用于语义分割的解码器 diffusion 预训练方法
目录¶
-
前言
-
DPSS 方法概述
-
DeP 和 DDeP
- 基础网络结构
- 损失函数
- diffusion 的扩展
-
实验
-
总结
-
参考
前言¶
当前语义分割任务存在一个特别常见的问题是收集 groundtruth 的成本和耗时很高,所以会使用预训练。例如监督分类或自监督特征提取,通常用于训练模型 backbone。基于该问题,这篇文章介绍的方法被叫做 decoder denoising pretraining (DDeP),如下图所示。
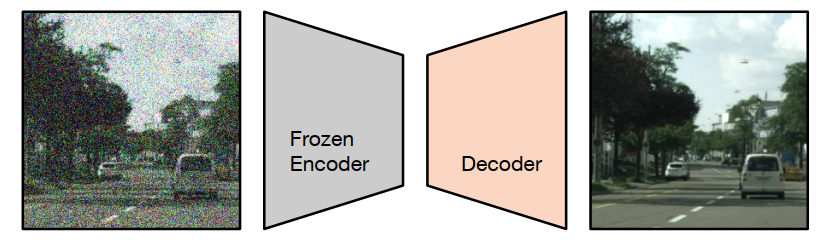
与标准的去噪自编码器类似,网络被训练用于对带有噪声的输入图像进行去噪。然而,编码器是使用监督学习进行预训练并冻结的,只有解码器的参数使用去噪目标进行优化。此外,当给定一个带有噪声的输入时,解码器被训练用于预测噪声,而不是直接预测干净图像,这也是比较常见的方式。
DPSS 方法概述¶
这次介绍的这篇文章叫做 Denoising Pretraining for Semantic Segmentation,为了方便,后文统一简写为 DPSS。DPSS 将基于 Transformer 的 U-Net 作为去噪自编码器进行预训练,然后在语义分割上使用少量标记示例进行微调。与随机初始化的训练以及即使在标记图像数量较少时,对编码器进行监督式 ImageNet-21K 预训练相比,去噪预训练(DeP)的效果更好。解码器去噪预训练(DDeP)相对于主干网络的监督式预训练的一个关键优势是能够预训练解码器,否则解码器将被随机初始化。也就是说,DPSS 使用监督学习初始化编码器,并仅使用去噪目标预训练解码器。尽管方法简单,但是 DDeP 在 label-efficient 的语义分割上取得了最先进的结果。
