UTNet:用于医学图像分割的混合 Transformer 网络阅读笔记
文章目录¶
- 1 概述
- 2 浅析 Transformer 架构
- 2.1 重看 Self-attention Mechanism
- 2.2 高效的 Self-attention Mechanism
- 2.3 Relative Positional Encoding
- 3 UTNet 的整体结构
- 4 实验
- 5 总结
- 6 参考链接
1 概述¶

很久之前读了这篇接收在 MICCAI 2021 上的文章,复现调试了代码之后还没有及时整理一篇阅读笔记。由于在 MICCAI 上,这篇文章同样没有大量的实验对比工作,但是提出的方法思路清晰易懂,值得借鉴。arXiv: https://arxiv.org/abs/2107.00781 。作为前置依赖,本篇阅读笔记首先介绍了 Transformer Architecture 和在医学图像分割上的应用;其次,分析了论文中提出的 UTNet 架构(主干 U-Net,混合 Transformer 等 module);最后,看了下论文的实验结果。
在语义分割上,FCN 这类卷积的编码器-解码器架构衍生出的模型在过去几年取得了实质性进展,但这类模型存在两个局限。第一,卷积仅能从邻域像素收集信息,缺乏提取明确全局依赖性特征的能力;第二,卷积核的大小和形状往往是固定的,因此它们不能灵活适应输入的图像或其他内容。