前言¶
近段时间,Vision Transformer展现了自注意力模型的在图像领域的潜力,但是想要赶上CNN的SOTA结果,需要依赖额外的大数据集预训练。我们发现限制VIT表现的因素是其编码细微级别特征到token上效率低下,因此我们提出了基于outlook attention机制的模型:Vision Outlooker,在ImageNet-1K分类任务能达到87.1%的准确率,在分割任务上也能达到SOTA级别。
论文: https://arxiv.org/abs/2106.13112
官方代码:https://github.com/sail-sg/volo
介绍¶
我们在本次工作中,提出一个简单,轻量级的Attention机制,称为Outlooker, Outlooker可以丰富fine level级别特征表达。
简单来说,就是对于一个中心token,经过简单的线性变换,可以生成其周围token对应的注意力权重,这种做法也能避免原始self-attention昂贵的计算代价。
基于这个Outlooker,我们提出的模型VOLO使用两阶段结构,考虑了细粒度特征和全局信息聚合。首先会用Patch Embedding降采样,将分辨率从224x224降采样到28x28,对应第一阶段使用Outlooker Attention。然后再做一次降采样至14x14,使用原始的Transformer Block来聚合全局信息。下面会结合论文原图和代码来讲解。
Outlook Attention¶
先看下作者的insight:
-
每一个空间位置上的feature足以生成周边feature的注意力权重
-
Dense和局部空间聚合可以有效地编码fine-level级别特征
下图是Outlook Attention的全局图
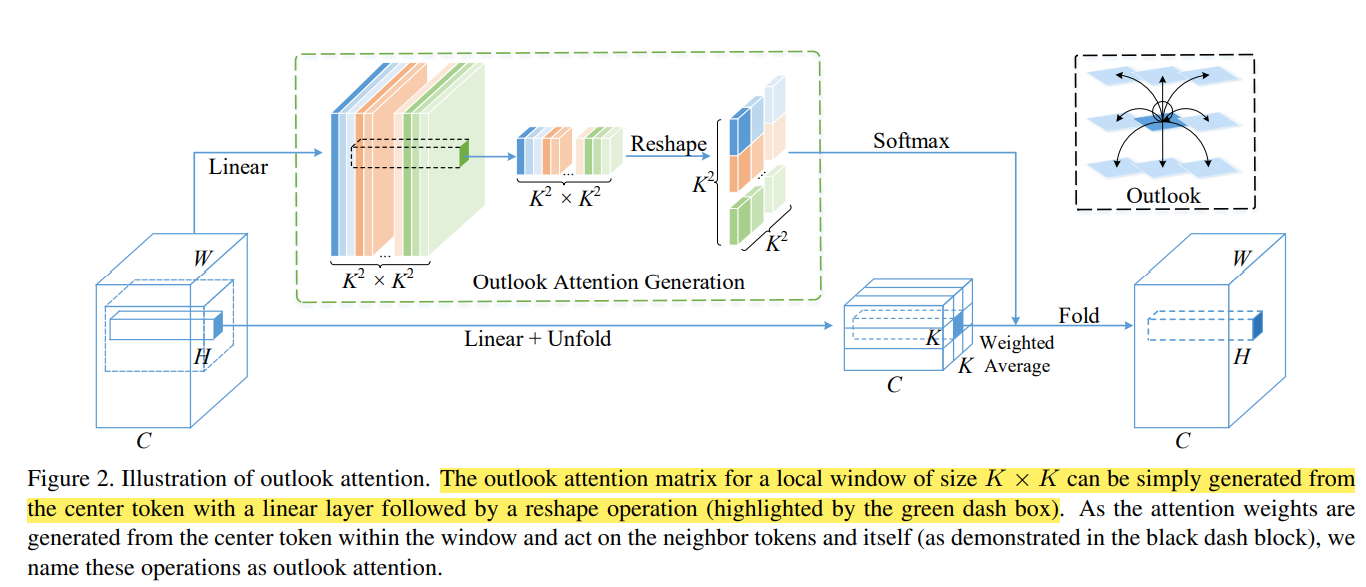
我们先看上面一条路,对于(C, H, W)输入,我们先经过全连接层压缩到(K^2*K^2, H, W)。其中K表示的是Kernel的大小,你可以理解为每一个空间feature生成周边KxK个特征的注意力权重。
然后我们取其中的一个空间位置的特征来看
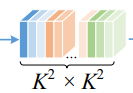
他的大小为(K^2*K^2, 1, 1),然后我们可以reshape成(1, K^2, K^2)
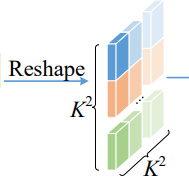
接着经过softmax,获得注意力。下面我们来看下面一条路
熟悉Unfold的同学应该会知道,unfold就是取每一个位置的KxK大小窗口的元素(因此unfold+矩阵乘其实就是卷积操作,unfold的别名也叫img2col)。
回到刚刚示例的位置,我们取其包含中心的KxK个元素,形状为(C, K, K)
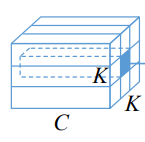
reshape成(1, C, K^2),和前面的注意力做矩阵乘,然后再经过unfold的逆向操作fold,恢复成特征图
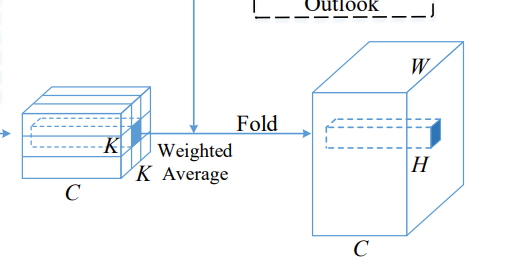
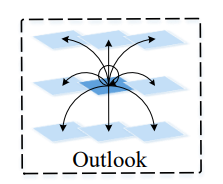
而整个过程相当于从一个位置"往外看",得到注意力权重,我猜这也是作者起名为Outlook的原因
