GitNet:基于几何先验变换的鸟瞰图分割¶
0. 引言¶
鸟瞰(BEV)的语义分割对于自动驾驶、路径规划等下游任务至关重要,由于需要推断前景对象后面的被遮挡对象的标签,给网络学习有效的特征表示带来了巨大的困难。本文将带大家精读2022 CVPR的论文"GitNet:基于几何先验变换的鸟瞰图分割",该论文阐述了一种新颖的从透视空间到BEV空间的两阶段变换,对于自动驾驶系统中的鸟瞰图分割网络设计具有重要的借鉴和指导意义。
1. 论文信息¶
标题:GitNet: Geometric Prior-based Transformation for Birds-Eye-View Segmentation
作者:Shi Gong, Xiaoqing Ye, Xiao Tan, Jingdong Wang, Errui Ding, Yu Zhou, Xiang Bai
来源:2022 Computer Vision and Pattern Recognition(CVPR)
原文链接:https://arxiv.org/abs/2204.07733v1
2. 摘要¶
鸟瞰图语义分割因其强大的空间表达能力而对自动驾驶至关重要。由于空间差距,从单目图像估计BEV语义图是具有挑战性的,因为它隐含地需要实现透视到BEV的变换和分割。我们提出了一个新的基于几何先验的两阶段变换框架GitNet,它包括(I)几何引导的预对准和(II)基于光线的变换。在第一阶段,我们将BEV分割解耦为透视图像分割和基于几何先验的映射,通过将BEV语义标签投影到图像平面上进行显式监督,以学习可视性感知特征和可学习几何以转换到BEV空间。第二,预对准的粗糙BEV特征通过基于极线的变换器进一步变形,以考虑可见度知识。GitNet在具有挑战性的nuScenes和Argoverse数据集上取得了领先的性能。该代码将公开。