相反,Transformer architecture 由于自注意力机制具有捕获全局依赖特征的能力,且允许网络根据输入内容动态收集相关特征。
值得注意的是,Transformer 架构的训练需要的更大的开销,因为自注意力机制(self-attention)在序列长度方面具有的时间和空间复杂度。基于此,标准的 self-attention 大多数以 patch-wise 方式应用到模型中,比如使用 16 × 16 这种小扁平图像块作为输入序列,或者在来自 CNN 主干的特征图之上对图像进行编码,这些特征图一般是下采样后的低分辨率图像。这里问题就出来了,对于医学图像分割任务目标位置敏感的特殊性,一些欠分割或者过分割的区域都在目标周围,往往需要高分辨率特征。此外,有些实验论证,在 ImageNet 上进行了预训练,Transformer 要比 ResNet 差,Transformer 真的能适应医学图像这种小数据集分割任务吗?
为了解决上面的问题,文章中提出的 U-Net 混合 Transformer 网络:UTNet,它整合了卷积和自注意力策略用于医学图像分割任务。应用卷积层来提取局部强度特征,以避免对 Transformer 进行大规模的预训练,同时使用自注意力来捕获全局特征。为了提高分割质量,还提出了一种 efficient self-attention,在时间和空间上将整体复杂度从 O(n2) 显着降低到接近 O(n)。此外,在 self-attention 模块中使用相对位置编码来学习医学图像中的内容-位置关系。
2 浅析 Transformer 架构¶
上面我们对 Transformer 在医学图像分割上的应用和局限做了概述,这里我们简单分析下 Transformer 架构,对这部分很了解的读者可以跳过。
2.1 重看 Self-attention Mechanism¶
Transformer 建立在多头自注意机制 (MHSA) 模块上,MHSA 是由多个 Self-Attention 组成的。下图是 Self-Attention 的结构,在计算的时候需要用到矩阵 Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量 x 组成的矩阵 X) 或者上一个 Encoder block 的输出。而 Q,K,V 是通过 Self-Attention 的输入进行线性变换得到的。
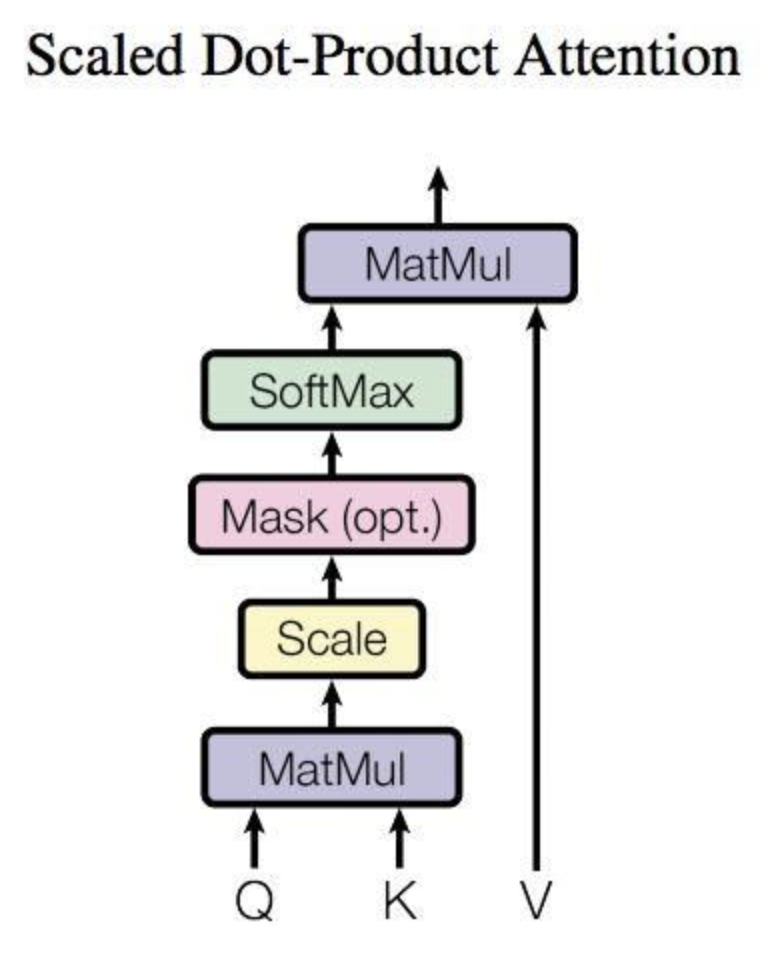
