TMI 2023:对比半监督学习的领域适应(跨相似解剖结构)分割
目录¶
- 前言
- 前置知识
- Semi-supervised Learning
- Domain Adaptation
-
Contrastive Learning
-
CS-CADA 方法介绍
- Joint Learning with Domain-Specific Batch Normalization(DSBN)
- Self-Ensembling Mean Teacher (SE-MT) with DSBN
-
Cross-Domain Contrastive Learning
-
Overall Training Loss
- 实验和可视化
- 总结
- 参考
前言¶
U-Net 在医学图像分割方面已经取得了最先进的表现,但是需要大量手动注释的图像来进行训练。半监督学习(SSL)方法可以减少注释的需求,但是当数据集和注释图像数量较小时,其性能仍然受到限制。利用具有相似解剖结构的现有标注数据集来辅助训练可以提高模型性能。但是,这个方法面临的挑战是由于目标结构的外观和成像模式与现有标注数据集不同,导致解剖跨域差异。为了解决这个问题,这篇论文提出了跨解剖域自适应对比半监督学习(Contrastive Semi-supervised learning for Cross Anatomy Domain Adaptation,CS-CADA)方法,通过利用源域中一组类似结构的现有标注图像来适应目标域的模型分割类似结构,只需要在目标域中进行少量标注。
有一些细节的方法我们先简单概述下,CS-CADA 使用领域特定批归一化(Domain Specific Batch Normalization ,DSBN)来分别归一化两个解剖域的特征图,并提出跨域对比学习策略来鼓励提取领域不变性特征。