1. 前言¶
其实之前对图像去雾也没有什么深入的理解,只是了解,实现过一些传统的图像去雾方法而已。个人感觉,在CNN模型大流行的今天,已经有很多人忽略了传统算法的发展,以至于你今天去搜索10年前的传统去雾算法或许根本找不到相关资料了,或许这就是网络中的围城吧。今天周六有空来整理一下我所了解到的图像去雾技术的发展,并尝试做一个详细点的综述。
2. 概述¶
图像去雾在计算机视觉中虽然不像目标检测,语义分割这种任务整天会放在台面上说,但实际上也有大量的研究人员在不断的研究新方法攻克这一充满挑战性的问题。具体来说,图像去雾算法大致可以分为下面这几类。
-
基于图像增强的去雾算法。基于图像增强的去雾算法出发点是尽量去除图像噪声,提高图像对比度,从而恢复出无雾清晰图像。代表性方法有:直方图均衡化(HLE)、自适应直方图均衡化(AHE)、限制对比度自适应直方图均衡化(CLAHE) 、Retinex算法、小波变换、同态滤波 等等。
-
基于图像复原的去雾算法。这一系列方法基本是基于大气退化模型,进行响应的去雾处理。代表性算法有:来自何凯明博士的暗通道去雾算法(CVPR 2009最佳论文)、基于导向滤波的暗通道去雾算法、Fattal的单幅图像去雾算法(Single image dehazing) 、Tan的单一图像去雾算法(Visibility in bad weather from a single image) 、Tarel的快速图像恢复算法(Fast visibility restoration from a single color or gray level image) 、贝叶斯去雾算法(Single image defogging by multiscale depth fusion) ,基于大气退化模型的去雾效果普遍好于基于图像增强的去雾算法,后面挑选的传统去雾算法例子也大多是基于图像复原的去雾算法。
-
基于深度学习的去雾算法。由于CNN近年在一些任务上取得了较大的进展,去雾算法自然也有大量基于CNN的相关工作。这类方法是主要可以分为两类,第一类仍然是于大气退化模型,利用神经网络对模型中的参数进行估计,早期的方法大多数是基于这种思想。第二类则是利用输入的有雾图像,直接输出得到去雾后的图像,也即是深度学习中常说的end2end。
3. 雾天退化模型¶
我们后面介绍的一些经典算法例子大多基于雾天退化模型,因此有必要在这里将它讲清楚。
在计算机视觉领域,通常使用雾天图像退化模型来描述雾霾等恶劣天气条件对图像造成的影响,该模型是McCartney首先提出。该模型包括衰减模型和环境光模型两部分。模型表达式为:
I(x)=J(x)e^{-rd(x)}+A(1-e^{-rd(x)})...........................(1)
其中,x是图像像素的空间坐标,I(x)是观察到的有雾图像,J(x)是待恢复的无雾图像,r表示大气散射系数,d代表景物深度,A是全局大气光,通常情况下假设为全局常量,与空间坐标x无关。
公式(1)中的e^{-rd(x)}表示坐标空间x处的透射率,我们使用t(x)来表示透射率,于是得到公式(2):
I(x)=J(x)t(x)+A(1-t(x)).............................(2)
由此可见,图像去雾过程就是根据I(x)求解J(x)的过程。要求解出J(x),还需要根据I(x)求解出透射率t(x)和全局大气光A。
实际上,所有基于雾天退化模型的去雾算法就是是根据已知的有雾图像I(x)求解出透射率t(x)和全局大气光A。