得到矩阵 Q, K, V 之后就可以计算出 Self-Attention 的输出了,计算的公式如下。其中 d 是 Q,K 矩阵的列数(向量维度),公式中计算矩阵 Q 和 K 每一行向量的内积,为了防止内积过大,因此除以 d 的平方根。将 Q, K, V 展平并转置为大小为 n × d 的序列,其中 n = HW。P ∈ Rn×n 被命名为上下文聚合矩阵,用作权重以收集上下文信息。
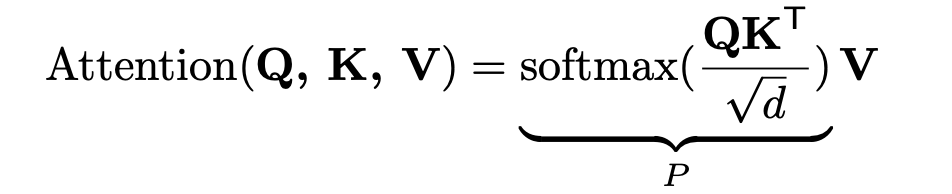
通过这种方式,self-attention 本质上具有全局感受野,擅长捕捉全局依赖。 此外,上下文聚合矩阵可以适应输入内容,以实现更好的特征聚合。关于更细节的内容,这里就不多介绍了。需要关注的是,n×d 矩阵的点乘会导致 O(n2d) 复杂度。通常,当特征图的分辨率很大时,n 远大于 d,因此序列长度 n 在自注意力计算中占主导地位,这使得高分辨率特征图中应用自注意力是不可行的,例如对于 16 × 16 特征图,n = 256,对于 128 × 128 特征图,n = 16384。这一点在本篇笔记的概述中提到过。
2.2 高效的 Self-attention Mechanism¶
那么如何降低 O(n2) 的复杂度呢?由于医学图像是高度结构化的数据,除了边界区域外,局部像素的高分辨率特征和图中的其他像素特征存在相似性,因此,所有像素之间的成对注意力计算往往是低效和冗余的。所以需要一种高效的自我注意机制,计算如下。
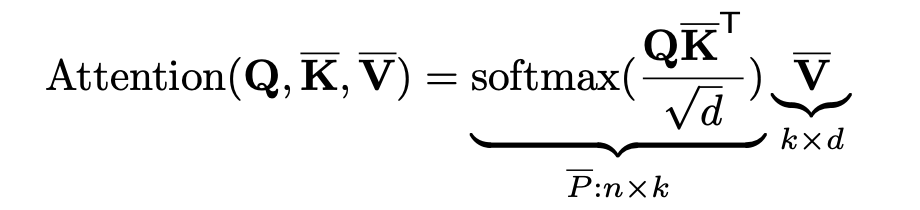