它们被整合到自我集成平均教师(Self-Ensembling Mean-Teacher,SE-MT)框架中,以利用具有预测一致性约束的未标注目标域图像。实验证明 CS-CADA 能够解决具有挑战性的解剖跨域差异问题,只给出目标域中少量的标注,就能够在 X 光血管造影图像分割中使用视网膜血管图像,在心脏 MR 图像分割中使用眼底图像,如下图所示。
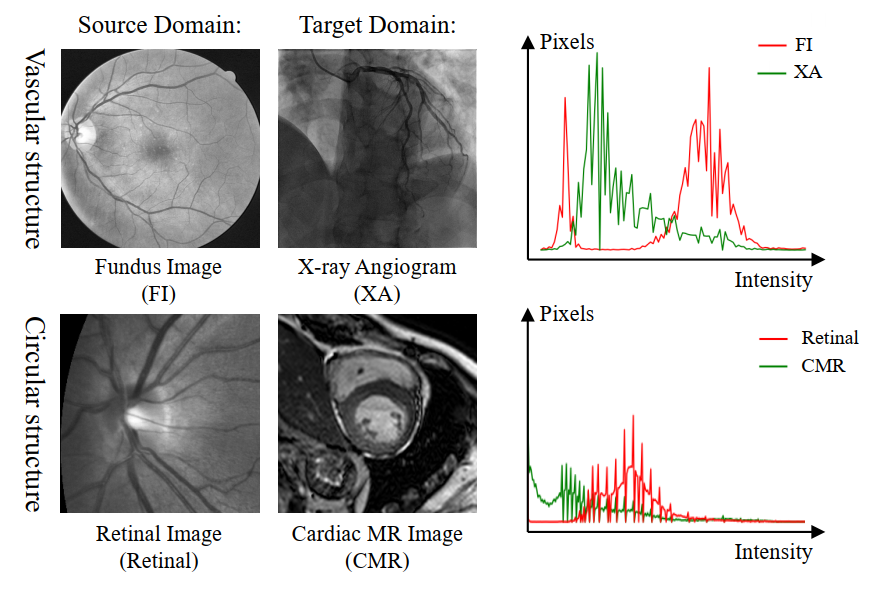
前置知识¶
Semi-supervised Learning¶
在半监督学习中,一个典型的例子是 Mean-Teacher。与对抗网络类似,其整体架构包含了两个网络:teacher 网络和 student 网络。不过与对抗网络不同的是,这两个网络结构是相同的,teacher 网络参数通过 student 网络计算得到,student 网络参数通过损失函数梯度下降更新得到。
(1)teacher 网络参数更新:整个训练过程中 teacher 网络的参数通过 student 网络参数的 moving Average 更新:
(2)student 网络参数更新:通过梯度下降更新参数得到损失函数包含两部分:第一部分是有监督损失函数,主要是保证有标签训练数据拟合;第二部分是无监督损失函数,主要保证 teacher 网络的预测结果与 student 网络的预测标签尽量的相似。由于teacher 的参数是 student 网络参数的 moving Average,因此要求不管什么样本预测标签都不应该有太大的抖动,类似于对标签做了平滑,保证其输出结果更具有稳定性,无标签数据也可以构造该损失函数。
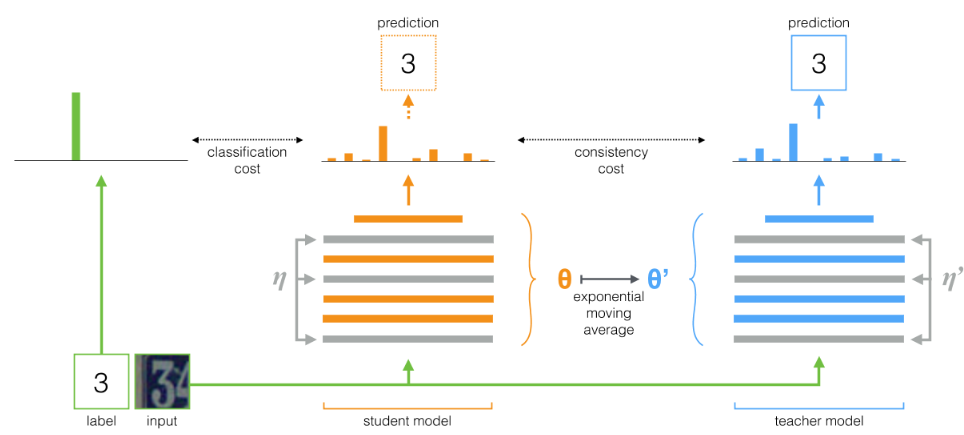
