YOLOV1 - V4 第二次阅读¶
YOLOV1 - V4 算法更新日志
V1:
- 作者尝试从回归角度而不是分类角度(参考faster rcnn)来理解目标检测问题(可以看YOLOV1的参考文献[9] multibox提出的思路)
- 因为采用的是纯粹的CNN设计,所以定位和分类层能够更好的获取特征的上下文信息,带来的收益是更低的定位假阳性(背景误检为目标)
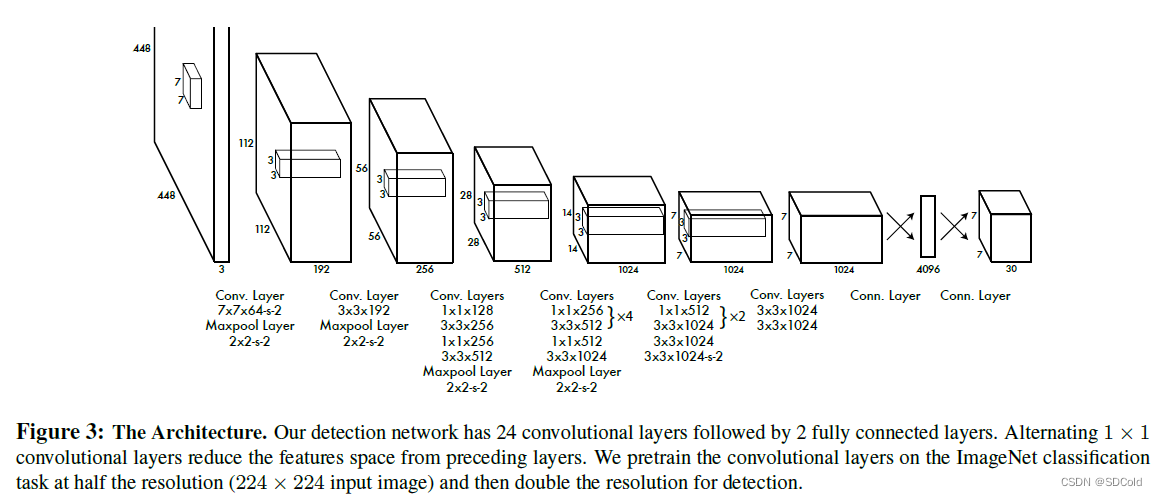
- backbone的设计参考了GoogLenet,再参考论文的参考文献[29],增加了卷积层和全连接层,并提高了输入图的分辨率
- 作者还尝试了用VGG-16做backbone,得到的结论是比darknet的backbone更准确,但是推理速度也更慢一些
- 此时的网络设计,某个位置预测的所有bbox共用一组分类分数,但是有各自独立的定位回归值和objectness分值
- 作者在VOC 2007上做了和faster rcnn的详细性能对比
- 优点:网络推理速度比当时的其它网络都要快; 缺点:定位精度低,对有遮挡目标往往只能检测到一个,小目标召回偏低,对同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力较弱
 ¶
¶
V2:基于论文发布时间段其他学者的一些学术成果和作者自己的思考和实验进行yolo的改进
- 在所有卷积层上增加BN层
- 去掉了V1中的全连接层,从而允许检测网络接受多分辨率图像的输入
- 作者在yolo中开始采用基于anchor的定位回归,且anchor为对数据集通过k-means聚类得到,针对由anchor直接回归目标bbox不稳定的问题,改为使用logstic激活(sigmoid函数),将回归值物理意义上调整为(0,1)之间的值,表示比例值,此举让定位训练更加稳定易收敛,宽高则采用了exp函数。在最后输出特征层的每个位置预测K个anchor,作者实验认为k=5时效果不错
- 添加passthrough层,进行浅层特征和深层特征的concat,目的是提升小目标的检测能力(作者有看到SSD从三个不同的feature层进行回归分类的设计,而YOLOV2中,选择了添加passthrough改进方式)
