Towards Compact Single Image Super-resolution via Contrastive self-distillation_owen
Towards Compact Single Image Super-Resolution via Contrastive Self-distillation 利用对比自蒸馏实现超分加速 (IJCAI 2021)
原创论文解读,首发于GiantPandaCV公众号,禁止其他任何形式的转载!
背景 Background¶
卷积神经网络在超分任务上取得了很好的成果,但是依然存在着参数繁重、显存占用大、计算量大的问题,为了解决这些问题,作者提出利用对比自蒸馏实现超分模型的压缩和加速。
主要贡献¶
- 作者提出的对比自蒸馏(CSD)框架可以作为一种通用的方法来同时压缩和加速超分网络,在落地应用中的运行时间也十分友好。
- 自蒸馏被引用进超分领域来实现模型的加速和压缩,同时作者提出利用对比学习进行有效的知识迁移,从而 进一步的提高学生网络的模型性能。
- 在Urban100数据集上,加速后的EDSR+可以实现4倍的压缩比例和1.77倍的速度提高,带来的性能损失仅为0.13 dB PSNR。
方法 Method¶
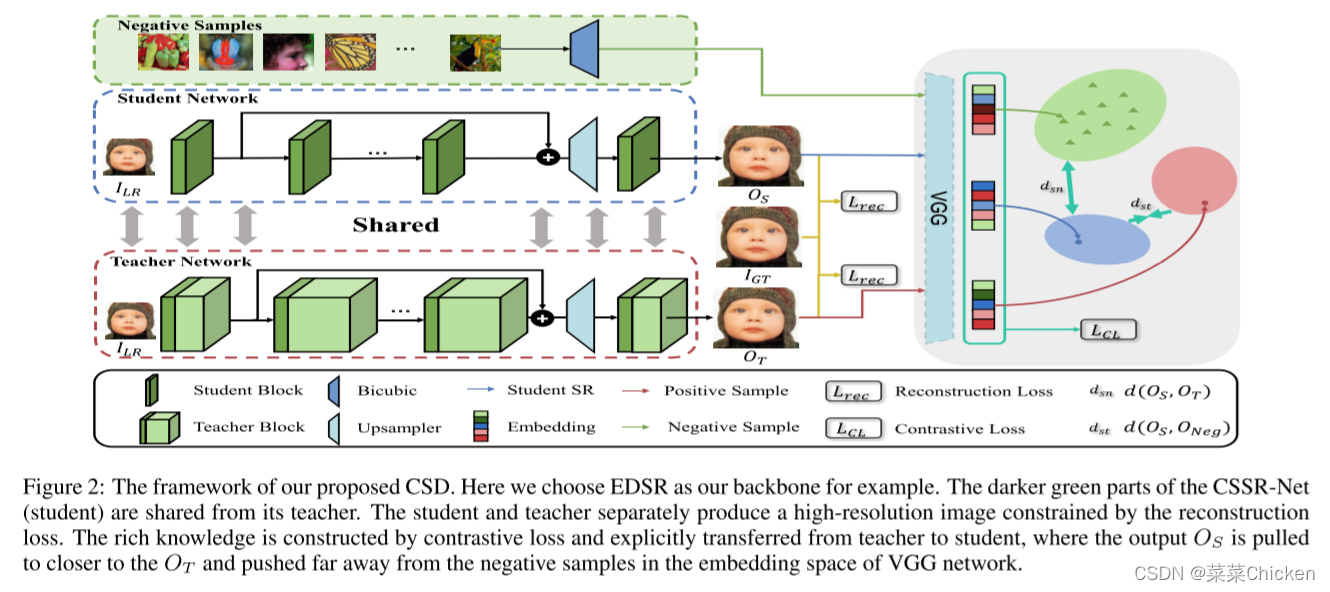
CSSR-Net¶
作者提出的CSD框架主要包含两个部分: CSSR-Net和Contrastive loss。 先简单介绍一下 channel-splitting super-resolution network (CSSR-Net), CSSR-Net其实可以是任何超分网络的子网络,与原网络的区别仅在于channel数量上,在CSD框架中作为学生网络,来作为加速优化的目标产物模型。
如图中所示,在CSD框架中,CSSR-Net被耦合进教师网络,共享教师网络的部分参数(即共同参数部分)。
在训练过程中联合优化的目标函数为:
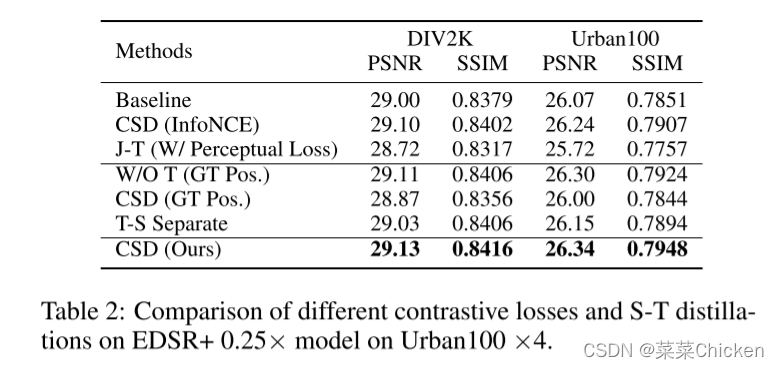
作者发现,如果只有单独的知识蒸馏(即不加对比损失来进一步提高模型性能),训练后得到的模型效果其实更差,详见表1。