观察与 2.1 中公式不同之处,主要思想很简单,是将 K 和 V 矩阵做了一个 Low-dimension Embedding 达到减小计算量的目的,对应的上下文聚合矩阵 P 的 size 也会被修改。 通过这样做,可以把复杂度降低到 O(nkd)。相当于,这里我们可以做任意下采样操作,例如平均/最大池化或带步长卷积操作。 比如,使用 1×1 卷积,然后使用双线性插值对特征图进行下采样,缩小后的 size 是可以推断的。
基于 MHSA 的 Encoder 和 Decoder block 分别如下图所示,关于这两部分如何插入到 U-Net 中,在后面会有解释。
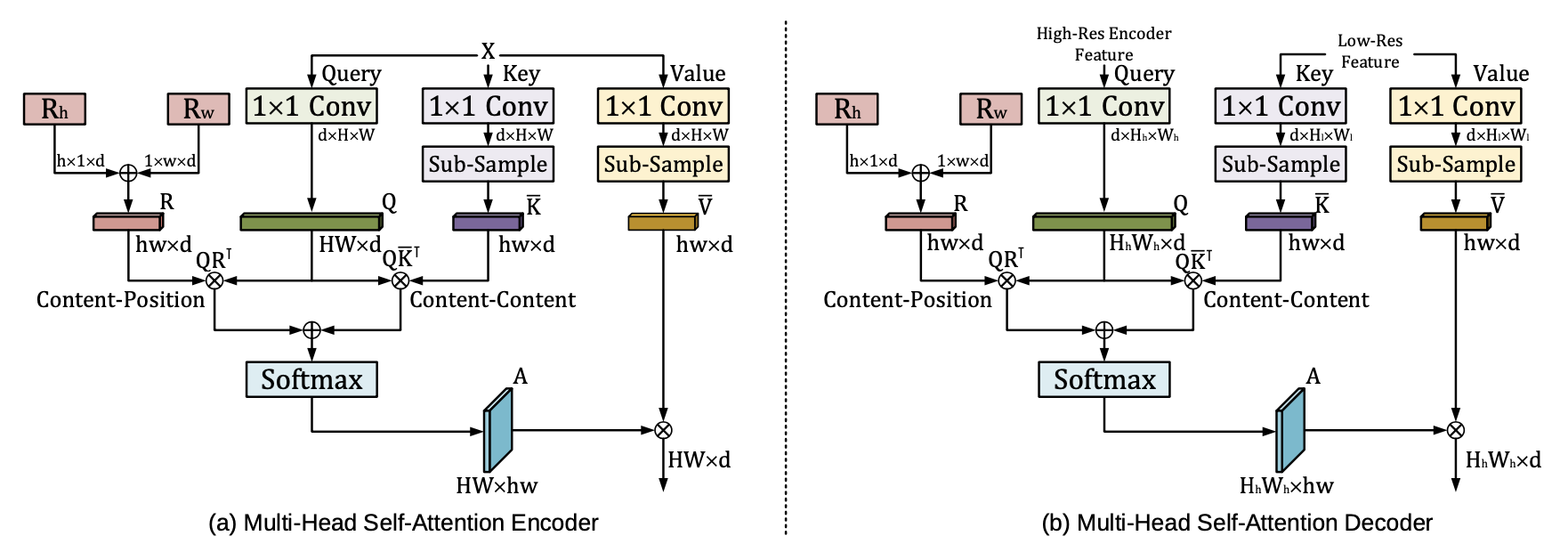
2.3 Relative Positional Encoding¶
Transformer 的相对位置编码大概作用是让像素间保持空间位置关系(从ViT的实验看,去掉 position embedding 后,性能会下降3个点以上),对于图像就是保持二维信息,它对于图像任务来讲很重要。像目前的相对位置编码设计,都算是将位置编码整合到了 Attention 的定义中去了,没有显式地使用绝对位置编码。读者们应该可以发现 2.2 的 MHSA 图里,在 softmax 之前的 pair-wise attention logit 计算中使用了像素 i 和 j 的位置编码,具体的计算如下。