- 训练时采用了多尺度训练
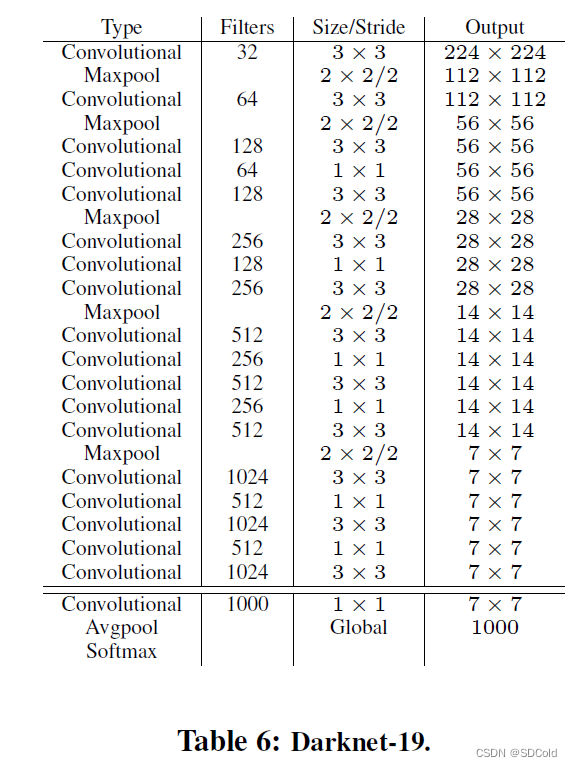
- 仍旧基于GoogLenet重新进行backbone的设计,和V1版本的区别是,将网络输入层的7-7的卷积核换回了3-3的卷积核,仍旧大量的采用了1-1卷积核,新设计的backbone为Darknet-19,相比之前的backbone更轻量(去掉了一些利用1-1卷积核进行特征图升维及降维的算子流程),推理速度更快,模型的精度也有提高
- 优点: 对小目标和遮挡目标的处理能力比V1版本有提高,mAP 稳步提高; 缺点:对小目标的识别仍旧是瓶颈
 ¶
¶
V3:原作者的第三版,作者原意是说这版只是对前一版的一些比较小的改动和优化,但是工作还是做的很扎实
- anchor base 定型为对应特征图上每个位置三个不同宽高比及尺度的anchor,也就是我们熟悉的(5+n)*3的输出模式
- 作者认为分类部分用一个softmax并不是最优选择,所以设计为对每个类别一个单独的sigmoid函数进行分类得分计算
- 替换passthrough层为上采样再与较深的某指定层进行concat以得到更细粒度的特征应对小目标
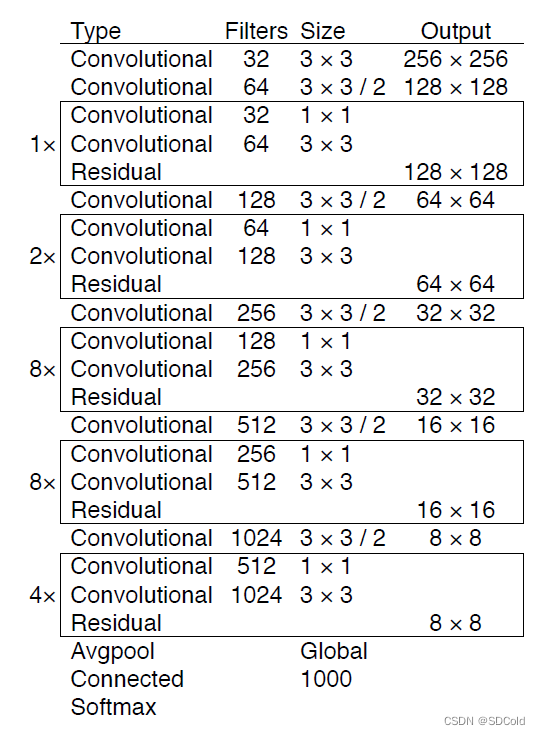
- 仍旧对backbone进行了改进,添加了残差结构,得到了Darknet-53
- 作者还尝试了将focal loss作为损失函数的一部分加入训练,实验证明并没有提高模型性能,所以就去掉了
- 作者还吐槽了了COCO数据集上的mean mAP .5 : .95 指标,实际业务中IOU 0.3和 0.5 区别并不大
- 优点:易训练易使用,精度和速度在一些固定场景完全够用;缺点:作者分析认为YOLOV3对中大型目标的检测结果依旧说不上好
 ¶
¶
V4:硬核工作,对当时的训练技巧,网络结构定义时的各个组件组成、效能及选择都做了很棒的分析报告
- 将网络结构设计划分为:backbone、neck、head、loss function、tricks五个部分,并对每个部分的任务和效能做了说明,例如backbone就是为了既快又好的提取特征,neck的目的是为了扩大感受野、head是用于解析特征输出结果