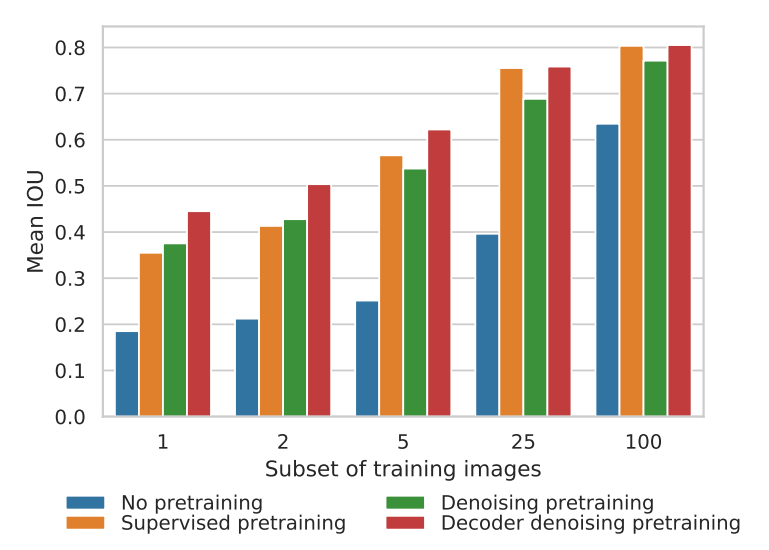
为了方便理解,上图是以可用的标记训练图像比例为横坐标的 Cityscapes 验证集上的平均 IOU 结果。从左到右四个直方图依次是不进行预训练,使用 ImageNet-21K 预训练 backbone,使用 DeP 预训练编码器和使用 DDeP 的方式。当可用的标记图像比例小于5%时,去噪预训练效果显著。当可用标记比例较大时,基于 ImageNet-21K 的监督式预训练 backbone 网络优于去噪预训练。值得注意的是,DDeP 在各个标记比例下都取得了最佳的结果。
DeP 和 DDeP¶
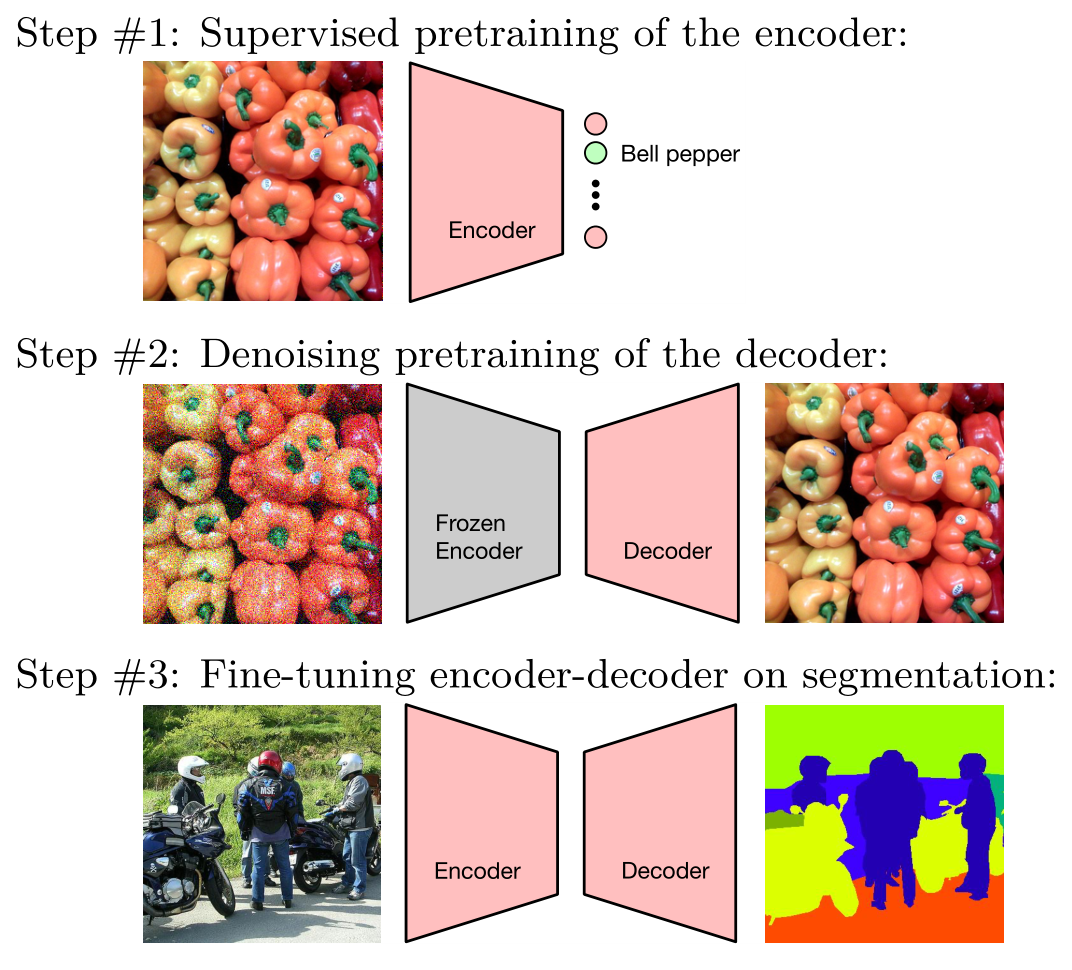
下图是 DPSS 的一个形象的图示,其中第二步代表 DDeP。最后的 Fine-tuning 过程是微调整个网络,而不是只做 last layer。
基础网络结构¶
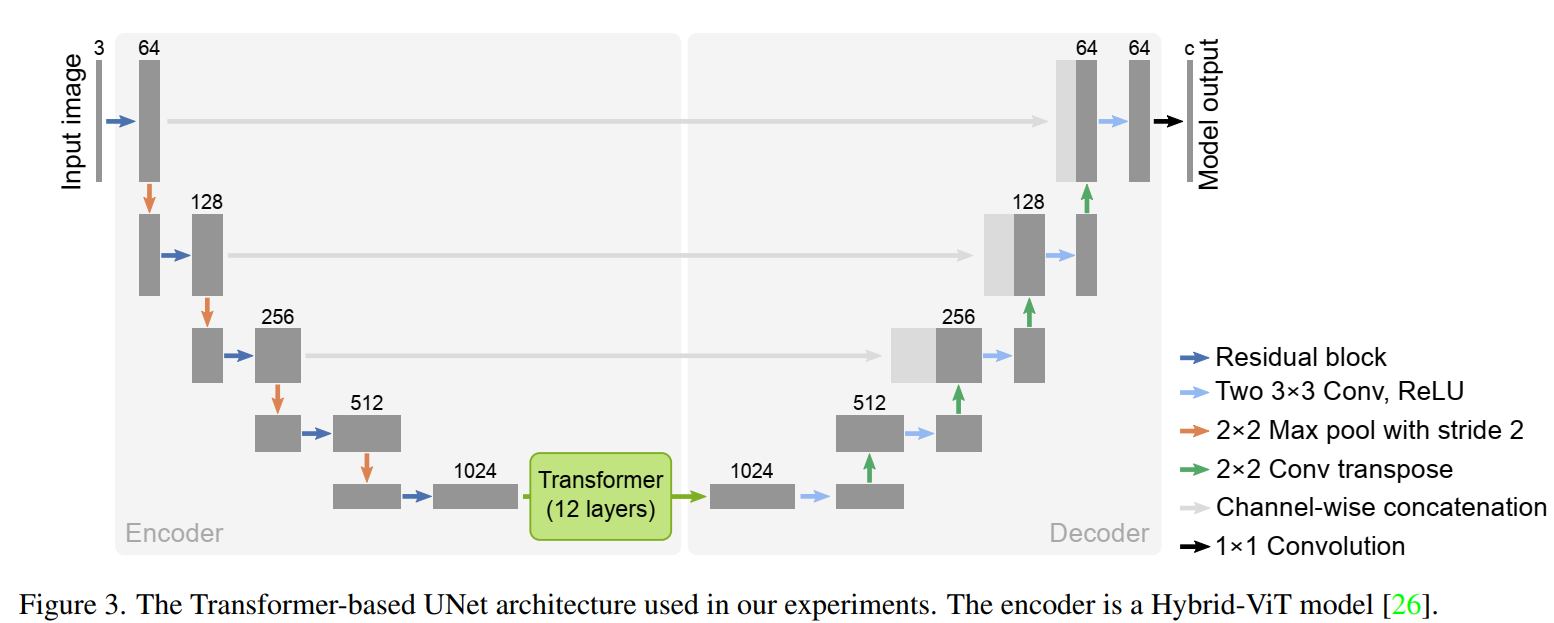
DPSS 使用了基于 Transfomer 的 U-Net 架构:TransUnet,如下图所示。它将 12 层 Transfomer 与标准的 U-Net 模型相结合。这种架构中的编码器是一种混合模型,包括卷积层和自注意力层。也就是说,patch embeddings 是从 CNN 特征图中提取的。这篇论文采用了和 Hybrid-vit 模型相同的编码器,以利用在 imagenet-21k 数据集中预先训练的监督模型 checkpoints。论文中强调,去噪预训练方法并不特定模型架构的选择,只是结果都在 TransUNet 架构上测试。
损失函数¶