3.1 如何估计全局大气光值A?¶
- 一,将图像的亮度最大的点的灰度值作为全局大气光值A。
- 二,利用暗通道估计全局大气光值A。在暗通道去雾算法中,从暗原色通道中选取最亮的0.1%比例的像素值,然后选取原输入图像中这些像素具有的最大灰度值作为全局大气光值A。RGB三通道中每一个通道都有一个大气光值。
- 三,分块递归思想估计全局大气光值A。具体思想就是先将图像平均分为四个部分,然后分别求取四个部分中的平均亮度值,选取亮度值最大的块,将这个块平均分为四个块,选取最亮的块,当分解到块的大小达到一定阈值时,在这个块中选取亮度最大的点作为全局大气光A。 可以看到这有一个递归的过程。
- 四,分段思量估计全局大气光值A。我记得这是一个韩国小哥提出的方法,对天空具有天然的免疫性。我们观察一般的图像,天空部分一般被分配在图像的上1/3部分,因此将图像水平分为3个部分,然后在最上的1/3部分使用暗通道估计算法估计全局大气光A。
- 五,快速估计全局大气光值A。首先求取输入图像RGB三通道中的最小值,即求取暗原色通道图像,然后对暗原色通道图像进行均值滤波,然后求取其中灰度值最大的点,接着求取输入图像RGB三通道中值最大的通道图像,然后求取出灰度值最大的点,然后将两个点的灰度值的平均值作为全局大气光A。
3.2 如何估计透射率?¶
3.2.1 暗通道去雾算法估计透射率¶
在3.1节估计出全局大气光值A之后,
根据公式(2)可以得出:
t(x)=\frac{A-I(x)}{A-J(x)}...........................(3)
首先可以确定的是t(x)的范围是[0, 1],I(x)的范围是[0,255],J(x)的范围是[0, 255]。A和I(x)是已知的,可以根据J(x)的范围从而确定t(x)的范围。已知的条件有:
0<=J(x)<=255, 0<=I(x)<=A,0<=J(x)<=A,0<=t(x)<=1...............(4)
=>t(x)>=\frac{A-I(x)}{A-0}=\frac{A-I(x)}{A}=1-\frac{I(x)}{A}..................(5)
根据(4)和(5)推出: 1-\frac{I(x)}{A}<=t(x)<=1..................................(6)
因此初略估计透射率的计算公式:
t(x)=1-\frac{I(x)}{A}...........................................(7)
最后为了保证图片的自然性,增加一个参数w来调整透射率 :
t(x)=1-w\frac{I(x)}{A}..............................(8)
3.2.2 利用迭代思想估计透射率¶
这个算法非常有意义,本人还没来得及复现,先来看看原理。首先,如果想获得更好的去雾效果,就要求去雾后的图像对比度高,并且失真度小。然后对上面的公式(2)做一个变换可以得到: J(x)=\frac{1}{t(x)}I(x)-\frac{A}{t(x)}+A.................(9)
可以发现,J(x)和I(x)在坐标轴上对应一条直线,其中直线和y轴的交点是(0,-\frac{A}{t(x)}),和x轴的交点是(A[1-t(x)], 0)。可以看到随着I(x)在(0,255)的范围内进行变化,J(x)会对应的产生负数或者超过255,这就导致了图像失真。因此为了改善这一缺点,论文提出使用下面的等式来衡量失真度。
