
题外话¶
刚刚过去的2019年出现了大量Anchor Free的工作,并且这个方向似乎大有可为,不少大佬都在研究这个方向。本着学习的态度,我将从Anchor Free的起源开始讲起,这是一个持续更新的系列。今天先来讲一下CVPR 2015的DenseBox,这项工作算是Anchor Free的起源。不得不说接近3-4年时间,Anchor Free才大火起来,由此看来这篇论文确实高瞻远瞩。论文地址和代码实现见附录。
贡献¶
论文首先提出了一个问题,即如何将FCN(全卷积网络)应用到目标检测?为了解决这一问题,论文提出了DenseBox。即一个可以直接在图像的位置上预测出目标的边界框的端到端网络。论文的主要贡献为:
- 在FCN的基础上提出DenseBox直接检测目标,不依赖候选框。
- 在多任务学习过程中结合了关键点检测进一步提高目标检测的精度。
框架总览¶
DenseBox的整体框架如Figure1所示。
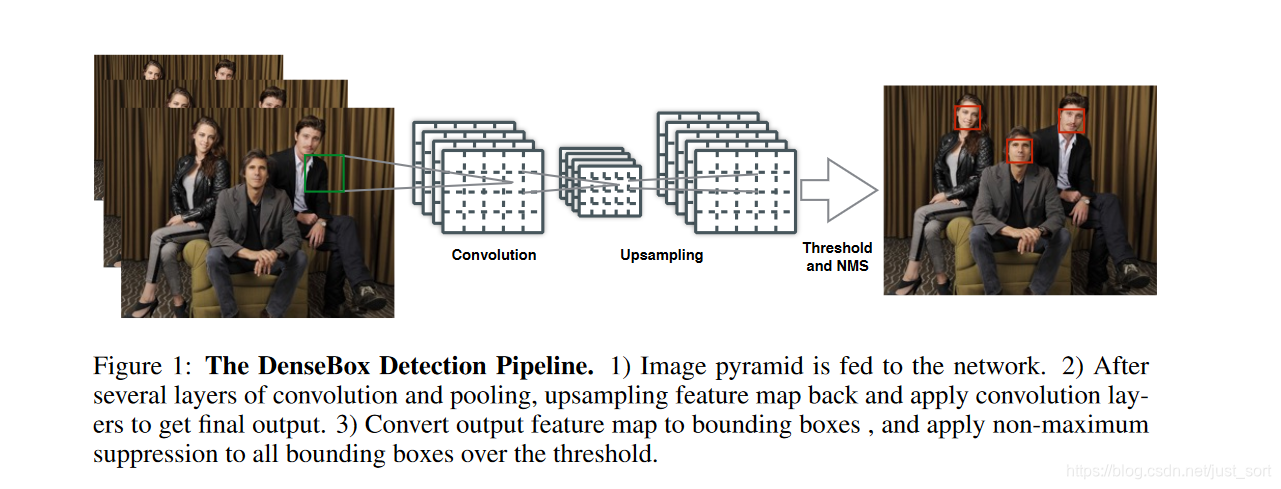
- 首先经过图像金字塔生成多个尺度的图片。
- 图片经过FCN得到最终的输出。
- 将输出特征图转化为边框,并用NMS后处理。
测试阶段¶
在测试时,假设网络输入了一张m\times n的图片,输出为\frac{m}{4}\times \frac{n}{4}的图片且维度为5维,即: t_i={s_i,dx^t=x_i-x_t,dy^t=y_i-y_t,dx^b=x_i-x_b,dy^b=y_i-y_b},其中t代表目标框左上角坐标,b代表目标框右下角坐标,s代表为目标的分数。
生成Ground Truth¶
没有必要将整张图片送入网络进行训练,这样会造成不必要的计算资源消耗。一种有效的方式是对输入图片进行裁剪出包含人脸和丰富背景的patches进行训练。在训练阶段,这些被裁剪的patches区域被resize到240\times 240,其中人脸区域大约占50像素。因此,最后的输出特征图维度为60\times 60\times 5,人脸区域由一个以人脸框的中心为圆心且半径为0.3倍人脸框尺寸的圆形区域来确定。如下图所示:

在Ground Truth的第一个通道,使用0来初始化,如果包含在正样本区域就设置为1。剩下4个通道由该像素点和最相近边界框左上角及右下角的距离来确定。对于patch中存在多张人脸的情况,如果它们落在patch的中心一定范围内(论文取0.8-1.25)那么这些人脸就是正样本,其余的均为负样本。
网络结构¶
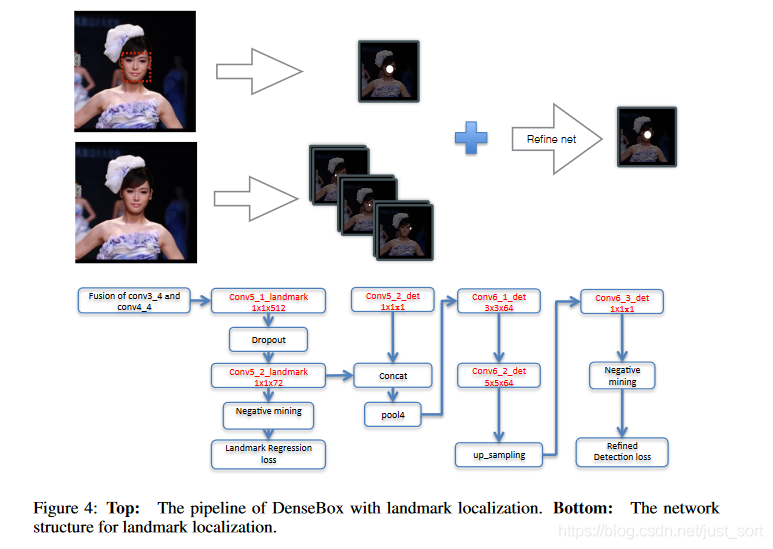
网络结构如Figure3所示,是基于VGG19进行改进,整个网络包含了16个卷积层,前面12层由VGG的预训练权重初始化,输出conv4_4后接了4个1\times 1卷积,前面两个卷积产生通道数为1的分数特征图,后面两个卷积产生4通道的位置预测特征图。
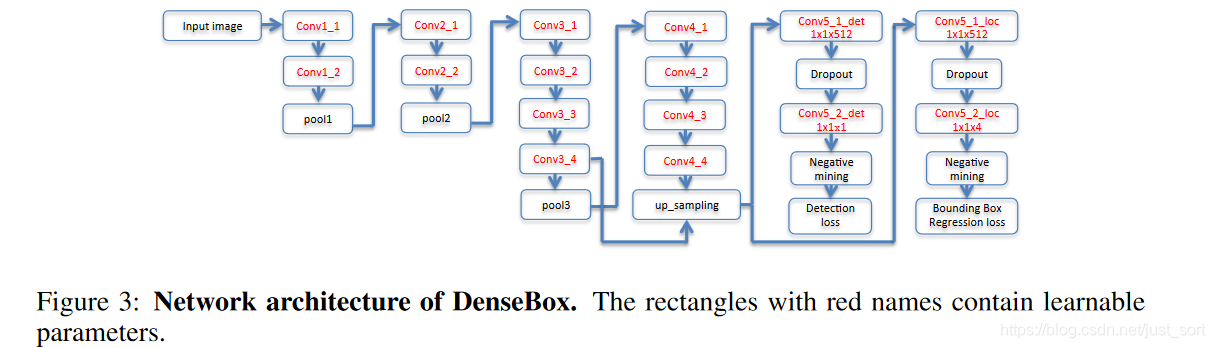