假设有一批训练样本 x1,x2,其中 x1 是有标签数据,x2 是无标签数据。具体训练过程如下:步骤一,把这一批样本作为 student 网络输入,然后分别得到输出标签 ys1 和 ys2;步骤二,损失函数 L1,对于有标签样本 X1,构造分类损失函数;步骤三,损失函数 L2,通过 student 网络参数,更新计算 teacher 网络参数,并把样本 x1,x2 输入 teacher 网络,得到预测标签 yt1,yt2,然后构造防标签抖动,连续性损失函数(直接采用 MSE 损失函数);步骤四,根据 L=L1+L2 进行梯度下降,求解更新 student 网络参数。
Domain Adaptation¶
在这一部分我们只做思路介绍,不做论文中具体例子的讲解。其目标就是将原数据域(source domain)尽可能好的迁移到目标域(target domain),Domain Adaptation 任务中往往源域和目标域属于同一类任务,即源于为训练样本域(有标签),目标域为测集域,其测试集域无标签或只有少量标签,但是分布不同或数据差异大,具体根据这两点可以划分为:
- homogeneous 同质:target 与 source domain 特征空间相似,但数据分布存在 distribution shift。
- heterogeneous 异构:target 与 source domain 特征空间不同。
- non-equal:空间不同且数据偏移,这种就属于差异很大的情况了,可借助中间辅助 data 来 bridge the gap,用 multi-step / transitive DA 来解决。
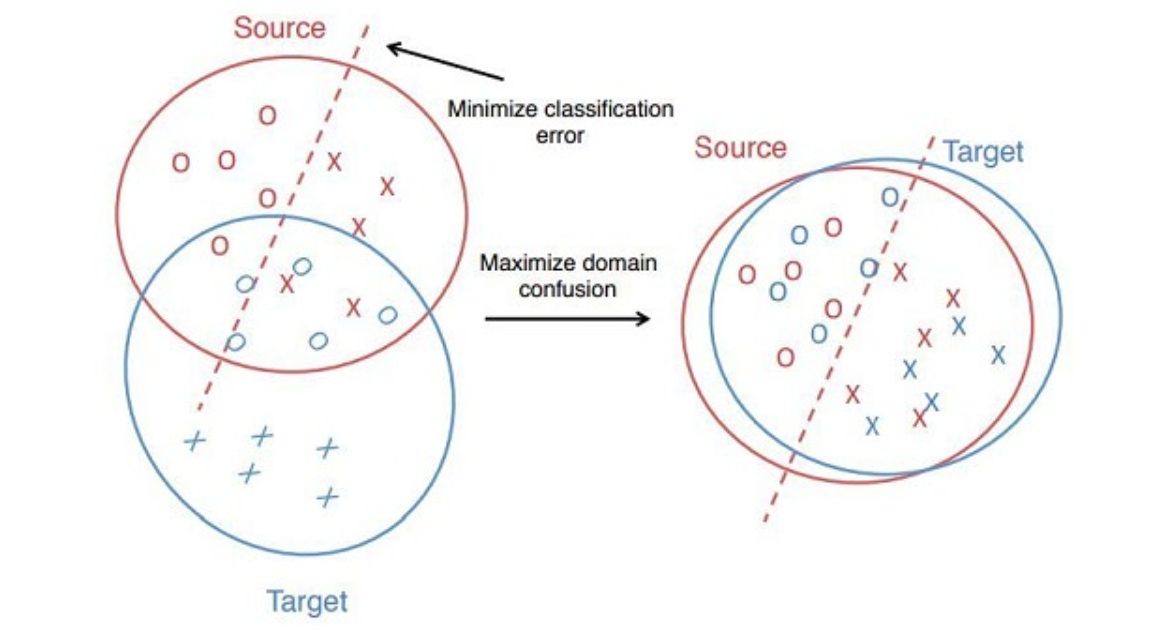
这也是与 Pre-traning 不一样的地方,现在流行的 Pre-traning 技术也需要后期的很多数据才行。但由于 DA 的目标域是没有标签的,那么如何使在源于训练得到的模型也能够被目标域使用呢?很自然的想法是将源域和目标域映射到一个特征空间中,使其在该空间中的距离尽可能近。于是产生了三大类方法:
- 样本自适应,对源域样本进行加权重采样,使得重采样后的源域样本和目标域样本分布基本一致,然后在重采样的样本集合上重新学习分类器,即把源域和目标域相似的数据直接加权然后再训练。这种方法虽然简单但太过依赖于设计和经验。
- 特征层面自适应,将源域和目标域投影到公共特征子空间,在子空间中两者的数据分布一致。
- 模型层面自适应,对源域误差函数进行修改,考虑目标域的误差。主要有两种方式,一是直接建模模型,但是在模型中加入“domain 间距离近”的约束,二是采用迭代的方法,渐进的对目标域的样本进行分类,将信度高的样本加入训练集,并更新模型。
技术手段主要分为 Discrepancy-based(空间距离近)和 Adversarial-based(混淆空间)。
Contrastive Learning¶
对比学习是一种自监督的学习方法,旨在通过学习相似和不相似的样本之间的差异,从而为后续的下游任务提供有用的特征。在这篇论文中,使用对比学习方法进行跨解剖域自适应,旨在训练一个能够提取具有域不变性的特征的模型。这种方法与以往的对比学习方法不同之处在于,它是用于解决跨域问题的,并且它特别强调了模型应该在相似的解剖结构之间提取全面的特征。通过这种方法,可以训练出一个能够在不同解剖域上具有较好性能的模型。
CS-CADA 方法介绍¶
在这一部分,主要介绍 CS-CADA 方法的实现流程,主要由三部分组成,分别是 DSBN、SE-MT 和跨域对比学习模块。橙色圆圈和蓝色圆圈分别表示源域和目标域经过 DBSN 处理后的特征,因为 DBSN 的设计,每个域上会输出两种特征。
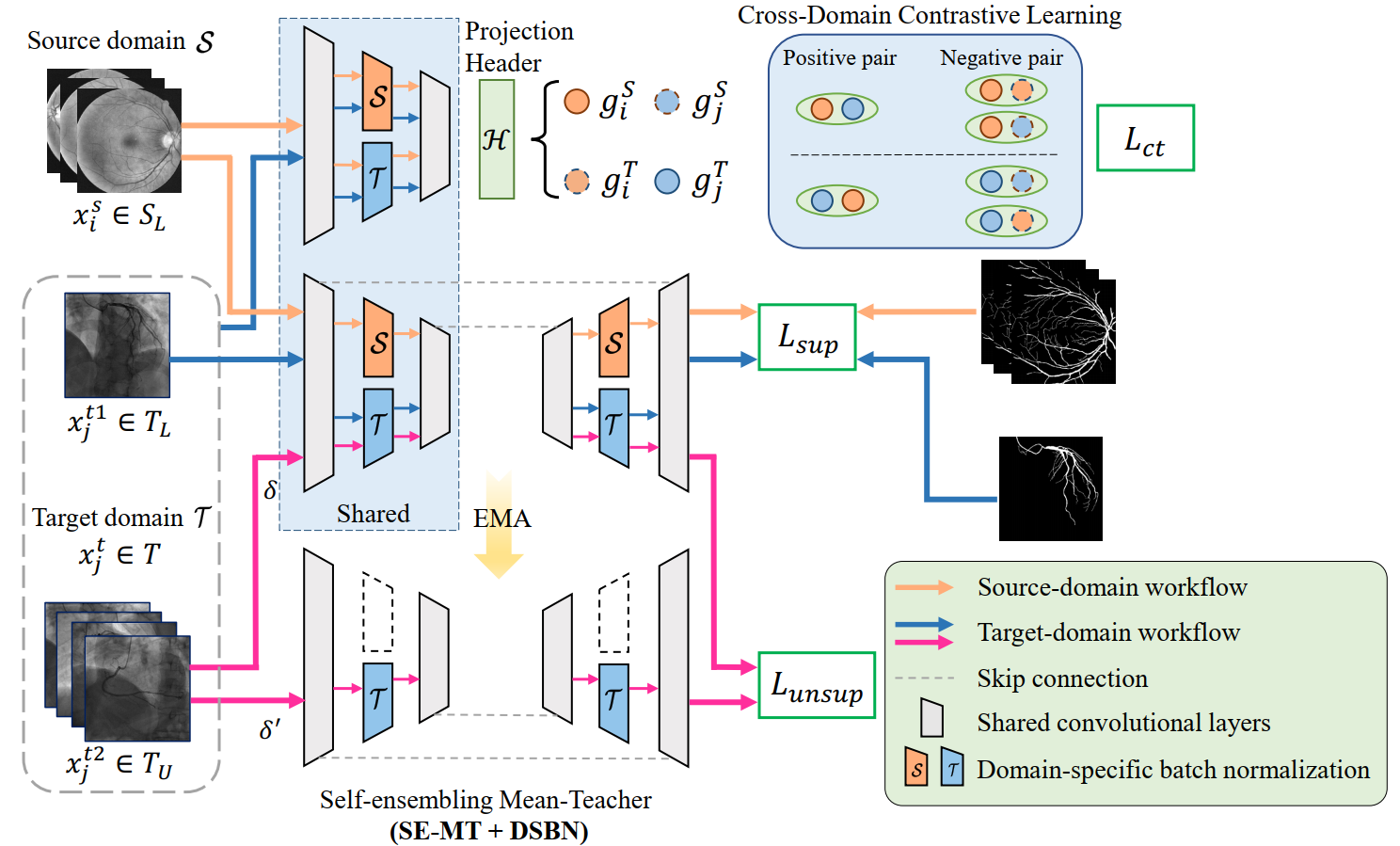
Joint Learning with Domain-Specific Batch Normalization(DSBN)¶