为了预训练 U-Net,设计了去噪目标函数。该函数向未标记的图像添加高斯噪声以创建噪点图像。噪音水平由一个叫做 gamma 的标量值控制: $$ \widetilde{\boldsymbol{x}}=\sqrt{\gamma} \boldsymbol{x}+\sqrt{1-\gamma} \boldsymbol{\epsilon}, \quad \boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \boldsymbol{I}) . $$ 然后,噪声图像被输入到 U-Net,它试图通过消除噪点来重建原始图像。去噪目标函数用如下公式表示,它涉及对噪声水平和噪声分布的期望值: $$ \mathbb{E}{\boldsymbol{x}} \mathbb{E}{\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \boldsymbol{I})} \mathbb{E}{\sigma \sim p(\sigma)}\left|f\theta(\boldsymbol{x}+\sigma \boldsymbol{\epsilon})-\epsilon\right|2^2, $$ 还将去噪目标函数与另一种公式进行了比较,该公式对图像和噪声进行衰减以确保随机变量的方差为 1。发现具有固定噪声水平的更简单的去噪目标函数非常适合表示学习: $$ \mathbb{E}{\boldsymbol{x}} \mathbb{E}{\boldsymbol{\epsilon} \sim \mathcal{N}(\mathbf{0}, \boldsymbol{I})}\left|f\theta(\boldsymbol{x}+\sigma \boldsymbol{\epsilon})-\boldsymbol{\epsilon}\right|_2^2 $$ DeP 经过训练,可以从噪声损坏的版本中重建图像,并且可以使用未标记的数据。