低层次特征关注目标的局部细节,而高层次的特征通过一个较大的感受野来对目标进行识别,感受野越大,语义信息越丰富,越有利于提高准确率。从Figure3中可以看到,论文将conv3_4和conv4_4进行了拼接处理。conv3_4感受野的大小为48\times 48,和本文的训练目标尺寸大小类似,而conv4_4的感受野为118\times 118,可以有效的利用全局的语义信息用于检测。同时conv4_4的特征图尺寸是conv3_4的一半,因此需要将其上采样到和conv3_4相同的分辨率再做融合。
损失函数¶
上面提到,网络的前12层用预训练的VGG19权重来初始化,其余卷积层用xavier初始化.和Faster-RCNN类似,这个网络也有两个输出分支,第一个是输出目标类别分数\hat{y},也即是输出特征图的第一个通道的每个像素值,标签y^{*}={0,1},分类损失定义如下:
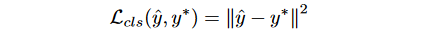
第二个损失是边界框回归损失,定义为最小化目标偏移及预测偏移之间的L2损失:
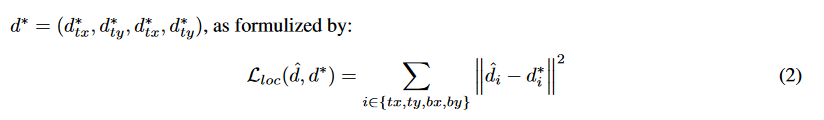
平衡采样¶
在训练过程中,负样本的挑选是很关键的。如果简单的把一个批次中所有的负样本都进行处理,会让模型更倾向于负样本。此外,检测器在处理正负样本边界上的样本时会出现模型“坍塌”。论文提出使用一个二值mask图来决定像素是否为训练样本。注意!!!负样本指的是像素哦,不是指没有人脸的图片哦, 没有人脸的图片根本不会送到网络。
- 忽略灰度区域。 将正负区域之间区域定义为忽略区域,该区域的样本既不是正样本也不是负样本,其损失函数的权重为0。在输出坐标空间中,对于每一个非正标记的像素,只要半径为2的范围内出现任何一个带有正标记的像素,就将f_{ign}设为1。
- Hard Negative Mining。 通过寻找预测困难的样本来提高学习效率。具体方法为在训练过程的前向传播时,按照分类损失将像素降序排列,将top1%定义为困难样本(
hard negtive)。在实验中,将positive和negative的比例设置在1:1。在negative samples中,一半来自于hard-negative,剩余的从非hard-negative中随机采样。为了方便,将被挑选的像素设置标记f_{sel}=1。 - Loss with Mask。 为每个样本\hat{t_i}=({\hat{y_i},\hat{d_i}})(像素)定义mask值M(\hat{t_i}),如下:
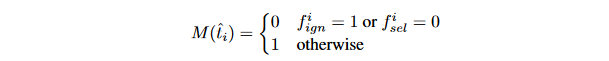
回归损失只对正样本起作用,论文中还将目标框坐标d^{*}进行了归一化,即把坐标除以\frac{50}{4},最后还对回归损失设置了一个惩罚系数\lambda_{loc}=3。
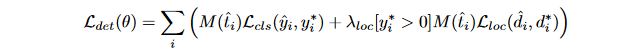
- 其他细节。 将特定尺度图片中心处包含目标中心的输入
