前言¶
前天发了一个推文【目标检测Anchor-Free】CVPR 2019 CenterNet,讲解的是CenterNet: Keypoint Triplets for Object Detection这篇论文,今天要讲的这篇论文全名是Object as Points。这篇论文提出的网络也被叫作CenterNet,和前面介绍的CenterNet重名了,注意加以区别。论文原文见附录。
摘要:目标检测往往是在图像上将目标以矩形框的形式标出。大多数先进的目标检测算法都是基于Anchor框来穷举可能出现目标的位置,然后针对该位置进行目标的分类和回归,这种做法浪费时间,低效,并且需要额外的后处理(NMS)。这篇论文使用不同的方法,构建模型时将目标作为一个点,即目标BBox的中心点。并且检测器使用关键点估计来找到中心点,并回归其它的目标属性,例如尺寸,3D位置,方向,甚至姿态。这个模型被论文叫做CenterNet,这个模型是端到端可微的,更简单,更快速,更准确。下面是其性能:1:Resnet-18 with up-convolutional layers : 28.1% coco and 142 FPS 。2:DLA-34 : 37.4% COCOAP and 52 FPS 。3:Hourglass-104 : 45.1% COCOAP and 1.4 FPS。
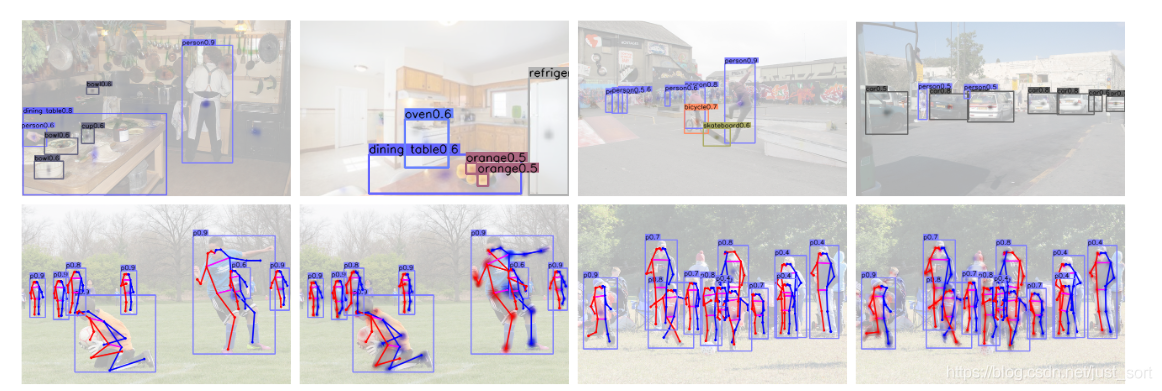
下面的Figure2展示了使用CenterNet目标检测器检测目标的一个可视化效果。
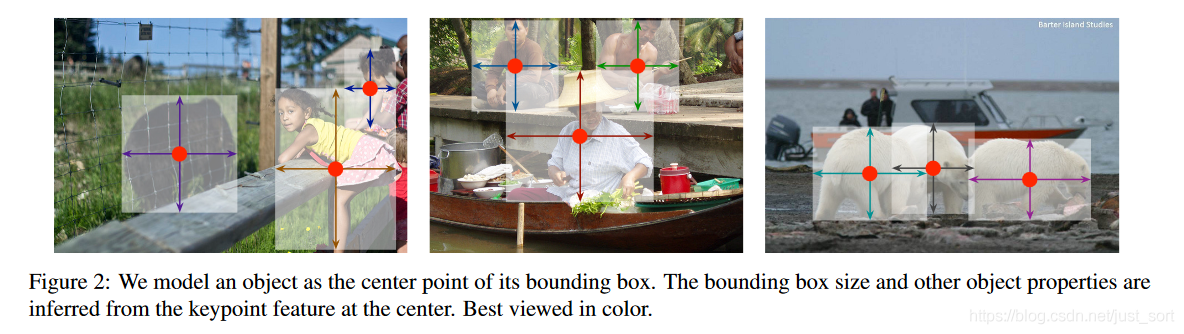
贡献¶
CenterNet的创新点如下: - 用heatmap预测的目标中心点代替Anchor机制来预测目标,使用更大分辨率的输出特征图(相对于原图缩放了4倍),因此无需用到多层特征,实现了真正的Anchor-Free。CenterNet和Anchor-Based检测器的区别如Figure3所示。
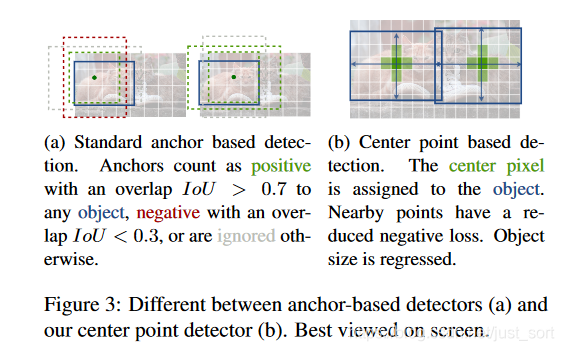
