score却不怎么让人满意。如果产生了这种现象,就证明了这个网络结构在设计的时候出现了一些缺陷,需要去修改backbone之后的multi-task分支,让两者的相关性尽量减小。或者是ONet就不去做关键点,而是选择单独的一个网络去做关键点的预测(比如追加一个LNet)。box的回归并不是特别受关键点影响,大部分情况box和landmarks是正向促进的,影响程度可以看做和score是一致的,box的精度即便下降了5%,它还是能框得住目标,因此不用太在意。
上面这个实验意在说明,要存在就好的loss权重组合,那么你的网络结构就必须设计的足够好。不然你可能还需要通过上述的实验就验证你的网络结构。从多种策略的设计上去解决这种loss不均衡造成的困扰。
和@叶不知(知乎用户)讨论后,有一篇论文也可以提供参考:
https://arxiv.org/abs/1810.04002
1.2 ocr-table-ssd¶
第二个是我之前做过一点OCR方面的工作,这个是我对于表格框格式化方面做的工作,基本算原创工作。
https://github.com/hanson-young/ocr-table-ssd
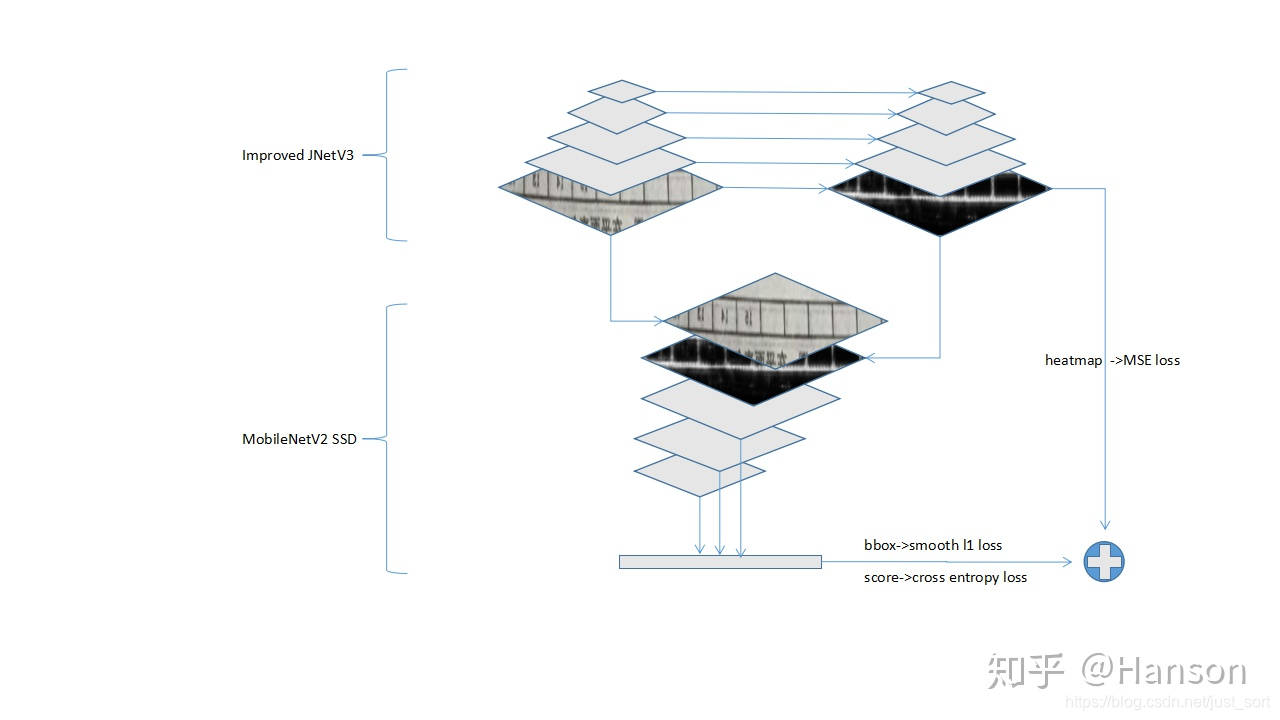
算法是基于SSD改的,与原有SSD相比增加了一个预测heatmap的分支,算是一种attention机制的表现吧。改进后训练达到相同的精度和loss,SSD用时10小时,改进后的方法耗时仅需10-20min。在训练过程中如果两个分支一起训练,很难发挥网络的真正意义,并且收敛到不是很理想的地方,所以训练过程也挺重要的,在实验中,将原来的optimizer从SGD(不易收敛,可能和学习率有关)换到RMSProp:
- 先冻结SSD网络,然后训练segmentation分支,到收敛
- 再冻结segmentation分支进行SSD部分的训练,到收敛
- 再将整个网络解冻训练到收敛,能达到比较好的效果