E_{loss}=\sum_{c\in (r,g,b)}{(min(0,J_c(x)))^2+(max(0,J_c(x)-255))^2}....................(10)
我们使用均方误差MSE来衡量对比度增强。
E_{contrast}=\sum_{c\in(r,g,b)}\frac{(J_c(x)-J_{mean})^2}{N_{all}}=\sum_{c\in(r,g,b)\frac{(I_c(x)-I_{mean})^2}{t^2N_{all}}}...........(11)
其中,I_{mean}表示平均值,N_{all}表示像素点总数,因此我们要求取透射率使得E_{loss}-E_{contrast}最小。假设t(x)从0.1开始,增强是0.1,一直到1.0结束,一共迭代9次,选取其中使得上式最小的值作为该像素点的透射率。
可以想一下,这种做法会导致什么问题?复杂度会增加10倍! 为了改善这一问题,我们可以假设一小块区域的像素的透射率相同,计算每一小块中E_{loss}-E_{contrast}的最小值为该块所有像素点的透射率。
3.2.3 精细化透射率的例子¶
如何精细化透射率,典型的有以下几种方法:
- Soft matting(暗通道去雾论文中有提到)。
- 双边滤波。
- 导向滤波。(已复现成功,后面分享)。
3.3 后处理¶
上面我们获得了大气光值A以及透射率t(x),那么根据雾天退化模型我们就可以获得去雾后的结果图了。一般来说,去雾后的结果图可能会偏暗,因此可以适当进行一些后处理如采用自动对比度增强,亮度增强,伽马校正 (均在公众号分享了)等图像处理方法进行处理,以便得效果更佳的无雾图像。
OK,现在了解了去雾算法的重要理论接下来就直接开始盘点经典算法。
4. 带色彩恢复的多尺度视网膜增强算法(MSRCR)¶
这篇论文主要提出了一个Retinex理论,包含了两个方面的内容:物体的颜色是由物体对长波、 中波和短波光线的反射能力决定的,而不是由反射光强度的绝对值决定的;物体的色彩不受光照 非均匀性的影响,具有一致性 。 根据Retinex理论,人眼感知物体的亮度取决于环境的照明和物体表面对照射光的反射,其数学表达式为:
I(x,y)=L(x,y)*R(x,y).........(4-1)
其中,I(x,y)代表被观察或照相机接收到的图像信号;L(x,y)代表环境光的照射分量 ;R(x,y)表示携带图像细节信息的目标物体的反射分量 。
将上式两边取对数,则可抛开入射光的性质得到物体的本来面貌,即有关系式:
Log[R(x,y)] = Log[I(x,y)]-Log[L(x,y)]......(4-2)
这个技术运用到图像处理上,就是针对我们现在已经获得的一幅图像数据I(x,y),计算出对应的R(x,y),则R(x,y)认为是增强后的图像,现在的关键是如何得到L(X,Y)。Retinex理论的提出者指出这个L(x,y)可以通过对图像数据I(x,y)进行高斯模糊得到。
因此,算法流程可以总结为:
- 输入: 原始图像数据I(x,y),尺度(也就是所谓的模糊的半径)
- 计算原始图像按指定尺度进行模糊后的图像L(x,y)。
- 按照4-2式的计算方法计算出Log[R(x,y)]的值。
- 将Log[R(x,y)]量化为0到255范围的像素值,作为最终的输出。
具体效果怎么样呢?看张图吧。


5. CVPR 2009 暗通道去雾算法¶
