【目标检测算法50篇速览】一、检测网络的出现¶
【GiantPandaCV导读】用深度学习网络来完成实际场景的检测任务已经是现在很多公司的常规做法了,但是检测网络是怎么来的,又是怎么一步步发展的呢?在检测网络不断迭代的过程中,学者们的改进都是基于什么思路提出并最终被证实其优越性的呢?
这个系列将从2013年RCNN开始,对检测网络发展过程中的50篇论文进行阅读,并尝试梳理检测网络的发展脉络。这个系列将按照以下安排梳理:
- 检测网络从出现到成为一个完整的端到端模型。
- one stage 模型出现及two stage 的优化。
- 当前 anchor base检测算法的完整优化思路。
- anchor free算法及检测的最新进展。
第一篇 RCNN¶
《Rich feature hierarchies for accurate object detection and semantic segmentation》
提出时间:2014年
针对问题:
从Alexnet提出后,作者等人思考「如何利用卷积网络来完成检测任务」,即输入一张图,实现图上目标的定位(目标在哪)和分类(目标是什么)两个目标,并最终完成了RCNN网络模型。
创新点:
RCNN提出时,检测网络的执行思路还是脱胎于分类网络。也就是「深度学习部分仅完成输入图像块的分类工作」。那么对检测任务来说如何完成目标的定位呢,作者采用的是Selective Search候选区域提取算法,来获得当前输入图上可能包含目标的不同图像块,再将图像块裁剪到固定的尺寸输入CNN网络来进行当前图像块类别的判断。下图为RCNN论文中的网络完整检测流程图。
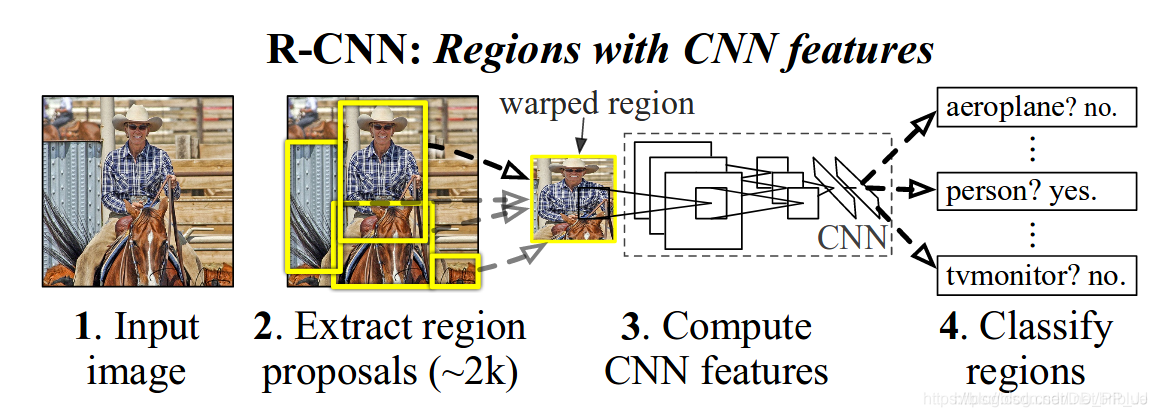 图1
图1
详解博客: https://blog.csdn.net/briblue/article/details/82012575。
第二篇 OverFeat¶
《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》
提出时间:2014年
针对问题:
该论文讨论了,CNN提取到的特征能够同时用于定位和分类两个任务。也就是在CNN提取到特征以后,在网络后端组织两组卷积或全连接层,一组用于实现定位,输出当前图像上目标的最小外接矩形框坐标,一组用于分类,输出当前图像上目标的类别信息。 也是以此为起点,检测网络出现基础主干网络(backbone)+分类头或回归头(定位头)的网络设计模式雏形。
创新点:
在这篇论文中还有两个比较有意思的点,一是作者认为全连接层其实质实现的操作和1x1的卷积是类似的,而且用1x1的卷积核还可以避免FC对输入特征尺寸的限制,那用1x1卷积来替换FC层,是否可行呢?作者在测试时通过将全连接层替换为1x1卷积核证明是可行的;二是提出了offset max-pooling,也就是对池化层输入特征不能整除的情况,通过进行滑动池化并将不同的池化层传递给后续网络层来提高效果。如下为论文中的offset max-pooling示意图。

另外作者在论文里提到他的用法是先基于主干网络+分类头训练,然后切换分类头为回归头,再训练回归头的参数,最终完成整个网络的训练。图像的输入作者采用的是直接在输入图上利用卷积核划窗。然后在指定的每个网络层上回归目标的尺度和空间位置。
详解的博客:https://blog.csdn.net/qq_35732097/article/details/79027095
第三篇 MultiBox¶
《Scalable Object Detection using Deep Neural Networks》
提出时间:2014年multibox
针对问题:
既然CNN网络提取的特征可以直接用于检测任务(定位+分类),作者就尝试将目标框(可能包含目标的最小外包矩形框)提取任务放到CNN中进行。也就是「直接通过网络完成输入图像上目标的定位工作」。
创新点:
本文作者通过将物体检测问题定义为输出多个bounding box的回归问题. 同时每个bounding box会输出关于是否包含目标物体的置信度, 使得模型更加紧凑和高效。
先通过聚类获得图像中可能有目标的位置聚类中心,(800个anchor box)然后学习预测不考虑目标类别的二分类网络,背景or前景。用到了多尺度下的检测。
详解的博客:https://blog.csdn.net/m0_45962052/article/details/104845125
第四篇 DeepBox¶
《DeepBox: Learning Objectness with Convolutional Networks》
提出时间:2015年ICCV
主要针对和尝试解决问题:
本文完成的工作与第三篇类似,都是对目标框提取算法的优化方案,区别是本文首先采用自底而上的方案来提取图像上的疑似目标框,然后再利用CNN网络提取特征对目标框进行是否为前景区域的排序;而第三篇为直接利用CNN网络来回归图像上可能的目标位置。
创新点:
本文作者想通过CNN学习输入图像的特征,从而实现对输入网络目标框是否为真实目标的情况进行计算,量化每个输入框的包含目标的可能性值。
 图3
图3
详解博客:https://www.cnblogs.com/zjutzz/p/8232740.html
第五篇 AttentionNet¶
AttentionNet: AggregatingWeak Directions for Accurate Object Detection》
提出时间:2015年ICCV
主要针对和尝试解决问题:
对检测网络的实现方案进行思考,之前的执行策略是,先确定输入图像中可能包含目标位置的矩形框,再对每个矩形框进行分类和回归从而确定目标的准确位置,参考RCNN。那么能否直接利用回归的思路从图像的四个角点,逐渐得到目标的最小外接矩形框和类别呢?