3. 算法分析¶
如图1所示是作者提出的GitNet网络架构,该网络可以从单目图像中学习鸟瞰视图(BEV)分割图。
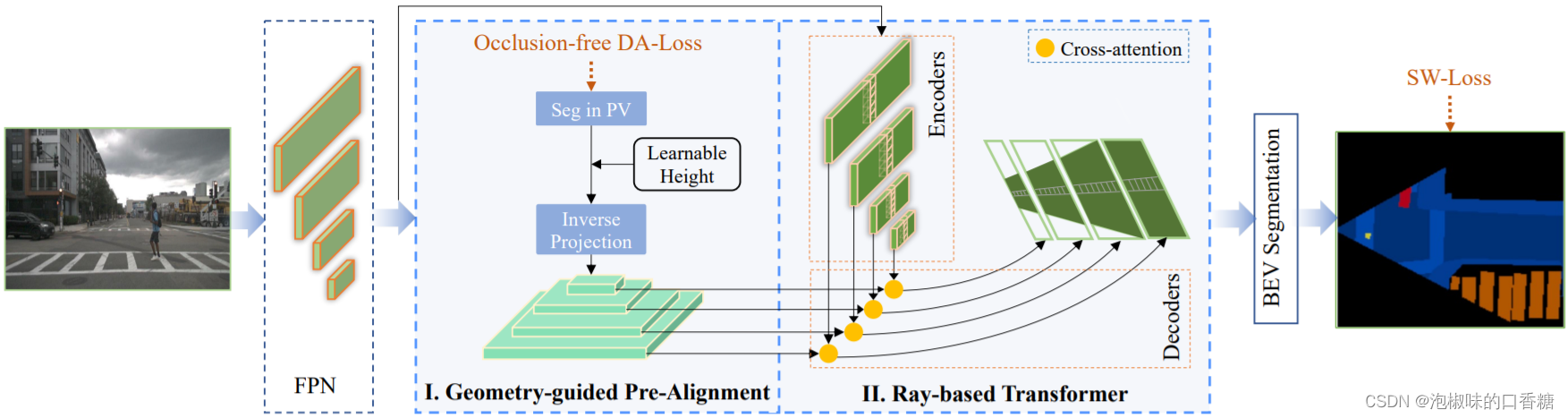
图1 GitNet网络架构总览
GitNet网络有两个阶段:在第一阶段,利用几何引导预对准(GPA)来获得粗预对准的BEV特征。在GPA中,将BEV分割解耦为透视图像分割和基于几何先验的映射,通过将BEV语义标签投影到图像平面上进行显式监督。由于投影标签反映了透视视图中所有的地面区域,包括可见和不可见区域,而透视图像的外观特征只反映了可见区域,因此GitNet网络通过融合投影标签和外观特征的信息来获得可见性感知的图像特征。
在第二阶段,预对准的BEV特征通过基于极线的转换器(RT)进一步增强,该转换器采用高效的基于极线的注意机制,即在单列中计算注意图以保持特征图的高分辨率。传达外观和可见性信息的预先对准的BEV特征,连同BEV位置编码作为查询工作,并且增强的视角特征充当键和值。结合投影标签,提出了新的深度感知骰子损失,以减轻透视视图中较近实例的主导效应。此外,由于那些具有容易分类的外观或遵循简单的透视到BEV映射的像素(大多数道路区域),包含了大部分的损失,因此作者提出了一种自加权骰子损失来平衡类别之间的容易-困难样本。
综上所述,作者所作工作的主要贡献如下:
1 提出了一种新颖的从透视图到鸟瞰图的两阶段转换。在第一阶段,我们将BEV分割解耦为透视图像分割和基于几何先验的映射,并提供可视性感知和预对准的BEV特征。在第二阶段,通过聚集外观信息使扭曲特征变形。