源域和目标域之间存在差异,如果直接使用来自这两个域的数据进行训练,则会受到域间统计变化的影响,从而无法学习到通用的特征表示。为了解决这个问题,提出了一种称为 DSBN 的方法,在网络中引入了两种不同的批归一化,分别用于处理两个域中的数据。通过采用这种方法,可以更好地处理源域和目标域之间的差异,并从中学习到更通用的特征表示。DSBN 会对每个域中的特征进行归一化,并使用特定于该域的参数来对其进行仿射变换。同时,卷积核在两个域之间是共享的,以学习到更通用的表示。
模型中有编码器和解码器两部分,分别共享卷积参数 𝜃𝑒𝑛 和 𝜃𝑑𝑒。在 DSBN 方法中,{𝛾𝑑, 𝛽𝑑} 表示在域 𝑑 中的一组可训练参数。对于源域,参数集合可以表示为 ΘS = »𝜃𝑒𝑛, 𝜃𝑑𝑒, 𝛾S, 𝛽S…,对于目标域,参数集合可以表示为 ΘT = »𝜃𝑒𝑛, 𝜃𝑑𝑒, 𝛾T, 𝛽T…。DSBN 方法提供了处理域特定分布和将风格特征映射到公共空间的域特定变量,通过执行单独的特征归一化,可以有效地减少域间差异。在训练期间,DSBN 分别计算每个域的特征的均值和标准差。对于每个域,使用 DSBN 来进行白化输入激活,并在测试阶段使用移动平均估计(EMA)。这种方法可以使不同域之间的数据分布更加一致,提高模型的跨域泛化能力。给定源域 S 和目标域 T 中的图像-标签对,定义了一个监督损失函数来联合优化这些参数集合。
这是一个混合分割损失,由交叉熵损失和 Dice 损失组成。具体来说,交叉熵损失用于测量预测的类别分布与真实类别分布之间的差异,而 Dice 损失用于测量预测边界的相似性。通过联合优化参数集和这个损失函数,可以在源域和目标域之间实现高质量的图像分割。
上面提到的 EMA,是一种常见的数据平滑技术,用于减少数据的噪声和波动性。它通过对最近数据的加权平均来计算平均值,其中较新的数据被赋予更高的权重,而较旧的数据则具有较低的权重。这使得 EMA 能够比简单平均更好地反映数据的趋势和变化。EMA 通常用于计算参数的指数加权平均值,这可以使参数更新更平稳,从而减少过拟合。在测试阶段,EMA 通常用于计算移动平均值以估计某些统计量,如平均值和标准差。