降噪预训练目标表示为 DDPM 扩散过程的单次迭代。sigma 的选择对表示学习质量有很大影响,预训练后,最终的 projection layer 会被丢弃,然后再对语义分割任务进行微调。此外,上面设计 DDPM 的内容,这里就不赘述了,在 GiantPandaCV 之前的语义分割和 diffusion 系列里可以找到。
diffusion 的扩展¶
在最简单的形式下,当在上一节的最后一个方程中使用单个固定的 σ 值时,相当于扩散过程中的一步。DPSS 还研究了使该方法更接近于 DDPM 中使用的完整扩散过程的方法,包括:
- Variable noise schedule:在 DDPM 中,模拟从干净图像到纯噪声(以及其反向)的完整扩散过程时,σ 被随机均匀地从 [0, 1] 中抽样,针对每个训练样本。尽管发现固定的 σ 通常表现最佳,但 DPSS 也尝试随机采样 σ。在这种情况下,将 σ 限制在接近 1 的范围内对于表示质量是必要的。
- Conditioning on noise level:在扩散形式化方法中,模型表示从一个噪声水平过渡到下一个的(反向)转换函数,因此受当前噪声水平的条件约束。在实践中,这是通过将为每个训练样本抽样的 σ 作为额外的模型输入(例如,用于标准化层)来实现的。由于我们通常使用固定的噪声水平,对于 DPSS 来说,不需要进行条件设置。
- Weighting of noise levels:在 DDPM 中,损失函数中不同噪声水平的相对权重对样本质量有很大影响。论文中的实验表明,学习可转移表示不需要使用多个噪声水平。因此,DPSS 并未对不同噪声水平的加权进行实验。
实验¶
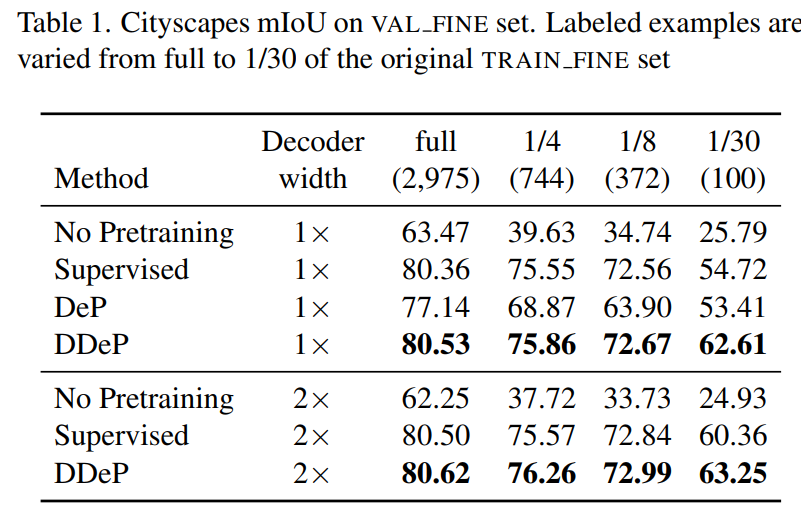