创新点:
通过从图像的四个角点,逐步迭代的方式,每次计算一个缩小的方向,并缩小指定的距离来使得逐渐逼近目标。作者还提出了针对多目标情况的处理方式。
详解博客: https://blog.csdn.net/m0_45962052/article/details/104945913
第六篇 SPPNet¶
《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
提出时间:2014年SPPnet
针对问题:
如RCNN会将输入的目标图像块处理到同一尺寸再输入进CNN网络,在处理过程中就造成了图像块信息的损失。在实际的场景中,输入网络的目标尺寸很难统一,而网络最后的全连接层又要求输入的特征信息为统一维度的向量。作者就尝试进行「不同尺寸CNN网络提取到的特征维度进行统一」。
创新点:
作者提出的SPPnet中,通过使用「特征金字塔池化」来使得最后的卷积层输出结果可以统一到全连接层需要的尺寸,在训练的时候,池化的操作还是通过滑动窗口完成的,池化的核宽高及步长通过当前层的特征图的宽高计算得到。原论文中的特征金字塔池化操作图示如下。
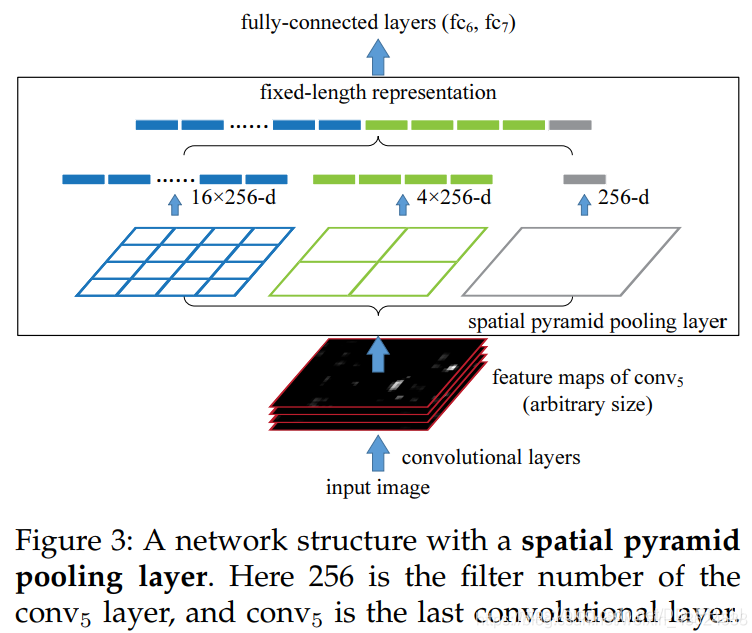 图4
图4
详解的博客: https://blog.csdn.net/weixin_43624538/article/details/87966601
第七篇 Multi Region CNN¶
《Object detection via a multi-region & semantic segmentation-aware CNN model》
提出时间: 2015年
针对问题:
既然第三篇论文multibox算法提出了可以用CNN来实现输入图像中待检测目标的定位,本文作者就尝试增加一些训练时的方法技巧来提高CNN网络最终的定位精度。
创新点:
作者通过对输入网络的region进行一定的处理(通过数据增强,使得网络利用目标周围的上下文信息得到更精准的目标框)来增加网络对目标回归框的精度。具体的处理方式包括:扩大输入目标的标签包围框、取输入目标的标签中包围框的一部分等并对不同区域分别回归位置,使得网络对目标的边界更加敏感。这种操作丰富了输入目标的多样性,从而提高了回归框的精度。
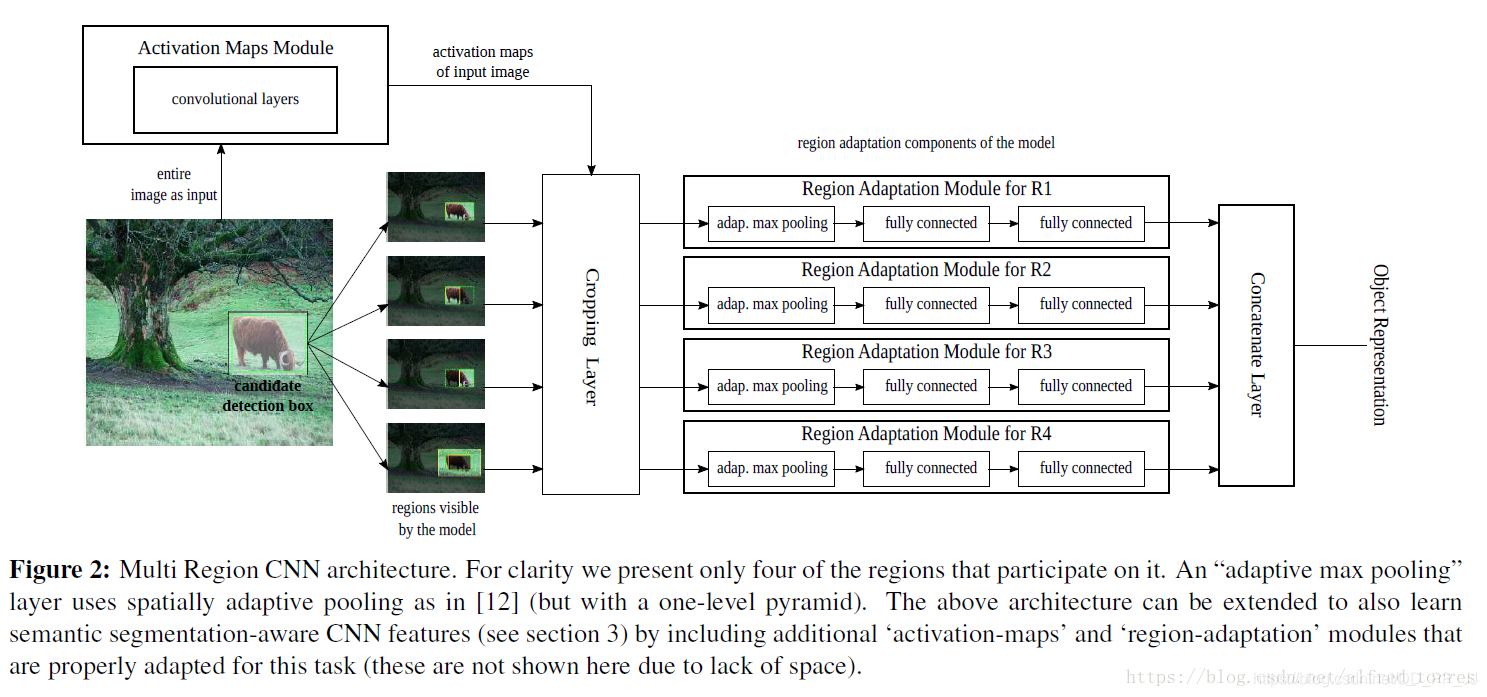 图5
图5
详解博客:https://blog.csdn.net/alfred_torres/article/details/83022967
第八篇 Fast R-CNN¶
提出时间:2015年
针对问题:
RCNN中的CNN每输入一个图像块就要执行一次前向计算,这显然是非常耗时的,那么如何优化这部分呢?
创新点:
作者参考了SPPNet(第六篇论文),在网络中实现了ROIpooling来使得输入的图像块不用裁剪到统一尺寸,从而避免了输入的信息丢失。其次是将整张图输入网络得到特征图,再将原图上用Selective Search算法得到的目标框映射到特征图上,避免了特征的重复提取。
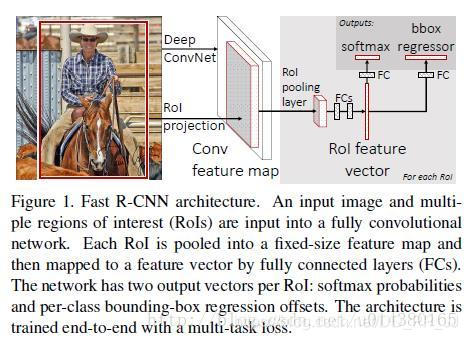 图6
图6
详解博客:https://blog.csdn.net/u014380165/article/details/72851319
第九篇 DeepProposal¶
《DeepProposal: Hunting Objects by Cascading Deep Convolutional Layers》
提出时间:2015年
主要针对和尝试解决问题:
本文的作者观察到CNN可以提取到很棒的对输入图像进行表征的论文,作者尝试通过实验来对CNN网络不同层所产生的特征的作用和情况进行讨论和解析。
创新点:
作者在不同的激活层上以滑动窗口的方式生成了假设,并表明最终的卷积层可以以较高的查全率找到感兴趣的对象,但是由于特征图的粗糙性,定位性很差。 相反,网络的第一层可以更好地定位感兴趣的对象,但召回率降低。
第十篇 Faster R-CNN¶
提出时间:2015年NIPS
主要针对和尝试解决问题:
由multibox(第三篇)和DeepBox(第四篇)等论文,我们知道,用CNN可以生成目标待检测框,并判定当前框为目标的概率,那能否将该模型整合到目标检测的模型中,从而实现真正输入端为图像,输出为最终检测结果的,全部依赖CNN完成的检测系统呢?