Self-Ensembling Mean Teacher (SE-MT) with DSBN¶
这一部分就是我们在前置知识中介绍的内容,可以结合 CS-CADA 的流程图理解,涉及到一个无标签的损失函数:
即将学生网路和教师网路的输出计算 MSE。
Cross-Domain Contrastive Learning¶
一个用于解决源域和目标域之间差异和上下文变化的跨域对比学习策略。如最上面的 CS-CADA 流程图,为了在保持对不同图像鲁棒性的同时捕捉相似解剖结构的域不变特征,该方法使用非线性投影将编码器的输出进行投影,得到高级特征表示。通过对源域图像和目标域图像的标准化特征表示进行比较,建立了正负样本对,其中正样本对应相似的解剖结构,负样本对应不同的图像样式。通过自监督对比损失函数定义了源域到目标域对比损失和目标域到源域对比损失,最终得到了交叉域对比损失函数。该方法可以使特征表示更容易迁移到目标域并提高分割性能。
源域到目标域的对比损失如下:
目标域到源域的对比损失如下:
最后两者取均值就好。
Overall Training Loss¶
最终涉及到有三个损失:
L_sup 代表监督损失,衡量源域和目标域中带注释图像的预测分割结果与金标准之间的差异。 第二个 L_unsup 代表无监督损失,即半监督学习中使用的损失。衡量目标域中带注释和未注释图像的特征表示之间的相似性。目标是鼓励模型为属于同一类别的图像生成相似的特征表示。 第三项 L_ct 表示对比损失,用于利用源域中带注释的图像使模型适应目标域。衡量源域和目标域中带注释的图像的特征表示之间的相似性。目标是鼓励模型为属于同一类别的图像生成相似的特征表示,即使它们来自不同的域。系数 λ1 和 λ2 是超参数。
实验和可视化¶
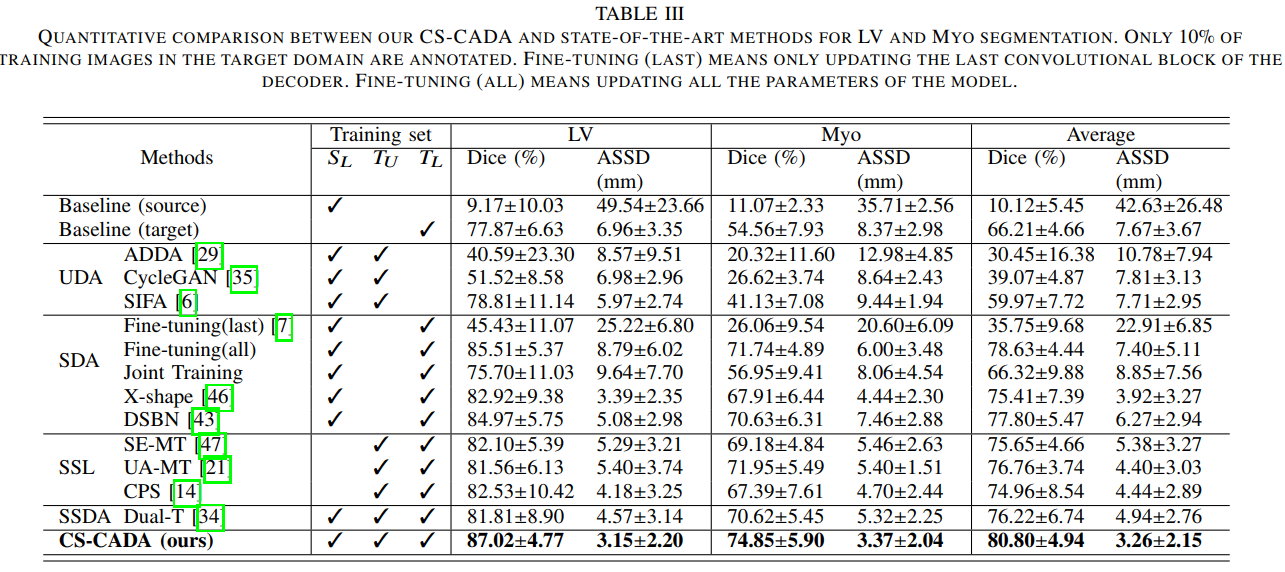