2 引入了一个深度感知的骰子损失来消除透视图像分割的透视效应,并引入了一个自加权的骰子损失来重新加权由易到难的样本。
3 在包括nuScenes和Argoverse在内的两个大规模数据集上展示了最新的性能。
3.1 几何引导预对准¶
GitNet网络的目标在于从单目透视图像预测鸟瞰空间中场景的语义图。而预测BEV语义图的挑战在于输入和输出表示存在于不同的空间中,因此获取网络来学习从透视图像视图到正交BEV空间的转换。如图2所示为几何引导预对准模块的网络结构。

图2 几何引导预对准模块结构
图2所示的几何引导预对准模块解释了从perspective空间到BEV空间的两阶段转换。首先,GitNet利用几何指导来提供外观和可视性,以初始化转换后的BEV特征。在获得预对齐的BEV特征后,进一步采用基于列关注度的极线变换模型,进一步增强特征在BEV空间中的变形,进行语义分割。在可学习的摄像机高度的引导下,对GPA阶段实施明确的监督,以学习可见度感知特征,然后将可见度感知特征转换为预对准的BEV特征。
3.2 基于极线的Transformer模块¶
如图3所示,GitNet网络的两阶段转换的第二步是基于极线的Transformer模块。在此阶段,作者扩展了常见的多头注意力机制。不同于以往Transformer工作的是,作者使用位于同一列的透视图像素对应于鸟瞰图的同一极线。这促使GitNet网络在单个列或极线中计算注意力,大大降低了注意力的复杂性。
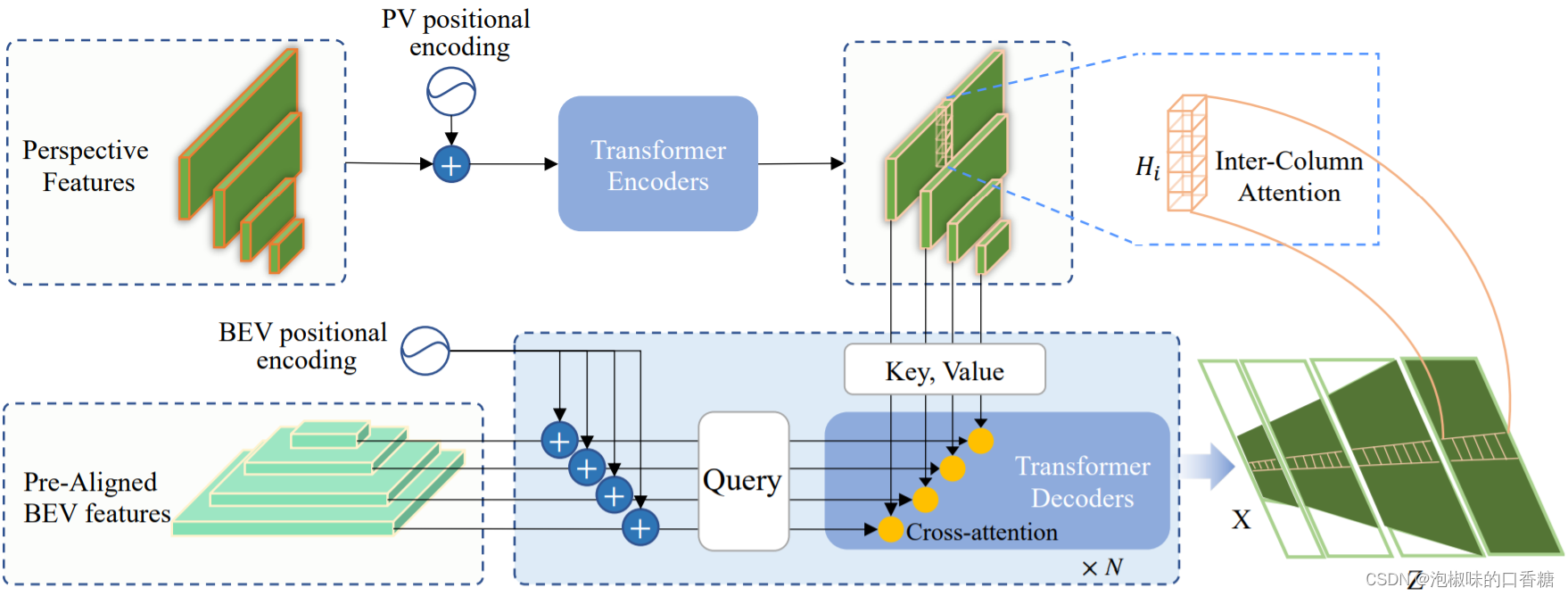
图3 基于极线的Transformer模块