创新点:
将当前输入图目标框提取整合到了检测网络中,依赖一个小的目标框提取网络RPN来替代Selective Search算法,从而实现真正的端到端检测算法。
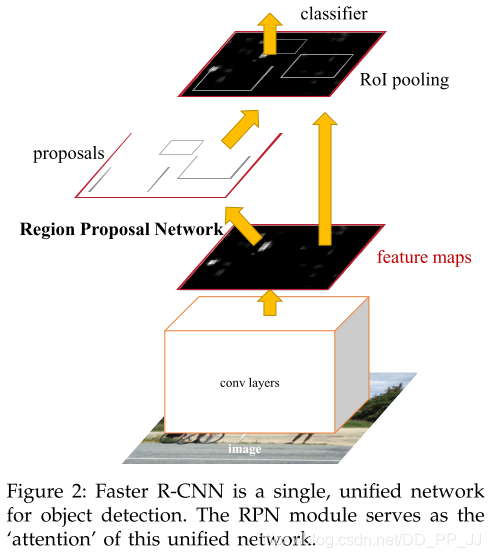 图7
图7
详解博客:https://zhuanlan.zhihu.com/p/31426458
总结¶
第一章是检测CNN开始的阶段,这个阶段的模型最早从Alexnet的分类模型开始,首先提出了检测网络模型的基础结构RCNN(第一篇),接着讨论了利用CNN网络同时完成定位和分类任务的可能性(第二篇)。接着就是基于以上两篇论文的思路,对检测网络的不同部分进行完善。首先针对候选目标框提取部分,也就是图像中目标的定位,分别为基于全图直接回归(第三篇),基于自底向上方案候选框的筛选(第四篇)以及基于全图的迭代回归(第五篇)做了尝试;接着对不同尺度的目标如何统一训练的问题进行了优化(第六篇),并通过一些训练技巧来强化网络模型的精度(第七篇);然后是对CNN中不同层输出特征情况的研究,以此奠定了CNN网络不同层的特征具有不同的作用(第九篇);最终,总结并 凝练学者们提出的检测模型结构和改进,形成了两阶段目标检测框架Fast RCNN和Faster RCNN。也标志着用CNN来实现端到端的目标检测任务的主流方向确定。
【目标检测算法50篇速览】二、检测网络检测网络设计范式的完善¶
【GiantPandaCV导读】到了第二章,检测网络已经发展到了将整个的检测任务都放在CNN中进行,也开始有学者探讨,CNN中每一层到底学到了什么信息。到此部分,现在通用的检测模型结构开始逐步的产生和完善,并向更高精度和更快速度迈进。
第一篇 FCN¶
《Fully Convolutional Networks for Semantic Segmentation》
提出时间:2015年
针对问题:
过往的检测网络大都采用了全连接层来对CNN提取到的特征进行处理。作者尝试讨论那能否设计一个「全部由卷积层构建的网络模型」,来达到更精细的检测效果。
创新点:
设计了一种全卷机的网络来实现对输入图像的像素级分割任务。采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。
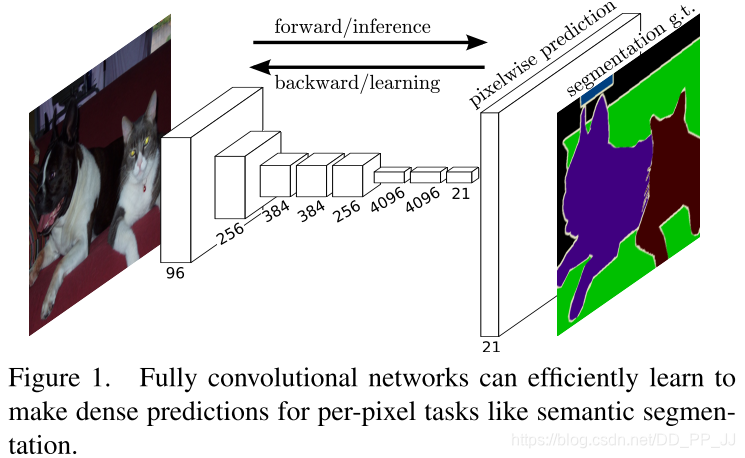 图1
图1
详解博客:https://blog.csdn.net/qq_36269513/article/details/80420363
第二篇 OHEM¶
《Training Region-based Object Detectors with Online Hard Example Mining》
提出时间:2016年
针对问题:
本文作者的出发点是对faster rcnn论文算法的训练流程进行改进,从而提高该模型的检测精度。该操作也侧面说明了网络的训练过程,「难例对模型性能提升是重要的」。
创新点:
利用难例挖掘技术在CNN中的应用来优化训练流程,从而使得Fast RCNN网络模型的检测精度提高。在第t次迭代时,输入图片到卷积网络中得到特征图,然后 把特征图和所有的RoIs输入到RoI网络中并计算所有RoIs的损失,把损 失从高到低排序,然后选择B/N个RoIs。这里有个小问题,位置上相邻 的RoIs通过RoI网络后会输出相近的损失,这样损失就翻倍。作者为了 解决这个问题,使用了NMS(非最大值抑制)算法,先把损失按高到低排 序,然后选择最高的损失,并计算其他RoI这个RoI的IoU(交叉比),移除IoU大于一定阈值的RoI,然后反复上述流程直到选择了B/N个RoIs。
详解博客:https://zhuanlan.zhihu.com/p/58162337
第三篇 YOLOv1¶
提出时间:2016年
针对问题:
主流的检测网络都是两段式的,因为要先提取疑似目标框,再对目标框进行精细定位和分类,所以耗时都会很高,那么能不能设计「一种一段式的网络,既能达到检测的效果,又能降低耗时呢」?
创新点:
作者创新的提出了,依赖回归和在输出特征图上划分grid直接进行回归和分类的网络模型,从而去掉了显式的提取疑似目标框的流程,回归的思路一定程度上,可以参考第二章第二篇,该网络模型设计思路降低了检测流程的耗时,形成了新的一段式检测网络设计模式。
详解博客:https://www.jianshu.com/p/cad68ca85e27
第四篇 G-CNN¶
《G-CNN: an Iterative Grid Based Object Detector》
提出时间:2016年
针对问题:
「既然yolov1创新的提出了grid划分网格并在网格内直接回归目标框的思路来替换显式提取目标框的方案,那能不能将该方案应用到两段式的网络模型中,从而即利用了两段式的精度又加快了速度?」
创新点:
作者在fast rcnn上做试验,用grid来替换selective search算法,并逐步迭代回归到目标的真实位置。
详解博客:https://www.jianshu.com/p/17139e4c5580
第五篇 AZ-Net¶
《Adaptive Object Detection Using Adjacency and ZoomPrediction》
提出时间:2016年CVPR
针对问题:
作者尝试对faster rcnn中的RPN部分进行优化,主要是在保证精度的前提下,提高该部分的目标框提取速度,从而实现对faster rcnn的优化。
创新点:
AZ-net,主要对深度检测网络中的RPN部分进行优化,「利用递归的思路来避免生成Region proposal时候的大量重复操作和计算资源浪费」。也就是对输入图像分块,再逐步向下分块直到当前块判断无目标。
详解博客:https://blog.csdn.net/qq_34135560/article/details/84951384
第六篇 Inside-OutsideNet¶
《Inside-OutsideNet:Detecting Objects in Context with Skip Poolingand Recurrent Neural Networks》
提出时间:2016年
针对问题:
由第一章第九篇论文,我们可以知悉网络的浅层和深层所获取到的图像特征是从局部到整体逐渐抽象的。那么对最终的目标检测任务来说,我们就需要浅层的特征信息来对较小目标进行检测,还需要深层的特征信息来对较大目标实现检测,「如何协调浅层和深层的特征来达到对不同尺度的目标都比较好的检测效果呢」?
创新点:
提取不同层的特征,经过L2正则后拼接,并使用了iRNN结构来提高检测效果,是2016年精度最高的监测模型,最早的利用多层特征融合来进行检测的论文。
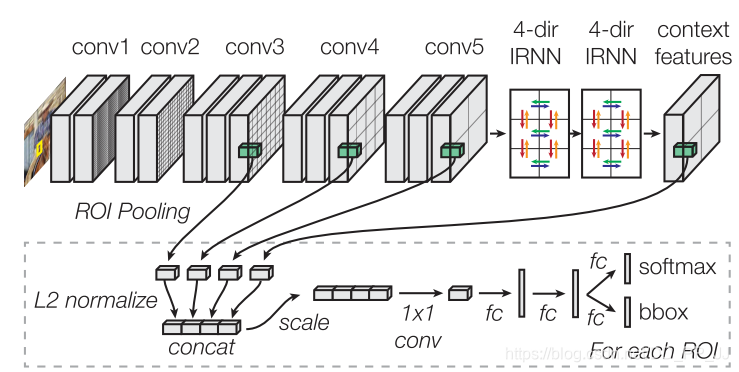 图2
图2
详解博客:https://blog.csdn.net/u014119694/article/details/88423331
第七篇 HyperNet¶
《HyperNet: Towards Accurate Region Proposal Generationand Joint Object Detection》
提出时间:2016年
针对问题:
有faster rcnn网络里的RPN子网络以后,虽然将先验的目标框从几千减少到了几百,但是还是存在着大量的冗余,如何近一步提高先验框提取部分的性能并改进检测网络?