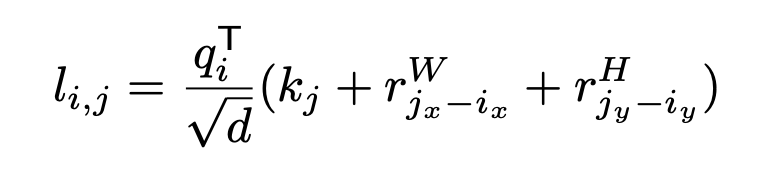
相应的,self-attention 的计算公式又需要做修正了,和之前的区别就是相对宽度和高度是在 low-dimensional projection (低维投影)之后计算的。对 2.2 的高效 self-attention 修正后的计算方式如下。
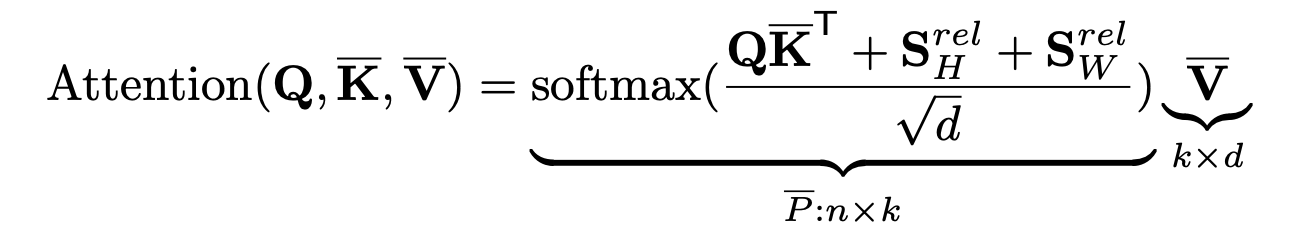
3 UTNet 的整体结构¶
上一部分我们对 UTNet 中的 Transformer 架构做了清晰的介绍,这一部分会整体解释下 UTNet 结构,也就是如何把 Transformer 的 encoder 和 decoder 合理加入到主干 U-Net 中。
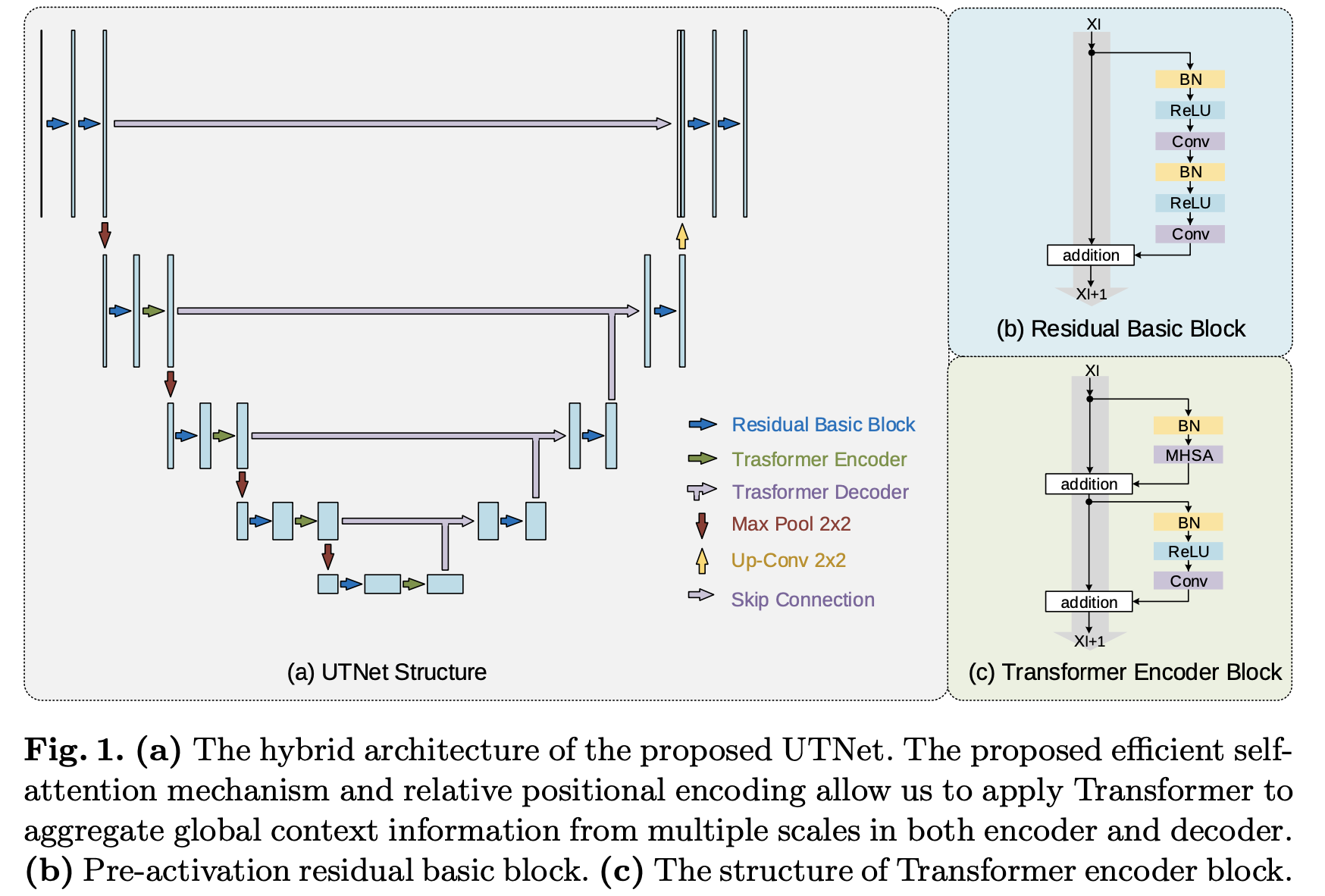
如上图所示 UTNet 结构图,整体上还是保持 U 型。(b) 是一个经典的残差块,传统的 U-Net 改进方法也是这么做的,这样也可以提高分割任务的准确率,避免网络深度带来的梯度爆炸和梯度消失等问题,这些都是老生常谈了,我们不重点关注。 © 是一个标准的 Transformer Decoder 设计。可以发现,遵循了 U-Net 的标准设计,但将每个构建块的最后一个卷积(最高的除外)替换为 2.2 的 Transformer 模块。