MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space CVPR 2022¶
1. 论文信息¶
标题:MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space
作者:Rui Huang, Yixuan Li
代码链接:https://github.com/deeplearning-wisc/large_scale_ood
2. 介绍¶
out -distribution (OOD)检测已经成为在开放世界中安全部署机器学习模型的一个核心挑战,在开放世界中,测试数据可能与训练数据分布不同。由于数据集中不可能枚举出所有真实世界可能出现的样本类别,所以在训练模型过程中,需要完成对于OOD样本的检测。然而,现有的解决方案主要是由小型、低分辨率的数据集驱动的,如CIFAR和MNIST。像自动驾驶汽车这样的部署系统通常对分辨率更高的图像进行操作,感知的环境类别也更多。因此,针对大规模图像分类任务的OOD检测算法的开发和评估存在一个关键的gap。本文首先志在提出一个benchmark实现大规模数据集上的OOD检测。
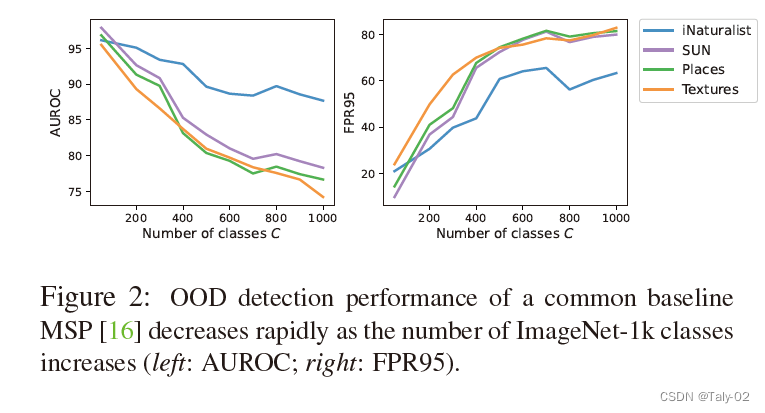
本文指出,随着语义类别数量的增加,OOD数据出现的方式也呈指数增长。论文的分析显示,当ImageNet-1k上的类别数量从50增加到1000时,最直接的OOD检测方式,MSP,的FPR95将从17.34%增加到76.94%。如下图,随着类别数量的增加,利用MSP检测的性能下降的也非常快。很少有研究大规模环境下的OOD检测,评价和有效性都很有限。但是我们当然希望能够在大规模数据集上取得不错的效果,并设立一套完整的评价体系来评价算法的性能。为此,这份工作建立了新的benchmark,在ImageNet-1k级别的数据集上设立了一个全新的benchmark。并提出了一种基于group的OOD检测框架,该框架对大规模图像分类有效,可以探索在该规模数据集上的OOD检测。
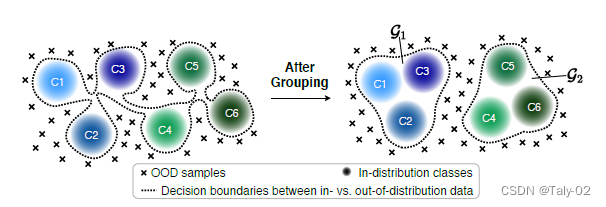
其实论文high-level的idea很好理解,因为相对于小规模的数据集,如CIFAR和MNIST,显然直接去确定大规模数据集的决策边界是非常有挑战的。但是既然我们以及在较小规模的数据集上设计了比较好的算法,取得了不错的性能,那么我们是不是可以根据一定的规则,将大的语义空间分解为具有类似语义的更小的group。从而通过这种方式简化决策边界,并减少分布内与分布外数据之间的不确定性空间。直观地说,对于OOD检测来说,估计一个图像是否属于一个粗粒度语义组比估计一个图像是否属于一个细粒度语义组要简单得多,而且我们也有比较不错的算法来处理这种量级的数据。