原理见:OpenCV图像处理专栏六 | 来自何凯明博士的暗通道去雾算法(CVPR 2009最佳论文)




6. 基于中值滤波进行去雾¶
算法原理:OpenCV图像处理专栏十 | 利用中值滤波进行去雾


7. A Fast Single Image Haze Removal Algorithm Using Color Attenuation Prior¶
这篇论文就更有意思了哦。论文观察到,单幅图像去雾的难点在于图像中包含的关于场景结构等信息非常少,因此很难获得较为全面的信息从而进行去雾。然而,人的大脑在面对一幅图像的时候其实是可以很快的分辨清楚哪里有雾、哪里没有,或者很快分辨清楚近景、远景而不需要其他太多的资料。基于这一思考,作者对很多副有雾图像进行分析发现统计意义上的结论从而提出一个新的思路,通过对很多图像的远景、中景、近景进行分析发现了雾的浓度与亮度和饱和度之差呈正比。
作者通过2幅图像分析了有雾和无雾图像的区别:
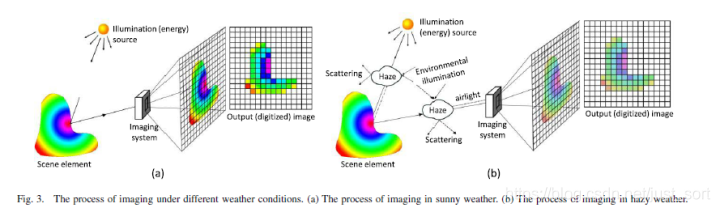
我们知道,雾天退化模型可以写成:
I(x)=J(x)t(x)+A(1-t(x))
从Figure3中可以看到直接的衰减会导致反射能量的减弱,从而导致brightness的低值,也即J(x)t(x)。同时,大气光成分会增强brightness的值并且降低饱和度saturation。 总结下来,即为,当雾的程度越大,大气光成分的的影响越大。因此,论文考虑通过研究saturation和brightness之间的差来分析雾的浓度。公式为:
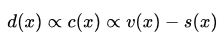
其中d(x)为景深,c(x)为雾浓度,v(x),s(x)分别为亮度值和饱和度值。这个公式就是color attenuation prior。然后,作者通过构建训练样本采集了超过500张图像,最后得出了合适的参数。最终公式如下:
d(x)=\theta_0+\theta_1v(x)+\theta_2s(x)+ \varepsilon (x)
最终,参数结果为:
d(x)=0.121779+0.959710v(x)-0.780245s(x)+\varepsilon(x)
论文地址为:http://ieeexplore.ieee.org/document/7128396/。
8. 中部小结¶
上面列出了一些经典的用传统算法去雾的例子(姑且把它叫作图像去雾的前世),接下来我们看看CNN是如何在这个领域发挥的(图像去雾的今生)。
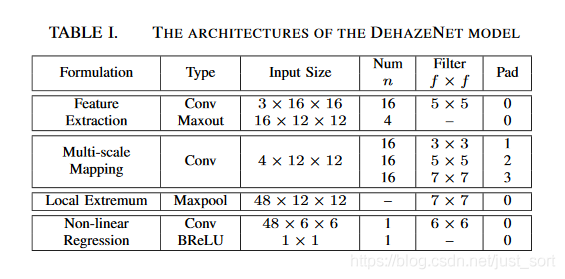
9. 2016 华南理工DehazeNet¶
论文和代码下载官方地址:http://caibolun.github.io/DehazeNet/
这篇论文是较早使用深度学习来进行去雾的网络,它是一个端到端的模型,利用CNN来对大气退化模型中的t(x)进行估计。模型输入雾图,输出透射率t(x)映射图,然后通过大气退化模型来恢复无雾图像。采用深度CNN结构(4层),并提出了一种新的非线性激活函数。提高了恢复图像的质量。
DehazeNet的贡献如下:
- end2end系统,直接学习并估计传输率与有雾图像的关系。
- 提出nonlinear激活函数,称为BReLU(双边ReLU),取得了更好的恢复效果。
- 分析了DehazeNet与已有去雾技术之间的关系。