- 网络可拓展性非常强,论文中介绍了实现3D目标检测和人体姿态估计任务。具体来说对于3D目标检测,直接回归得到目标的深度信息,3D目标框的尺寸,目标朝向;对于人体姿态估计来说,将关键点位置作为中心的偏移量,直接在中心点回归出这些偏移量的值。例如对于姿态估计任务需要回归的信息如Figure4所示。
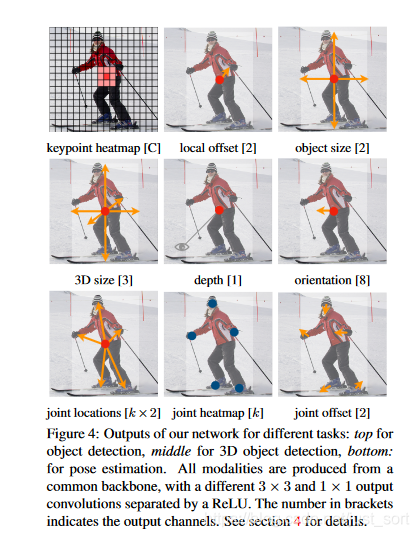
- 由于模型设计简单,因此在运行速度和精度的平衡上取得了很好的结果。
网络设计¶
网络结构¶
CenterNet的网络结构如Figure6所示。对于2D目标检测任务来说,CenterNet输入512\times 512分辨率的图像,预测2个目标中心点坐标和2个中心点的偏置。以及80个类别信息。其中Figure6(a)表示Hourglass-104,Figure6(b)表示带有反卷积做上采样的ResNet-18,Figure6(c)表示经典的DLA-34网络,而Figure6(d)表示改进的DLA-34网络。
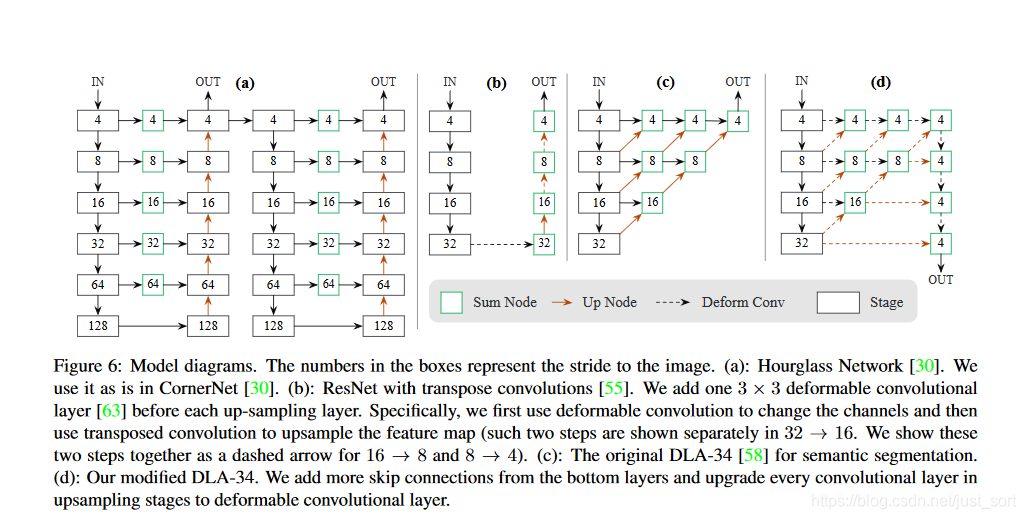
注意这几个结构都是Backbone网络,最后只需要在输出特征图上接卷积层映射结果即可。比如在目标检测任务中,用官方的源码(使用Pytorch)来表示一下最后三层,其中hm为heatmap、wh为对应中心点的width和height、reg为偏置量:
(hm): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1))
)
(wh): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
(reg): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
前置内容¶
令I\in R^{H\times W\times 3}为输入图像,宽为W,高为H。我们的目标是生成关键点热力图\hat{Y}\in [0,1]^{\frac{W}{R} \times \frac{H}{R}\times C},其中R是输出步长(即尺度缩放比例),C是关键点参数(即输出特征通道数);关键点类型有C=17的人体关键点,用于姿态估计。C=80的目标类别,用于目标检测。我们默认R=4;\hat{Y}_{x,y,c}=1表示检测到的关键点,而\hat{Y}_{x,y,c}=0表示背景。我们采用了几个不同的全卷积编码-解码网络来预测图像I得到的\hat{Y}。我们在训练关键点预测网络时参考了CornerNet,对于ground truth的关键点c,其位置为p\in R^2,计算得到低分辨率(经过下采样)上对应的关键点为:
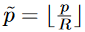
我们将GT坐标通过高斯核
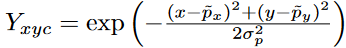
分散到热力图Y\in [0,1]^{\frac{W}{R} \times \frac{H}{R}\times C}上,其中\sigma_p是目标尺度-自适应的标准方差。如果某一个类的两个高斯分布发生了重叠,直接取元素间最大的就可以。训练目标函数如下,像素级逻辑回归的Focal Loss:
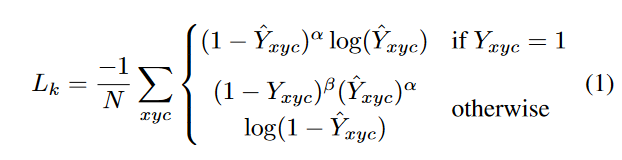
其中\alpha和\beta是Focal Loss的超参数,实验中分别设为2和4,N是图像I中的关键点个数,除以N主要为了将所有Focal Loss归一化。
由于图像下采样的时候,GT的关键点会因数据是离散的而产生偏差,我们对每个中心点附加预测了个局部偏移\hat{O}\in R^{\frac{W}{R}\times \frac{H}{R}\times 2},所有类别共享一个偏移预测,这个偏移用L1损失来训练。
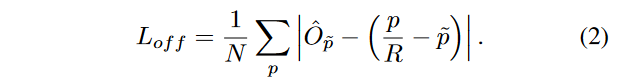
关键点估计用于目标检测¶
令(x_1^{(k)},y_1^{(k)},x_2^{(k)},y_2^{(k)})是目标k(其类别为c_k)的bbox,其中心位置为p_k=(\frac{x_1^{(k)}+x_2^{(k)}}{2},\frac{y_1^{(k)}+y_2^{(k)}}{2}),我们使用关键点估计\hat{Y}来得到所有的中心点。此外,为每个目标k回归出目标的尺寸s_k=(x_2^{(k)}-x_1^{(k)},y_2^{(k)}-y_1^{(k)})。为了减少j计算负担,我们为每个目标种类使用单一的尺度预测\hat{S}\in R^{\frac{W}{R}\times \frac{H}{R}\times 2},我们在中心点添加了L1损失。