3. 方法¶
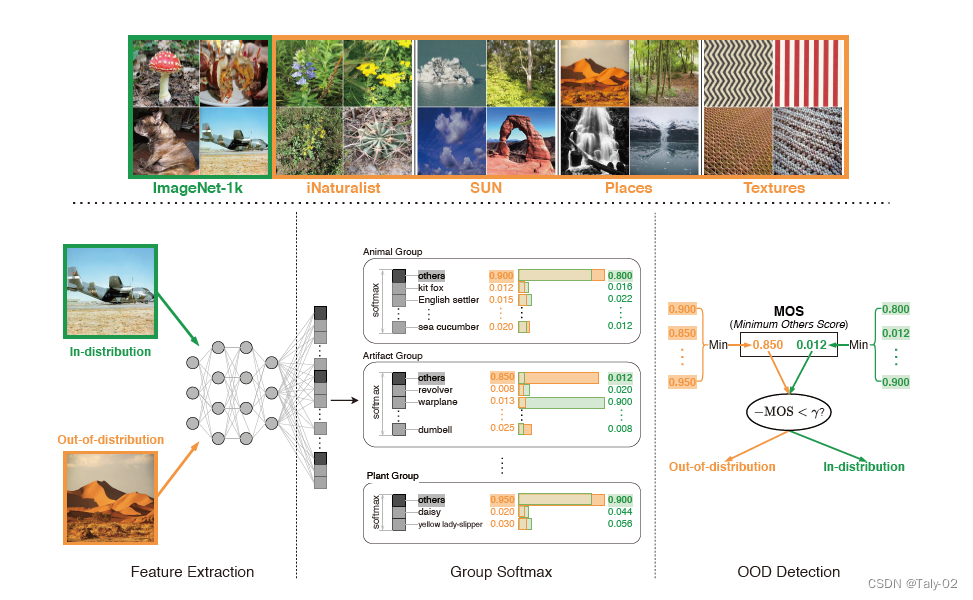
如前所述,OOD检测性能会因分布内类数量的增加而受到显著影响。为了解决由于ID数据类别过多导致决策边界难以确定这个问题,论文提出的关键idea是将大的语义空间分解为具有类似概念的更小的组,这允许简化决策边界,并减少分布内与分布外数据之间的不确定性空间。如果在没有经过分组的的情况下进行OOD检测,ID vs. OOD数据之间的决策边界由所有类决定,并且随着类的数量而变得越来越复杂,其非常难以描述,决策边界不好确定。而把ID数据分成若干个group,则可以显著简化OOD检测的决策boundary,如图虚线所示。换句话说,通过分组的方式,OOD检测器只需要对一幅图像是否属于这个组进行少量相对简单的估计,而不是对一幅图像是否属于这个类进行大量艰难的决定。如果一个图像不属于任何一个group,它就会被归类为OOD。
然后我们来介绍了论文设计的新的训练机制:

考虑以上的公式,因为不同类别都想定义出“other”,利用标准的group softmax是不够的,因为它只能区分组内的类,但不能估计ID和OOD之间的uncertainty。在划分成不同的group类别之外,每个group都引入了一个新的类别others,如上图所示。如果输入x不属于这一组,模型可以预测为others。其实就是在把OOD detection的任务划分为若干个进行OOD检测的二分类任务,通过在每个group之中都去明确该group的ID与OOD之间的决策边界。这对于OOD检测是可取的,因为OOD输入可以映射到所有其它groups的others,而分布内的输入将以高置信度映射到某个组中的某个语义类别。
训练阶段中,就是根据ID数据把数据集分为若干个部分,ground-truth标签就是在每个group中进行重新映射。 在组中c 不包括在内,其他类将被定义为真实类。 训练过程中的优化目标,自然就是交叉熵损失的每组的总和:
然后在测试阶段,就是按照各个组的最大值作为类似MSP的输出:
再在多个组内选取最大值,作为最后的OOD score:
其实直接来讲,就是利用一个“others”类别定义除了该group以内的类别,然后比较各个类别others的概率输出绝对值。如果others的最大值相对比较大,则该样本大概率是OOD样本。
其实high-level的idea很简单,就是把大的ID数据集分为若干个小的ID数据集。那想必大家都会有这么一个疑问:
how do different grouping strategies affect the performance of OOD detection?
就是该采用什么样的grouping方式,不同的方式对于OOD检测的影响又是怎么样的呢?
