【CV中的Attention机制】融合Non-Local和SENet的GCNet
前言: 之前已经介绍过SENet和Non Local Neural Network(NLNet),两者都是有效的注意力模块。作者发现NLNet中attention maps在不同位置的响应几乎一致,并结合SENet后,提出了Global Context block,用于全局上下文建模,在主流的benchmarks中的结果优于SENet和NLNet。
GCNet论文名称为:《GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond》,是由清华大学提出的一个注意力模型,与SE block、Non Local block类似,提出了GC block。为了克服NL block计算量过大的缺点,提出了一个Simplified NL block,由于其与SE block结构的相似性,于是在其基础上结合SE改进得到GC block。
SENet中提出的SE block是使用全局上下文对不同通道进行权值重标定,对通道依赖进行调整。但是采用这种方法,并没有充分利用全局上下文信息。
捕获长距离依赖关系的目标是对视觉场景进行全局理解,对很多计算机视觉任务都有效,比如图片分类、视频分类、目标检测、语义分割等。而NLNet就是通过自注意力机制来对长距离依赖关系进行建模。
作者对NLNet进行试验,选择COCO数据集中的6幅图,对于不同的查询点(query point)分别对Attention maps进行可视化,得到以下结果:

可以看出,对于不同的查询点,其attention map是几乎一致的,这说明NLNet学习到的是独立于查询的依赖(query-independent dependency),这说明虽然NLNet想要对每一个位置进行特定的全局上下文计算,但是可视化结果以及实验数据证明,全局上下文不受位置依赖。
基于以上发现,作者希望能够减少不必要的计算量,降低计算,并结合SENet设计,提出了GCNet融合了两者的优点,既能够有用NLNet的全局上下文建模能力,又能够像SENet一样轻量。
作者首先针对NLNet的问题,提出了一个Simplified NLNet, 极大地减少了计算量。

NLNet 中的Non-Local block可以表示为:
输入的feature map定义为x=\{x_i\}^{N_p}_{i=1}, N_p是位置数量。x和z是NL block输入和输出。i是位置索引,j枚举所有可能位置。f(x_i,x_j)表示位置i和j的关系,C(x)是归一化因子。$W_z和W_v是线性转换矩阵。
NLNet中提出了四个相似度计算模型,其效果是大概相似的。作者以Embedded Gaussian为基础进行改进,可以表达为:
简化后版本的Simplified NLNet想要通过计算一个全局注意力即可,可以表达为:
这里的W_v、W_q、W_k都是1\times1卷积,具体实现可以参考上图。
简化后的NLNet虽然计算量下去了,但是准确率并没有提升,所以作者观察到SENet与当前的模块有一定的相似性,所以结合了SENet模块,提出了GCNet。