在下表中,以源域为 REFUGE 数据集,目标域为心脏 MR 图像为例,CS-CADA 的 LV(左心室血腔)分割结果是非常好的,很接近监督学习的效果,但 Myo(心肌)的分割效果还有待提高。
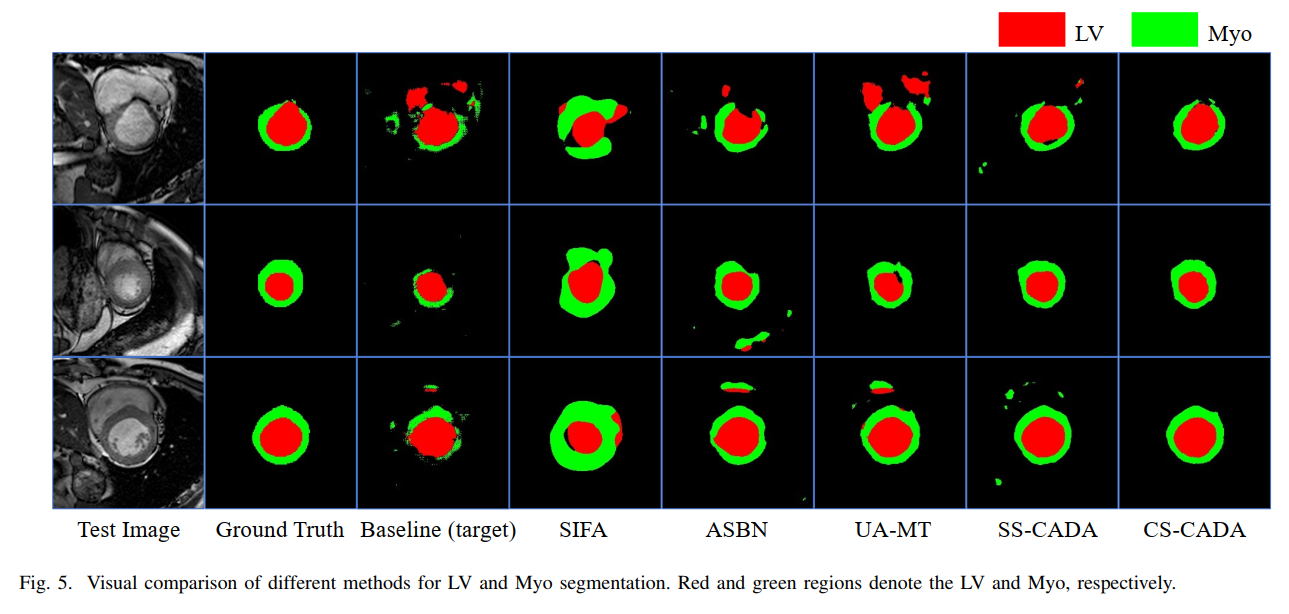
可视化效果如下图:
总结¶
这篇论文提出了一种在医学图像分割任务中进行跨解剖结构域自适应(cross-anatomy domain adaptation)的方法,其重要性在于减少标签成本并同时保持模型的鲁棒性。考虑到已有具有类似解剖结构的标注数据集的可用性,CS-CADA 可以通过从这些可用数据集中转移知识到目标分割任务中来提高分割性能,其中目标分割任务仅有少量注释数据,并且该方法的性能优于传统的 fine-tuning 方法进行的迁移学习。同时,也优于现有的半监督方法,因为后者并不考虑来自其他域的图像,并且也优于现有的专注于相似或不同模态中的相同解剖结构的领域自适应方法。
值得注意的是,CS-CADA 与传统的领域自适应不同,传统方法只考虑对于同一组结构的跨模态域位移。这篇论文处理的是更加困难的情况,即使用具有类似解剖结构的现有数据集来辅助目标域的模型训练。”类似的解剖结构“要求表示两个域之间存在形状相似性,即形状具有相似的拓扑结构,但在尺度上可能有所不同。例如,不同器官中的血管在血管形状上是相似的,但它们在直径和方向上可能是不同的。此外,心脏 MRI 中的 LV 和 Myo 以及眼底图像中的视杯和视盘明显是两个不同的域,但它们都具有不同尺度的圆形结构。
参考¶
- https://blog.csdn.net/qq_39388410/article/details/111749346
- https://ieeexplore.ieee.org/abstract/document/9903480
本文总阅读量次