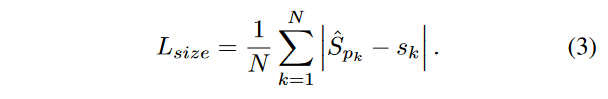
我们不进行尺度归一化,直接使用原始的像素坐标来优化损失函数,为了调节该Loss的影响,将其乘了个系数,整个训练的损失函数为:
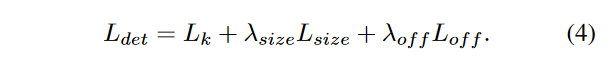
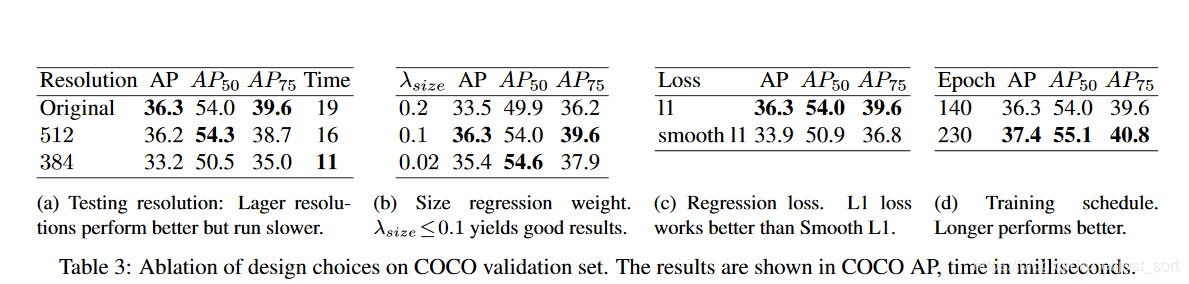
实验中,取\lambda_{size}=1,\lambda_{off}=1,整个网络会在每个位置输出C+4个值(即关键点类别C, 偏移量的x,y,尺寸的w,h),所有输出共享一个全卷积的Backbone。
从点到边界框¶
在推理的时候,我们分别提取热力图上每个类别的峰值点。如何得到这些峰值点呢?做法是将热力图上的所有响应点与其连接的8个临近点进行比较,如果该点响应值大于或等于其8个临近点值则保留,最后我们保留所有满足之前要求的前100个峰值点。令\hat{P_c}是检测到的c类别的n个中心点的集合,每个关键点以整型坐标(x_i,y_i)的形式给出。\hat{Y_{x_iy_ic}}作为预测的得到的置信度,产生如下的bbox:
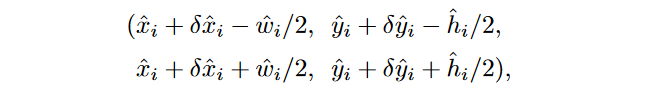
其中(\delta \hat{x_i},\delta \hat{y_i})=\hat{O_{\hat{x_i},\hat{y_i}}}是偏移预测结果,(\hat{w_i},\hat{h_i})=\hat{S_{\hat{x_i},\hat{y_i}}}是尺度预测结果,所有的输出都直接从关键点估计得到,无需基于IOU的NMS或者其他后处理。
3D目标检测¶
3D目标检测是对每个目标进行3D bbox估计,每个中心点都需要三个附加信息:depth,3D dimension, orientation。我们为每个信息分别添加head。对于每个中心点,深度值depth是一个维度的。然后depth很难直接回归,因此论文参考【D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS, 2014.】对输出做了变换,即d=\frac{1}{\sigma(\hat{d})}-1,其中\sigma是sigmoid函数,在特征点估计网络上添加了一个深度计算通道\hat{D}\in [0,1]^{\frac{W}{R}\times \frac{H}{R}},该通道使用了由ReLU分开的两个卷积层,我们用L1损失来训练深度估计器。