可以看出,GCNet在上下文信息建模这个地方使用了Simplified NL block中的机制,可以充分利用全局上下文信息,同时在Transform阶段借鉴了SE block。
GC block在ResNet中的使用位置是每两个Stage之间的连接部分,下边是GC block的官方实现(基于mmdetection进行修改):
代码实现:
import torch
from torch import nn
class ContextBlock(nn.Module):
def __init__(self,inplanes,ratio,pooling_type='att',
fusion_types=('channel_add', )):
super(ContextBlock, self).__init__()
valid_fusion_types = ['channel_add', 'channel_mul']
assert pooling_type in ['avg', 'att']
assert isinstance(fusion_types, (list, tuple))
assert all([f in valid_fusion_types for f in fusion_types])
assert len(fusion_types) > 0, 'at least one fusion should be used'
self.inplanes = inplanes
self.ratio = ratio
self.planes = int(inplanes * ratio)
self.pooling_type = pooling_type
self.fusion_types = fusion_types
if pooling_type == 'att':
self.conv_mask = nn.Conv2d(inplanes, 1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
if 'channel_add' in fusion_types:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))
else:
self.channel_add_conv = None
if 'channel_mul' in fusion_types:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.inplanes, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.inplanes, kernel_size=1))
else:
self.channel_mul_conv = None
def spatial_pool(self, x):
batch, channel, height, width = x.size()
if self.pooling_type == 'att':
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
context_mask = self.conv_mask(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = self.softmax(context_mask)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(-1)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
else:
# [N, C, 1, 1]
context = self.avg_pool(x)
return context
def forward(self, x):
# [N, C, 1, 1]
context = self.spatial_pool(x)
out = x
if self.channel_mul_conv is not None:
# [N, C, 1, 1]
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
out = out * channel_mul_term
if self.channel_add_conv is not None:
# [N, C, 1, 1]
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out
if __name__ == "__main__":
in_tensor = torch.ones((12, 64, 128, 128))
cb = ContextBlock(inplanes=64, ratio=1./16.,pooling_type='att')
out_tensor = cb(in_tensor)
print(in_tensor.shape)
print(out_tensor.shape)
对这个模块进行了测试,需要说明的是,如果ratio × inplanes < 1, 将会出问题,这与通道个数有关,通道的个数是无法小于1的。
实验部分
作者基于mmdetection进行修改,添加了GC block,以下是消融实验。
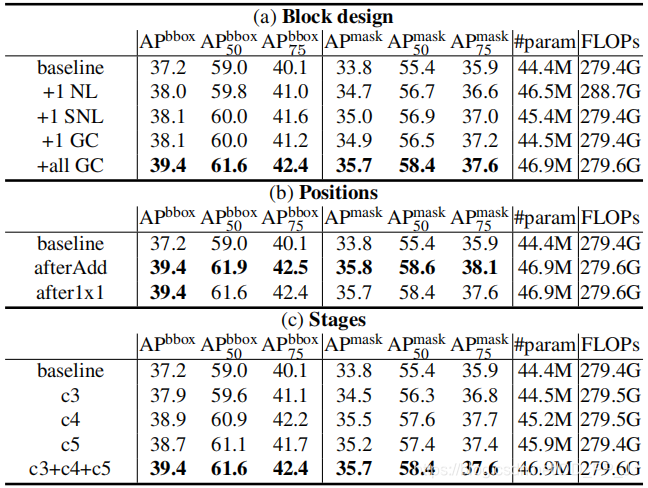
- 从block设计来讲,可以看出Simplified NL与NL几乎一直,但是参数量要小一些。而每个阶段都使用GC block的情况下能比baseline提高2-3%。
- 从添加位置进行试验,在residual block中添加在add操作之后效果最好。
- 从添加的不同阶段来看,施加在三个阶段效果最优,能比baseline高1-3%。
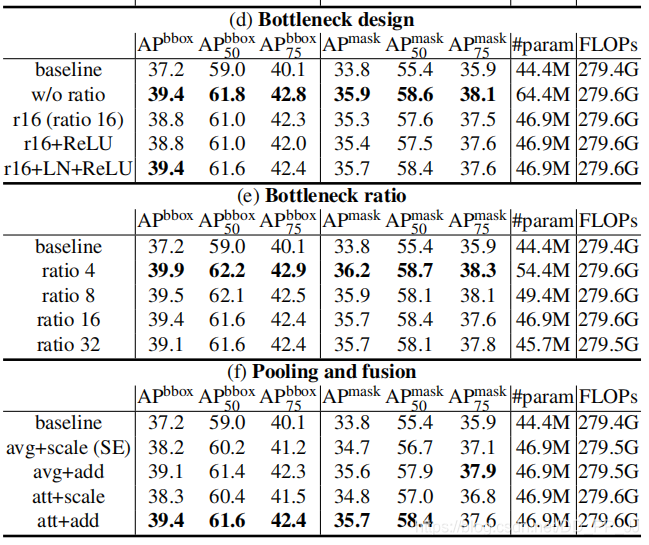
-
Bottleneck设计方面,测试使用缩放、ReLU、LayerNorm等组合,发现使用简化版的NLNet并使用1×1卷积作为transform的时候效果最好,但是其计算量太大。
-
缩放因子设计:发现ratio=¼的时候效果最好。
- 池化和特征融合设计:分别使用average pooling和attention pooling与add、scale方法进行组合实验,发现attention pooling+add的方法效果最好。

此处对ImageNet数据集进行了实验,提升大概在1%以内。
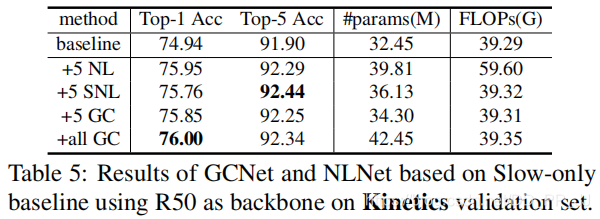
在动作识别数据集Kinetics中,也取得了1%左右的提升。
总结:GCNet结合了SENet和Non Local的优点,在满足计算量相对较小的同时,优化了全局上下文建模能力,之后进行了详尽的消融实验证明了其在目标检测、图像分类、动作识别等视觉任务中的有效性。这篇论文值得多读几遍。
参考:
论文地址:https://arxiv.org/abs/1904.11492
官方实现代码:https://github.com/xvjiarui/GCNet
文章中核心代码:https://github.com/pprp/SimpleCVReproduction/tree/master/attention/GCBlock
本文总阅读量次