创新点:
作者尝试「跳层提取特征」,即分别从网络的浅层和深层提取特征。既能获取高层语义,又可以得到低层高分辨率的位置信息。提高小目标检测效果。
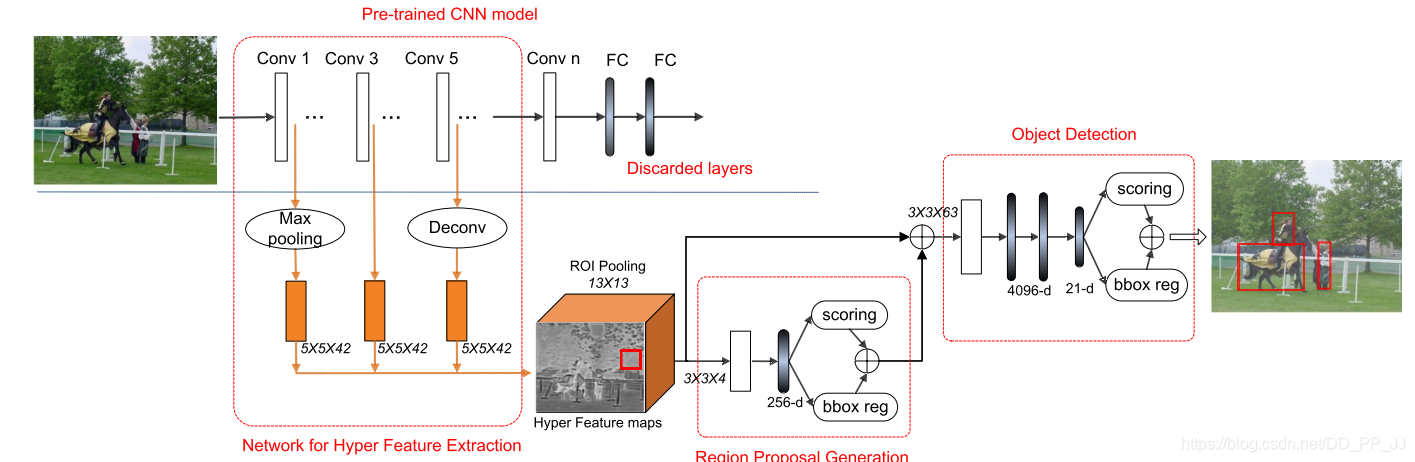 图3
图3
详解博客:https://blog.csdn.net/qq_35608277/article/details/80432907
第八篇 CRAFT¶
《CRAFT Objects from Images》
提出时间:2016年
针对问题:
作者在本篇论文中,认为faster rcnn网络模型仍旧存在改进的空间,通过任务细化,来改进网络RPN部分和分类部分的性能。
创新点:
对于生成目标proposals阶段,论文在RPN的后面加了一个二值的Fast RCNN分类器来对RPN生成的proposals进行进一步的筛选,留下一些高质量的proposals;对于第二阶段的目标proposals分类,论文在原来的分类器后又级联了N个类别(不包含背景类)的二值分类器以进行更精细的目标检测
详解博客:https://blog.csdn.net/scarecrowliu/article/details/53067529
第九篇 MultiPathNet¶
《A MultiPath Network for Object Detection》
提出时间:2016年
针对问题:
本篇论文也是在总结跳层提取特征、输入训练样本的多个不同IOU等模型训练技巧的基础上,对faster rcnn模型进行的改进。
创新点:
MPN网络,是对Fast R-CNN的改进,改进的点主要有三个:
(1)跳跃结构:在VGG网络里,从conv1到conv4,每层conv之后都有一次2*2的max pooling,4次max pooling之后,特征图将下采样到原先的1/16,这会导致信息的丢失。所以将具有丰富信息的较早层连接至后面的网络。 (2)中心区域:背景信息对于小目标检测识别来说是很有用的,所以作者使用了4种不同大小的region crops,分别是1x,1.5x,2x和4x。在每种情况下,使用RoI Pooling技术将它们固定到相同大小。送入全连接层。四个输出连接成一个长向量,用于打分和框回归。 (3)积分损失函数:Fast R-CNN里所有IoU>50%的proposals的得分是相等的,作者改进了损失函数,设置6个不同大小的IoU,分别计算得分然后求平均。这样的话,IoU越高,得分就越高
详解博客:https://blog.csdn.net/qq_37124765/article/details/54906517
第十篇 SSD¶
提出时间:2016年CVPR
针对问题:
一段式的网络从yolov1推出以后,因其对遮挡多目标检测效果不理想、小目标检测不理想等原因,仍旧存在很大的提升空间,本篇论文的作者通过结合多层特征的检测结果,对yolov1进行改进,从而增强其对目标尤其是小目标的检测能力,成为了一段式检测网络的里程碑。
 图4
图4
创新点:
继yolov1之后,一段式目标检测的又一里程碑,相较于yolov1,采用了多个卷积层的特征来进行检测,显著提升对小目标的检测能力;第二点是引入了初始框的设计,也就是对用于检测的特征图,也就是说在每个特征图的单元格的中心设置一系列尺度和大小不同的初始框,这些初始框都会反向映射到原图的某一个位置,如果某个初始框的位置正好和真实目标框的位置重叠度很高,那么就通过损失函数预测这个初始框的类别,同时对这些初始框的形状进行微调,以使其符合我们标记的真实目标框。以这种设计来完成一段式网络的anchor设定。
详解博客:https://blog.csdn.net/u013044310/article/details/89380273
总结¶
到本章,学者们开始对两段式的网络,进行速度和精度上的优化改进,其中很明显的特征是学者们都注意到了不同层的特征混合使用可以对网络的检测精度有很大的提高。与此同时,我们也可以看到,针对两段式网络检测速度低的问题,基于回归的思想,一段式的检测网络开始出现并在SSD网络上达到了不错的检测效果。以此开始基于anchor的检测网络的一段式和两段式网络齐头并进。
【目标检测算法50篇速览】三、检测网络优化及改进¶
【GiantPandaCV导读】检测网络模型发展到16年已经基本形成了一段式和两段式的两种网络设计模式,两者的共同点是均采用了anchor based的设计结构来达到对输入特征图遍历的效果。但是反映出来的现象是两段式网络的精度更高,一段式网络速度更快,两者都对待检测目标的尺度适应能力存在一定的瓶颈,那么如何继续提高特征表达来增强网络性能呢?基于anchor的思路也引入了相对较多的超参数,如何继续简化超参数的数量呢?本章我们将沿着这个问题进行2016年到2018年论文的速览。
第一篇 MS-CNN¶
《A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection》
提出时间:2016
针对问题:
多尺度目标的检测问题仍旧是检测任务的一个重点问题,既然已经有学者考虑了在网络的不同层上完成对不同尺度的目标检测任务,那么具体怎么运用多层的特征呢,本文作者的思路是对不同的输出层设计不同尺度的目标检测器。
创新点:
对于不同的输出层设计不同尺度的目标检测器,完成多尺度下的检测问题,使用特征的上采样代替输入图像的上采样步骤。设计一个去卷积层,来增加特征图的分辨率,使得小目标依然可以被检测出来。这里使用了特征图的deconvolutional layer(反卷积层)来代替input图像的上采样,可以大大减少内存占用,提高速度。
详解博客:https://blog.csdn.net/app_12062011/article/details/77945816
第二篇 R-FCN¶
《R-FCN: Object Detection via Region-based Fully Convolutional Networks》
提出时间:2016
针对问题:
分类网络对输入特征图中目标的位置信息是不敏感的,而检测网络即需要对目标的位置敏感,还需要保证足够的分类精度。如何解决或者平衡这个矛盾?按我们的理解来说就是,对分类网络来说输入的特征图,目标在图上的不同位置其损失差别不大,但是对检测网络来说,就需要考虑定位的损失,定位的损失再经过回传,会改变网络的权重参数,从而可能对分类的性能产生影响。
创新点:
主要贡献在于解决了“分类网络的位置不敏感性(translation-invariance in image classification)”与“检测网络的位置敏感性(translation-variance in object detection)”之间的矛盾,在提升精度的同时利用“位置敏感得分图(position-sensitive score maps)”提升了检测速度。具体就是把每个目标输出为kk(c+1)的特征向量,k*k每一层表征当前目标的上,下左右等细分位置的heatmap图。
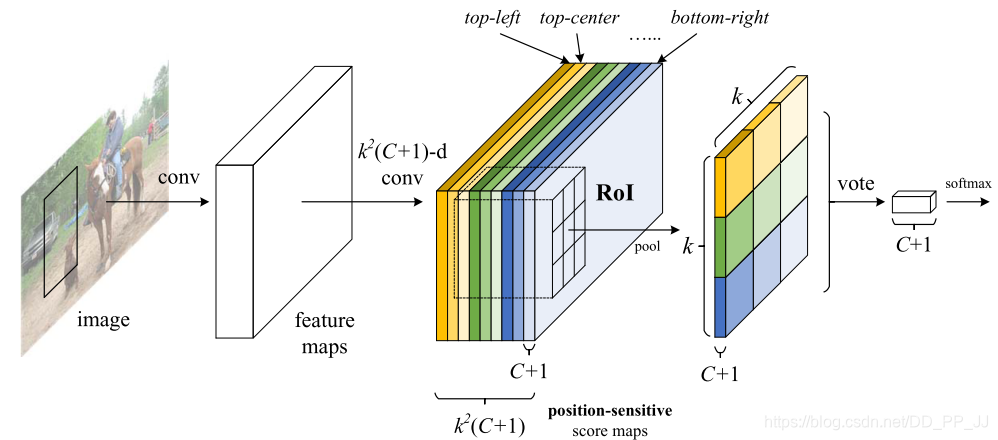 1
1
详解博客:https://zhuanlan.zhihu.com/p/30867916
第三篇 PVANET¶
《PVANET: Deep but Lightweight Neural Networks for Real-time Object Detection》
提出时间:2016年
针对问题:
本篇论文继续在faster rcnn网络上深耕,综合之前提出的多层特征融合、浅层特征计算冗余和inception结构来改善faster rcnn网络的性能。
创新点:
改进了faster rcnn的基础特征提取网络,在不影响精度的前提下加速。主要是三个点:1)C.RELU,C.ReLU(x)=[ReLU(x), ReLU(-x)],认为浅层卷积核的一半计算都是冗余的。2)Inception结构的引入。 3)多层特征的融合。以尽可能的利用细节和抽象特征。
详解博客:https://blog.csdn.net/u014380165/article/details/79502113
第四篇 DSSD¶
《DSSD : Deconvolutional Single Shot Detector》
提出时间:2017
针对问题:
继续在SSD的基础上尝试提高对小目标的检测能力。
创新点:
在网络中添加了反卷积的结构,并通过在backbone中使用resnet结构来提高浅层特征的表达能力。
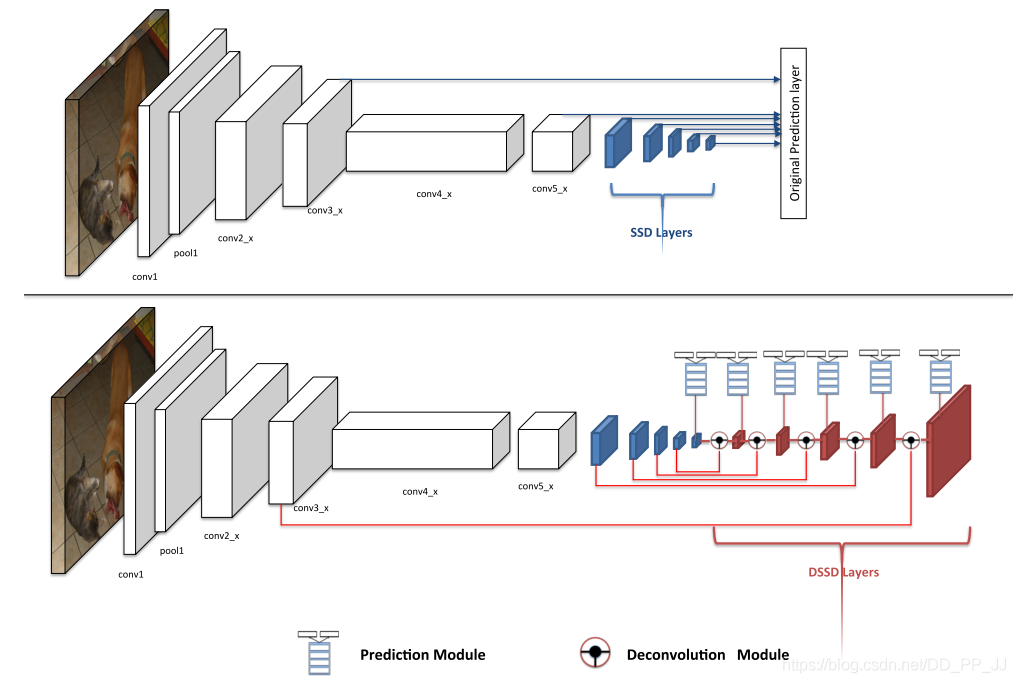 2
2
详解博客:https://blog.csdn.net/u010725283/article/details/79115477/
第五篇 YOLOv2/YOLO9000¶
《YOLO9000:Better, Faster, Stronger》
提出时间:2017年
针对问题:
对yolov1进行改进,借鉴了anchor、多特征层融合检测等网络改进技巧,在保证检测速度的前提下,提高了yolo系列的检测精度。
创新点:
在v1的基础上,用anchor来强化grid,提高输入的分辨率,用BN替代dropout,约束anchor的中心点变动区间,新的backbone
详解博客:https://blog.csdn.net/shanlepu6038/article/details/84778770
第五篇《YOLO9000:Better, Faster, Stronger》
提出时间:2017年
针对问题:
对yolov1进行改进,借鉴了anchor、多特征层融合检测等网络改进技巧,在保证检测速度的前提下,提高了yolo系列的检测精度。
创新点:
在v1的基础上,用anchor来强化grid,提高输入的分辨率,用BN替代dropout,约束anchor的中心点变动区间,新的backbone
详解博客:https://blog.csdn.net/shanlepu6038/article/details/84778770
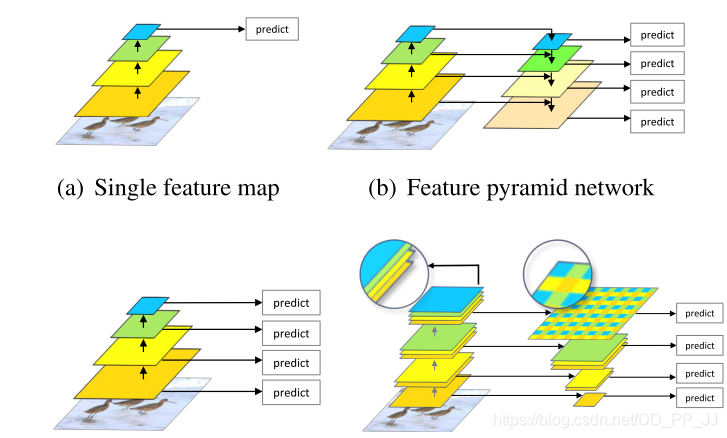
第六篇 FPN¶
《Feature Pyramid Networks for Object Detection》
提出时间:2017年
针对问题:
本篇论文的作者尝试通过增强CNN主干网络输出的特征来进一步增强网络的检测精度。
创新点:
CNN目标检测网络开始尝试利用多层特征融合来进行大目标+小目标的检测,本篇主要是提出新的跳层特征融合及用作分类的方式。 「FPN网络的提出也成为后续检测的主干网络常用结构」。
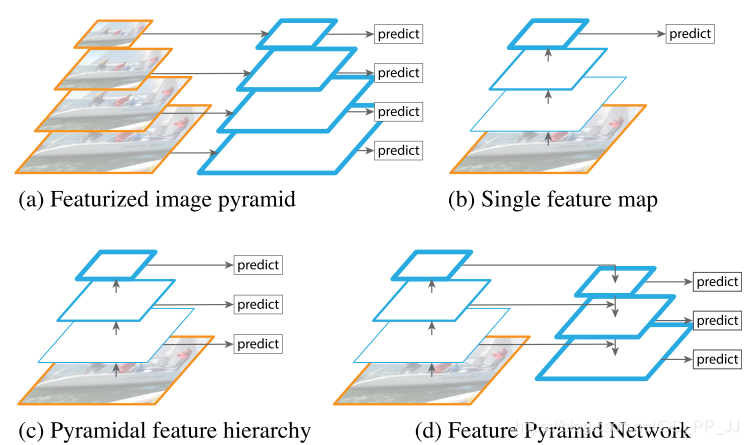 3
3
详解博客:https://blog.csdn.net/kk123k/article/details/86566954
第七篇《RON: Reverse Connection with Objectness Prior Networks for Object Detection》¶
提出时间:2017年
针对问题:
对一段式网络模型的训练精度问题进行优化,作者发现一段式网络在训练时相对两段式网络正负样本不均衡程度更大且没有有效的抑制手段。不均衡的正负样本会不利于网络模型收敛。
创新点:
为了优化one-stage目标检测算法的正负样本不均匀的问题,添加了objectness prior层来筛选正负样本,并采用了和FPN类似的特征融合思路,使得浅层特征的表现能力得到了提高。
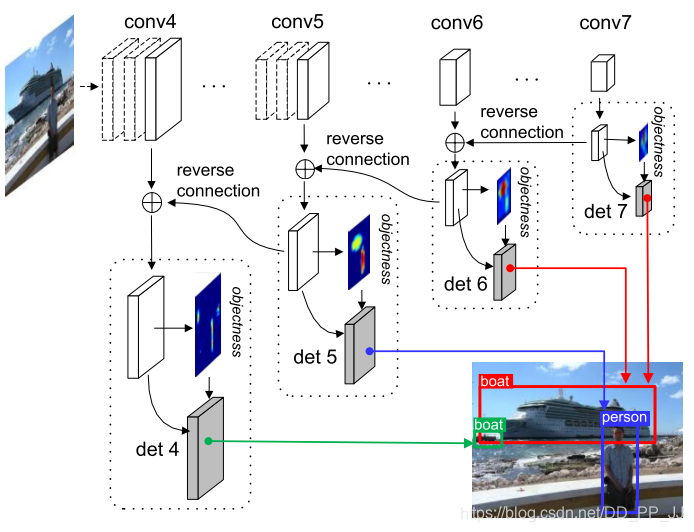 4
4
详解博客:https://blog.csdn.net/shanlepu6038/article/details/84778770
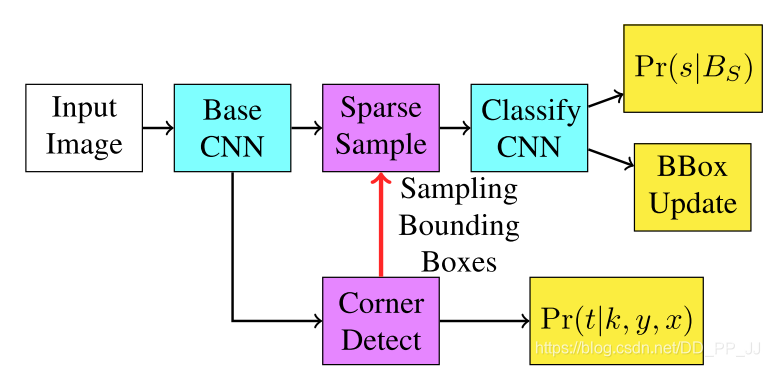
第八篇《DeNet: Scalable Real-time Object Detection with Directed Sparse Sampling》¶
提出时间:2017年
针对问题:
本文作者注意到,当前的检测网络模型都应用了anchor来完成对特征图的近似遍历,其中的anchor超参数的设置也很重要。作者尝试继续简化anchor的超参数,即将基于一定长宽anchor组合的检测算法,取anchor的极限,通过预测图像中目标的角点来完成对图像中目标的定位。
创新点:
之前的two stage 和 one stage都是基于anchor来实现目标建议框的选取,这是第一篇,尝试在anchor盛行的时候,不手工设置anchor,而是利用目标角点检测来实现目标位置检测的方案。
第九篇《CoupleNet: Coupling Global Structure with Local Parts for Object Detection》¶
提出时间:2017年
针对问题:
本文是对R-FCN的一个改进。作者观察到R-FCN中,对输入特征图直接映射为目标的不同组件的,对纹理较少的目标,比如沙发,就可能定位误差偏大。所以作者考虑在R-FCN中加上全局信息。
创新点:
在R-FCN中加上了对全局信息的提取,因为R-FCN是直接将共享的Feature Map 映射为了每类目标的各个组件,而对沙发这种单独结构文理很少的,更需要目标的全局信息,ROI Pooling则保留了类似的信息,所以两者合一一起用。
详解博客:https://blog.csdn.net/qq_34564947/article/details/77462819
第十篇《Focal Loss for Dense Object Detection》¶
提出时间:2017年
针对问题:
如第七篇论文的工作,在网络模型训练的过程中,正负样本的不平衡是影响模型精度的重要因素。第七篇采用的的策略和两段式网络相似,都是通过筛选生成的目标框是否包含正样本来过滤。本文作者则从损失函数的角度,「通过设计的Focal Loss降低重复的简单样本对模型权重的影响,强调难例对网络学习的益处,以此来提高模型权重收敛的方向,使其达到更高精度。」
创新点:
定义新的损失函数Focal loss来使得难训练的样本对loss贡献大,从而一定程度优化训练样本类别不均衡的问题。
详解博客:https://www.bilibili.com/read/cv2172717
第十一篇《DSOD: Learning Deeply Supervised Object Detectors from Scratch》¶
提出时间:2017年
针对问题:
本文作者认为当前的检测模型大部分都是以大数据集训练得到的分类模型为骨干网络,再将其迁移到当前数据集的检测任务上,虽然分类和检测可以共用特征,但是检测直接从头训练的模型和分类网络训练出来的模型参数还是有区别的。所以作者尝试提供一种从头有监督的训练检测网络模型的方案。
创新点:
摆脱预训练模型,从头训练自己的模型,从而摆脱结构依赖。
https://arleyzhang.github.io/articles/c0b67e9a/
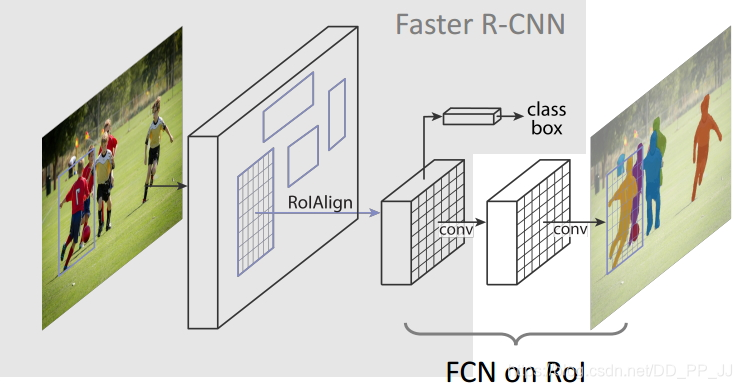
第十二篇《MASK R-CNN》¶
提出时间:2017年
针对问题:
作者尝试从采用分割网络的思路来实现检测的任务,也就是对每个像素点判断其类别,再通过不同实例来确定其最小外接矩形框从而达到检测的目的。
创新点:
主要是ROI align技术,也就是不进行截断,而是差值方式的ROI POOLING 。
 6
6
详解博客:https://blog.csdn.net/WZZ18191171661/article/details/79453780
第十三篇《Deformable Convolutional Networks》¶
提出时间:2017年
针对问题:
作者认为卷积神经网络由于其构建模块中的固定几何结构而固有地仅限于模型几何转换,即因为卷积核是固定的形状,无法自适应的对输入特征图上的特征进行有效的提取。所以作者设计了可变形的卷积层和池化层。
创新点:
可变形卷积,通过借鉴空洞卷积实现,通过单独的层学习采样点位置;可变形roi,roi pooling里面的每个bin都可以有一个offset来进行平移。
详解博客:https://zhuanlan.zhihu.com/p/52476083
第十四篇《YOLOv3》¶
提出时间:2018年
针对问题:
主要是作者对yolov2网络的持续优化和改进。
创新点:
主要是借鉴FPN和resnet来提高主干网络的特征层表征能力。
详解博客:https://blog.csdn.net/dz4543/article/details/90049377
第十五篇《Scale-Transferrable Object Detection》¶
提出时间:2018年
针对问题:
作者认为类似原始FPN中的特征的融合并不能够很好的增强特征的表达能力,所以设计了新的融合方式来强化这部分。
创新点:
提出了一种新的在几乎不增加参数和计算量前提下得到大尺寸featuremap的方法,首先将输入feature map在channel维度上按照r2长度进行划分,也就是划分成C个,每个通道长度为r2的feature map,然后将每个11r^2区域转换成rr维度作为输出feature map上rr大小的结果,最后得到rHrWC的feature map。
 7
7
详解博客:https://blog.csdn.net/u014380165/article/details/80602130
第十六篇《Single-Shot Refinement Neural Network for Object Detection》¶
提出时间:2018年
针对问题:
作者观察到两段式网络有较好的精度表现,而一段式网络有更优秀的速度性能,作者尝试结合两者的特点来构建新的网络结构。
创新点:
TCB,ARM与ODM模块的提出。
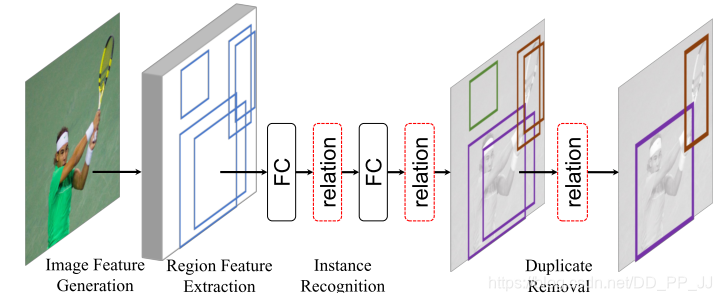
第十七篇《Relation Networks for Object Detection》¶
提出时间:2018年
针对问题:
大家都有感觉,物体间或者物体内一些区域的关联性是有助于目标检测任务的,但是之前没人有实际的证明如何使用这种关联性是一定可行的,本文作者就尝试在检测网络中添加注意力模块来提高网络表现。
