Fine-tuned CLIP Models are Efficient Video Learners¶
1. 论文信息¶
标题:Fine-tuned CLIP Models are Efficient Video Learners
作者:Hanoona Rasheed, Muhammad Uzair Khattak, Muhammad Maaz, Salman Khan, Fahad Shahbaz Khan
原文链接:https://arxiv-export1.library.cornell.edu/abs/2212.03640
代码链接:https://github.com/muzairkhattak/ViFi-CLIP
近期的基于视频的方法采用了 CLIP 表示,使用额外的可学习组件进行时空建模。这些组件包括用于帧间通信的自注意层,文本或视觉prompts或专用视频解码器模块,在保持 CLIP 骨干冻结或适应 CLIP 编码器的同时学习。然而,这些设计需要在开发的架构模块中建模特定于模态的inductive bias,并需要仔细设计才能适应 CLIP 的video任务。此外,在为下游视频任务适应 CLIP 时,这些方法通常不会在所有设置中保持优势。例如,zero-shot的adaptation方法在监督设置中的表现较差,并且监督模型在zero-shot的 generalization任务上的表现也不那么令人满意。
为了解决上述挑战,我们提出了以下两个问题:
- 使用额外的可学习的参数来fine-tune CLIP 是否会破坏其泛化能力?
- 简单的视频特定微调是否足以弥合图像和视频之间的模态差距?
在论文的实证分析中,我们观察到,与新引入的时间建模组件一起微调预训练的 CLIP 编码器可能会妨碍 CLIP 的泛化能力。有趣的是,当在视频数据集上对简单的 CLIP 模型进行微调时,可以在常规 CLIP 模型中采用适合视频的特定adaptation模型,并且与具有内置视频特定组件的更复杂方法相竞争。
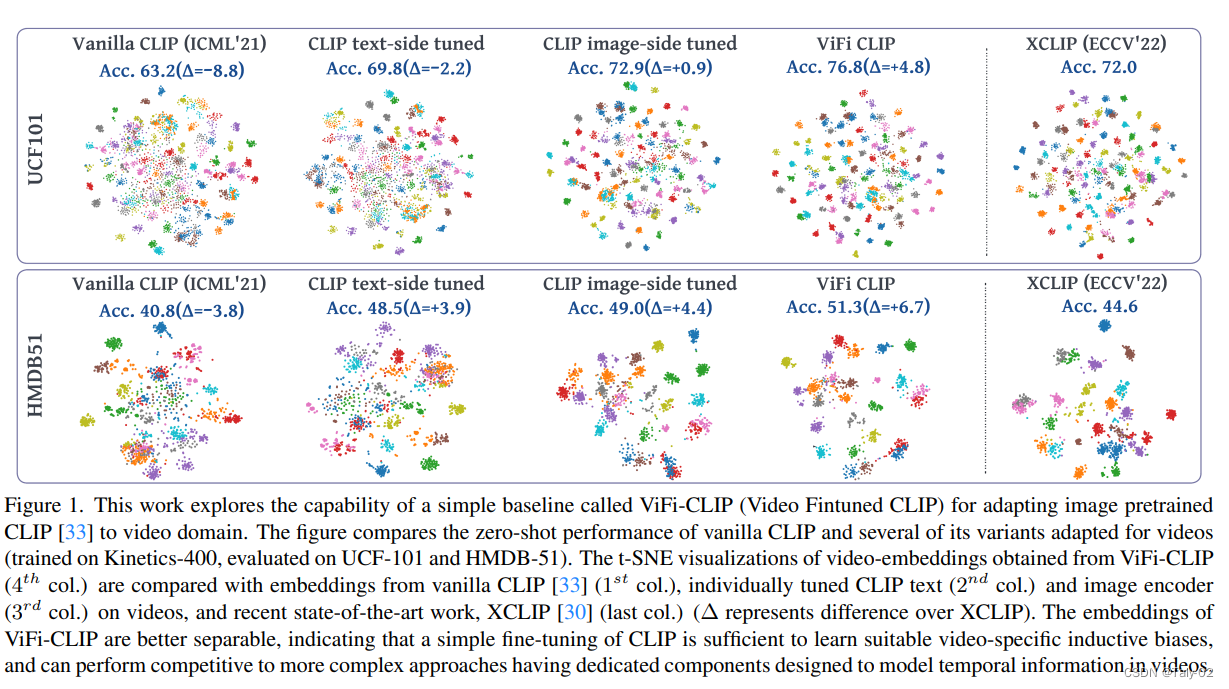
尽管现有工作探索了 CLIP encoder的fine-tune作为baseline,但对于全面fine-tune CLIP 的潜力还是有所嘀咕。然而,我们注意到,为了在视频上获得更好的视觉语言对齐,全面fine-tune可以提高time和language prompt之间的协同作用。为了了解常规 CLIP 模型如何实现这种能力,我们表明,在损失计算之前进行帧级后期表示聚合允许在视频微调的 CLIP 中交换时间的prompt。根据简单fine-tune可以有效适应 CLIP 的视频的发现,我们提出了一种two-stage的“bridge and prompt”方法,用于在小数据模式下微调 CLIP。该方法首先在视频上微调原始 CLIP,以弥合模态差距,然后采用视觉语言提示学习方法,让tuned CLIP保持frozen。此工作的贡献如下:
- 我们提出了一种简单的方法来适应 CLIP 的视频,即完全微调 CLIP,并证明它可以与具有内置视频特定组件的复杂方法竞争。
- 我们提出了一种两阶段方法,用于在低数据量模式下适应 CLIP,它首先在视频上fine-tune原始 CLIP,然后采用vision-language prompt的学习方法,来对 CLIP 进一步地fine-tune。
- 我们对常规 CLIP 模型进行定量和定性分析,以深入了解它为何能够适应视频并获得良好的性能。
在这项工作中,我们研究了如何有效地将预训练的视觉语言(Vision-Language)模型适应视频任务。作者发现,完全fine-tune预训练的 CLIP 模型可以提供竞争力,且不需要为视频开发特定组件。在低数据量模式下,作者提出了一种两阶段方法,用于在视频上微调原始 CLIP,并采用视觉语言提示学习方法,以保持微调 CLIP 的冻结。通过定量和定性分析,作者提供了一个深入了解了 CLIP 模型是如何适应视频并获得良好性能的角度。
3. 方法¶
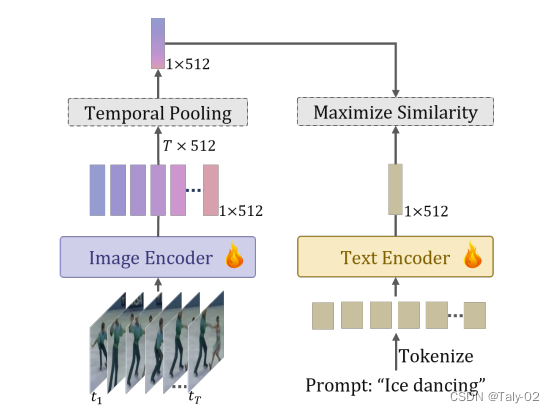
在文献中探索的一种可靠替代方案是将大规模预训练的基于图像的视觉语言模型(如CLIP)适应视频下游任务。考虑到图像和视频之间domain gap,先前的方法已经探索了各种专门的基于注意力的组件的使用,这些组件通过帧之间和模块之间的通信来灌输信息,以整合来自多个帧的信息。相反,我们探索了一种简单的基线(称为 ViFi-CLIP)的能力来适应 CLIP 到视频领域。如上图,描绘了所提出的新方法ViFi-CLIP 的概览。
由于视频中具有额外的时间信息,重要的问题是如何将这些信息利用到基于图像的 CLIP 模型中。我们探索了完全微调 CLIP 的能力,以弥合视频领域中的模态差距。 ViFi-CLIP 微调图像和文本编码器。
给定一个具有 T 帧的视频样本 V_i \in \mathbb{R}^{T \times H \times W \times C} 和相应的文本标签 Y,CLIP 图像编码器将 T 帧独立地编码为一批图像,并产生帧级嵌入 x_i \in \mathbb{R}^{Ttimes D}。通过average pooling这些帧级的embeddings,可以获得video-level的representation v_{i} \in \mathbb{R}^{D}。我们称之为temporal pooling,因此隐式地通过多帧的聚合来实现时间维度的表征学习。