作者在采用多头注意力机制的同时,首先使用列方向的注意力机制,这样可以在高分辨率的特征图上执行;其次引入了预先对齐的特征编码外观和可见性,以及BEV位置编码,作为交叉注意中的查询。
4. 实验分析¶
4.1 数据集测试¶
作者在nuScenes和Argoverse两个大规模数据集上进行了大量的实验。由于这两个数据集本身是针对3D对象检测任务而不是BEV语义分割任务,因此作者将地面实况和矢量化道路地图转换成BEV中的GT语义地图。表1是nuScenes验证集上的IoU结果,表2是Argoverse验证集上的IoU结果,图4是nuScenes验证集分割的可视化结果。
表1 nuScenes验证集上的IoU结果
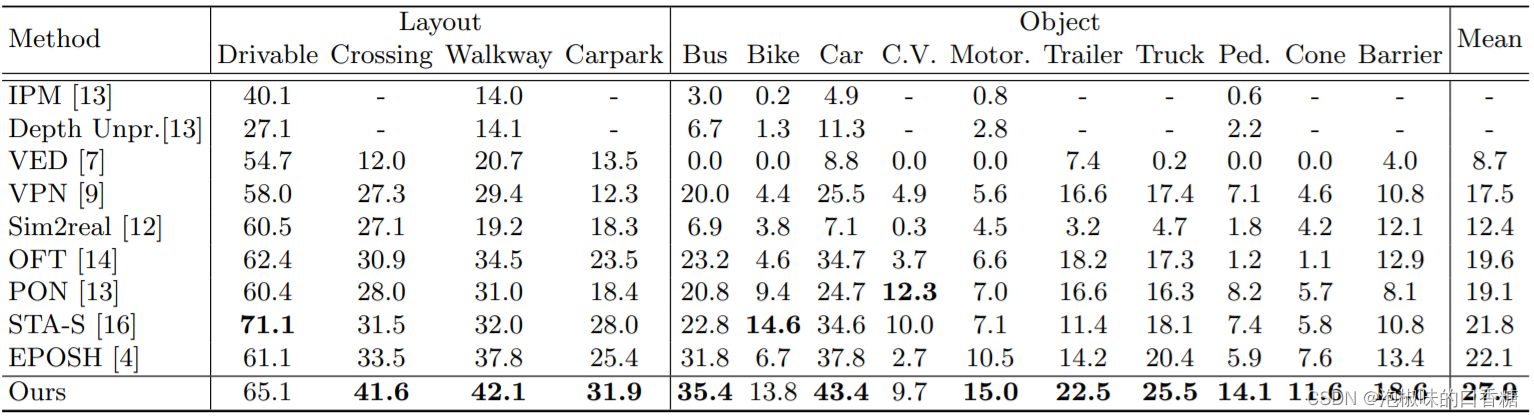
表2 Argoverse验证集上的IoU结果
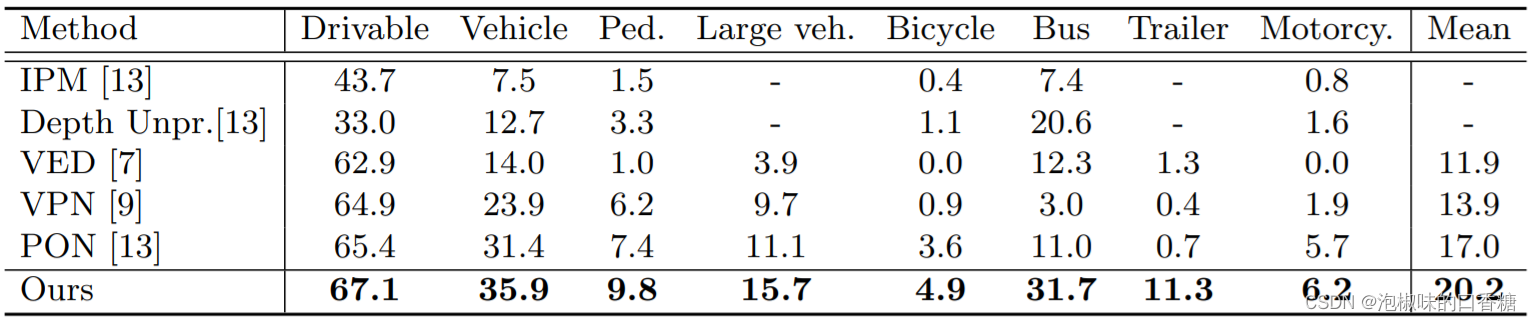
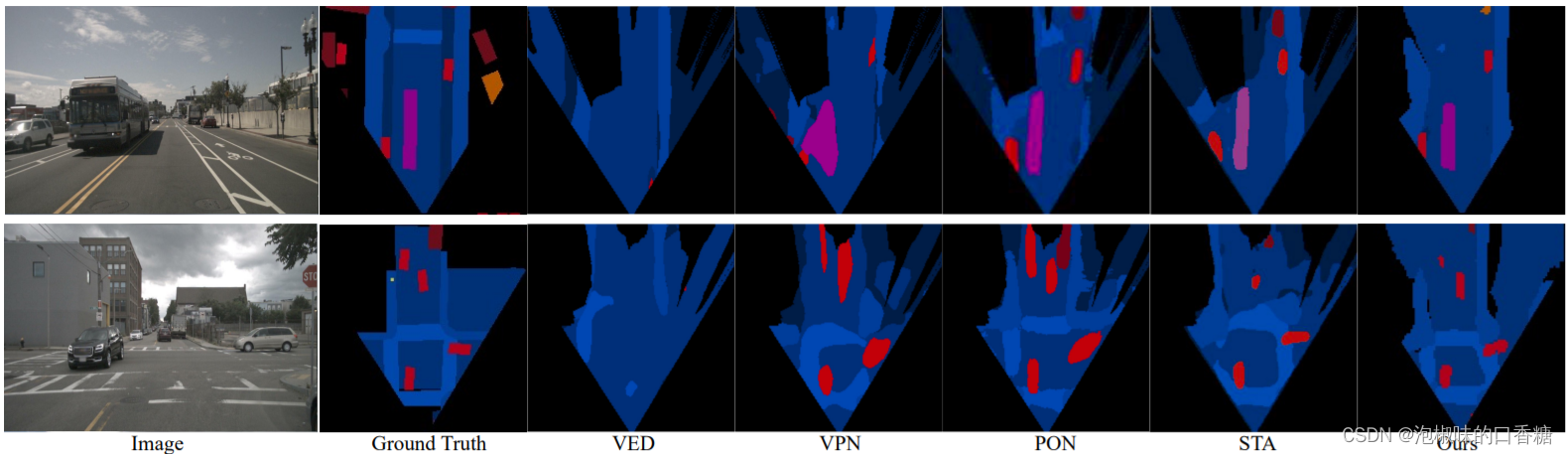
图4 nuScenes验证集的定性结果
表1、表2和图4显示,在所有对比的方法中,GitNet网络在大多数类别上都取得了最好的性能,在nuScenes和Argoverse上分别以6.1%和3.2%的平均IoU显著超过了对比方法。此外,GitNet网络可以利用不同深度间隔的多尺度空间信息来保持细节,从而可以准确预测所有深度范围内的车辆。
4.2 消融实验¶
针对消融实验,作者主要在nuScenes验证集上进行评估,表3所示是消融实验中的不同组合。
表3 消融实验的不同关键元素
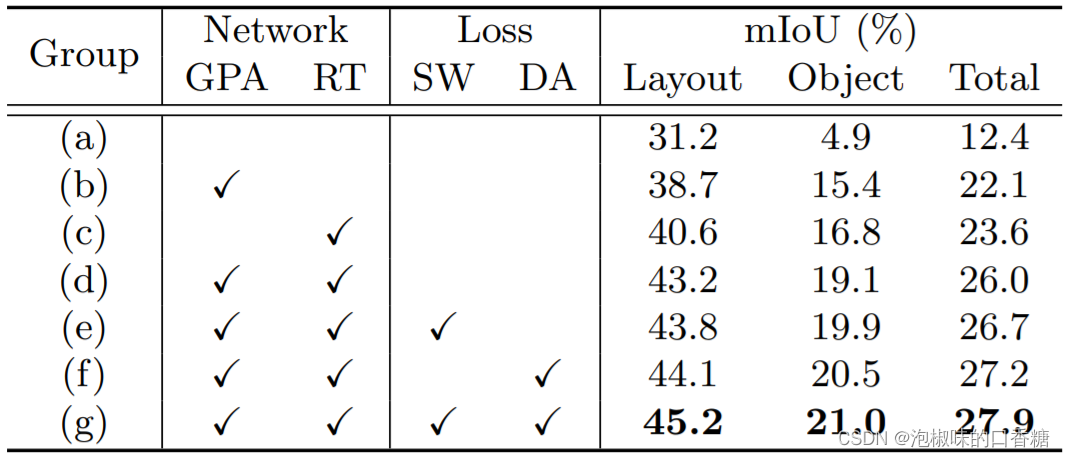