创新点:
计算object之间的relation,作为训练参数,从而提高检测精度。
 8
8
详解博客:https://blog.csdn.net/weixin_42102248/article/details/102858695
第十八篇《Cascade R-CNN: Delving into High Quality Object Detection》¶
提出时间:2018年
针对问题:
本文也是对网络训练过程中的优化技巧,作者发现训练检测网络时候需要设置超参数IOU阈值来判断当前定位框是否为正样本,但是一个单一的IOU阈值可能并不是合用的,所以尝试做级联的IOU阈值来辅助训练。
创新点:
为了优化RPN中的单一IOU问题对最终检测精度的影响问题而提出,做不同IOU阈值的级联来提高计算最终损失的正负样本质量及比例,从而提高性能。
详解博客:https://blog.csdn.net/qq_17272679/article/details/81260841
第十九篇《Receptive Field Block Net for Accurate and Fast Object Detection》¶
提出时间:2018年
针对问题:
本文作者的工作也是对主干网络的不同层特征融合工作的优化进行的。主要是为了更有效且更高效的实现特征的融合。
创新点:
提出RFB结构,利用空窗卷积来进行特征的融合。
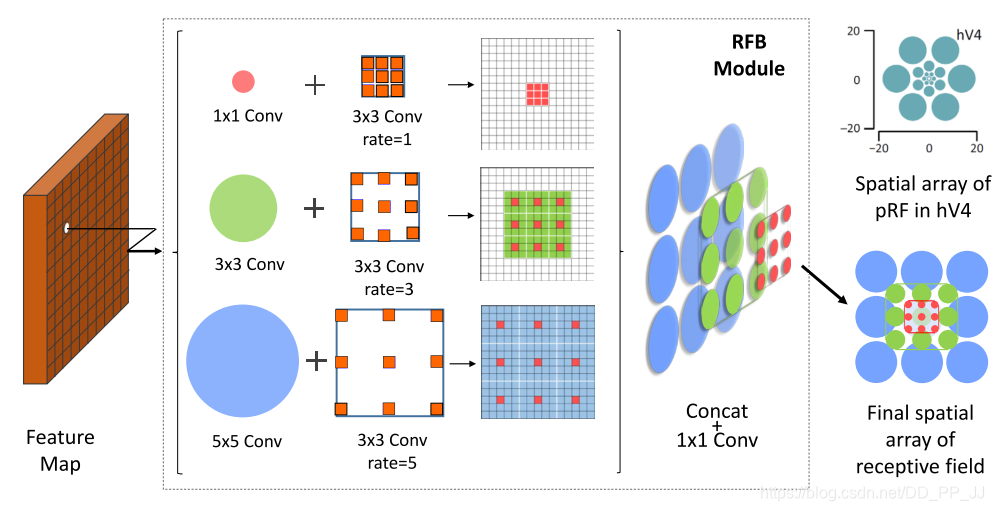 9
9
详解博客:https://blog.csdn.net/u014380165/article/details/81556769
第二十篇《Object Detection based on Region Decomposition and Assembly》¶
提出时间:2019年
针对问题:
本文作者还是针对两段式网络中目标框提取部分进行优化,来提高检测精度。
创新点:
思路还是借鉴之前的论文,对正样本图像块进行拆分左右上下半边和其本身,再分别送入后续卷积,目的是让网络尽可能多的看到当前正样本的丰富的特征。
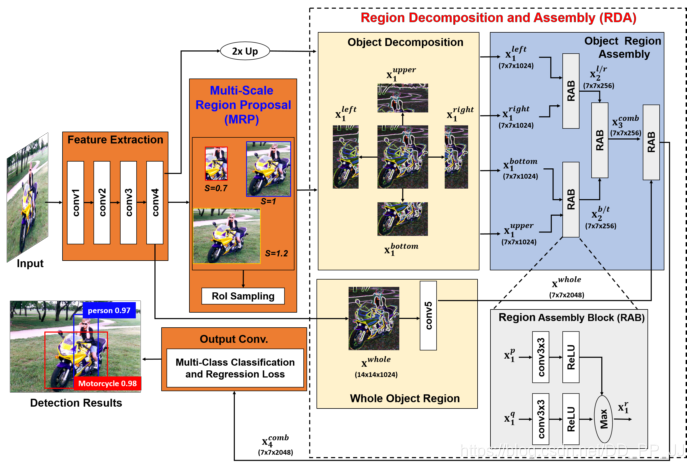 10
10
详解博客:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/88148760
第二十一篇《M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network》¶
提出时间:2019年
针对问题:
作者认为FPN的特征金字塔最开始就是为了分类而设计的,在检测网络中需要进行一定的适配才能达到最好的性能。
创新点:
原始的backbone更适合分类任务,改善backbone的使用机制,使其更适应检测任务。两个新模块1)TUM 通过卷积、上采样和相同shape相加来得到多尺度的特征2)FFMv2 特征融合模块,通过卷积核upsample来统一输入feature map的shape,再concat 3)SFAM 对输入的特征先concat,再进行通道层面的attention,并转化为权重参数相乘,再送入分类和回归。
详解博客:https://blog.csdn.net/hanjiangxue_wei/article/details/103311395
本章总结¶
到本章以后,所提到的21篇论文大部分都是对已有的两种检测网络设计范式的调整和优化,学者们探索了多层特征的融合并最终推出了FPN,并在FPN基础上对检测问题进行适配;学者们还探索了在检测网络中添加注意力模块的方式和方法,并证明其有效。我们还要注意到第八篇和第十三篇论文,其中第八篇讨论了anchor从多个框压缩为点的可能性,第十三篇则探讨了,可能纯卷积的结构并不是检测问题的最优选项,这个方向仍旧有优化的可能。
完成前三章的速览以后,到18年底的检测网络发展情况相信读者已经基本心里有数了,第四章我们将开始介绍从19年的anchor free类目标检测算法,到最新的transformer目标检测算法并尝试提供相应的代码仓库,以便更好的把握检测网络的发展。
第一篇《CornerNet: Detecting Objects as Paired Keypoints》¶
提出时间:2018
针对问题:
如第三章第八篇,有学者提出了基于目标的角点进行目标检测的思路,这种思路的优势就是避免了anchor设计时不同长宽比的调整,且在不同的网络层不同尺度的设计也能统一,从而降低了超参数的数量。
创新点:
anchor free ,利用corner来做,1)内嵌映射2)角点的特征值回传及loss计算方式。
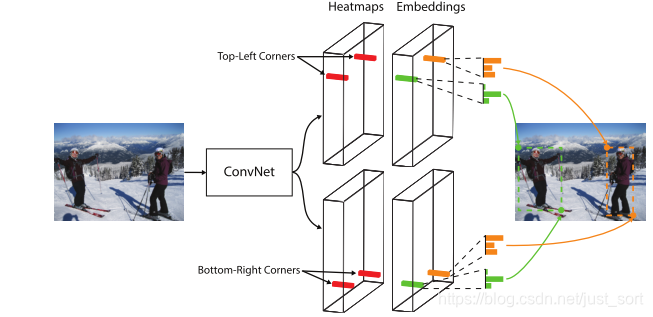 CornerNet
CornerNet
详解博客:https://blog.csdn.net/u014380165/article/details/83032273
第二篇《ExtremeNet》¶
提出时间:2019
针对问题:
单纯用角点进行目标的检测存在一个问题是对目标来说其角点大多都不在目标上,单纯采用角点来进行目标的检测并没有很好的利用目标样例上的特征。那么如何参考利用目标内的特征来实现更高精度的anchor free目标检测就是作者着力解决的问题。
创新点:
anchor free 方案,通过目标的四个方向的极值点和中心点来实现目标检测。
 ExtremeNet
ExtremeNet
详解博客:https://blog.csdn.net/sinat_37532065/article/details/86693930
库地址:https://github.com/xingyizhou/ExtremeNet
第三篇《FCOS》(建议重点细看)¶
提出时间:2019
针对问题:
尝试将anchor free算法和已有的一段式检测网络结合,提出性能更加优越的检测网络模型。
创新点:
FCOS以一种类似语义分割的方式,按像素进行预测,解决目标检测问题
详解博客:https://blog.csdn.net/sinat_37532065/article/details/105252340