此外,低三层的跨层连接也被替换为了 Transformer Decoder,我认为还是很好理解的哈,关于这样做的目的在笔记前面陆陆续续都说了一些,下面总结下。
这种混合架构可以利用卷积图像的归纳偏差来避免大规模预训练,以及 Transformer 捕获全局特征关系的能力。由于错误分割的区域通常位于感兴趣区域的边界,高分辨率的上下文信息可以在分割中发挥至关重要的作用。因此,重点放在了自我注意模块上,这使得有效处理大尺寸特征图成为可能。没有将自注意力模块简单地集成到来自 CNN 主干的特征图之上,而是将 Transformer 模块应用于编码器和解码器的每个级别,以从多个尺度收集长期依赖关系。请注意,没有在原始分辨率上应用 Transformer,因为在网络的非常浅层中添加 Transformer 模块对实验没有帮助,但会引入额外的计算。一个可能的原因是网络的浅层更多地关注详细的纹理,其中收集全局上下文特征效果肯定不理想。
4 实验¶
数据集选用 Multi-Centre, Multi-Vendor & Multi-Disease Cardiac Image Segmentation Challenge。
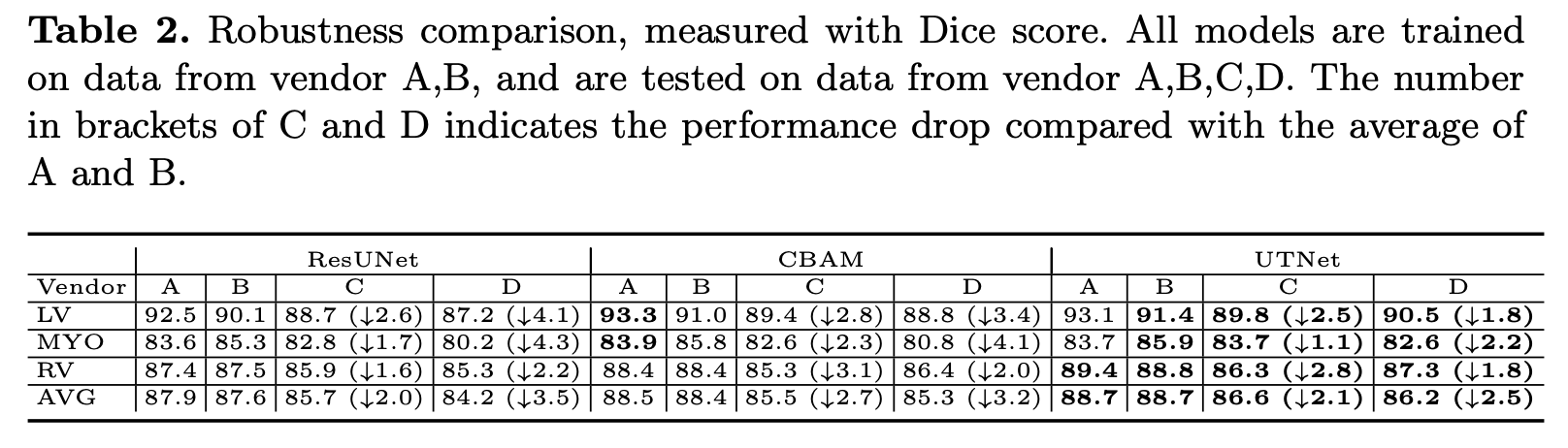