这里作者利用三种方式进行grouping:
- 根据标签已知的信息:比如大家都知道ImageNet-1k就是根据WordNet中的信息进行层次化标注的,所以其实不同类别是有相应的父类的,所以可以直接使用相应的标注作为grouping的根据。
- 根据特征聚类:自然是根据训练模型的特征,距离比较近的归为一个group,比较远的归为不同的group。
- 随机分组:这个自然是最简单的对照组。
至于效果,我们在实验部分慢慢讨论。
4. 实验¶
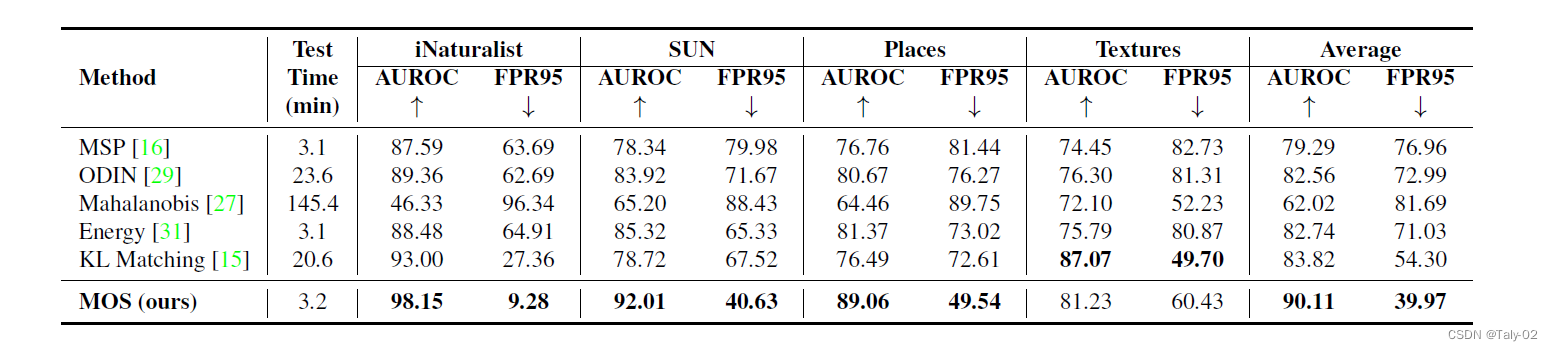
首先是主实验:把MOS与其他baseline的OOD检测性能比较。所有方法都通过使用ImageNet-1k作为分布内数据集,从相同的预先训练的BiT-S-R101x1的backbone进行微调。4采用了个OOD测试数据集。所有方法的测试时间都使用相同的分布内和分布外数据集(总共60k张图像)进行评估。可以发现,其实MOS的测试时间相对于最简单的MSP、Energy来讲并没有显著的增加,只是增加了若干个others类别的logit计算,但是可见无论是AUROC还是FPR95,都具有很大的优势。