CLIP 文本编码器对类 Y 进行编码,将其包装在诸如“{a photo of a <category>”的prompts temple中,以产生文本嵌入 t \in \mathbb{R}^{D}。对于一批视频,通过卡尔曼相似度 sim(.),在所有视频级embeddings v_i 和相应的文本embeddings t_i 之间最大化,以便通过交叉熵(CE)目标微调 CLIP 模型,温度参数为 \tau,如下所示:
概括来讲,在这项工作中,论文提出了一种称为 ViFi-CLIP 的简单的baseline,用于微调 CLIP 模型以用于视频领域。该方法对 CLIP 模型进行完全微调,以桥接图像和视频之间的模态差距。此外,它还通过卡尔曼相似度和交叉熵目标来微调 CLIP 模型。
4. 实验¶
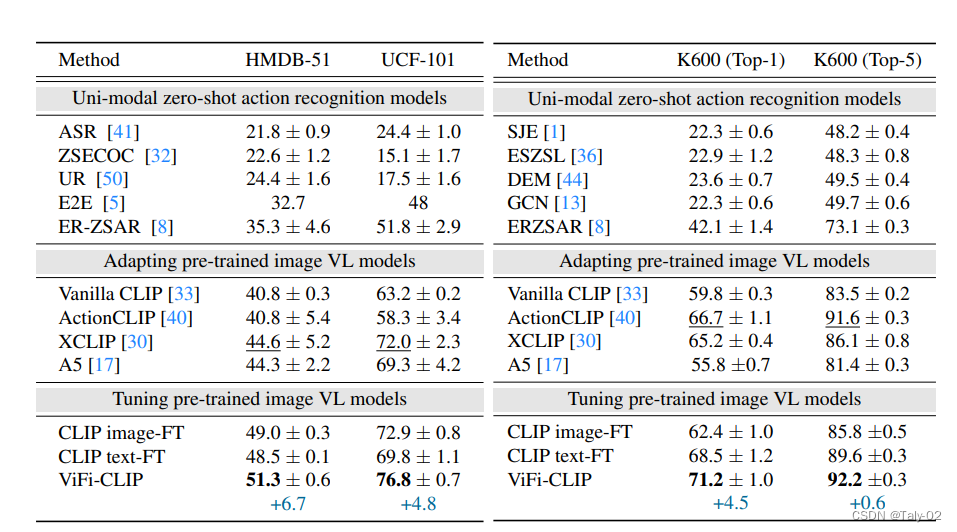
来看实验,首先可以发现,基于CLIP的模型来直接做adapting在zero-shot的情景下已经远超其他方法了。本文设计的ViFo-CLIP这种方法能在较为简单的数据集HMDB-51上,在baseline(Vanilla CLIP)的基础上提高6.7个点,相较于其他的fine-tune方法还是具有明显的优势的,高了2.3个点,而在更难的任务UCF-101上则更是高出了3.9个点。可见本文提出方法的有效性。

从可视化的角度来看,ViFi-CLIP的确有效的学习到了动作相关的attention。由此也可以见识到CLIP的潜力有多么巨大,仅仅进行有限的fine-tune就可以取得很可观的效果,而且具有一定的可解释性。
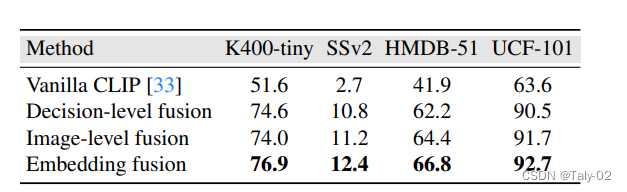
对于消融实验,可以发现在embedding level进行fusion效果是最好的。按照笔者的个人理解,这是因为在embedding层面,feature是具有更多语义上的特征的,所以融合可以捕捉到比较high-level的特征,这也是一种latent fusion的体现。
5. 结论¶
这项工作表明,微调基于图像的 CLIP 模型在视频域的简单基线是常见但往往被忽略的重要方法。论文说明,在视频数据上微调视觉和文本编码器对监督任务和泛化任务都有好处。结果表明,相对于为视频开发的复杂方法,简单解决方案的可扩展性和优势在大多数设置中都是显著的。
本文总阅读量次