patch称为"postive patches"(因为目标中心是一个小圆,所以有包含这一说),这些patches在正样本的周围只包含负样本。论文将输入图片进行随机裁剪并resize到相同大小送入到网络中,这类patch叫"random patches","positive patch"与"random patch"的比例为1:1,另外,为了提升网络的鲁棒性,对每个patch进行了jitter操作,left-right flip,translation shift(25个像素),尺寸变形([0.8,1.25])。使用随机梯度下降算法进行训练,batch_size=10。初始学习率为0.001,每100K迭代,学习率衰减10倍。momentum设置为0.9,权重衰减为0.0005。
利用关键点精炼¶
DenseBox由于是全卷积网络,因此定位关键点可以加几个分支来实现,然后结合关键点heatmaps以及目标分数图来对检测结果进行增强。Figure4展示了增加了一个分支用于关键点定位,假设存在N个关键点,关键点定位分支将会输出N个heatmaps,其中每个像素值代表该位置为关键点的置信度。这个任务的Ground Truth和检测任务的类似,对于一个关键点实例l_i^k,即关键点k的第i个实例,其对应的Ground Truth是位于输出坐标空间中第k个响应图上的positive标记的区域。半径r_l应该设置得比较小避免准确度的损失。和回归任务相似,关键点定位损失也是定义为预测值和真实值的的L2距离损失。同样使用negative mining及ignore region策略。最终整个网络的损失函数改写为:
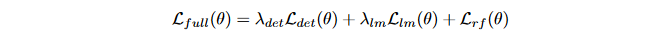
更多的细节请看原文,就不赘述了。
实验¶
在MALF检测任务上的PR曲线如下图所示,其中(a)表示的是不同版本的DenseBox的结果对比(是否带Landmark和是否Ensemble),(b)是不同算法的对比结果。

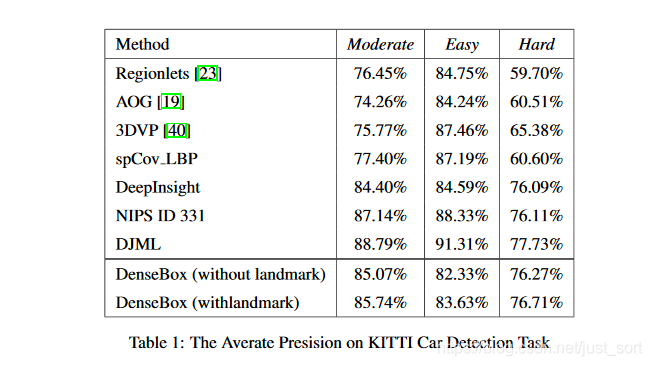
在KITTI 数据集上的AP值测试结果如Table1所示。
同时论文还提供了几组可视化结果如下:


后记¶
本文介绍了Anchor-Free的起源篇DenseBox,最重要的一点是要理解此算法是如何在不使用候选框的条件下得到目标框的思想,这是后面众多Anchor-Free算法的基本出发点。
附录¶
- 论文原文:https://arxiv.org/abs/1509.04874
- 源码:https://github.com/CaptainEven/DenseBox
- 参考:https://www.cnblogs.com/fourmi/p/10771387.html
- 参考:https://zhuanlan.zhihu.com/p/62573122
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次