下图是消融实验的结果。下表除了参数量和预测时间比 U-Net 等大,其他均是 SOTA。(a) 为不同自注意力位置的影响消融;(b) 为不同高效 Self-attention 的 projection 效果(对应 2.2);(c)为 Transformer 编码器、Transformer 解码器和相对位置编码的影响消融。
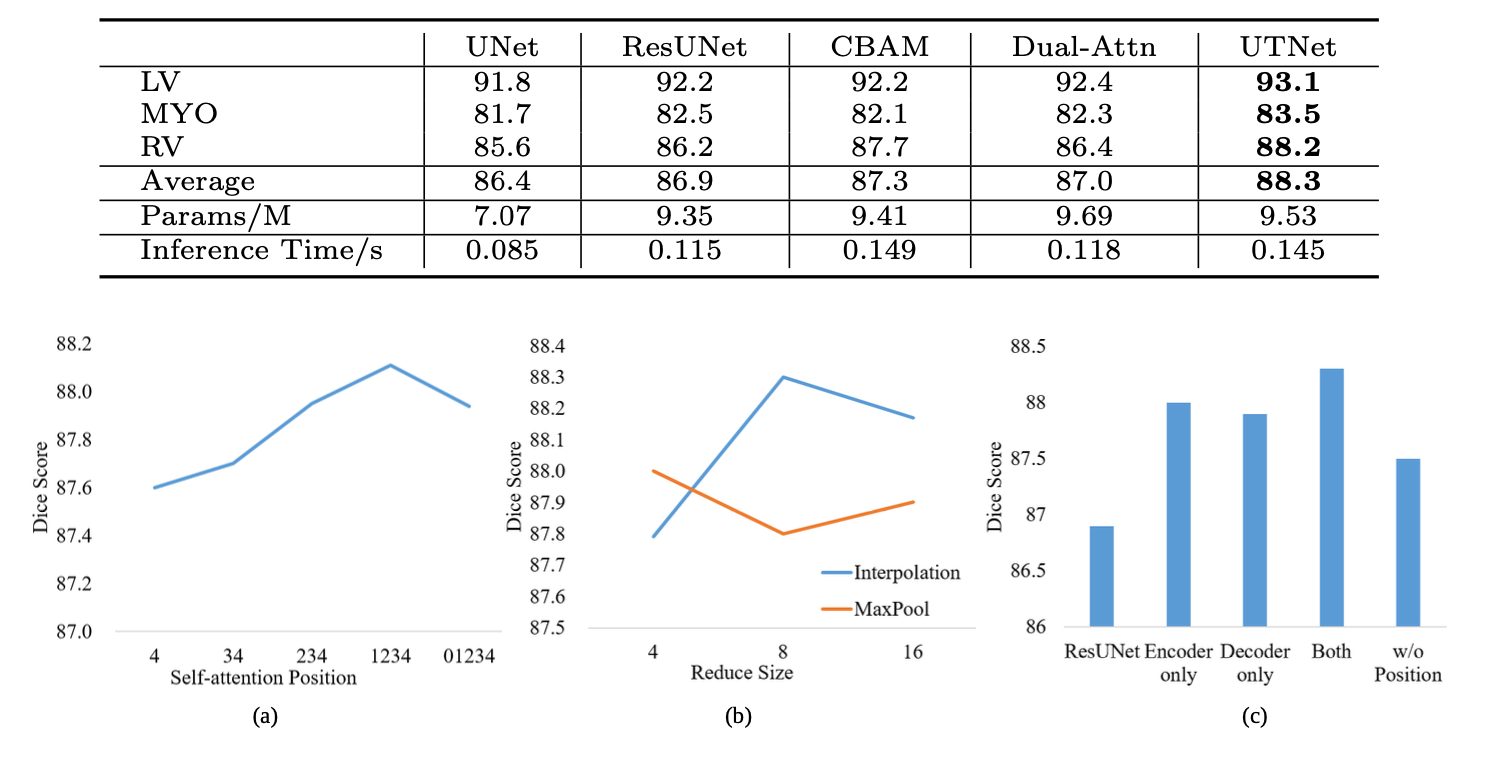
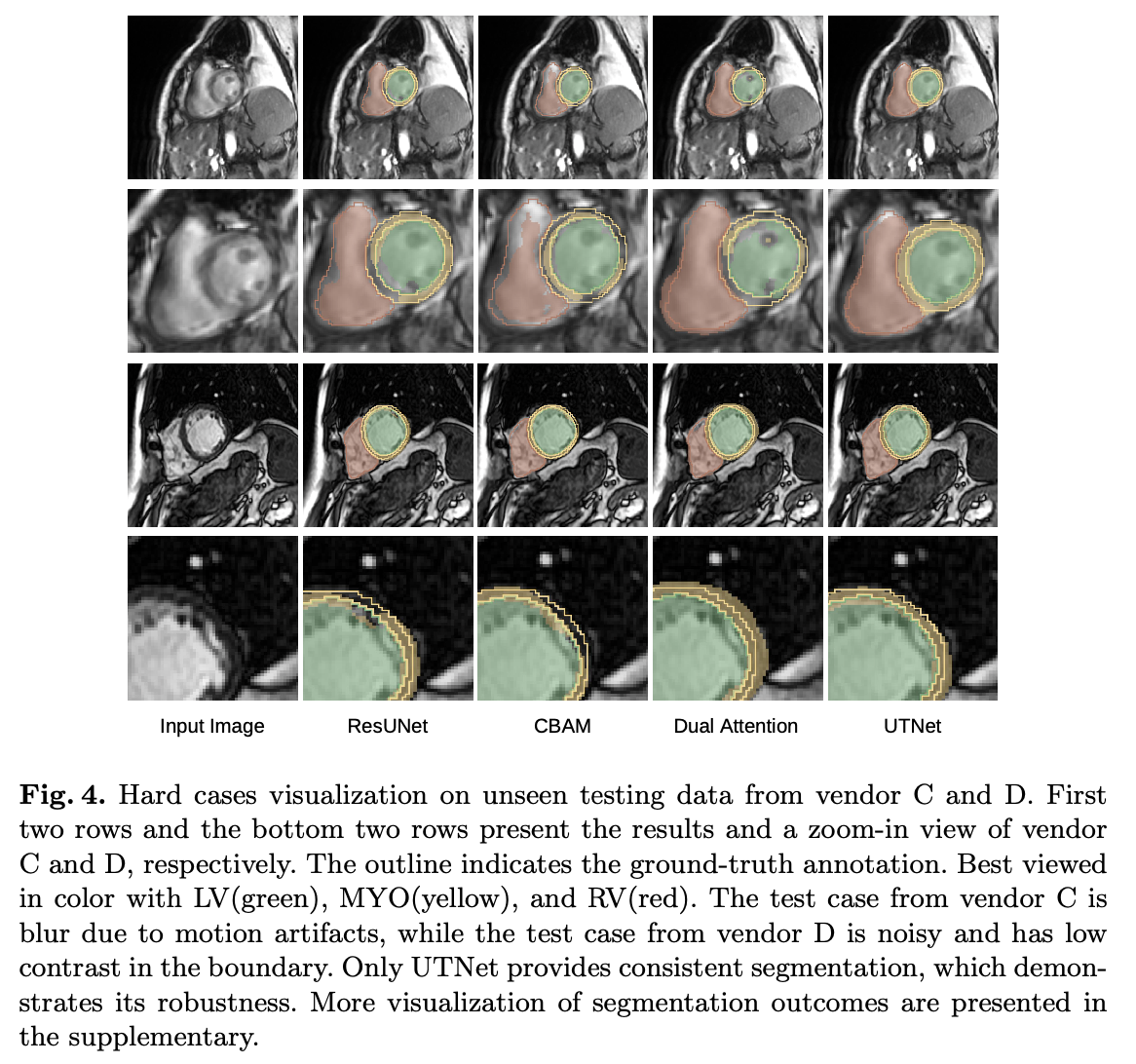
更多的实验对比和结果可视化如下所示,大多数指标比 CBAM 要优秀。
5 总结¶
这篇阅读笔记大多为个人理解,代码复现我后面也许还会更新一篇文章,由于一些医学图像处理任务数据集的特殊性,vit 在医学图像上的应用还需要不断优化,最近有一些不错的想法,也欢迎交流和纠正!
6 参考链接¶
- https://arxiv.org/abs/2107.00781
- Campello, V.M., Palomares, J.F.R., Guala, A., Marakas, M., Friedrich, M., Lekadir, K.: Multi-Centre, Multi-Vendor & Multi-Disease Cardiac Image Segmentation Challenge (Mar 2020)
本文总阅读量次