目标检测的3D维度是3个标量值,我们直接回归出它们(长宽高)的绝对值,单位为米,用的是一个独立的head和L1损失:
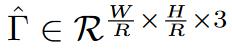
目标方向默认是单标量的值,然而这也很难回归。论文参考【A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka. 3d bounding box estimation using deep learning and geometry. In CVPR, 2017.】用两个bins来呈现方向,并在bins中做回归。特别地,方向用8个标量值来编码的形式,每个bin有4个值。对于一个bin,两个值用作softmax分类,其余两个值回归在每个bin中的角度。
姿态估计¶
人体姿态估计旨在估计图像中每个人的k个2D关键点位置(如在COCO上,k为17,即每个人有17个关键点)。因此,中心点回归分支的维度是k\times 2的,然后我们直接回归出关节点的偏移(像素单位)\hat{J}\in R^{\frac{W}{R} \times \frac{H}{R} \times k\times 2},用到了L1 loss;我们通过给Loss添加Mask方式来无视那些不可见的关键点(关节点)。此处参照了Slow-RCNN。为了精细化关键点,我们进一步估计k个人体关键点热力图\hat{\Phi}\in R^{\frac{W}{R}\frac{H}{R}\times k},使用的是标准的bottom-up 多人体姿态估计,我们训练人的关节点热力图时使用Focal Loss和像素偏移量,这块的思路和中心点的训练类似。我们找到热力图上训练得到的最近的初始预测值,然后将中心偏移作为一个分组的线索,来为每个关键点(关节点)分配其最近的人。具体来说,令(\hat{x}.\hat{y})表示检测到的中心点,第一次回归得到的关节点为:
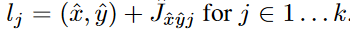
我们提取到的所有的关键点为(关节点,此处是类似中心点检测用热力图回归得到的,对于热力图上值小于0.1的直接略去):
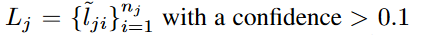
然后将每个回归(第一次回归,通过偏移方式)位置 l_j与最近的检测关键点(关节点)进行分配:
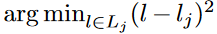
注意,只对检测到的目标框中的关节点进行关联。
实现细节¶
论文实验了4个结构:ResNet-18, ResNet-101, DLA-34, Hourglass-104。并且使用用deformable卷积层来更改ResNets和DLA-34,按照原样使用Hourglass 网络。得到的结果如下:
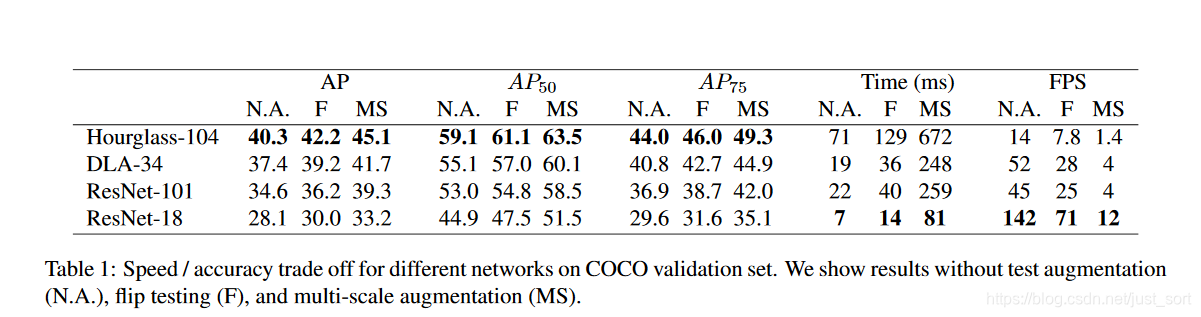
- Hourglass 堆叠的Hourglass网络通过两个连续的hourglass模块对输入进行了4倍的下采样,每个hourglass 模块是个对称的5层 下和上卷积网络,且带有skip连接。该网络较大,但通常会生成最好的关键点估计。
- ResNet-18 Xiao et al. [55]等人对标准的ResNet做了3个up-convolutional来获得更高的分辨率输出(最终stride为4)。为了节省计算量,论文改变这3个up-convolutional的输出通道数分别为256,128,64。up-convolutional核初始为双线性插值。
-
DLA 即Deep Layer Aggregation (DLA),是带多级跳跃连接的图像分类网络,论文采用全卷积上采样版的DLA,用deformable卷积来跳跃连接低层和输出层;将原来上采样层的卷积都替换成3x3的deformable卷积。在每个输出head前加了一个3\times 3\times 256的卷积,然后做1x1卷积得到期望输出。
-
训练 训练输入图像尺寸:512x512; 输出分辨率:128x128 (即4倍stride);采用的数据增强方式:随机flip, 随机scaling (比例在0.6到1.3),裁剪,颜色jittering;采用Adam优化器;在3D估计分支任务中未采用数据增强(scaling和crop会影响尺寸);其它细节见原文。