具体来说,作者先对暗通道去雾,最大对比度去雾(Maximum Contrast,MC,论文名为:Visibility in bad weather from a single image),基于颜色衰减先验去雾(Color Attenuation Prior,CAP,论文名为:A fast single image haze removal algorithm using color attenuation prior),基于色度不一致去雾(A fast single image haze removal algorithm using color attenuation prior)这些方法做了介绍,然后作者结合上面的方法进行网络设计,网络结构主要分成4大部分:
- 特征提取。
- 多尺度映射。
- 局部极值。
- 非线性回归。
网络结构如下图所示。
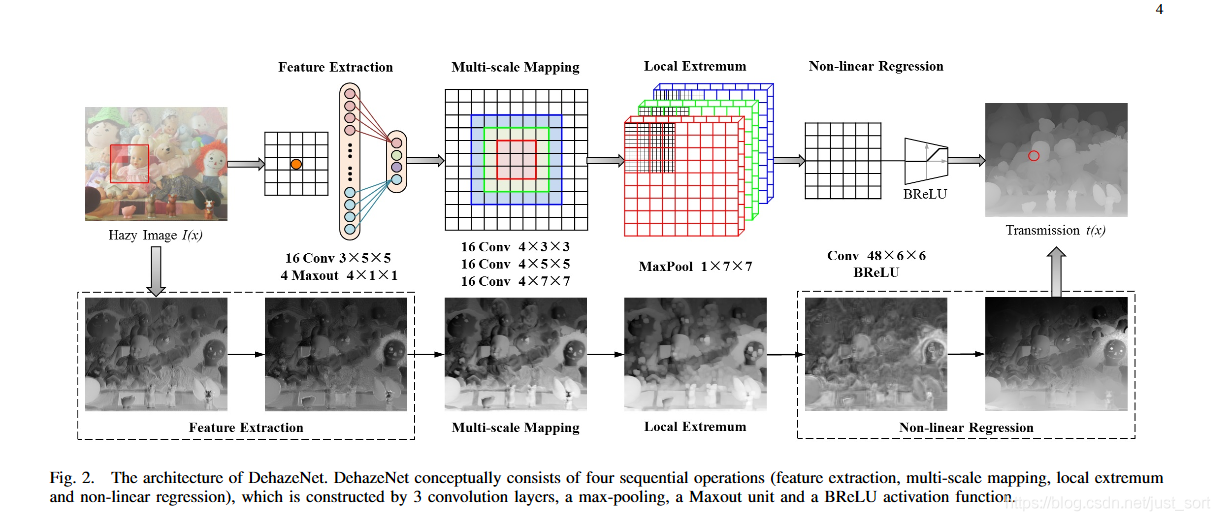
9.1 特征提取¶
这里的特征提取和普通的CNN不同,这里采用“卷积+Maxout”的结构作为网络第一层。如下面公式所示:
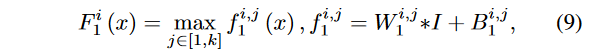
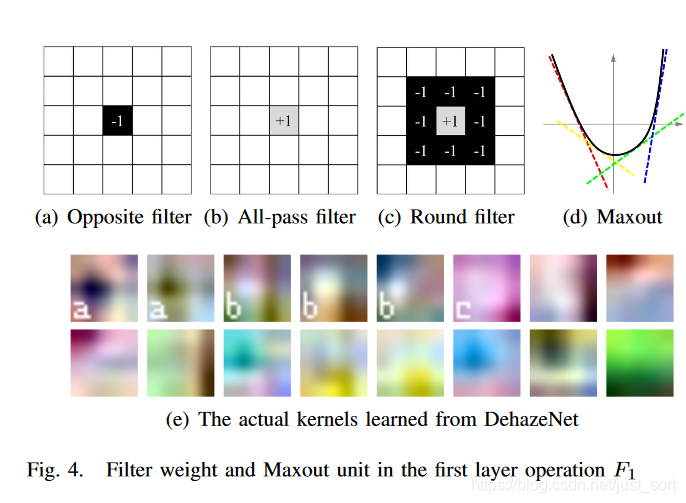
其中F表示输出的特征,i代表第i个,1是是指第一层,k是指k个层进行Maxout操作。W和B是权重和偏置。 第一层是特征提取层,即提取有雾图像特征。本文中使用了16个滤波器,通过Maxout Unit的激活函数,每四个输出一张图。这里不Padding,输入是3*16*16三通道的块。输出的是四个12*12,每一个代表一种特征。
作者指出,“卷积+Maxout”等价于传统的手工去雾特征。当W1是反向(Opposite)滤波器,通道的最大等价于通道的最小值,等价于暗通道先验(DCP);当W1是环形(Round)滤波器, 等价于对比度提取,等价于最大对比度(MC);当W1同时包含反向(Opposite)滤波器和全通(All-pass)滤波器,等价于RGB到HSV颜色空间转换,等价于颜色衰减先验(CAP)。此外,从机器学习角度,Maxout是一种样条函数,具有更强的非线性拟合能力,如图(d)。
9.2 多尺度映射¶
使用空间多个尺度的卷积。分别使用16个3\times 3,5\times ,7\times 7的卷积核和特征图进行卷积,最后一共获得48个12\times 12大小的特征图。
9.3 局部极值¶
根据假设,透射率具有局部不变性,所以使用了一个Max Pooling层(7\times 7大小)抑制透射率的估计噪声。
9.4 非线性回归¶
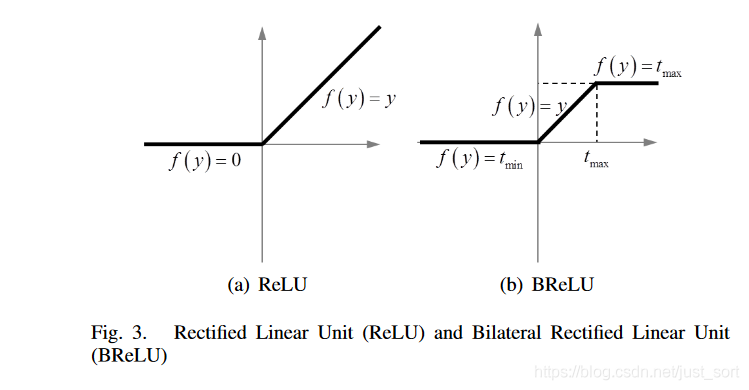
大气透射率t(x)是一个概率(0到1),不可能无穷大,也不可能无穷小。受到Sigmoid和ReLU激励函数的启发,提出了新的激活函数(Bilateral Rectified Linear Unit,BReLU),在双边约束的同时,保证局部的线性。激活函数图如下:
9.5 训练¶
要获取自然场景的有雾和无雾的图像是十分困难的,所以作者使用了基于物理雾霾形成模型的综合训练集。从网络上收集的图像中随机抽样10,000个大小为16\times 16的无雾霾patch。对于每个patch,作者统一采样10个t以生成10个模糊patch,这里为了减小变量学习的不确定性,将大气光A设置为1,共生成100,000个16\times 16的数据。损失函数被定义为:
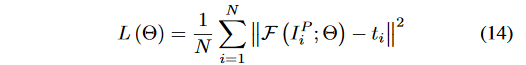
10. ICCV 2017 AOD-Net¶
论文名为:All-in-One Network for Dehazing and Beyond
这篇文章文并没有单独估计t(x)和大气光A,而是通过轻量级的CNN直接生成清晰的图像,这种端到端的设计使得其可以嵌入到其他的模型中,比如说物体检测Faster-RCNN。
这篇文章的贡献如下: - 提出了一个end2end的去雾模型,完成了有雾图像到清晰图像之间的转化。通过K(x)将t(x)与A统一,基于K(x)可以完成对清晰图像的重构。 - 提出了新的比较去雾效果的客观标准,定量研究去雾质量是如何影响后续高级视觉任务的,同时,其模型可以和其他深度学习模型无缝嵌套。
由雾天退化模型知可以知道,表达式中有两个未知数大气光A和透射率t(x),作者提出将这两个未知数化为一个,即用K(x)将A与t(x)相统一。其中,b是具有默认值的恒定偏差。
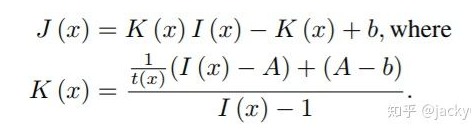
网络结构如下:
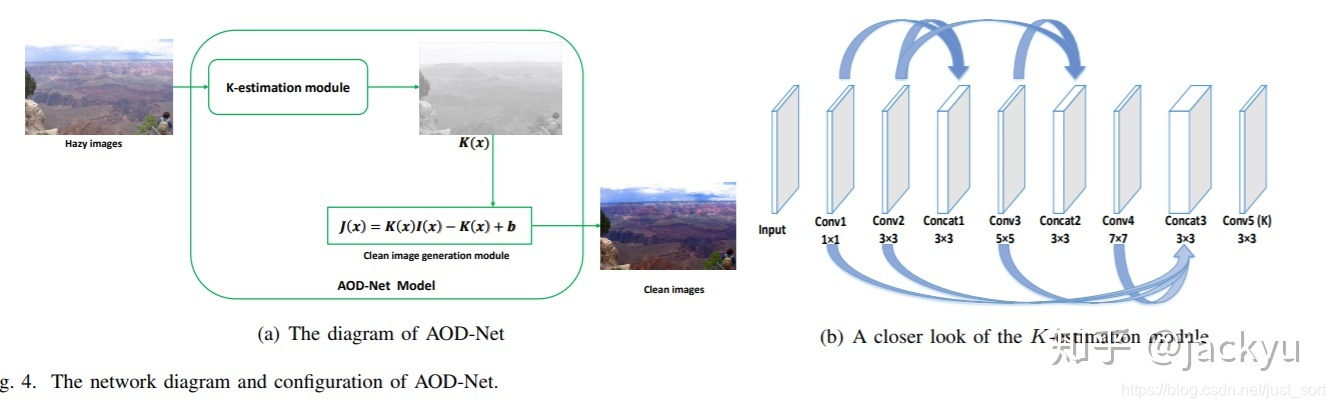
其中,K-estimation Module是利用输入图像I(x)对未知变量K(x)进行估计。而Clean image generation module 是将估计所得的K(x)作为自适应变量输入网络,得到J(x)。K-estimation Module 有点意思,作者是受到DehazeNet,MSCNN的启发,使用五个卷积层,并通过融合不同大小的滤波器形成多尺度特征。值得注意的是,AOD-Net的每个卷积层仅仅使用了3个卷积核。
11. CVPR 2018 DCPDN¶
论文标题: Densely Connected Pyramid Dehazing Network
论文的贡献如下:
- 提出一个基于去雾公式的端到端的网络。
- 一个保边的密集连接的编解码网络生成t。
- 为了获得去雾后的图和t之间的关联性,使用判别器对它们进行联合训练。
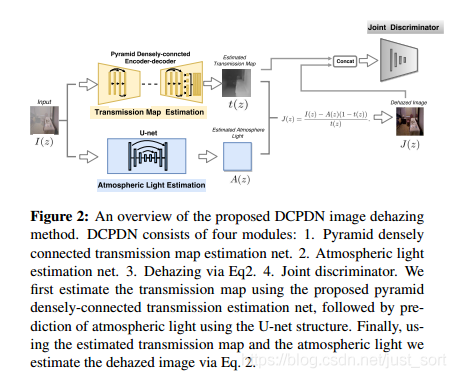
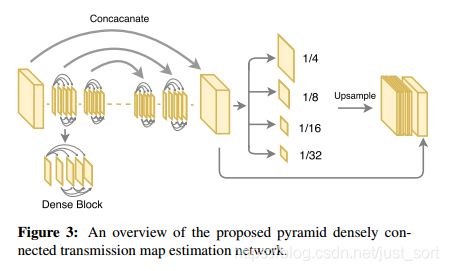
具体而言,对于产生t图的网络,采用的是多层金字塔池化模块。这里从DenseNet里直接取前三个DenseBlock和相应的下采样层作为Encode模块,然后同样使用DenseBlock进行上采样。这样做的目的是可以通过金字塔池化获得全局的信息,Dense模块可以让利于信息流动,加速收敛。同时为了,为了最后的输出获得多个scale的特征,同时保留这些特征的局部信息而不是只获得全局信息,这里使用了一个多scale的pooling层,将不同级别的特征pooling到同一个尺度下,然后进行上采样。网络示意图如下所示:
而对于A,使用一个8个Block的UNet。
12. WACV 2019 GCANet¶
论文标题:Gated Context Aggregation Network for Image Dehazing and Deraining 这篇论文用GAN网络,实现可端到端的图像去雾,本文的重点在于解决了网格伪影(grid artifacts)的问题,该文章的方法在PSNR和SSIM的指标上,有了极大的提升,非常值得借鉴。
本文贡献如下:
- 提出端到端的去雾网络,不依赖于先验。