- mosaic数据增强方法的引入
- 花费大量篇幅讲述和实验了好用的检测网络训练trick及即插即用组件
- 该论文最重要的我觉得是实验章节,细节太多建议大家常看常新,推荐一个论文翻译
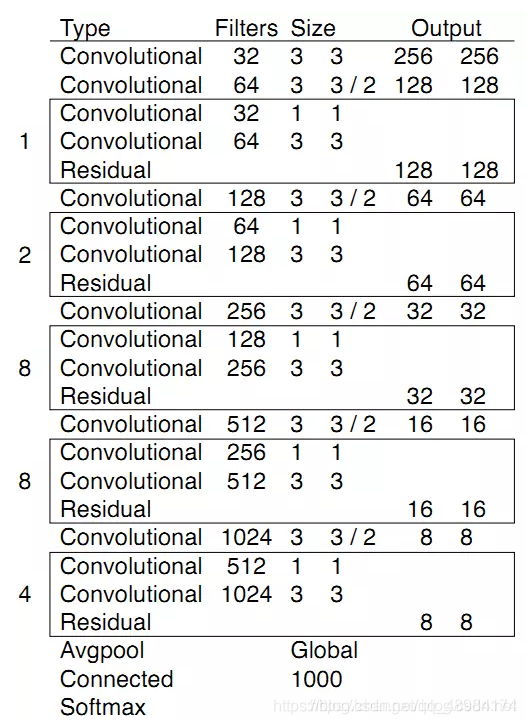
- 继续改进backbone,利用CSP结构对darknet53进行进一步的优化改进,并添加了SPP模块,引自一位CSDN博主
 ¶
¶
自说自话¶
因为笔者目前进度只看了这四篇,所以关于V5、V6和V7的知识打算后续再总结补充,先说说从V1 - V4的设计中体会到的点
1.这四个版本,作者都在紧跟最新技术来修改和优化backbone的设计,而从V1开始,作者在论文中其实就隐约提到检测和分类网络设计是有区别的,落在实际的网络设计上,就是作者在backbone的设计中,和常见的分类网络设计一样大量采用了1-1卷积核来进行特征维度的调整,而该设计也一直沿用下来,但是用于检测的backbone特征通道维度相对分类网络是降低了的,这里我的个人猜测是因为检测需要的是更大的上下文,分类要的是更细粒度的编码空间
2.关于评测指标的问题,作者从V1开始,其实结果分析就不是完全的相信某个指标,而是在指标之外,尽量详尽的分析,针对哪类目标,什么情况性能仍旧受限,与其他网络的对比是什么样的等,在V3中,作者也提到了COCO的mean mAP指标设计,感觉作者是真的觉得对网络性能的分析除了指标外,应定性定量的对不同待检测情况进行分析,才能得到一个更加准确的模型性能说明。比如对COCO数据集,因为该数据集中目标普遍偏小,所以在该数据集上反应的性能可以理解为,在较小目标上,当前检测网络的泛化能力和检测能力。对遮挡、异形、恶略天气等可能都需要专门的数据集才能衡量出足够信赖的性能说明,比如这里贴一下YOLOV1原论文中的截图片段,作者就不只是看了指标,而是对

3.关于yolo在历史演变过程中的各种变种,其实我也是推荐大家都看看,有些设计还是很棒的,只是这四篇作为YOLO检测器的历史发展主干摆在这里,希望能够给大家提供一点帮助
本文总阅读量次