因为表格尺度的影响,不加入heatmap分支会导致图像被过分拉升,导致无法检测到表格框。
加入heatmap后还有个好处就是为表格的对齐提供了可能。

如果直接检测,对于一个矩形框来说,恐怕是会非常吃力的。如果
heatmap -> 阈值分割 -> Sobel -> HoughLineP -> angle
求出表格的倾斜角angle后,可以将原图和heatmap旋转统一的angle后concatenation,这样再接着跑SSD,对齐后的效果比较明显,解决了倾斜角度过大,带来bbox框过大的影响,详细见下图。
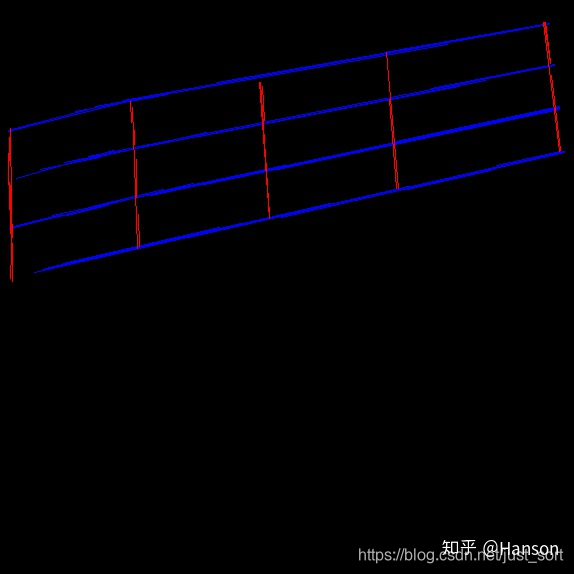
然后进行对齐工作

是不是能好很多。
2. 有哪些「魔改」损失函数,曾经拯救了你的深度学习模型?¶
我在做缺陷检测时候对比了一些loss的性能,其实确实是那句话,适合自己的才是最好的。以下我用实际例子来说明这个问题。
2.1 实验条件¶
为了实验方便,我们使用了CrackForest数据集(https://github.com/cuilimeng/CrackForest-dataset)做训练测试,目的是去将裂纹缺陷分割出来,总共118张图片,其中训练样本94张,测试样本24张,采用旋转、随机缩放、裁剪、图像亮度增强、随机翻转增强操作,保证实验参数一直,模型均是类Unet网络,仅仅使用了depthwise卷积结构,进行了如下几组实验,并在tensorboard中进行图像预测状态的观测。

2.2 weighted CrossEntropy¶
在loss函数的选取时,类似focal loss,常规可以尝试使用cross_entropy_loss_RCF(https://github.com/meteorshowers/RCF-pytorch/blob/master/functions.py),或者是weighted MSE,因为图像大部分像素为非缺陷区域,只有少部分像素为缺陷裂痕,这样可以方便解决样本分布不均匀的问题
validation
epoch[625] | val_loss: 2708.3965 | precisions: 0.2113 | recalls: 0.9663 | f1_scores: 0.3467
training
2018-11-27 11:53:56 [625-0] | train_loss: 2128.9360 | precisions: 0.2554 | recalls: 0.9223 | f1_scores: 0.4000
2018-11-27 11:54:13 [631-2] | train_loss: 1416.9917 | precisions: 0.2359 | recalls: 0.9541 | f1_scores: 0.3782
2018-11-27 11:54:31 [637-4] | train_loss: 1379.9745 | precisions: 0.1916 | recalls: 0.9591 | f1_scores: 0.3194
2018-11-27 11:54:50 [643-6] | train_loss: 1634.6824 | precisions: 0.3067 | recalls: 0.9636 | f1_scores: 0.4654
2018-11-27 11:55:10 [650-0] | train_loss: 2291.4810 | precisions: 0.2498 | recalls: 0.9317 | f1_scores: 0.3940