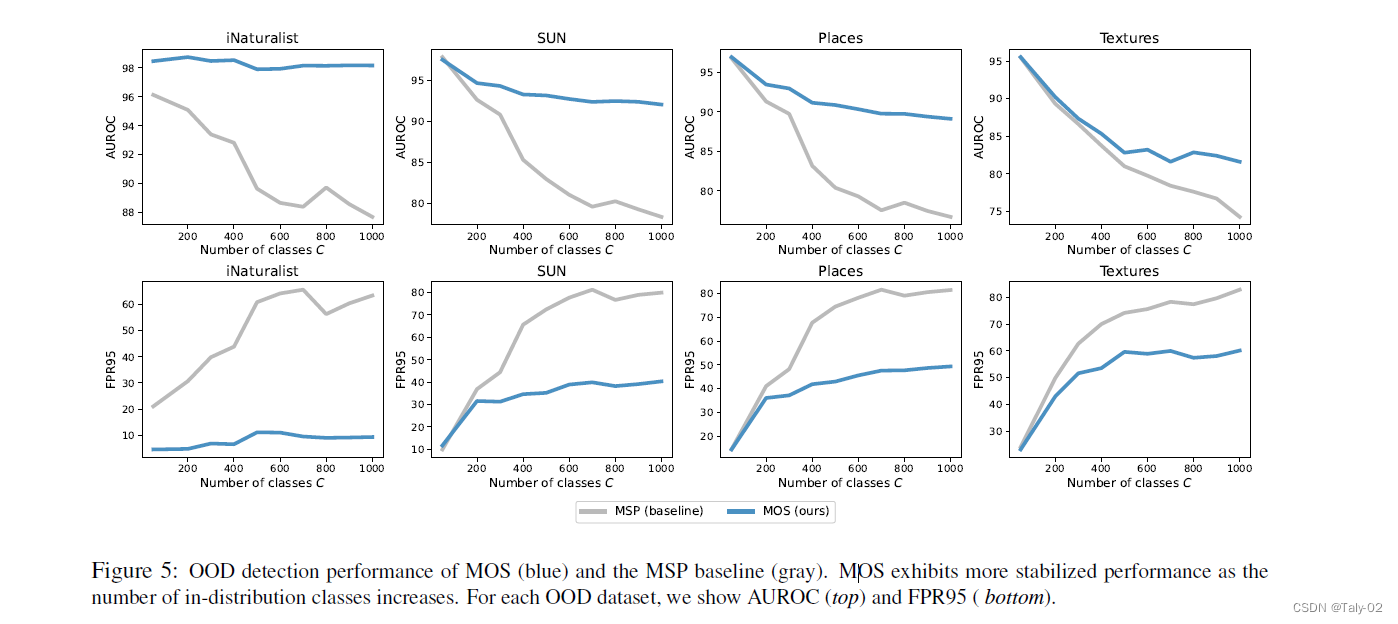
可以发现,随着类别数量的增加,MOS相对于MSP这种baseline的提升也越大。这是很好理解的,毕竟语义空间过大的时候,over-confidence的现象也会非常严重,而MOS可以很好得handle这一点。
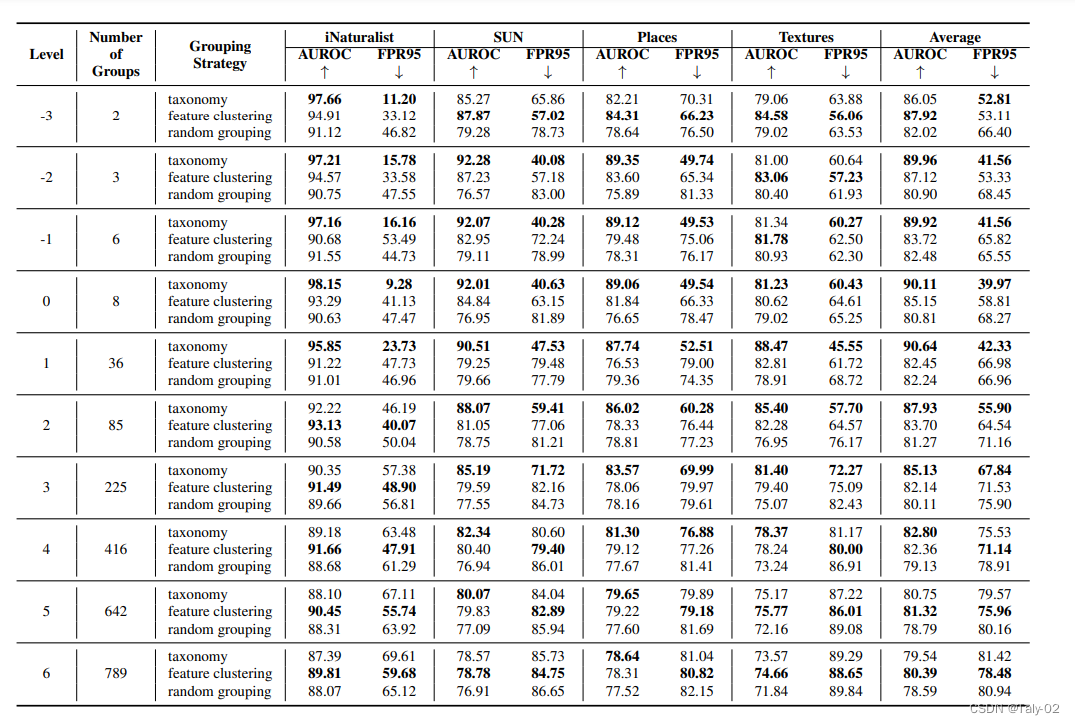
针对不同的分组方法,我们可以发现taxonomy还是相对最好的方式,但是随着层级不断加深,可能特征聚类又表现出优越的性能,这可能是因为层级多了之后,特征质量更高。
5. 结论¶
本文提出了一个基于分组的OOD检测框架,以及一个新的OOD评分函数MOS,该函数可以有效地将OOD检测扩展到具有大标签空间的真实世界。我们策划了四个不同的OOD评估数据集,允许未来的研究在大规模设置中评估OOD检测方法。大量实验表明,与现有方法相比,我们的基于组的框架可以显著提高这种大规模场景下OOD检测的性能。希望这份研究能够引起更多的关注,将OOD检测的视野从小型基准扩展到大规模的真实世界设置。
本文总阅读量次