作者推测其原因为:隐式的知识蒸馏不够强,无法通过两项独立的损失项来提供足够insightful的信息。 因此作者引进对比学习来显示的在学生和教师之间建立一种联系,为优化目标提供了一个封闭的上下限,从而同时提高学生网络和教师网络的性能。上限被构建来将CSSR-Net的输出向教师拉近,下限来限制CSSR-Net的输出远离负样本。
Contrastive Learning¶
论文中的对比学习损失其实非常简单,基本和论文作者团队在AECR-Net(“Contrastive learning for single image dehazing”)中的contrastive loss一致:
其中,\phi_{j}是VGG预训练网络的第j层,M是总隐藏层的数量,d(x,y)是L_1损失,我们希望上式的分母越大越好,分子越小越好。这种损失引入了相反的力,将CSSR-Net的输出向其教师的输出特征拉近,向负样本的特征拉远。
感知损失与CL相比,其只有一个优化的上限来限制学生网络的输出,与感知损失不同,Contrastive learning使用了多种负样本来作为一个优化的下限目标减小解空间,并且进一步提高CSSR—Net和教师网络的性能。
实验¶

-
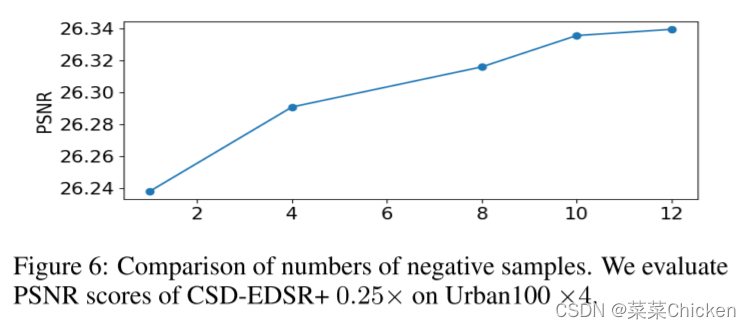
如原文图6所示,引入对比学习损失计算的负样本越多,模型性能越好,这很好解释,更多的负样本进一步约束了下限,每个batch的loss来自于更好的数据采样。
-
表2中值得注意的一点:没有负样本约束的 CSD(GT Pos),相比与baseline来说,性能更差,作者推测 这是由于HR图像只是提供了更强的上限,我们的模型容量是有限的,也就是说模型其实是欠拟合的,这种更强的上限反而难以完全释放模型的性能。 (We speculate that HR images provide a stronger upper bound which is more difficult for the limited capacity S to fully exlpoit.)
笔者观点¶
这篇论文还是很有趣的,通过自蒸馏来实现超分模型的加速和压缩,出发点很好,但是性能上的提高感觉不是非常显著,对比学习损失其实和作者团队cvpr21的对比学习去雾基本一致。这篇论文让我想到cvpr20中一篇利用memory unit实现自蒸馏去雨的论文,也很有趣。
本文总阅读量次