实验结果¶
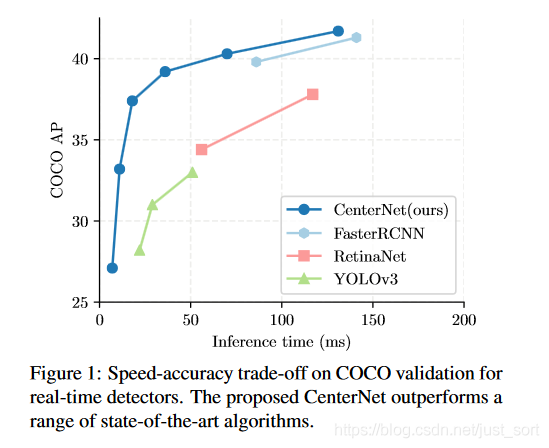
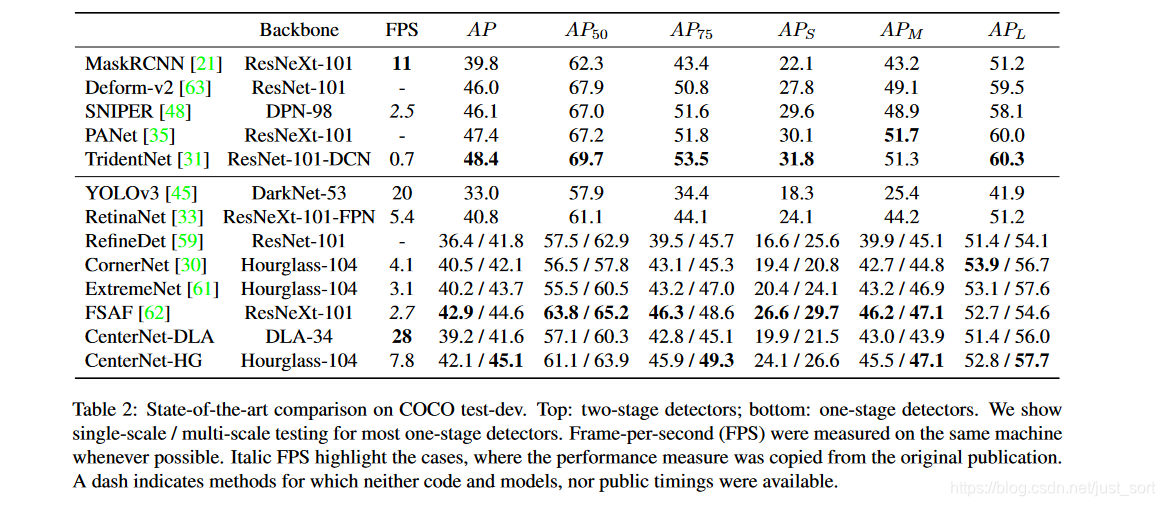
可以看到CenterNet的精度吊打了YOLOv3,并且完全的Anchor-Free使得我们看到了目标检测更好的思路,这篇论文我觉得应该是2019年目标检测领域最有价值的论文之一了。
贴一个预测可视化效果图看看。
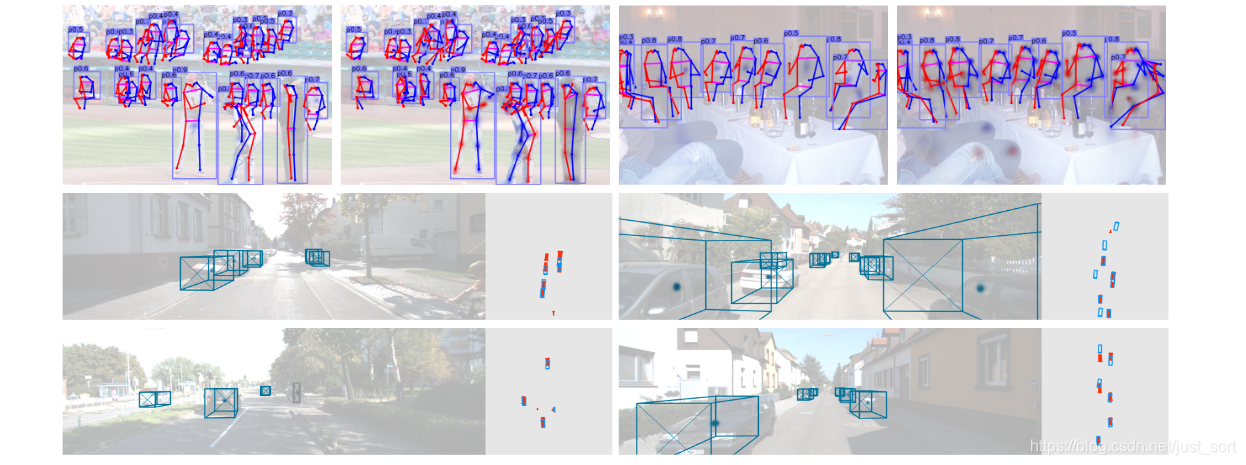
结论¶
这篇论文可以让我们理解什么是真正的Anchor-Free,并且另外一个重要点的是这种方法将检测,姿态估计,甚至分割都可以统一起来,做法十分优雅。不过CenterNet仍有缺点,例如在图像中,同一个类别中的某些物体的GT中心点,在下采样时会挤到一块,也就是两个物体在GT中的中心点重叠了,CenterNet对于这种情况也是无能为力的,可能结果就是只能检测一个目标了,不过这种密集检测的问题本就是这个领域仍未解决的难题,只能期待大牛后续工作了。对我们工程派来说,没有NMS后处理以及这种统一多个任务的思想实在是一剂强心针,这个方向的学术研究和工程部署应该会逐渐成熟的。
附录¶
- 论文原文:https://arxiv.org/pdf/1904.07850.pdf
- 代码:https://github.com/xingyizhou/CenterNet
- 参考:https://blog.csdn.net/c20081052/article/details/89358658
同期文章¶
- 目标检测算法之Anchor Free的起源:CVPR 2015 DenseBox
- 【目标检测Anchor-Free】ECCV 2018 CornerNet
- 【目标检测Anchor-Free】CVPR 2019 ExtremeNet(相比CornerNet涨点5.3%)
- 【目标检测Anchor-Free】CVPR 2019 CenterNet
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次