根据表3数据,在网络结构方面,GPA为特征转换提供了可靠的先验,并通过监督投影来减轻遮挡的影响,使mIoU总共提高了+9.7%。RT通过多尺度基于列的注意将图像特征转换到BEV空间,使mIoU总共提高了+11.2%。如果把GPA和RT结合起来,总增幅为+13.6%。
在损失函数方面,SW-Dice loss会自动为这些在鸟瞰图中难以分类的像素赋予更高的权重,从而将mIoU总共提高+0.7%。DA-Dice loss在学习基于几何先验的预对准模块时,通过在立方体深度的指导下重新加权Dice loss,平衡了透视图中不同深度范围的像素,使mIoU总共提高了+1.2%。而两种损失的结合可以带来+1.9%的进一步的mIoU提升。
4.3 多视图实验¶
如图5所示是GitNet网络针对来自六个环绕视图摄像机的融合360° BEV语义分割的实验,验证GitNet网络可以无缝地应用于预测跨视图的一致地图。
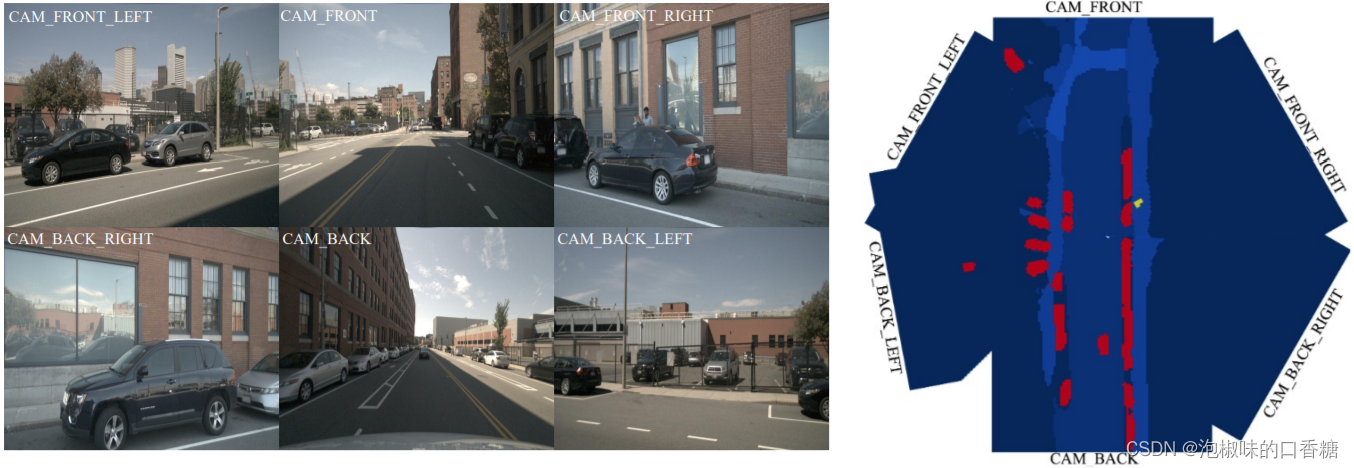
图5 6个环视拼接鸟瞰语义图语义分割实验
5. 结论¶
在论文"GitNet: Geometric Prior-based Transformation for Birds-Eye-View Segmentation"中,作者提出了一种从单目图像预测语义鸟瞰图的新方法GitNet。GitNet利用两级网络将透视图转换为鸟瞰图,首先执行几何引导的预对准,然后利用基于极线的Transformer进一步增强BEV特征。此外,作者最后提出GitNet也可以很容易地适用于多视图场景,以建立一个全场景的BEV图。
本文总阅读量次