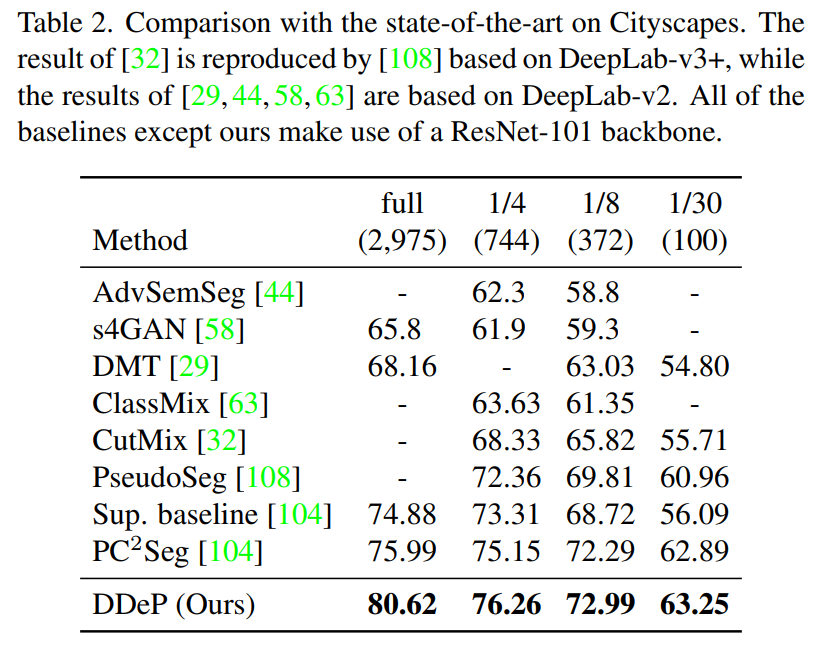
实验在 Cityscapes,Pascal Context 和 ADE20K 数据集上。下面两个表是在 Cityscapes 的验证集上进行测试,其中还测试了可用带标签训练数据为原始训练数据量 1/30 的情况,表明即使有标签的样本数量很少,DPSS 在 mIoU 上的表现也优于以前的方法。
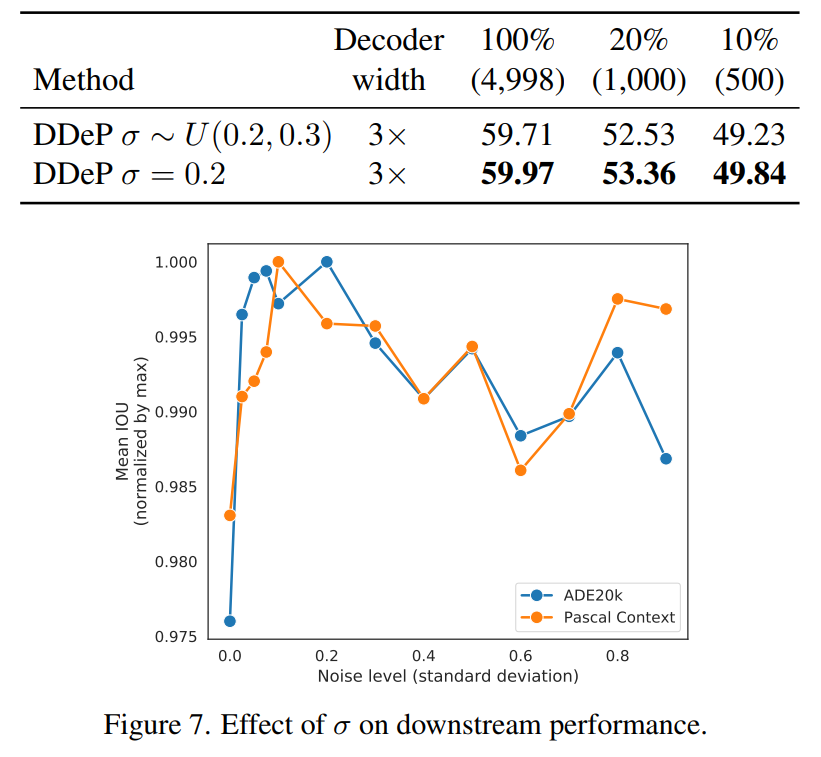
下面比较了在 DeP 模型中调整 sigma 参数的两种不同方法的性能。第二种方法使用固定的 sigma 值,而第一种方法从间隔 [0.2,0.3] 对西格玛进行均匀采样。此外,折线图表示固定 sigma 在值为 0.2 左右的区间效果更好。这部分实验基于 Pascal Context 和 ADE20K 数据集。
总结¶
这篇文章受到 diffusion 的启发,探索了这些模型在学习可转移的语义分割表示方面的有效性。发现将语义分割模型预训练为去噪自编码器可以显著提高语义分割性能,尤其是在带标记样本数量有限的情况下。基于这一发现,提出了一个两阶段的预训练方法,其中包括监督预训练的编码器和去噪预训练的解码器的组合。在不同大小的数据集上都表现出了性能提升,是一种很实用的预训练方法。
参考¶
- https://openaccess.thecvf.com/content/CVPR2022W/L3D-IVU/html/Brempong_Denoising_Pretraining_for_Semantic_Segmentation_CVPRW_2022_paper.html
- https://github.com/bwconrad/decoder-denoising
本文总阅读量次