- 采用了smooth dilated convolution 代替原有的dilated convolution,解决了原来的dilated convolution导致的grid artifacts问题。
- 提出了一个gated fusion sub-network,融合high-level 及low-level 特征,提升复原效果。
网络结构如Figure1所示,三个卷积模块作为编码部分,一个反卷积和两个卷积作为解码部分在二者之间插入多个smoothed dilated resblocks。
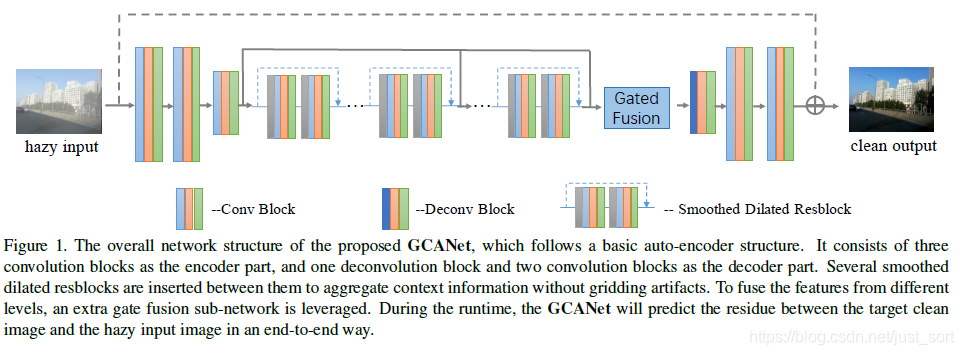
12.1 Smoothed Dilated Convolution(平滑空洞卷积)¶
从昨天的推文【综述】神经网络中不同种类的卷积层 我们了解了空洞卷积。但空洞卷积有一个缺点,它会产生网格伪影,针对这一问题,作者用了一个简单的分离卷积。
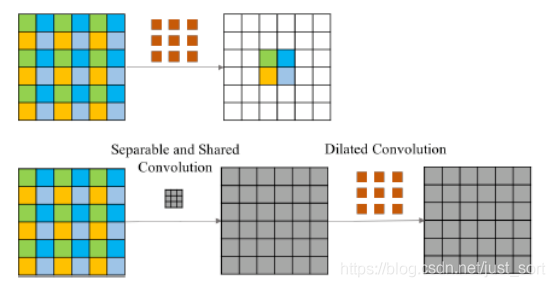
在上图中,上面这部分表示的是原始的空洞卷积,从图中色块可以看出,经过空洞率大于1的空洞卷积后,输出的特征图中相邻的特征值与输入特征图是完全独立的,不存在相互依赖的关系,而我们知道图像是局部相关的。因此,特征层也应当保留此特性。所以下面部分的图就是Smoothed Dilated Convolution了,在执行空洞卷积之前,做了一次核为2\times r-1的分离卷积,卷积的参数共享,经过该层卷积之后,每一个特征点都融合了周围2\times r-1大小的特征。该操作仅仅增加了(2\times r-1)\times (2\times r-1)大小的参数,却能有效的解决网格伪影问题。
12.2 Gated Fusion Sub-network(门控融合子网)¶
这个子网络主要是融合了不同层次的特征信息,和ASFF太像了。。。之前的网络都是直接添加直连(shortcut)操作进行信息融合,这里的门控融合单元为不同层次的特征分别学习了权重,最后加权得到融合的特征层。
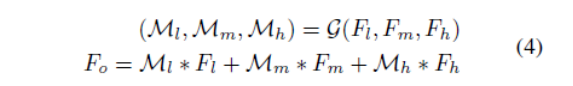
12.3 损失函数¶
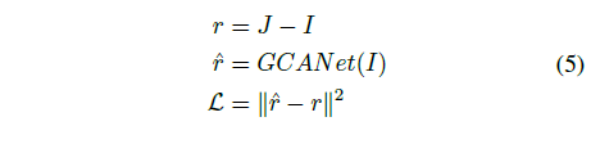
13. AAAI 2018 Disentangled Dehazing Network¶
论文标题:Towards Perceptual Image Dehazing by Physics-based Disentanglement and Adversarial Training
作者认为之前基于先验知识的去雾,缺点在于先验知识不是在任何情况都满足的(比如说多光源,大雾),并且不是监督训练的。而基于CNN的去雾需要训练集是成对的,即同时有有雾图像与无雾图像。而一个有效的去雾模型应该能够学习无雾图像到有雾图像的映射,无需使用成对监督。并且人类对去雾后的图像和没去雾的图像的感知应当是一致的,基于此,作者提出这个Disentangled Dehazing Network,主要贡献如下:
- 提出一种基于解耦的新型去雾网络。
- 收集了具有挑战性的数据集,包含800多个自然模糊图像与1000个无雾的室外场景图像。
- 通过对合成和真实图像的数据集的广泛实验来评估感知图像去雾。
一句话总结,将GAN用于去雾。
13.1 解耦网络 Disentangled Dehazing Network¶
论文引入基于解耦与重建的物理模型,目标是将有雾图像解耦为隐藏特征值,再利用隐藏特征值重建图像。网络的总体结构如Figure1所示。