下面是一段伪代码:
# H: height, W: width, K: kernel size
# x: input tensor (H, W, C)
################# initialization #####################
v_pj = nn.Linear(C, C)
attn = nn.Linear(C, k ** 4)
unfold = nn.Unfold(K, padding)
fold = nn.Fold(output_size=(H, W), K, padding)
################# code in forward ####################
def outlook_attention(x):
v = v_pj(x).permute(2, 1, 0)
# Eqn. (3), embedding set of neighbors
v = unfold(v).reshape(C, K*K, H*W).permute(2, 1, 0)
a = attn(x).reshape(H*W, K*K, K*K)
# Eqn. (4), weighted average
a = a.softmax(dim=-1)
x = mul(a, v).permute(2, 1, 0).reshape(C*K*K, H*W)
# Eqn. (5)
x = fold(x).permute(2, 1, 0)
return x
类似Multihead-self-attention机制,作者也对Outlook Attention加入了多头机制
整体模型:¶
下面是模型具体配置,stage1使用outlook attention,stage2使用self attention。

复杂度分析¶
作者列举了self-attention,local-attention和本文的outlook attention的复杂度公式:
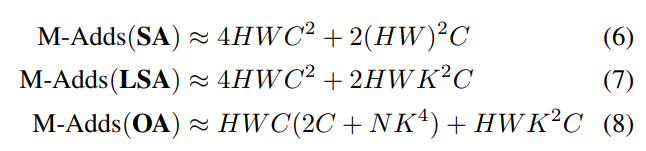
作者取了一个常规case: C=384, K=3, N=6(代表分头数) 由NK^4<2C,从而得到Outlook Attention复杂度更低的结论(但实际配置不完全满足这样的公式假设)
补充一些细节¶
-
不同于VIT无重叠的图像分块,这里的Patch Embedding采用了有重叠的卷积层来操作,并且是4个卷积层叠加(可能对最后准确率有一定帮助)
-
分类部分沿用CaiT的class Attention及相关模块(看来这个是真好用)
-
不同模型分头数不一样,对于小模型D1,分头数为[6, 12, 12, 12], 而对于更大的D3模型,分头数为[8, 16, 16, 16]
结果概览¶
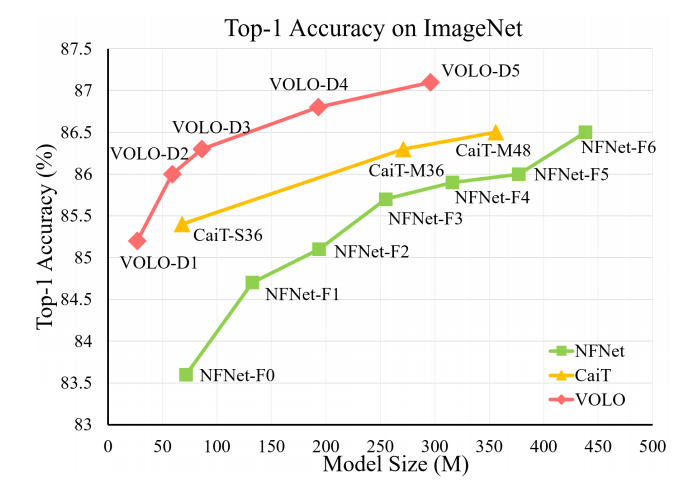
这里只简单放一张分类准确率图片,该模型在ADE数据集分割表现也很好,感兴趣的读者可以到原文查看。
总结¶
这篇工作也是刷了最近分类,分割的榜。这种Attention也很新奇,从一个位置,得到周边位置的注意力权重(个人感觉有点像Involution用在注意力)。 希望能像swin Transformer一样,衍生出其他领域,好用的模型。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次