github仓库:https://github.com/tianzhi0549/FCOS/
第四篇《CenterNet》(建议重点细看)¶
提出时间:2019
针对问题:
作者参考了cornernet和extremenet,发现两者虽然都尝试优化了anchor设计的复杂超参数调优,但是其检测目标特征点的组队过程仍旧略显繁复。所以作者考虑如何进一步优化该问题来达到更高效的anchor-free检测模型。
创新点:
作者考虑只使用目标的中心点(center),从而将目标检测任务转换为图像中的关键点检测任务。然后通过在这个关键点来回归其所指向的目标类别以及以当前点为中心构建的目标最小外接矩形到改点的四个回归值来完成目标的检测任务。
详解博客:https://baijiahao.baidu.com/s?id=1644905321397514137&wfr=spider&for=pc
第五篇《FSAF》¶
提出时间:2019
针对问题:
当前检测算法大多都是anchor based,通过设置不同的anchor来在FPN输出的多张特征图上进行目标的检测,我们一般经验的认为在网络深层的特征图上检测大目标而在浅层的特征图上检测小目标。但是作者发现在实际网络训练过程中,可能40x40和60x60的目标被分配给了FPN的不同层。为了尝试优化对FPN特征层的利用,同时降低过采样anchor带来的计算量,作者提出了该网络模型。
创新点:
主要是通过在检测网络中添加anchor free的特征层筛选模组,来强化每个输入的实例所归属的判定特征层,从而充分利用FPN的性能。 提出了Online feature selection方法,改善了基于anchor机制和feature pyramids的single-shot检测器的两个潜在问题。FSAF在COCO数据集上达到了state-of-art,mAP为44.6%,超过了所有single-shot检测器。同时额外的计算量很小。
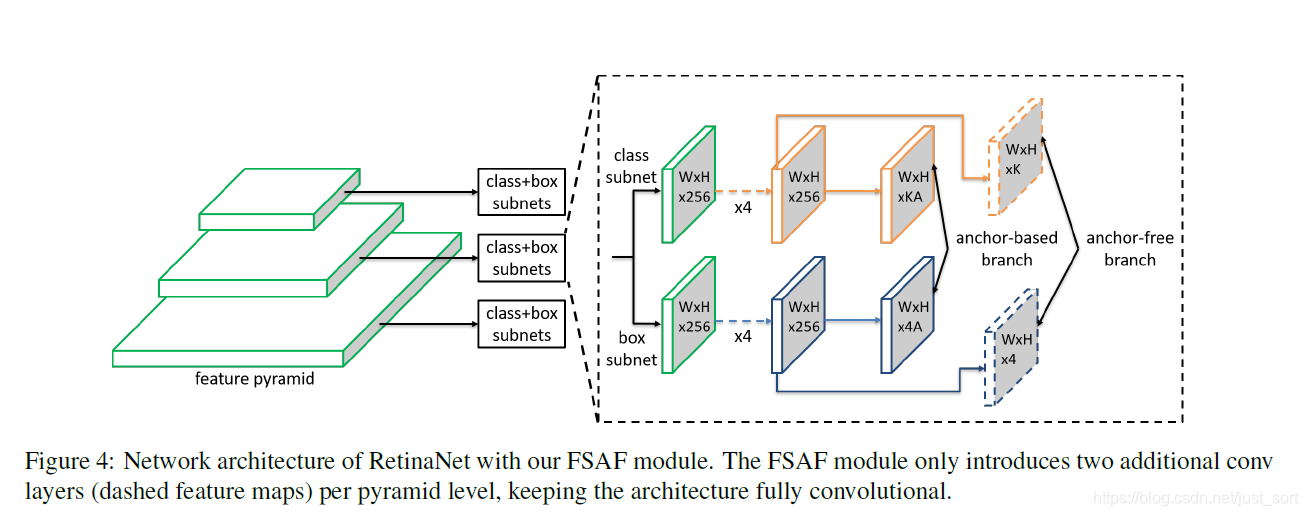 FSAF
FSAF
详解博客:https://www.cnblogs.com/fourmi/p/10602936.html
第六篇《NAS-FPN》¶
提出时间:2019
针对问题:
有学者认为当前FPN的设计并不一定是最优的结果,结合现下的NAS搜索技术,尝试得到更优的FPN结构
创新点:
利用网络结构搜索技术来得到的结构更好的FPN结构
详解博客:https://blog.csdn.net/qq_41375609/article/details/98499442
第七篇《DetNAS》¶
提出时间:2019
针对问题:
作者认为之前检测网络的backbone大多都是基于分类任务完成的,分类任务得到的模型并不关心图像中目标的位置信息,所以作者尝试利用NAS技术得到更适合检测任务的backbone网络。
创新点:
利用网络结构搜索技术来得到的检测网络专用backbone,作者的试验证明确实是对检测精度有提升。
详解博客:https://blog.csdn.net/mrjkzhangma/article/details/103369432
第八篇《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》¶
提出时间:2019
针对问题:
卷积神经网络(ConvNets)通常是在固定的资源预算下发展起来的,如果有更多的资源可用的话,则会扩大规模以获得更好的精度,比如可以提高「网络深度(depth)」、「网络宽度(width)*「和」*输入图像分辨率 (resolution)*「大小。但是通过人工去调整 depth, width, resolution 的放大或缩小的很困难的,在计算量受限时有放大哪个缩小哪个,这些都是很难去确定的,换句话说,这样的组合空间太大,人力无法穷举。基于上述背景,作者尝试提出」*复合模型扩张方法」结合「神经结构搜索技术」获得的更优的网络结构。
创新点:
该论文提出了一种新的模型缩放方法,它使用一个简单而高效的复合系数来从depth, width, resolution 三个维度放大网络,不会像传统的方法那样任意缩放网络的维度,基于神经结构搜索技术可以获得最优的一组参数(复合系数)。
详解博客:https://blog.csdn.net/mrjkzhangma/article/details/103369432
代码:https://github.com/qubvel/efficientnet
第九篇《DETR》¶
提出时间:2020
针对问题:
作者尝试将NLP领域的transformer引入目标检测任务中,目的是想进一步的降低网络的超参数。
创新点:
第一个将 Transformer 成功整合为检测 pipeline 中心构建块的目标检测框架。基于Transformers的端到端目标检测,没有NMS后处理步骤、真正的没有anchor,且对标超越Faster RCNN
详解博客:https://blog.csdn.net/c2250645962/article/details/106399116
代码:https://github.com/facebookresearch/detr
本章总结¶
到了本章,学者们尝试进一步优化anchor base类算法,考虑到anchor设计时的大量经验参数,进一步的优化anchor设计,完成了从框匹配到直接点回归的进化;对检测网络的backbone方面,学者们也通过尝试希望更好的利用输入的特征来提高检测的效果。其中CenterNet和FCOS的代码和论文建议大家有时间的话精度。再之后就是尝试将transformer整合进检测任务中,例如DETR模型,有精力的同学也推荐阅读和学习。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
 二维码
二维码
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。
 公众号QQ交流群
公众号QQ交流群
本文总阅读量次