13.2 损失函数¶
损失函数包含三部分,重建损失,对抗损失,正则化损失。 - 重建损失。使用L1损失函数。
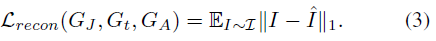
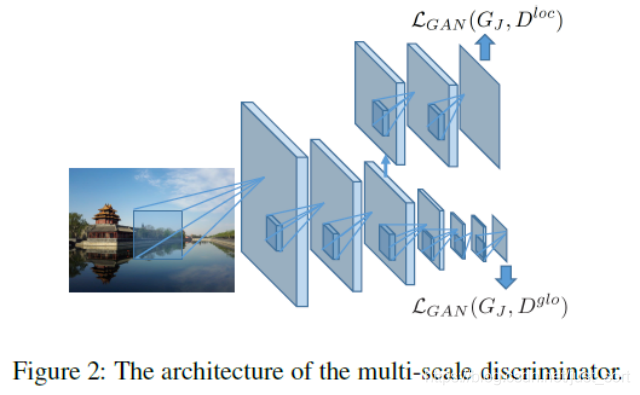
- 多尺度对抗损失。为了生成更真实的图像,作者其对中间输出J引入了多尺度生成训练,受到(Isola et al. 2017) and (Zhu et al. 2017)启发,作者使用了patch-level discriminator,并进行了改进,使用了局部鉴别器和全局鉴别器。如Figure2所示。
- 正则化损失。在该部分,借鉴了前人的经验,使用medium transmission map的平滑性作为正则化损失。
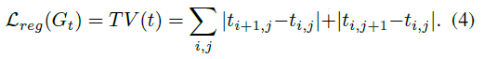
最后,总的损失函数为:
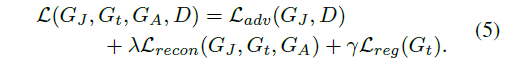
目标函数为:
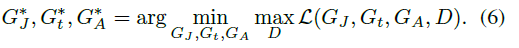
13.3 图像恢复¶
经过网络处理后,可以得到两个去雾后的图像,一个是生成器G_J的直接输出,另一个是利用估计的t(x)和A来获得的。这两种方法得到的去雾图像各有优劣,其中生成器输出得到的图像倾向于生成具有更多纹理细节的图像,并且在感知上更加清晰,但是其易于受到噪声的影响并且会有undesirable artifacts,而用后种方式得到的图像更平滑,所以作者将二者进行了混合。公式如下:
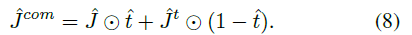
14. CVPR 2018 Cycle-Dehaze¶
论文题目:Enhanced CycleGAN for Single Image
这篇论文是基于《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》来做改进的,前者设计了一个循环的对抗网络学习图像风格的迁移,使用不成对的图像来训练网络。这篇论文在其基础上加入了循环感知一致损失,对图片的特征进行监督。其实可以总结为一句话,改造CycleGAN用于去雾。
没兴趣去看这篇论文了,就不细讲了,感兴趣可以去读一读。
15. 总结¶
今天是周六,花了很长的时间来盘点我所认识的图片去雾,可以看到这并不是一件简单的事。通过对图像去雾的前世今身的了解,相信你和我一样对图像去雾有了更好一点点的认识了吧。
16. 参考¶
https://blog.csdn.net/u013684730/article/details/76640321
https://zhuanlan.zhihu.com/p/28942127
https://blog.csdn.net/Julialove102123/article/details/80199276
https://zhuanlan.zhihu.com/p/47386292
https://kevinj-huang.github.io/2019/03/03/%E5%8D%9A%E5%AE%A287/
http://www.cnblogs.com/jingyingH/p/10061286.html
https://blog.csdn.net/suixinsuiyuan33/article/details/7945106
本文总阅读量次