weighted CrossEntropy 在实验过程中因为图片中的缺陷部分太过稀疏,导致了weights的选取有很大的问题存在,训练后会发现其recall极高,但是precision却也是很低,loss曲线也极其不规律,基本是没法参考的,能把很多疑似缺陷的地方给弄进来.因此只能将weights改为固定常量,这样可以在一定程度上控制均衡recall和precision,但调参也会相应变得麻烦
2.3 MSE(不带权重)¶
我们先来试试MSE,在分割上最常规的loss
validation
epoch[687] | val_loss: 0.0063 | precisions: 0.6902 | recalls: 0.6552 | f1_scores: 0.6723 | time: 0
epoch[875] | val_loss: 0.0067 | precisions: 0.6324 | recalls: 0.7152 | f1_scores: 0.6713 | time: 0
epoch[1250] | val_loss: 0.0066 | precisions: 0.6435 | recalls: 0.7230 | f1_scores: 0.6809 | time: 0
epoch[1062] | val_loss: 0.0062 | precisions: 0.6749 | recalls: 0.6835 | f1_scores: 0.6792 | time: 0
training
2018-11-27 15:01:34 [1375-0] | train_loss: 0.0055 | precisions: 0.6867 | recalls: 0.6404 | f1_scores: 0.6627
2018-11-27 15:01:46 [1381-2] | train_loss: 0.0045 | precisions: 0.7223 | recalls: 0.6747 | f1_scores: 0.6977
2018-11-27 15:01:58 [1387-4] | train_loss: 0.0050 | precisions: 0.7336 | recalls: 0.7185 | f1_scores: 0.7259
2018-11-27 15:02:09 [1393-6] | train_loss: 0.0058 | precisions: 0.6719 | recalls: 0.6196 | f1_scores: 0.6447
2018-11-27 15:02:21 [1400-0] | train_loss: 0.0049 | precisions: 0.7546 | recalls: 0.7191 | f1_scores: 0.7364
2018-11-27 15:02:32 [1406-2] | train_loss: 0.0057 | precisions: 0.7286 | recalls: 0.6919 | f1_scores: 0.7098
2018-11-27 15:02:42 [1412-4] | train_loss: 0.0054 | precisions: 0.7850 | recalls: 0.6932 | f1_scores: 0.7363
2018-11-27 15:02:53 [1418-6] | train_loss: 0.0050 | precisions: 0.7401 | recalls: 0.7223 | f1_scores: 0.7311

MSE在训练上较cross entropy就比较稳定,在heatmap预测上优势挺明显
2.4 weighted MSE(8:1)¶
既然MSE的效果还不错,那么是否加权后就更好了呢,其实从我做的实验效果来看,并不准确,没想象的那么好,甚至导致性能下降了
validation
epoch[2000] | val_loss: 11002.3584 | precisions: 0.5730 | recalls: 0.7602 | f1_scores: 0.6535 | time: 1
training
2018-11-27 13:12:44 [2000-0] | train_loss: 7328.5186 | precisions: 0.6203 | recalls: 0.6857 | f1_scores: 0.6514
2018-11-27 13:13:01 [2006-2] | train_loss: 6290.4971 | precisions: 0.5446 | recalls: 0.5346 | f1_scores: 0.5396
2018-11-27 13:13:18 [2012-4] | train_loss: 5887.3525 | precisions: 0.6795 | recalls: 0.6064 | f1_scores: 0.6409
2018-11-27 13:13:36 [2018-6] | train_loss: 6102.1934 | precisions: 0.6613 | recalls: 0.6107 | f1_scores: 0.6350
2018-11-27 13:13:53 [2025-0] | train_loss: 7460.8853 | precisions: 0.6225 | recalls: 0.7137 | f1_scores: 0.6650

以上loss在性能表现上,MSE > weighted MSE > weighted CrossEntropy,最简单的却在该任务上取得了最好的效果,所以我们接下来该做的,就是去怀疑人生了!
有问题欢迎评论区留言交流。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次